AIナレッジベース記事ライター:実際の使い方(2026年版)
Kurnia Kharisma Agung Samiadjie
Katelin Teen
最終更新 June 23, 2026

まとめ
AIナレッジベース記事ライターは、白紙の状態から書き始めるのではなく、解決済みチケット、散在するドキュメント、エージェントが毎日送っている返信など、すでに持っているソースからヘルプセンターやナレッジベースの記事を下書きします。価値はスピードではなく、チームがすでに知っていることを顧客が実際に見つけられる記事に変えることにあります。
多くのチームが間違えること:マーケティングページや社内のウィキにAIを向け、出てきたものをそのまま公開してしまう。結果はそれなりに読めるが誰にも役立たない。なぜなら、間違った読者向けに書かれているからです。優れたツールはすべての下書きを実際のコンテンツに基づいて作成し、実際に質問する人向けに書き、記事がまったく存在しないギャップにフラグを立てます。
私はeesel AIでコンテンツとSEOを担当しており、AIが実際のナレッジベースから実際のサポートチケットに答える様子を何年も見てきました。これはツールの比較記事ではありません。AIナレッジベース記事ライターが何をするのか、使う価値のあるものが実際にどのように機能するのか、そして記事が存在意義を持つためのワークフロー、さらに執筆と回答を同じソースで動かしたい場合のeeselの役割についての解説です。
AIナレッジベース記事ライターが実際にすること
マーケティングを取り除くと、仕事は限定的です:チケット、チャット、未完成のドキュメントに閉じ込められた知識を取り出し、顧客が読んでセルフサービスできるクリーンで構造化された記事に変換することです。
これは、ブログ投稿を対象とした汎用AIライターやAIコンテンツジェネレーターとは異なる仕事です。ブログ投稿は大まかに正確でも役割を果たせます。ナレッジベース記事が大まかに正確だと、チケットが発生するか、さらに悪い場合は顧客が誤った行動を取ります。つまり、まず精度、次に磨きです。
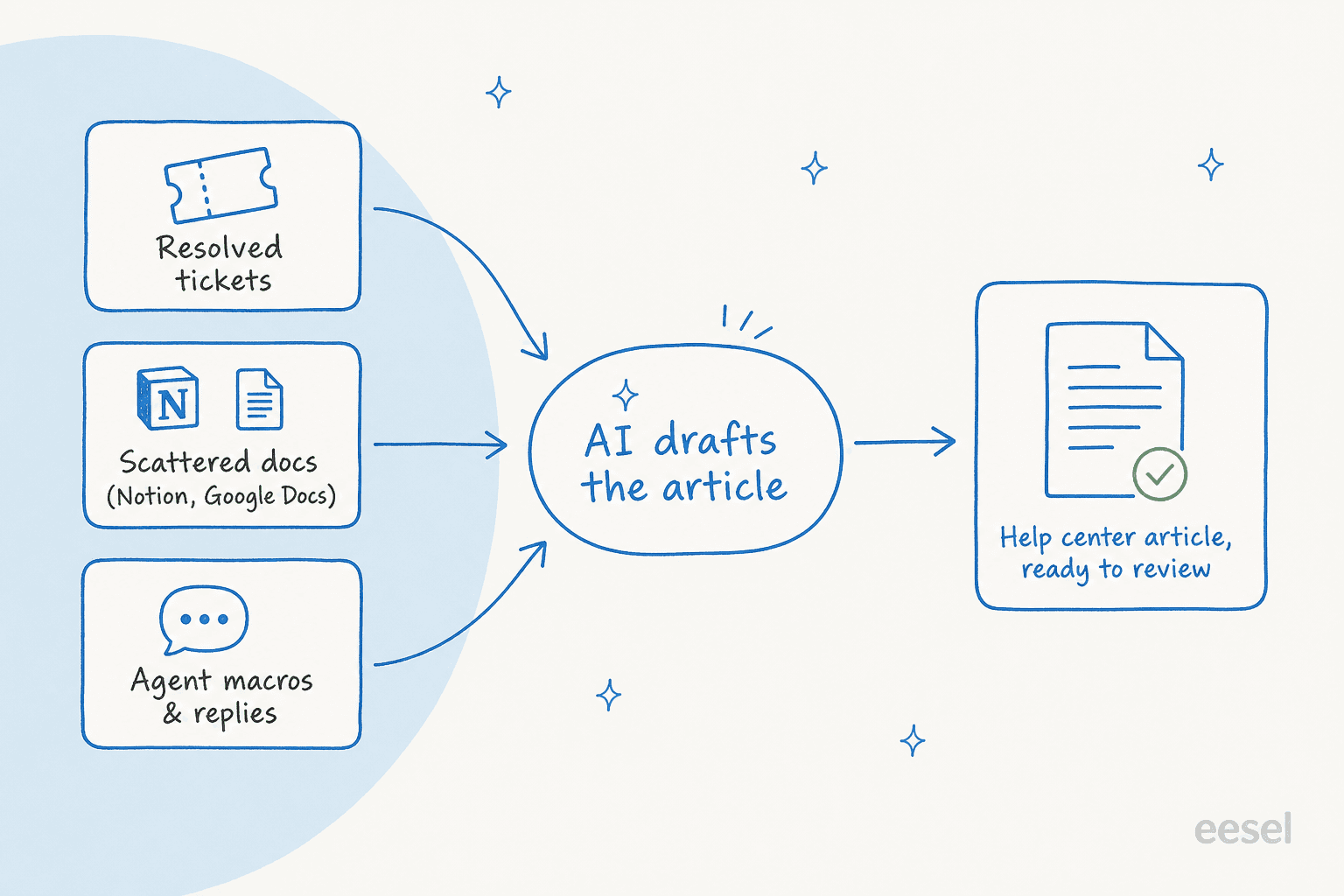
実際には、優れたライターは3つのことをします:
- 想像力ではなくソースから引き出す。 解決済みチケット、既存のヘルプセンター、NotionやGoogle Docsの社内ドキュメント、エージェントのマクロ、リリースノート。記事はすでに知っていることの再構成であり、AIが構造を担当します。
- あなたの声と形式で書く。 ハウツーにはステップリスト、FAQには短い回答、既存記事で使われている見出しとトーン。これはブランドボイストレーニングが重要な部分で、新しい記事が別の会社が書いたように読まれないようにします。
- 次に何を書くかを教えてくれる。 最良のものは顧客が検索するものやチケットで質問するものを見て、まだ記事が存在しないトピックを浮き上がらせます。
最後の点はチームが見落としがちですが、実際には時間が最も節約される部分です。
静かに全努力を無駄にする間違い
モデルの限界よりも多くのナレッジベースプロジェクトを沈めてきた失敗があります:記事が間違った読者向けに書かれるのです。
月に数百件のZendeskチケットを処理するバス追跡サービスのサポートマネージャーとの通話に参加したことがあります。彼らのナレッジベース全体が管理者向けに書かれていましたが、すべてのチケットは利用者からのものでした。ドキュメントは技術的に正確でしたが、問い合わせる人々には完全に役立たずでした。そのドキュメントにAIを向けると、管理者向けの記事をより速く生成するだけです。間違ったものを自動化してしまったことになります。
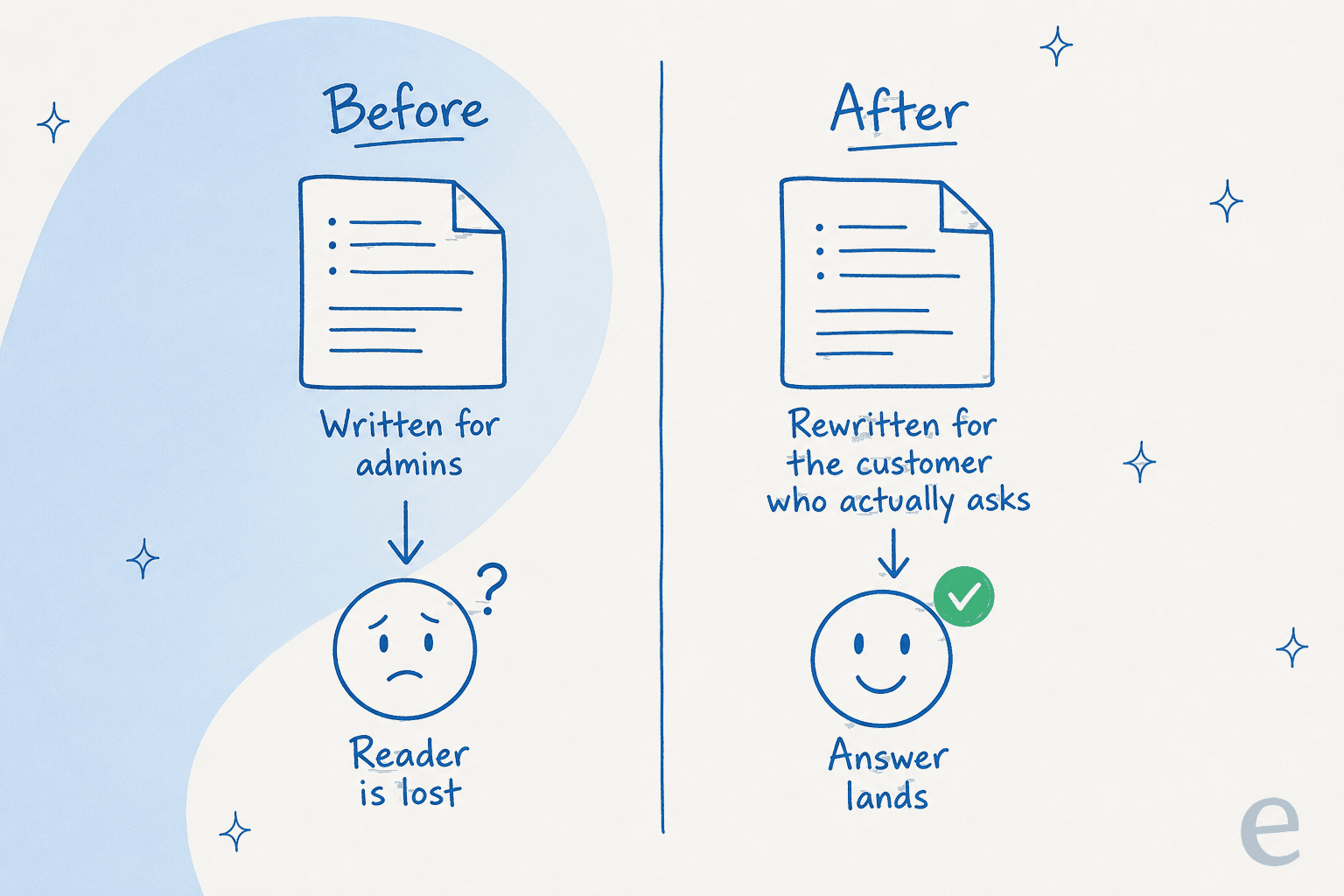
これがまさに、AIに既存のドキュメントを与えるより解決済みチケットを与える方が良い理由です。チケットには顧客自身の言葉で質問が含まれており、実際に使うフレーズ、混乱していたことが書かれています。そのソースから生成された記事は本物の質問に答えます。内部仕様から生成された記事は誰も聞かなかった質問に答えます。
ツールを評価する前に、何を読んでいるかを確認してください。現在のドキュメントのみを取り込むライターは、その中の誤りを忠実に再現します。AIナレッジベース記事ライターのポイントは、文書化したことと実際に人々が尋ねていることのギャップを埋めることであり、既存のドキュメントを増殖させることではありません。
優れたものが実際にどのように機能するか
ソースが正しければ、有用なツールと使い物にならないツールを分けるメカニズムはグラウンディングです:AIは取得したコンテンツのみから書くのか、答えが見つからないときに自分のトレーニングデータに頼るのか?
これはAIナレッジベースチャットボットを信頼できるものにするか危険なものにするかと同じ問題であり、書き込み側にも同一のリスクがあるため理解する価値があります。検索が何も返さずモデルが答えたとき、自信に満ちた架空の情報が生まれます。ナレッジベースに一致するエントリがなく、モデルが沈黙を埋めただけで、有料顧客のボットが製品に関する主張を作り上げて実際の人々に送信するのを見てきました。同じ欠陥を持つ記事ライターは、存在しない機能のハウツーを喜んで下書きします。
したがって、AIドキュメントアシスタントに重要な質問は:
- 各セクションの背後にあるソースドキュメントを引用し、レビュアーが確認できるようにしているか?
- 推測するのではなく、グラウンドされたソースがないときに拒否またはフラグを立てるか?
- どちらかだけでなく、ナレッジベースと過去のチケットの両方でトレーニングできるか?
このセクションから一つだけ持ち帰るとすれば:「このソースはありません」と認めるツールは、常に答えを持つものより価値があります。自信に満ちたものがトラブルを引き起こします。
自分で作るか、購入するか?
エンジニアがいる場合、特に公正な質問です:なぜOpenAIやClaude APIをドキュメントに接続して自分で作らないのか?ConfluenceとTelegramにeesel AIを接続するGENERAL BYTESのKarelは、トレードオフを率直に述べました:
「独自のLLMアプリケーションを書こうとすることはできましたが、その時間を投資したくありませんでした。メンテナンスが不要なものが欲しかったのです。」
Karel、GENERAL BYTES(ケーススタディ)
これが正直な計算です。検索と書き込みのパイプラインの最初の下書きは週末でできます。ドキュメントが変わり、製品がリリースされ、エッジケースが積み重なっても正確に保つことは永続的な仕事です。ほとんどのチームにとって、メンテナンスがコストであり、構築ではありません。
保持する価値のある記事を生成するワークフロー
ツールは別として、実際に実行するループはこれです。専用ツールを使うか、AIによる文章支援を手動で組み合わせるかに関わらず機能します。
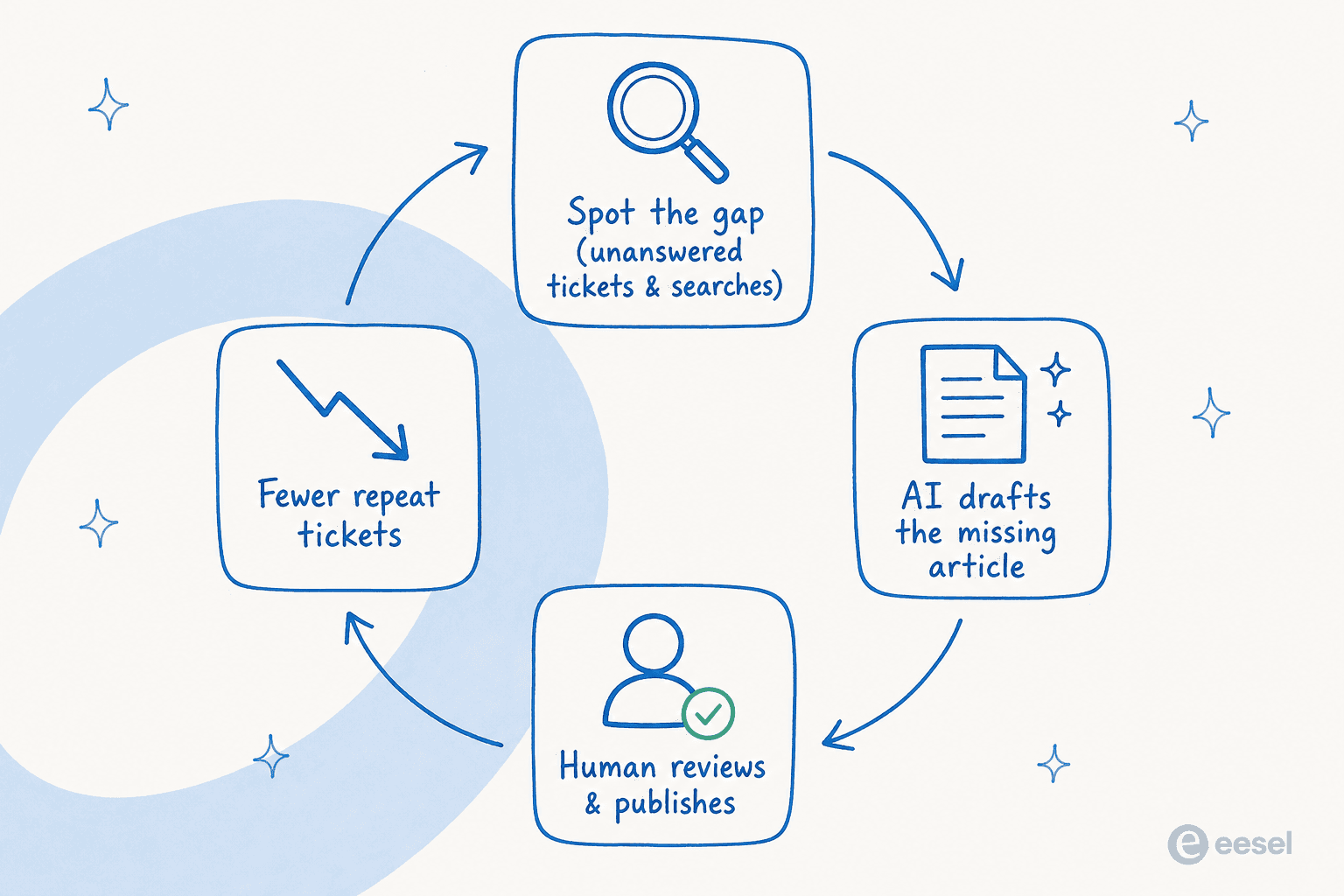
- 書く前にギャップを見つける。 コンテンツカレンダーからではなく、需要から始めます。繰り返し来るチケットとヘルプセンターのギャップにヒットした検索クエリを引き出します。それらが記事トピックであり、引き起こしている痛みの度合いでランク付けされます。
- 仕様書ではなく解決済みチケットから下書きする。 エージェントが解決した実際の会話をAIに与えます。エージェントがすでに書いた返信は、顧客の言葉で記事の80%になります。
- レビューに人間を置く。 AIが下書きし、人が承認します。これは形式的なことではなく、間違った数字や前回のリリースで変わったステップをキャッチする場所です。レビュアーは事実を確認すべきで、文章を書き直すのではありません。
- サポートがすでに読んでいるソースに公開する。 記事はエージェントとボットの両方が見られる場合のみチケットを偏向させます。それが執筆と回答を一つのプラットフォームに保つ理由です。
- スケジュールに従って更新する。 AIを使って古いヘルプセンターコンテンツにフラグを立て、顧客が壊れた記事を見つける前に古い記事を修正します。これがナレッジベースと墓場の違いです。
そのループを実行すると、記事数が指標でなくなります。繰り返しチケットの減少が指標になります。
あなたのチームに合うアプローチは?
ほとんどのチームはボリュームと知識がどこにあるかによって、3つのいずれかに落ち着きます。簡単な確認:
今、あなたの知識はどこにありますか?
うまくいかない場合
予測可能なため、いくつかの落とし穴を挙げておきます:
- 誰も管理しない古いコンテンツ。 AIは執筆を安くするため、200記事を公開して一つも更新しないことが簡単になります。古い大きなナレッジベースは、最新の小さなものより悪い。これは本質的にナレッジベース管理の問題であり、静かにダメージを与えます。
- 読者層のずれ。 上記で取り上げましたが再発します:数ヶ月ごとに、新しい記事が製品チームの言葉ではなく顧客がどう表現するかと一致しているか確認します。
- ウィキが沼になる。 社内ドキュメントと顧客向け記事は異なる仕事です。内部ナレッジベースも管理している場合は、二つを明確に分離してください。さもなければ、AIが社内の専門用語を公開記事に混ぜ込みます。
- 単一ソースへのこだわり。 ドキュメントのみ読むライターはチケットを見逃し、チケットのみ読むライターはリリースノートを見逃します。強いサポートチーム向けAIナレッジ管理はすべてから同時に引き出します。
これらはいずれもモデルの問題ではありません。プロセスの問題であり、ループを機能の中に組み込んだツールがほとんどから救ってくれます。
執筆と回答にeeselを試す
記事執筆とチケット回答を同じ仕組みで動かしたい場合、それがeesel AIの賭けです。ヘルプデスクとドキュメントに接続し、Zendesk、HubSpot、Confluence、Jiraなど、過去のチケットから学習し、推測ではなくそのコンテンツに基づいた返信と記事を下書きします。
この投稿全体に結びつく部分:記事を下書きするのと同じエンジンがチケットにも答えるため、ギャップが自然に浮き上がります。AIが自信を持って何かに答えられないとき、それが次の記事であり、すでに特定されています。ある顧客はeesel AIを使って本当に大きなナレッジベースの管理をまさにこのように行っており、別のチームはエージェントがNotionやGoogle Docsを掘り返すのをやめたと話してくれました。AIが検索を代わりにしてくれるからです。
既存のスタックに接続し、チケットとドキュメントに向け、コミットする前に実際の履歴に基づいた下書きを見ることができます。無料で試せ、ヘルプセンターをすでに読んだチームメンバーのように機能します。まだオプションを比較中なら、AIナレッジベースツールとナレッジ管理ソフトウェアの比較記事がフィールドを概説しており、AIパワードナレッジベースのメリットについての考えがその理由をカバーしています。


