Rédacteur d'articles de base de connaissances IA : comment vraiment l'utiliser (2026)
Kurnia Kharisma Agung Samiadjie
Katelin Teen
Dernière modification June 23, 2026

Résumé
Un rédacteur d'articles de base de connaissances IA rédige des articles de centre d'aide et de base de connaissances à partir de sources que vous possédez déjà, comme les tickets résolus, les docs épars et les réponses que vos agents envoient chaque jour, au lieu d'écrire depuis une page blanche. La valeur n'est pas la vitesse, c'est de transformer ce que votre équipe sait déjà en articles que vos clients peuvent vraiment trouver.
L'erreur que commettent la plupart des équipes : elles pointent une IA sur une page marketing ou leur propre wiki interne et publient ce qui en sort. Le résultat se lit bien et n'aide personne, parce qu'il est écrit pour le mauvais lecteur. Les bons outils ancrent chaque brouillon dans votre contenu réel, écrivent pour la personne qui pose vraiment la question, et signalent les lacunes là où vous n'avez aucun article du tout.
Je travaille sur le contenu et le SEO chez eesel AI, et nous avons passé des années à observer l'IA répondre à de vrais tickets d'assistance depuis de vraies bases de connaissances. Ce n'est donc pas un comparatif d'outils. C'est ce que fait un rédacteur d'articles de base de connaissances IA, comment fonctionnent vraiment ceux qui en valent la peine, et un flux de travail pour obtenir des articles qui méritent leur place, plus où eesel s'inscrit si vous voulez que la rédaction et les réponses s'appuient sur la même source.
Ce que fait vraiment un rédacteur d'articles de base de connaissances IA
Derrière le marketing, le travail est simple : prendre les connaissances enfouies dans les tickets, les chats et les docs à moitié rédigés, et les transformer en un article clair et structuré qu'un client peut lire et utiliser pour se débrouiller seul.
C'est un travail différent d'un rédacteur IA généraliste ou d'un générateur de contenu IA orienté articles de blog. Un article de blog peut être approximativement exact et faire son travail quand même. Un article de base de connaissances approximativement exact génère un ticket, ou pire, une mauvaise action de la part du client. La priorité est donc d'abord la précision, ensuite la forme.
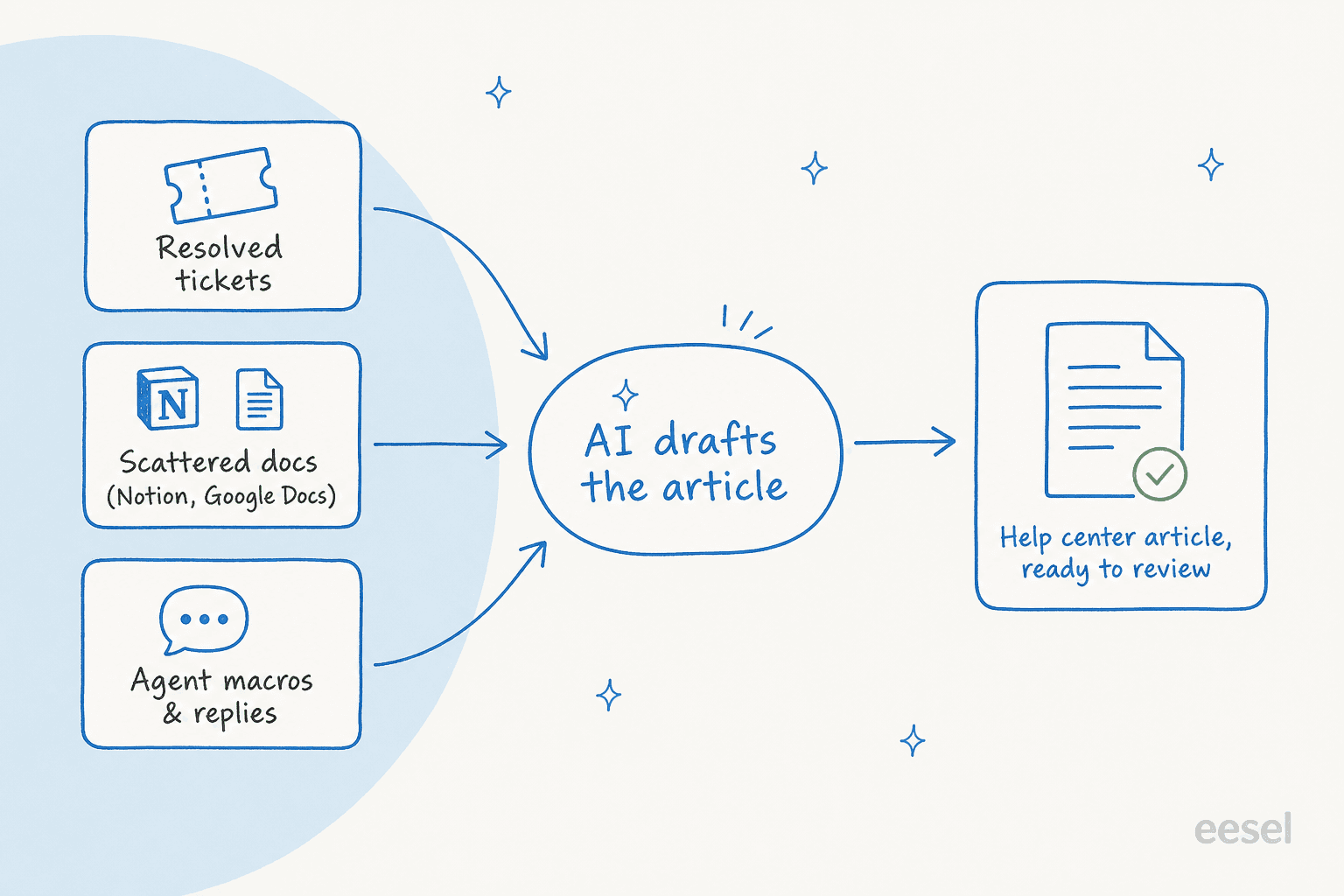
En pratique, un bon rédacteur fait trois choses :
- Il puise dans vos sources, pas dans son imagination. Tickets résolus, votre centre d'aide existant, docs internes dans Notion ou Google Docs, macros des agents, notes de mise à jour. L'article est une restructuration de ce que vous savez déjà, l'IA se chargeant de la structure.
- Il écrit dans votre style et votre format. Listes d'étapes pour les guides pratiques, réponses courtes pour les FAQ, les titres et le ton de vos articles existants. C'est là qu'intervient la formation à la voix de marque, pour qu'un nouvel article ne donne pas l'impression d'avoir été écrit par une autre entreprise.
- Il vous dit quoi écrire ensuite. Les meilleurs examinent ce que les clients recherchent et ce qu'ils demandent dans les tickets, puis font remonter les sujets sur lesquels vous n'avez encore aucun article.
Ce dernier point est celui que les équipes négligent, et c'est généralement là que le temps est vraiment économisé.
L'erreur qui gâche silencieusement tout l'effort
Voici l'échec que j'ai vu faire couler plus de projets de base de connaissances que n'importe quelle limitation de modèle : les articles sont rédigés pour le mauvais lecteur.
J'ai participé à des appels avec un responsable d'assistance d'un service de suivi de bus gérant quelques centaines de tickets Zendesk par mois, dont toute la base de connaissances était rédigée pour les administrateurs, alors que chaque ticket émanait de passagers. Les docs étaient techniquement précis et totalement inutiles pour les personnes qui écrivaient. Une IA pointée sur ces docs produit simplement plus d'articles pour les administrateurs, plus vite. Vous avez automatisé la mauvaise chose.
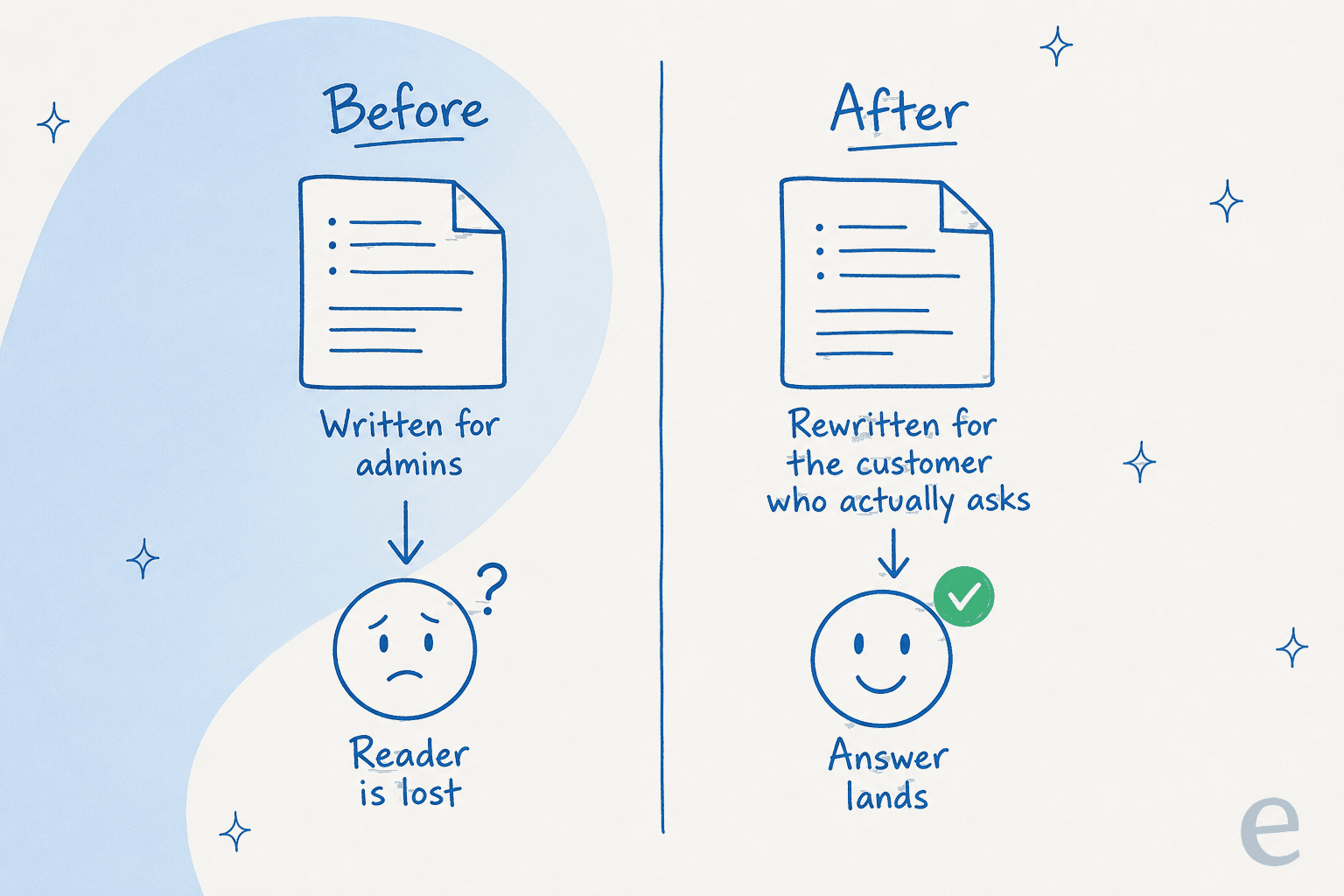
C'est exactement pourquoi alimenter l'IA avec vos tickets résolus est plus efficace que de lui soumettre vos docs existants. Les tickets portent la question dans les propres mots du client, la formulation qu'il utilise vraiment, le point sur lequel il était confus. Un article généré depuis cette source répond à la vraie question. Un article généré depuis un cahier des charges interne répond à une question que personne n'a posée.
Avant de juger n'importe quel outil, vérifiez donc ce qu'il lit. Un rédacteur qui n'ingère que vos docs actuels reproduira fidèlement tout ce qui ne va pas avec eux. L'objectif d'un rédacteur d'articles de base de connaissances IA est de combler l'écart entre ce que vous avez documenté et ce que les gens demandent vraiment, pas de multiplier vos docs existants.
Comment fonctionnent vraiment les bons outils
Une fois les sources correctes, le mécanisme qui sépare un outil utile d'un jouet est l'ancrage : l'IA écrit-elle uniquement à partir du contenu récupéré, ou se rabat-elle sur ses données d'entraînement quand elle ne trouve pas de réponse ?
C'est le même problème qui rend un chatbot de base de connaissances IA fiable ou dangereux, et cela vaut la peine d'être compris parce que le côté rédaction présente un risque identique. Quand la récupération ne renvoie rien et que le modèle répond quand même, on obtient de la fiction assurée. Nous avons vu des bots de clients payants inventer des affirmations produit et les envoyer à de vraies personnes, simplement parce que la base de connaissances n'avait pas d'entrée correspondante et que le modèle a comblé le silence. Un rédacteur avec le même défaut rédigera volontiers un guide pratique pour une fonctionnalité qui n'existe pas.
Voici donc les questions importantes pour tout assistant de documentation IA :
- Cite-t-il le document source derrière chaque section, pour qu'un relecteur puisse le vérifier ?
- Décline-t-il, ou signale-t-il, quand il n'a pas de source ancrée plutôt que de deviner ?
- Peut-il s'entraîner sur votre base de connaissances et vos tickets passés ensemble, pas seulement l'un ou l'autre ?
Si vous ne retenez qu'une chose de cette section : un outil qui admet « Je n'ai pas de source pour cela » vaut plus qu'un outil qui a toujours une réponse. C'est le plus sûr de lui qui vous causera des ennuis.
Construire soi-même ou acheter ?
Une question légitime, surtout si vous avez des ingénieurs : pourquoi ne pas brancher l'API OpenAI ou Claude sur vos docs et écrire votre propre système ? Karel chez GENERAL BYTES, qui connecte eesel AI à Confluence et Telegram, a résumé le compromis clairement :
« Nous aurions pu essayer de développer notre propre application LLM, mais nous ne voulions pas y investir notre temps. Nous voulions quelque chose que nous n'aurions pas à maintenir. »
Karel, GENERAL BYTES (étude de cas)
C'est le calcul honnête. Le premier brouillon d'un pipeline de récupération et de rédaction se fait en un week-end. Maintenir sa précision à mesure que vos docs changent, que votre produit évolue et que vos cas limites s'accumulent est un travail permanent. Pour la plupart des équipes, la maintenance est le coût, pas la construction.
Un flux de travail qui produit des articles qui méritent d'être conservés
Outils mis à part, voici la boucle que j'appliquerais vraiment. Elle fonctionne que vous utilisiez un outil dédié ou que vous assembliez une aide IA pour la rédaction à la main.
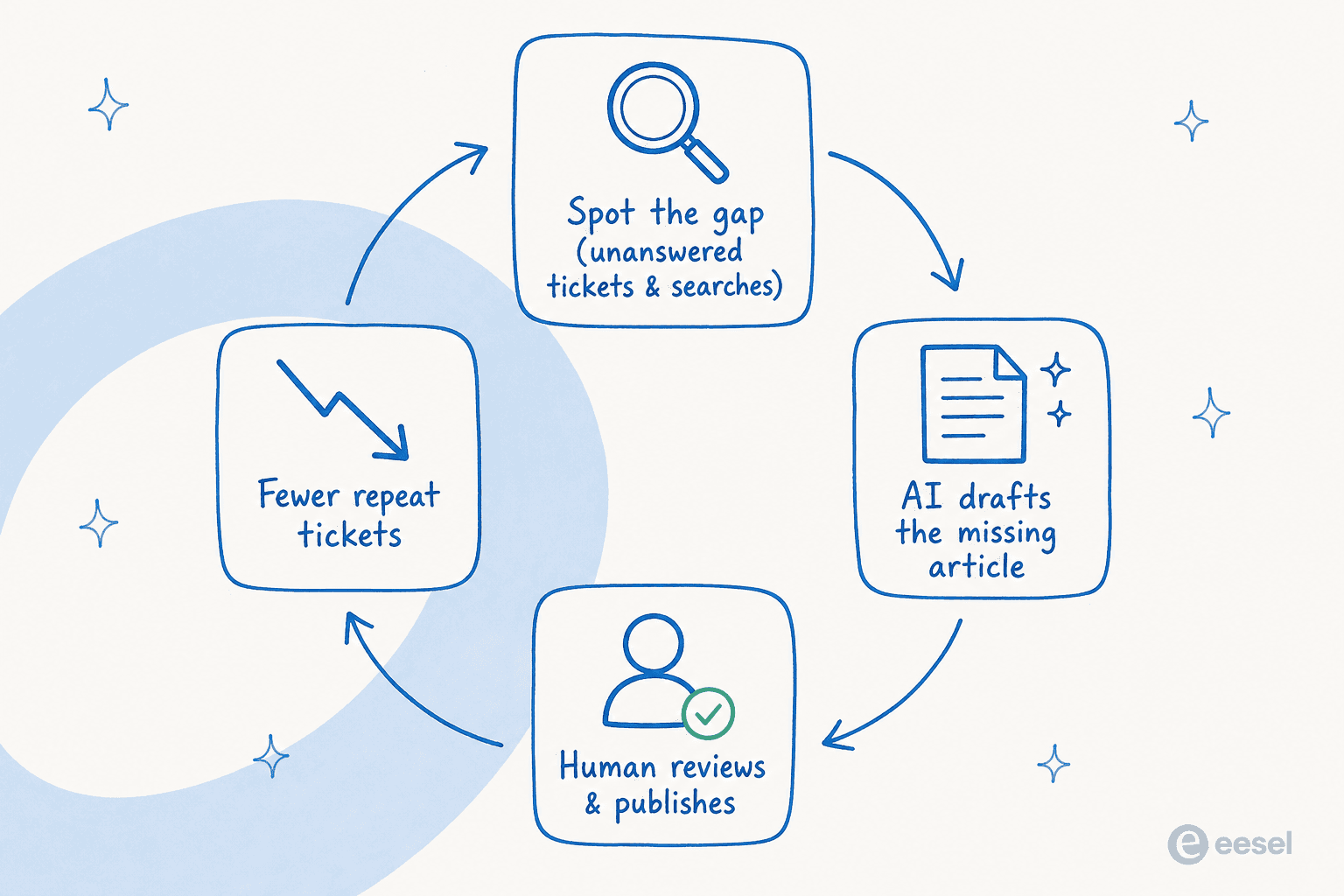
- Trouvez la lacune avant d'écrire. Ne partez pas d'un calendrier éditorial, partez de la demande. Récupérez les tickets qui reviennent sans cesse et les requêtes de recherche qui tombent dans une lacune du centre d'aide. Ce sont vos sujets d'articles, classés par niveau de douleur qu'ils causent.
- Rédigez à partir du ticket résolu, pas du cahier des charges. Alimentez l'IA avec la vraie conversation où un agent l'a résolue. La réponse que votre agent a déjà écrite constitue 80 % de l'article, dans le langage du client.
- Gardez un humain dans le siège de relecteur. L'IA rédige, une personne approuve. Ce n'est pas une formalité, c'est là que vous repérez le chiffre erroné ou l'étape qui a changé à la dernière mise à jour. Le relecteur doit vérifier les faits, pas réécrire la prose.
- Publiez dans la source que votre assistance lit déjà. Un article ne déflecte les tickets que si vos agents et votre bot peuvent tous les deux le voir. C'est l'argument pour maintenir la rédaction et les réponses sur une même plateforme.
- Actualisez selon un calendrier. Utilisez l'IA pour signaler le contenu de centre d'aide obsolète afin de corriger l'article périmé avant qu'un client ne le trouve. C'est la différence entre une base de connaissances et un cimetière.
Faites tourner cette boucle et le nombre d'articles cesse d'être la métrique. La baisse des tickets répétitifs, elle, l'est.
Quelle approche convient à votre équipe ?
La plupart des équipes se retrouvent dans l'une de ces trois situations selon le volume et l'endroit où leurs connaissances se trouvent déjà. Un rapide test :
Où se trouvent vos connaissances en ce moment ?
Là où ça se passe mal
Quelques écueils à nommer, car ils sont prévisibles :
- Contenu obsolète que personne ne possède. L'IA rend la rédaction bon marché, ce qui signifie qu'il est facile de publier 200 articles et de n'en mettre aucun à jour. Une base de connaissances plus grande mais périmée est pire qu'une petite qui est à jour. C'est vraiment un problème de gestion de la base de connaissances, et c'est celui qui mord discrètement.
- Dérive du lectorat. Nous l'avons évoqué plus haut, mais il revient : tous les quelques mois, vérifiez que les nouveaux articles correspondent encore à la façon dont les clients s'expriment, et non à celle de votre équipe produit.
- Le wiki qui devient un marécage. Les docs internes et les articles destinés aux clients sont deux travaux différents. Si vous gérez aussi une base de connaissances interne, séparez clairement les deux, sinon votre IA mélangera du jargon interne dans des articles publics.
- La vision tunnel mono-source. Un rédacteur qui ne lit que les docs rate les tickets ; un qui ne lit que les tickets rate vos notes de mise à jour. Une solide gestion des connaissances par IA pour les équipes d'assistance puise dans tout à la fois.
Aucun de ces problèmes n'est lié au modèle. Ce sont des problèmes de processus, et un outil qui intègre la boucle dans son fonctionnement vous en préserve en grande partie.
Essayez eesel pour la rédaction et les réponses
Si vous voulez que la rédaction d'articles et les réponses aux tickets s'appuient sur le même cerveau, c'est le pari que fait eesel AI. Il se connecte à votre service d'assistance et à vos docs, que ce soit Zendesk, HubSpot, Confluence, ou Jira, apprend de vos tickets passés et rédige des réponses et des articles ancrés dans ce contenu plutôt que de deviner.
Le point qui relie tout cet article : parce que le même moteur qui rédige des articles répond aussi aux tickets, les lacunes remontent naturellement. Quand l'IA ne peut pas répondre avec confiance à quelque chose, c'est votre prochain article, déjà identifié. Un client gère une base de connaissances vraiment grande avec eesel AI en faisant exactement cela, et une autre équipe nous a dit que ses agents avaient complètement arrêté de fouiller dans Notion et Google Docs parce que l'IA fait la récupération à leur place.
Vous pouvez le brancher à votre stack existant, le pointer sur vos tickets et docs, et le regarder rédiger à partir de votre vrai historique avant de vous engager. C'est gratuit à essayer, et ça fonctionne comme un coéquipier qui a déjà lu votre centre d'aide. Si vous comparez encore vos options, notre tour d'horizon des outils de base de connaissances IA et des logiciels de gestion des connaissances couvre le marché, et notre analyse des avantages d'une base de connaissances propulsée par l'IA explique le pourquoi.








Comment éviter que les articles rédigés par IA deviennent obsolètes ?