Resumen (TL;DR)
Qwen-Turbo ($0.05/1M entrada) es una de las APIs de texto competentes más baratas que existen. Qwen-Plus ($0.40/1M) es el punto de equilibrio de valor para la mayoría de las cargas de trabajo de producción: 9 veces más barato que Claude Opus 4.6 con una calidad comparable para una amplia gama de tareas. En el nivel Max, los precios de Qwen suben hacia el territorio de los modelos de vanguardia occidentales, por lo que la idea de que es "siempre más barato" solo se mantiene por debajo de esa línea. El acceso gratuito a la API para desarrolladores desapareció en abril de 2026; lo que queda es una prueba de incorporación de 70 millones de tokens y una aplicación de chat para consumidores permanentemente gratuita. Auto-hospedar cualquier modelo Qwen3 sigue siendo el costo mínimo real: cero por token. Si estás construyendo en eesel y necesitas ejecutar flujos de trabajo potenciados por IA a escala sin una factura por asiento, entender dónde Qwen realmente supera a las alternativas - y dónde no - te ahorrará dinero real.
¿Qué es Qwen? (y por qué es diferente)
Qwen (通义千问) es la familia de modelos de lenguaje de gran tamaño de Alibaba Cloud: un catálogo extenso de más de 145 IDs de modelos que abarcan texto, visión, audio, código, traducción, generación de video y embeddings, todos accesibles bajo una sola clave API a través de Qwen Cloud / Alibaba Cloud Model Studio.
Tres cosas lo hacen inusual en el mercado de LLM:
- Modelos de pesos abiertos junto a los propietarios. Toda la serie Qwen3 (desde 0.6B hasta 235B-A22B) tiene licencia Apache 2.0 y está disponible en Hugging Face. Puedes ejecutar localmente y de forma gratuita el mismo modelo por el que pagarías en la API.
- La arquitectura MoE domina el nivel medio. La mayor parte del precio competitivo de Qwen proviene del diseño de Mezcla de Expertos (MoE): el modelo 235B-A22B activa solo 22B parámetros por token, lo que hace que su costo de inferencia sea similar al de un modelo denso de 22B a pesar de su escala total de 235B.
- Volumen a una escala que pocos proveedores igualan. Qwen3.6-Plus fue el primer modelo en OpenRouter en procesar más de 1 billón de tokens en un solo día, una señal de cuánto se ha desplazado la adopción de los desarrolladores hacia la familia Qwen.
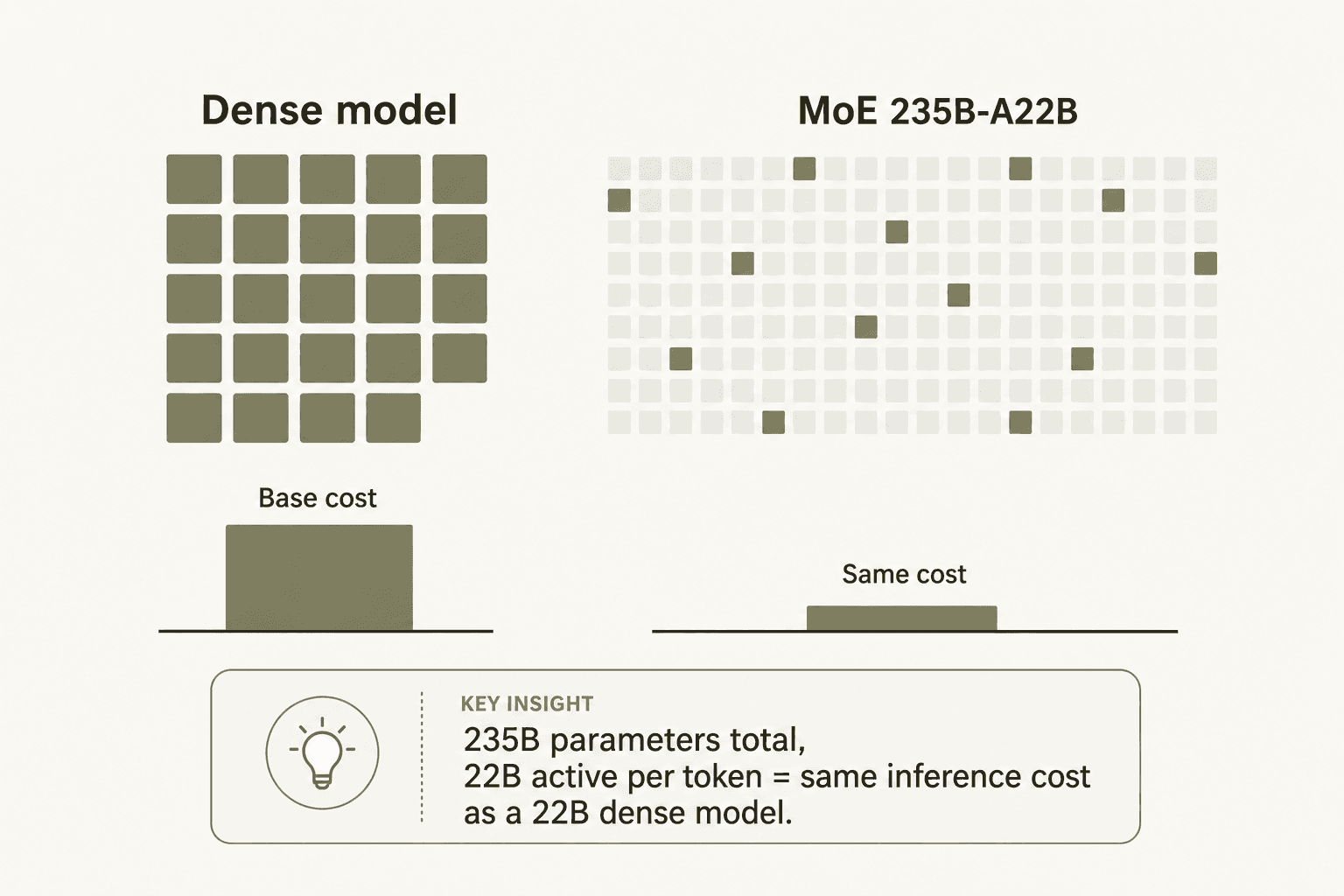
"The MoE Design: Most MoE models feel like bolt-ons. Qwen 3.5's sparse activation is native - only 4.3% of parameters fire per token. That's how you get trillion-parameter-class performance without trillion-parameter inference costs. The 0.8 RMB/million tokens pricing isn't subsidized; it's structurally earned."
Tabla completa de precios de la API de Qwen (2026)
Todos los precios están en USD, bajo el modelo de pago por uso en el endpoint internacional (Alibaba Cloud Model Studio, ap-southeast-1). Precios obtenidos de las páginas de detalles de modelos de Qwen Cloud y PricePerToken.com (verificado el 3 de junio de 2026).
Modelos de generación de texto
| Modelo | Entrada $/1M | Salida $/1M | Contexto | Notas |
|---|---|---|---|---|
| Qwen3.7-Max | $1.25 | $3.75 | 1M tokens | 50% de descuento sobre el precio de lista de $2.50/$7.50; solo texto; lanzado el 21-05-2026 |
| Qwen3.7-Plus | $0.32–$0.96 | $1.28–$3.84 | 1M tokens | Multimodal nativo; niveles por longitud de contexto; lanzado el 01-06-2026 |
| Qwen3-Max | $1.20 | $6.00 | 262K tokens | Optimizado para agentes; lectura de caché $0.12/1M |
| Qwen3.6-Plus | $0.50–$2.00 | $3.00–$6.00 | 1M tokens | Multimodal nativo; programación agéntica; visual + texto |
| Qwen3.6-Flash | $0.25–$1.00 | $1.50–$4.00 | 1M tokens | Visión-lenguaje optimizado por costo |
| Qwen3-235B-A22B | $0.70 | $2.80 / $8.40* | 131K tokens | Insignia de pesos abiertos MoE; *modo de pensamiento |
| Qwen3-30B-A3B | $0.20 | $0.80 / $2.40* | 131K tokens | MoE equilibrado; *modo de pensamiento |
| Qwen3-8B | $0.18 | $0.70 / $2.10* | 131K tokens | Denso pequeño; *modo de pensamiento |
| Qwen-Max | $1.60 | $6.40 | 32K tokens | Alias estable para producción |
| Qwen-Plus | $0.40 | $1.20 / $4.00* | 1M tokens | Alias estable; *modo de pensamiento |
| Qwen-Turbo | $0.05 | $0.20 / $0.50* | 131K tokens | Nivel de texto más barato; rendimiento de 5M TPM; *modo de pensamiento |
| Qwen3.5-0.8B | $0.01 | $0.05 | - | Mínimo absoluto; tareas de micro-automatización |
*La salida del modo de pensamiento se factura a la tarifa más alta cuando enable_thinking: true.
Modelos multimodal y de visión-lenguaje
| Modelo | Entrada $/1M | Salida $/1M | Contexto |
|---|---|---|---|
| Qwen3-VL-Plus | $0.20 | $1.60 | 262K tokens |
Modelos de embeddings
| Modelo | Precio |
|---|---|
| text-embedding-v3 / text-embedding-v4 | $0.07/1M tokens; $0.035/1M por lotes (batch) |
Modelos de generación de video
| Modelo | Precio |
|---|---|
| Serie HappyHorse-1.0 (T2V, I2V, R2V, edit) | $0.112/segundo |
| Wan2.7-T2V | $0.10/segundo |
Los rangos de precios en Qwen3.7-Plus y la serie Qwen3.6 reflejan niveles de entrada escalonados: el costo por millón de tokens aumenta a medida que crece la longitud de la entrada dentro de una sola solicitud (no es uso acumulativo). La tarifa de $0.32 se aplica a entradas cortas; los $0.96 se activan para solicitudes de contexto largo en Qwen3.7-Plus.
Cómo funciona realmente la facturación
Entender la tabla de tarifas es el primer paso. Entender cómo se combinan esas tarifas en una carga de trabajo real es donde la gente se lleva sorpresas.
Modo de pensamiento
Varios modelos de la generación Qwen3 admiten un parámetro opcional enable_thinking: true que activa el razonamiento de cadena de pensamiento antes de dar la respuesta final. Los tokens de pensamiento se generan internamente y luego se facturan, a tarifas que suelen ser de 3 a 10 veces superiores a la salida estándar. En Qwen-Plus, por ejemplo, la salida estándar cuesta $1.20/1M pero la salida de pensamiento cuesta $4.00/1M. En Qwen3-235B-A22B, la salida de pensamiento salta de $2.80 a $8.40/1M.
Para la mayoría de las cargas de trabajo de producción (clasificación, resumen, extracción estructurada), el modo de pensamiento es excesivo. Actívalo solo para tareas que requieran mucho razonamiento (revisión de código complejo, planificación de múltiples pasos, matemáticas) y ajusta tu presupuesto en consecuencia cuando lo hagas.
Almacenamiento en caché de prompts
El almacenamiento en caché de prompts implícito es automático en la mayoría de los modelos de Qwen: los prefijos de contexto repetidos se almacenan en caché y los aciertos de caché se facturan a aproximadamente el 20% de la tarifa de entrada estándar. Para Qwen-Plus, eso es $0.08/1M en lugar de $0.40/1M en las partes almacenadas en caché.
También hay una gestión de caché explícita disponible en Qwen3-Max y Qwen-Plus:
- Creación de caché: ~$0.50/1M (125% de la tarifa de entrada)
- Lectura de caché: ~$0.04/1M (10% de la tarifa de entrada)
El inconveniente señalado constantemente en la comunidad: el almacenamiento en caché de Qwen acierta con menos fiabilidad que el de sus competidores. Un usuario de Reddit ejecutó la misma tarea de revisión de código en cuatro interfaces de línea de comandos (CLI) de IA y descubrió que Qwen consumió el 23% de su cuota mensual de $30 en una sola tarea; la misma tarea consumió menos del 1% de planes comparables de $100 de Claude y OpenAI. El diagnóstico explícito fue: "No parecen almacenar en caché tan bien como otros proveedores de modelos".
Procesamiento por lotes (batch)
La API de lotes asíncrona ofrece aproximadamente un 50% de descuento sobre las tarifas estándar para cargas de trabajo que no son en tiempo real. En Qwen3-Max, la entrada por lotes baja de $1.20 a $0.60/1M; la salida por lotes de $6.00 a $3.00/1M. Para canalizaciones ETL, trabajos de clasificación masiva o generación de informes nocturnos, el modo por lotes es la opción predeterminada correcta.
Planes de ahorro
Alibaba Cloud ofrece Planes de Ahorro de IA con hasta un 47% de reducción de costos mediante el compromiso de uso. También hay un Plan de Tokens de IA (créditos de suscripción fijos entre modelos), pero la experiencia de la comunidad con esto es mixta (ver Lo que realmente pagas, a continuación).
Lo que realmente pagas en la práctica
Los precios de lista y las facturas reales divergen. Aquí hay tres ejemplos prácticos basados en datos del mundo real.
Ejemplo 1: una canalización de contenido a 10,000 tareas/día
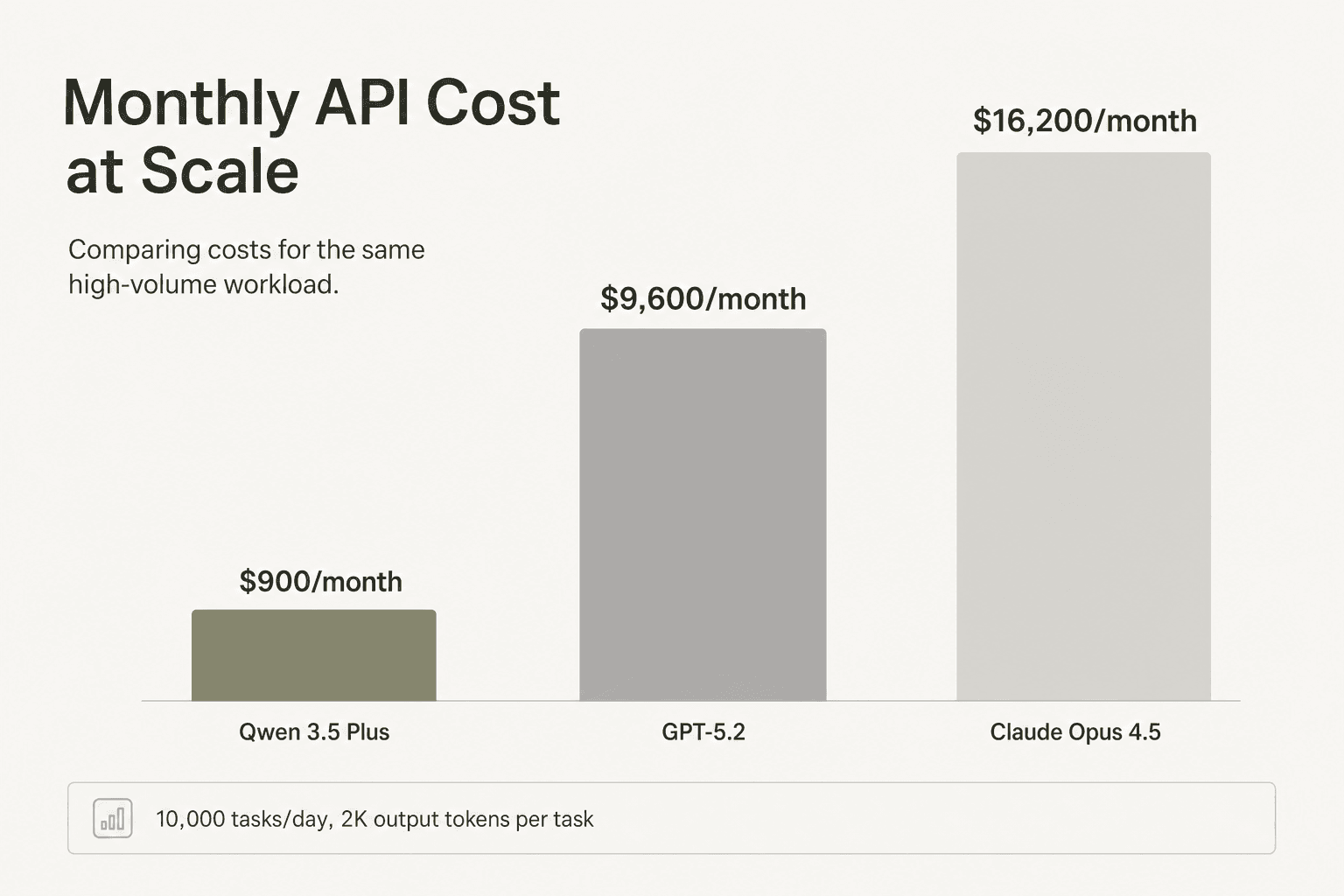
ChartGen AI comparó Qwen 3.5 frente a GPT-5.2 frente a Claude Opus 4.5 en 20 tareas de visualización de datos, cada una de las cuales requería aproximadamente 2,000 tokens de salida. La economía a 10,000 tareas al día:
| Modelo | Costo por tarea | Costo diario | Costo mensual |
|---|---|---|---|
| Qwen 3.5-35B-A3B | ~$0.003 | ~$30 | ~$900 |
| GPT-5.2 | ~$0.032 | ~$320 | ~$9,600 |
| Claude Opus 4.5 | ~$0.054 | ~$540 | ~$16,200 |
Qwen obtuvo una puntuación de 163/200 en el benchmark frente a los 178/200 de GPT-5.2: una brecha de calidad del 9% con una reducción de costos de 10 veces.
El equipo de ChartGen también destacó el multiplicador multi-agente:
"In ChartGen AI's pipeline, a single dashboard generation invokes the model 5-8 times... At this scale, you can run 10 Qwen 3.5 agents for the price of 1 GPT-5.2 call - and use ensemble voting to exceed any single model's accuracy."
Steven Cen, ChartGen AI [Fuente]
Ejemplo 2: la prueba de infraestructura del Intelligence Index
Artificial Analysis pasó a Qwen3.6 Plus por su benchmark completo del Intelligence Index. Costo total:
- Qwen3.6 Plus: $483 (~100M de tokens de salida a $0.50/$3.00)
- Claude Opus 4.6 (esfuerzo máximo): $4,970
Eso es una diferencia de costo de 10 veces para una brecha de solo 2 puntos en la puntuación de inteligencia (Qwen3.6 Plus obtuvo 51 frente a 53 de Claude Opus 4.6 en su índice). La advertencia: Qwen generó notablemente más tokens de salida por tarea que sus pares, lo que infló los costos en comparación con un modelo menos verboso con la misma tarifa por token.
Ejemplo 3: la sorpresa por el precio del Plan de Tokens
La oferta de suscripción más reciente de Qwen, el Plan de Tokens de IA, convierte dólares en créditos de formas que confundieron a muchos de los primeros usuarios. De un hilo de Reddit de mayo de 2026:
"I signed up for the $30 plan (which offers 25,000 credits)... in just 4 hours of use [with Qwen 3.6 Plus], [I burned through] approximately 8,000 credits (out of a total of 25,000 credits in the $30 plan)."
La comparación directa del usuario qu1etus es demoledora para el Plan de Tokens específicamente:
"qwen3.7-max (using qwen cli - $30 plan): used 23% of my monthly quota. gpt-5.5 xhigh (using codex cli - $100 plan): used <1% of monthly quota. opus 4.7 (using claude code - $100 plan): used <1% of monthly quota. For the cost though, I'm out. They do not appear to cache as well as other model providers and their pricing model is broken."
La tarifa bruta de la API de pago por uso es mejor de lo que sugiere el cálculo del Plan de Tokens. Si estás comparando Qwen con Claude u OpenAI, cíñete a los precios de la API por token en lugar de a los niveles del plan de suscripción.
Niveles de precios de Qwen: elegir el modelo adecuado
No todas las cargas de trabajo necesitan el nivel Max. La decisión sobre la arquitectura suele importar más que la generación del modelo.

Qwen-Turbo ($0.05/$0.20): la opción correcta para clasificación, enrutamiento, extracción y cualquier carga de trabajo donde necesites rendimiento a bajo costo. Con un límite de velocidad de 5 millones de tokens por minuto, maneja canalizaciones por lotes agresivas sin alcanzar los topes. Un usuario de Reddit lo dijo sin rodeos: "A siete centavos por millón de tokens, parece trampa".
Qwen3-30B-A3B ($0.20/$0.80): la opción MoE equilibrada. El 30B-A3B activa solo 3B de parámetros en la inferencia, funciona a ~137 tokens/segundo en una sola GPU H20 y cubre la gran mayoría de las tareas de programación y razonamiento que no necesitan la capacidad del nivel Max. El consenso de la comunidad en r/LocalLLaMA: la variante MoE de 35B-A3B funciona 15 veces más rápido que la densa de 27B a una fracción del costo; elige siempre el MoE si hay uno en tu tamaño objetivo.
Qwen-Plus ($0.40/$1.20): el alias estable para producción con contexto de 1M. Si necesitas un ID de API predecible que no cambie entre actualizaciones de modelos, este es el indicado. Modo de pensamiento disponible a $4.00/1M de salida.
Qwen3.7-Plus ($0.32–$0.96/$1.28–$3.84): la opción multimodal nativa con contexto de 1M y capacidades de programación agéntica. Ideal para canalizaciones que mezclan texto, imágenes y llamadas a herramientas en la misma solicitud.
Qwen3-Max / Qwen3.7-Max ($1.20–$1.25 / $6.00–$3.75): acercándose al territorio de los precios de vanguardia. La comunidad descubrió que la variante Coder MoE de 480B a menudo tiene más sentido que Max para programación pesada a $1.50/$7.50, a menos que necesites específicamente la optimización de canalización de agentes de la arquitectura Max. A los $1.25 descontados para Qwen3.7-Max, es competitivo con los precios de nivel medio de GPT-5, pero el descuento figura como promocional.
La situación del nivel gratuito en 2026
Esta es la parte que más confunde a la gente.
Lo que es gratuito: La aplicación de chat para consumidores Qwen Studio: no requiere registro, no se han comunicado límites de velocidad y es compatible con iOS, Android, macOS y web. Esto no va a desaparecer. Alibaba tiene fuertes incentivos comerciales para mantener gratuito el producto para el consumidor.
Lo que era gratuito y ya no existe: El nivel gratuito de la API OAuth para desarrolladores (que permitía 1,000 solicitudes/día, luego 100) fue discontinuado el 15 de abril de 2026. El nivel de programación gratuito de 2,000 solicitudes/día de Qwen Code CLI también se eliminó por esas fechas. La reacción de la comunidad fue inmediata:
"ngl i just subscribed to claude. I had qwen make .md files of everything so claude could just pick up from there."
u/ihateroomba, 3 votos positivos
Un comentario de Reddit analíticamente agudo explicó bien la distinción:
"It's important to distinguish between two distinct worlds that coexist at Alibaba: The 'Consumer Product' world (Qwen Studio): The app you use on your phone is a finished product. Alibaba has every interest in keeping it free... The 'Developer / API' world: This is where the policy has changed... It's a classic strategy: attract users with the free version, then charge them when it scales."
Lo que todavía está disponible como prueba gratuita: Las nuevas cuentas de Alibaba Cloud Model Studio reciben más de 70 millones de tokens gratuitos en los modelos Qwen (1 millón de tokens por modelo), además de 1,650 segundos de crédito para generación de video. Válido por 90 días, solo para el endpoint de Singapur. El endpoint de EE. UU. (Virginia) no tiene cuota gratuita.
El precio mínimo del auto-hospedaje
Hay un número que las tablas de precios de la API no muestran: $0.00 por token, disponible para cualquiera que esté dispuesto a ejecutar su propia inferencia.
Todos los modelos Qwen3 (desde 0.6B hasta 235B-A22B) son de pesos abiertos con licencia Apache 2.0 y están disponibles en Hugging Face. @WolframRvnwlf probó la versión cuantizada de Unsloth de Qwen3-30B-A3B en una MacBook Pro M4:
"The 30B-A3B Unsloth quant delivered 82.20% while running locally at ~45 tok/s and with zero API spend... Quantised 30B models now get you ~98% of frontier-class accuracy - at a fraction of the latency, cost, and energy."
vLLM y SGLang son los marcos recomendados para el auto-hospedaje; la documentación de Qwen3 incluye los comandos de implementación completos. Para los equipos que procesan datos sensibles o que operan en jurisdicciones donde importa el cumplimiento de la nube con origen en China, el auto-hospedaje también resuelve por completo la cuestión de la residencia de los datos.
La contrapartida: el costo del hardware es real. Un solo nodo de GPU H20 cuesta entre $3 y $5 por hora en proveedores de la nube. Para cargas de trabajo moderadas (menos de unos pocos millones de tokens al día), la API es probablemente más barata que el cómputo dedicado. Pero a escala - o con una GPU que ya poseas - el auto-hospedaje suele ganar.
Qwen vs Claude vs GPT: la comparación honesta
La idea de que "Qwen es 9 veces más barato que Claude" es real pero incompleta.
"The API pricing comparison tells the story clearly. Claude Opus 4.6 runs $5 input and $25 output per million tokens. GPT-5.3 Codex runs $1.75 and $14. Qwen 3.5 Plus runs $0.40 and $2.40. That's not a marginal difference. That's a structural shift in who can afford to build with frontier-level AI."
El matiz que añade Artificial Analysis: los modelos Qwen generan más tokens de salida por tarea que sus pares. Qwen3.5-27B utilizó 98 millones de tokens de salida para completar su benchmark del Intelligence Index, significativamente más que MiniMax-M2.5 (56 millones) o DeepSeek V3.2 (61 millones). Si tu carga de trabajo genera salidas largas, la verbosidad de los tokens compensa parcialmente el descuento por token.
El análisis en LinkedIn de Rishabh Choudhary sobre Qwen3.6-Plus plantea la pregunta central:
"It scored 78.8 on SWE-bench Verified... Claude Opus 4.5 scored 80.9. That's a 2-point gap. The price gap? Not 2 points. More like 17x... The question isn't whether Chinese models are catching up. They clearly are. The question is whether the remaining quality gaps matter enough to justify paying 17x more. For a lot of use cases, I think the honest answer is becoming no."
Las advertencias de los profesionales que han ejecutado Qwen en producción también merecen ser tomadas en serio. De los comentarios de ese mismo post de LinkedIn: una latencia de 11 segundos para el primer token en el nivel de vista previa gratuita (un problema para bucles de agentes de varios pasos donde el tiempo de espera se acumula) y una tasa de alucinación de razonamiento de código reportada del 26% en pruebas de producción que "requiere una capa de verificación que añade parte de los ahorros de costos que se están capturando en los tokens".
Para una comparación directa con las alternativas más populares, consulta los precios de Claude, los precios de Gemini y los precios de Mistral AI.
Contexto de los benchmarks
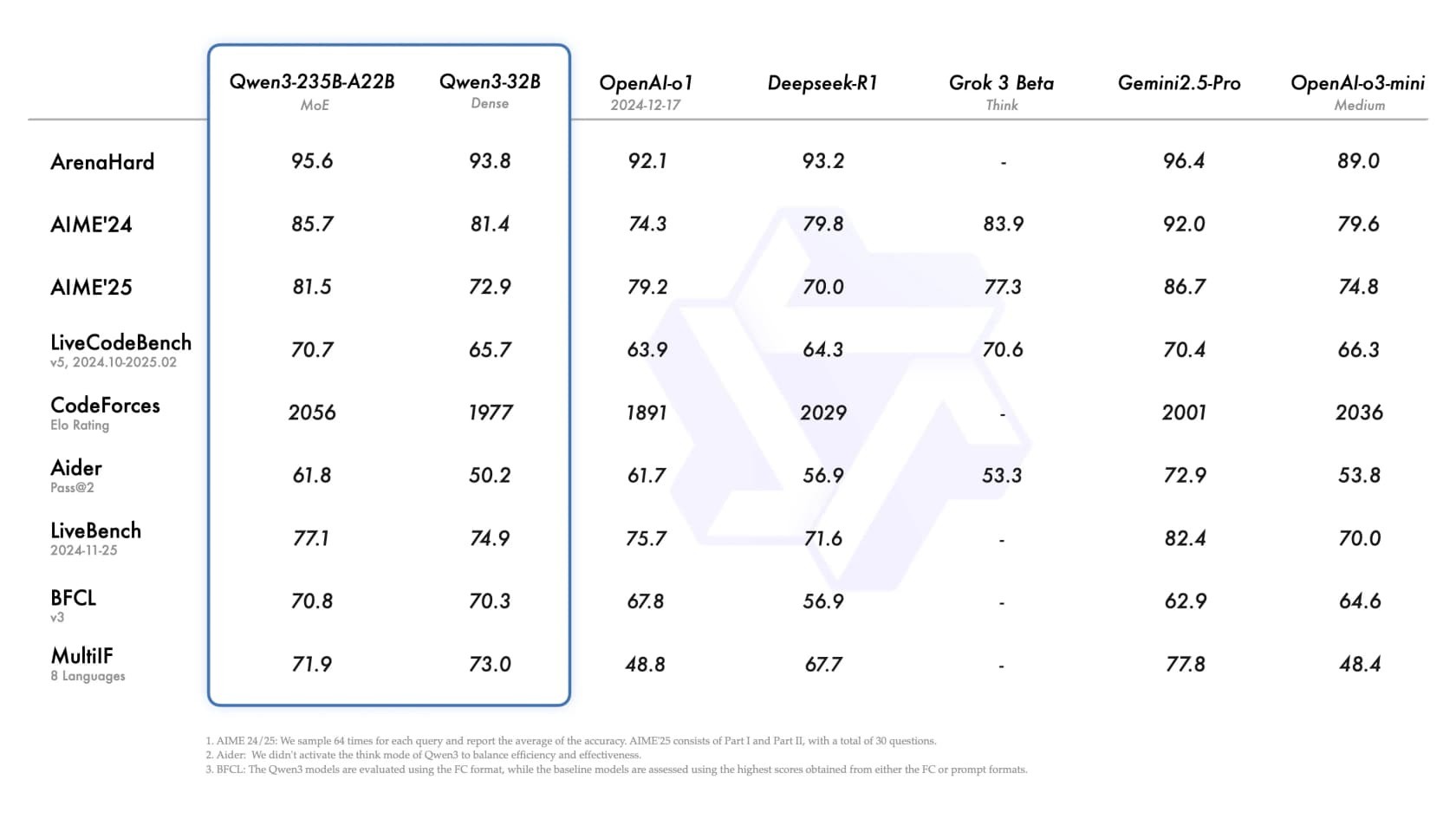
El modelo insignia MoE Qwen3-235B-A22B compite directamente con OpenAI o1, DeepSeek-R1 y Gemini 2.5 Pro en benchmarks públicos: ArenaHard 95.6, AIME'24 85.7, LiveCodeBench 70.7, BFCL 70.8. A $0.70/$2.80 por cada millón de tokens (estándar), supera en precio a la mayoría de esos modelos mientras iguala sus puntuaciones. La disponibilidad de pesos abiertos significa que también puedes descargarlo y ejecutarlo tú mismo sin ninguna dependencia de la API.
La señal de descargas de código abierto es reveladora: Qwen ocupa 7 de los 10 primeros puestos en los rankings de descargas de modelos abiertos de Hugging Face, según Nathan Lambert (investigador de ML), con Qwen2.5-7B-Instruct en 52.4 millones de descargas y múltiples variantes de Qwen3 en los cinco primeros. Ese nivel de adopción crea herramientas comunitarias, versiones cuantizadas e integraciones en el ecosistema que hacen que el auto-hospedaje sea cada vez más accesible.
Acceso a la API: cómo empezar
La API internacional funciona en Alibaba Cloud Model Studio. Es compatible con OpenAI, lo que significa que cambiar del SDK de OpenAI a Qwen suele ser un cambio de dos líneas: la URL base y la clave API.
from openai import OpenAI
client = OpenAI(
base_url="https://[workspace-id].ap-southeast-1.maas.aliyuncs.com/compatible-mode/v1",
api_key="your-dashscope-api-key"
)
Regiones disponibles: Sudeste Asiático (principal), Frankfurt (desde el 20-03-2026) y Hong Kong (desde el 17-03-2026). El endpoint de EE. UU. (Virginia) está disponible pero no incluye cuota de prueba gratuita.
Los límites de velocidad son de 600 RPM / 1M TPM para la mayoría de los modelos; Qwen-Turbo funciona a un nivel superior con 5M TPM, lo que lo convierte en la elección correcta para canalizaciones de alto volumen y picos de actividad. Las cuentas empresariales pueden solicitar aumentos de cuota mediante tickets de soporte.
Quién está adoptando realmente Qwen y quién está esperando
La adopción de los desarrolladores es fuerte: el dominio de descargas en Hugging Face y el volumen de tokens de OpenRouter lo hacen innegable. NVIDIA respaldó oficialmente a Qwen 3.5 el día de su lanzamiento, orientando a los desarrolladores hacia la ruta de construcción NeMo.
La adopción empresarial es otra historia. Como señaló un comentarista de LinkedIn:
"For our Fortune 500 / enterprise customers the most used models are: 1. Gemma 2. Mistral 3. GPT-OSS 4. Llama... Some of our forward thinking enterprise customers are starting to use Qwen, but it's not the majority yet."
Andrew Jardine, enterprise AI [Fuente]
Los obstáculos mencionados: las revisiones de cumplimiento por el origen en China en industrias reguladas (servicios financieros, salud, gobierno) y la latencia en los endpoints de vista previa de nivel gratuito. La serie Qwen3 cuenta con la certificación ISO 27001 en la API de pago, pero muchas revisiones de seguridad empresarial requieren aprobaciones adicionales sobre la residencia de los datos y el registro de acceso a los modelos antes de que la adquisición pueda proceder. El auto-hospedaje evita la mayoría de estos problemas.
Para los equipos que no tienen esas restricciones de cumplimiento (especialmente startups, desarrolladores de SaaS del mercado medio y operadores de canalizaciones de agentes sensibles a los costos), la economía es difícil de rebatir.
Prueba eesel
Si ejecutas flujos de trabajo potenciados por IA a escala y los costos de los tokens te importan, vale la pena echar un vistazo a eesel. Despliega agentes de IA autónomos directamente dentro de las herramientas que tu equipo ya usa (Zendesk, Slack, Freshdesk, correo electrónico, Shopify) sin requerir una nueva interfaz ni suscripciones por asiento. Pagas por tarea ($0.40 por ticket resuelto, $4.00 por borrador de post de blog) y los agentes se detienen automáticamente cuando alcanzas tu límite de gasto. El modelo de precios evita por completo la gestión del conteo de tokens. Comienza con $50 de crédito gratuito, sin necesidad de tarjeta.

Preguntas frecuentes
¿Cuánto cuesta Qwen por millón de tokens?
¿Qwen sigue siendo gratuito en 2026?
¿Cómo se comparan los precios de Qwen con ChatGPT y Claude?
¿Qué es el modo de pensamiento de Qwen y cómo se factura?
enable_thinking: true que activa el razonamiento de cadena de pensamiento. Los tokens de salida de pensamiento se facturan a una tarifa más alta que la salida estándar, típicamente de 3 a 10 veces más. Por ejemplo, Qwen-Plus cobra $1.20/1M por la salida estándar pero $4.00/1M por la salida de pensamiento. Los tokens de entrada estándar se facturan a la misma tarifa independientemente de si el pensamiento está activado.