¿Qué es Groq (y por qué los precios funcionan diferente aquí)?
Groq no fabrica modelos: ejecuta los modelos de otros (Llama, Qwen, Mistral, Whisper, modelos de pesos abiertos de OpenAI) en su propio silicio personalizado: la Unidad de Procesamiento de Lenguaje, o LPU. Fundada en 2016 por ex ingenieros de TPU de Google, recaudaron $750M con una valoración de $6.9B en septiembre de 2025 y ahora sirven a más de 2M de desarrolladores. El equipo McLaren F1 usa Groq para análisis de carreras en tiempo real, no es un caso de uso donde "generalmente rápido" sea aceptable.
El modelo de precios es simple: cobrar por token, sin tarifas de infraestructura inactiva, sin picos de precios elásticos. La declaración oficial de Groq al respecto: "Otros proveedores de inferencia aumentan los costos sin previo aviso. Algunos se esconden detrás de precios elásticos. Los precios de Groq son lineales y predecibles, sin costos ocultos ni infraestructura inactiva."

Por qué la LPU cambia la ecuación de costos
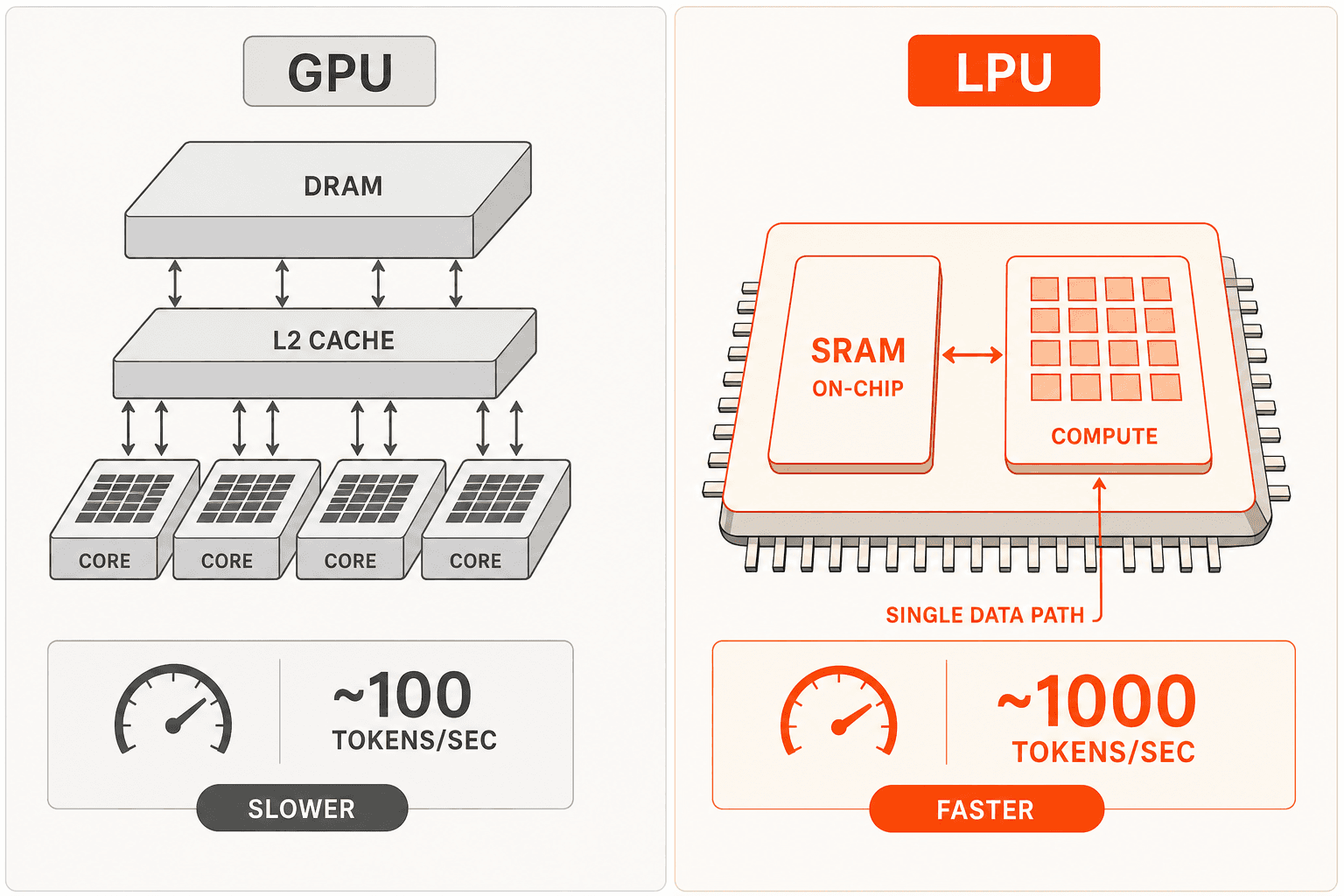
Las GPU fueron diseñadas para entrenamiento: grandes jerarquías de memoria DRAM/HBM externas, programación dinámica, protocolos de coherencia de caché. Estas son buenas propiedades al paralelizar operaciones matriciales en miles de núcleos para entrenamiento. Son una mala combinación para inferencia, donde la ejecución secuencial de capas tiene baja intensidad aritmética y las lecturas de memoria dominan la latencia.
La arquitectura LPU adopta un enfoque diferente. La SRAM en chip sirve como almacenamiento primario de pesos, no como caché, sino como memoria primaria. El compilador construido a medida de Groq pre-programa cada operación hasta ciclos de reloj individuales antes de que comience la ejecución, eliminando por completo la sobrecarga de programación dinámica. El protocolo RealScale chip-a-chip permite que cientos de LPUs se comporten como un solo núcleo para paralelismo tensorial. Como cada operación está programada estáticamente, Groq puede ejecutar paralelismo de pipeline sobre paralelismo tensorial: la capa N+1 comienza a procesarse mientras la capa N todavía está terminando, algo que la programación dinámica de GPU no puede hacer de forma fiable.
El resultado práctico: GPT OSS 20B a 1,000 tokens por segundo. Llama 3.1 8B a 560–840 TPS. Llama 3.3 70B a 280–394 TPS. Las API de nube basadas en GPU típicas ejecutan 50–100 TPS en modelos equivalentes. Cuando el mismo hardware sirve más solicitudes por segundo, los costos fijos se distribuyen entre más tokens, lo que hace viable comercialmente $0.05 por 1M de tokens de entrada.

Nivel gratuito de Groq: qué obtienes realmente
El nivel gratuito no requiere tarjeta de crédito y se rige por límites de tasa, no por un presupuesto mensual de tokens. Esto es exactamente lo que ofrece cada modelo en el plan gratuito:
| Modelo | RPM | TPM | Solicitudes/día |
|---|---|---|---|
llama-3.1-8b-instant | 30 | 6,000 | 14,400 |
llama-3.3-70b-versatile | 30 | 12,000 | 1,000 |
meta-llama/llama-4-scout-17b-16e-instruct | 30 | 30,000 | 1,000 |
openai/gpt-oss-20b | 30 | 8,000 | 1,000 |
openai/gpt-oss-120b | 30 | 8,000 | 1,000 |
qwen/qwen3-32b | 60 | 6,000 | 1,000 |
groq/compound | 30 | 70,000 | 250 |
whisper-large-v3 | 20 | - | 2,000 solicitudes de audio |
whisper-large-v3-turbo | 20 | - | 2,000 solicitudes de audio |
(RPM = solicitudes por minuto, TPM = tokens por minuto. Fuente: documentación de límites de tasa de Groq)
Hay dos cosas que sorprenden a los desarrolladores aquí. Primero, los límites de tasa se aplican a nivel de organización, no por clave API. Crear cinco claves no te da 150 RPM: sigue siendo 30 RPM compartidos en toda tu cuenta. Segundo, los tokens de caché de prompts no cuentan para los límites de tasa, lo que es un beneficio significativo si tienes prompts de sistema largos que se repiten entre llamadas.
Los límites de TPM por minuto suelen ser la restricción real, no los límites de solicitudes diarias. Un prompt de 2,000 tokens consume un tercio del presupuesto de TPM de Llama 8B en una sola llamada.
"He estado usando la API de Groq sin parar, constantemente pensando para mí mismo 'cómo es que todavía no he alcanzado algún tipo de límite del nivel gratuito'"
El nivel gratuito de Whisper es el valor más destacado. Artificial Analysis confirmó a Groq como uno de los proveedores de Whisper Large v3 de menor costo. En el plan gratuito obtienes 2,000 solicitudes de transcripción de audio por día, aproximadamente 2 horas de audio por hora del reloj al procesar en lotes con el mínimo de 10 segundos por solicitud. OpenAI cobra $0.36/hora por el acceso a Whisper; el nivel de pago de Groq cobra $0.04–$0.111/hora, por lo que el nivel gratuito es un punto de partida generoso.
"Su API gratuita para texto a voz es increíble, muy generosa, la recomiendo ampliamente."
Reseñador de Trustpilot, derivado de búsqueda

Precios de la API de pago de Groq: todos los modelos
Todos los precios están en USD por 1M de tokens (entrada / salida) a menos que se indique lo contrario. Fuente: página de precios de Groq.
Modelos de texto/LLM
| Modelo | ID del modelo | Velocidad (TPS) | Contexto | Entrada $/1M | Salida $/1M | Estado |
|---|---|---|---|---|---|---|
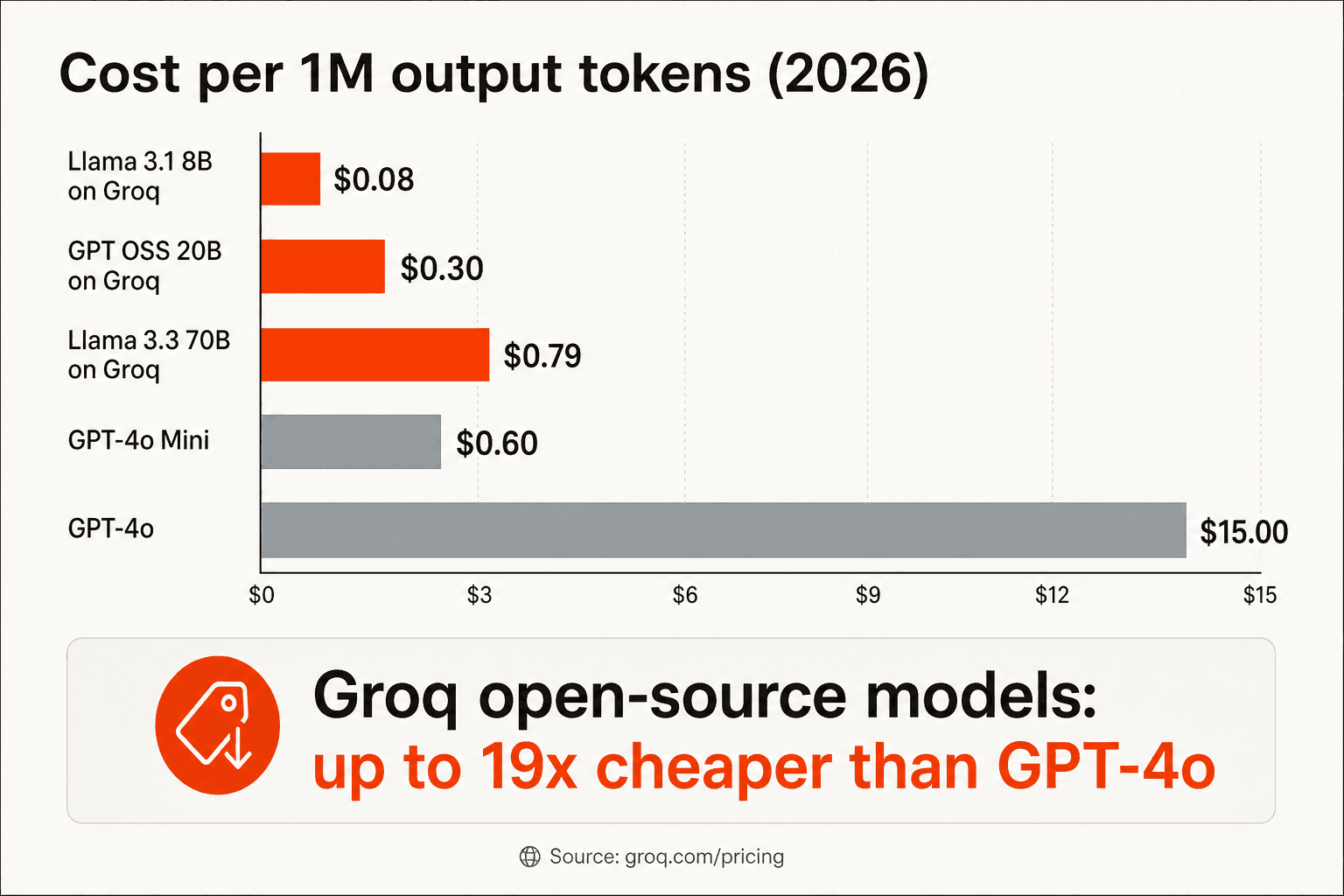
| Llama 3.1 8B Instant | llama-3.1-8b-instant | 560–840 | 128k | $0.05 | $0.08 | Producción |
| GPT OSS 20B | openai/gpt-oss-20b | 1,000 | 128k | $0.075 | $0.30 | Producción |
| Llama 4 Scout (17Bx16E) | meta-llama/llama-4-scout-17b-16e-instruct | 594–750 | 128k | $0.11 | $0.34 | Vista previa |
| GPT OSS 120B | openai/gpt-oss-120b | 500 | 128k | $0.15 | $0.60 | Producción |
| Qwen3 32B | qwen/qwen3-32b | 400–662 | 131k | $0.29 | $0.59 | Vista previa |
| Llama 3.3 70B Versatile | llama-3.3-70b-versatile | 280–394 | 128k | $0.59 | $0.79 | Producción |
| Kimi K2 Instruct | moonshotai/kimi-k2-instruct-0905 | - | - | $1.00 ($0.50 cacheado) | $3.00 | - |
| Llama Prompt Guard 2 22M | meta-llama/llama-prompt-guard-2-22m | - | 512 | $0.03 | $0.03 | Vista previa |
| Llama Prompt Guard 2 86M | meta-llama/llama-prompt-guard-2-86m | - | 512 | $0.04 | $0.04 | Vista previa |
Hay algunas notas sobre modelos que vale la pena destacar. GPT OSS 20B, el modelo de pesos abiertos de OpenAI, no GPT-4, se ejecuta a 1,000 tokens por segundo a $0.075 entrada / $0.30 salida. Es simultáneamente el modelo más rápido de la plataforma y uno de los más baratos por token de salida. Llama 4 Scout admite entradas de visión (archivos de hasta 20 MB) pero permanece en Vista previa: no lo pongas en producción todavía. Kimi K2 es el único modelo donde el caché de prompts está explícitamente incluido en la fila de precios: $0.50 por 1M de tokens de entrada cacheados frente a $1.00 sin caché.
Los modelos Prompt Guard ($0.03–$0.04 por 1M de tokens) son clasificadores de seguridad diseñados para detectar inyección de prompts e intentos de jailbreak, útiles si estás construyendo IA orientada al cliente y necesitas una capa de filtro ligera antes de tu modelo principal.
Límites de tasa del plan de desarrollador
El salto del plan gratuito al plan de desarrollador es sustancial:
| Modelo | TPM de desarrollador | RPM de desarrollador |
|---|---|---|
llama-3.1-8b-instant | 250,000 | 1,000 |
llama-3.3-70b-versatile | 300,000 | 1,000 |
openai/gpt-oss-20b | 250,000 | 1,000 |
openai/gpt-oss-120b | 250,000 | 1,000 |
meta-llama/llama-4-scout-17b-16e-instruct | 300,000 | 1,000 |
qwen/qwen3-32b | 300,000 | 1,000 |
whisper-large-v3-turbo | 400,000 ASH | 400 |
groq/compound | 200,000 | 200 |
(Fuente: console.groq.com/docs/models)
Cómo se comparan los precios de Groq con OpenAI y otros proveedores
La cifra más citada en las comunidades de desarrolladores es "10–20x más barato que OpenAI para modelos de código abierto comparables". Eso es aproximadamente correcto, con el calificador necesario de que no estás comparando modelos idénticos.
"La inferencia LLM en Groq cuesta aproximadamente 10 veces menos en comparación con los precios de OpenAI para GPT-4o. Groq es 10–20x más barato, pero para un modelo algo menos capaz: Llama 3-70B frente a GPT-4o."
La comparación más honesta no es Groq frente a los modelos propietarios de OpenAI, sino Groq frente a otros proveedores de hosting de código abierto como Together AI o Fireworks AI ejecutando los mismos modelos. Allí, según la revisión de producción de 8 semanas de Awesome Agents, Groq opera un 20–50% más barato en niveles de modelos equivalentes con latencia de cola determinista donde p99 se mantiene dentro del 15% de la mediana, una ventaja significativa sobre las cargas de trabajo de GPU donde los picos de latencia de cola son comunes.
"Adiós API de OpenAI. Hoy, puedes obtener la misma inteligencia subyacente, Llama-3 o sus competidores de código abierto, a precios que se desploman hacia el suelo, a menudo por debajo de $0.20 por millón de tokens. Eso es una reducción de precio del 99% en dieciocho meses."
El modelo mental práctico que ha surgido en la comunidad de desarrolladores, resumido por Jolly Gupta en LinkedIn (114 me gusta, septiembre de 2025): usa Groq para cargas de trabajo de código abierto críticas en velocidad y sensibles al costo, usa OpenAI cuando necesitas las capacidades de GPT-4o o profundidad multimodal. La mayoría de los stacks de producción usan ambos.
Groq también apareció en la encuesta de Artificial Analysis como uno de los 5 principales proveedores de inferencia por adopción de desarrolladores, junto con OpenAI, Google, Anthropic y Microsoft.
Precios de audio: Whisper y TTS
Reconocimiento de voz
Groq ejecuta ambas variantes de Whisper Large v3 en hardware LPU, ofreciendo transcripción a 217–228x velocidad en tiempo real. Una hora de audio se procesa en aproximadamente 15 segundos.
| Modelo | Factor de velocidad | Precio | Archivo máximo |
|---|---|---|---|
whisper-large-v3 | 217x tiempo real | $0.111 / hora | 100 MB |
whisper-large-v3-turbo | 228x tiempo real | $0.04 / hora | - |
Para la mayoría de las cargas de trabajo, Turbo a $0.04/hora es la elección obvia: más rápido y 2.8x más barato que el modelo completo, con solo diferencias de calidad marginales en la mayoría del audio. El audio se factura con un mínimo de 10 segundos por solicitud independientemente de la duración real, por lo que agrupar clips cortos vale el esfuerzo de implementación.
OpenAI cobra $0.36/hora por Whisper; Groq a $0.04/hora es 9x más barato en el modelo Turbo. Levels.io señaló que Whisper + TTS en Groq era "muy barato" incluso en 2024; los precios se han mantenido estables desde entonces.
Texto a voz (Vista previa)
Groq lanzó recientemente TTS a través de los modelos Orpheus de Canopy Labs:
| Modelo | Precio | Notas |
|---|---|---|
canopylabs/orpheus-v1-english | $22.00 / 1M de caracteres | Inglés, ~100 caracteres/seg |
canopylabs/orpheus-arabic-saudi | $40.00 / 1M de caracteres | Árabe (dialecto saudí) |
Estos siguen en estado de Vista previa. La ventaja de velocidad de la LPU también es visible aquí: Orpheus genera a 100 caracteres por segundo en Groq, lo que permite aplicaciones de voz casi en tiempo real.

Sistemas de IA compuesta: cuando las herramientas tienen costo adicional
Los sistemas Compound de GroqCloud, groq/compound y groq/compound-mini, son envolturas agénticas que le dan a un modelo de lenguaje búsqueda web integrada y ejecución de código. Los precios son los costos de tokens del modelo más el uso de herramientas:
| Herramienta | Precio |
|---|---|
| Búsqueda web básica | $5 / 1,000 solicitudes |
| Búsqueda web avanzada | $8 / 1,000 solicitudes |
| Visitar sitio web | $1 / 1,000 solicitudes |
| Ejecución de código | $0.18 / hora |
| Automatización de navegador | $0.08 / hora |
El sistema Compound se ejecuta a ~450 TPS con contexto de 131k. Es un punto de partida práctico para cargas de trabajo de IA agéntica donde quieres delegar la orquestación del uso de herramientas a la plataforma en lugar de construirla tú mismo.

Dos descuentos ocultos que vale la pena conocer
API por lotes: 50% de descuento para cargas de trabajo asíncronas
La API por lotes reduce a la mitad el costo de cualquier modelo ejecutando trabajos de forma asíncrona. Envías un archivo JSONL (hasta 50,000 líneas, 200 MB), el procesamiento se completa en 24 horas a 7 días, y pagas el 50% de la tarifa estándar por token. Sin impacto en tus límites de tasa estándar.
Esta es la opción correcta para: pipelines de clasificación de documentos, generación de contenido masivo, enriquecimiento de datos nocturnos, moderación de contenido a escala: cualquier cosa donde la tolerancia a la latencia te gane un descuento significativo. El uso de herramientas en los sistemas Compound todavía se cobra a tarifas estándar.
Caché de prompts: 50% de descuento en prefijos repetidos
El caché de prompts es automático: sin cambios de código, sin tarifa adicional. Cuando el mismo prefijo (un prompt de sistema largo, un documento de referencia) se repite entre llamadas, Groq lo almacena en caché hasta 2 horas. Los aciertos de caché cuestan el 50% del precio de entrada normal.
Modelos que admiten caché de prompts y sus tarifas cacheadas:
| Modelo | Entrada estándar | Entrada cacheada |
|---|---|---|
openai/gpt-oss-20b | $0.075 / 1M | $0.0375 / 1M |
openai/gpt-oss-120b | $0.15 / 1M | $0.075 / 1M |
moonshotai/kimi-k2-instruct-0905 | $1.00 / 1M | $0.50 / 1M |
El doble beneficio: los tokens cacheados cuestan la mitad y no cuentan para los límites de tasa. Para cargas de trabajo con prompts de sistema largos, pipelines de RAG, preguntas y respuestas sobre documentos, agentes de soporte al cliente con IA con grandes contextos de conocimiento, esto amplía significativamente tu rendimiento efectivo sin actualizar tu nivel de límite de tasa.
Límites de tasa: qué pasa cuando los alcanzas
Cuando se supera cualquier límite de tasa, Groq devuelve HTTP 429 con un encabezado retry-after que muestra cuántos segundos esperar. El cuerpo del error es específico:
"Se alcanzó el límite de tasa para el modelo
openai/gpt-oss-20b… nivel de servicio: on_demand … Límite 200,000 · Usado 199,336 · Solicitado 1,524 · Por favor inténtalo de nuevo en 6 min 11.52 seg."
Los encabezados de respuesta también incluyen x-ratelimit-limit-requests, x-ratelimit-remaining-tokens y x-ratelimit-reset-requests, suficiente para implementar retroceso exponencial preciso sin prueba y error.
La consideración operativa clave: los límites de tasa son por organización y por modelo. Si estás ejecutando múltiples servicios o miembros del equipo desde la misma cuenta de Groq, comparten el mismo pool de límites. Usa cuentas de organización separadas para entornos de producción y desarrollo, o contacta a Groq sobre límites más altos para cargas de trabajo específicas a través de console.groq.com/settings/limits.
Precios empresariales
No hay una tabla pública de precios empresariales. Para acceder a lo siguiente, contacta a groq.com/enterprise-access:
- Límites de tasa más altos para cargas de trabajo específicas
- Despliegue local de GroqRack
- Modelos ajustados con LoRA
- Modelos exclusivos para empresas (Minimax M2.5, Qwen3-VL 32B con visión)
- Opciones de despliegue regional y residencia de datos
- Documentación de cumplimiento SOC 2, GDPR e HIPAA
Sobre el tiempo de actividad: la revisión de producción de Awesome Agents midió un 99.94% de tiempo de actividad durante 8 semanas con latencia p99 dentro del 15% de la mediana, mejor comportamiento de cola que los competidores basados en GPU porque la programación LPU es determinista. Las garantías de SLA empresarial requieren un acuerdo formal.
La pregunta de sostenibilidad
La mayoría de las guías de precios de Groq omiten esto. Nosotros no lo haremos.
En septiembre de 2024, Kyle Corbitt publicó en X que había escuchado a un empleado de Groq afirmar que sus costos por token son "1–2 órdenes de magnitud más altos que lo que cobran". La publicación alcanzó 271k vistas. A principios de 2024, @swyx hizo los cálculos y encontró que los precios solo funcionan con un tamaño de lote de ~512, inaudito en la inferencia normal, y cae a ~$1.84 por millón de tokens con un lote normal de 64.
El contraargumento: Groq recaudó $750M de BlackRock, Samsung, Cisco y Disruptive AI específicamente porque la tesis del volumen y los nuevos chips es creíble. Sus casos de estudio de clientes muestran GPTZero a 7x más rápido y 50% menor costo, ReBlink a 14x menor costo por juego, Recall a 10x menor costo. Los datos de participación de PeerSpot muestran un ligero declive interanual (de 13.7% a 9.8%) entre los evaluadores de infraestructura de IA empresarial, lo que puede reflejar incertidumbre sobre los acuerdos con NVIDIA: vale la pena monitorear.
Nuestra opinión: no sabemos si los precios actuales son estructuralmente sostenibles o una estrategia deliberada de land-and-expand antes de los chips de segunda generación. Lo que sí sabemos es que los precios han sido estables durante 2025–2026 y los $750M recaudados compran tiempo. Úsalo donde la relación precio-rendimiento tenga sentido; no te arquitectes en una dependencia de un solo proveedor que no puedas cambiar.
Quién debería (y no debería) usar Groq
Usa Groq cuando:
- Estás construyendo interfaces de voz o chat en tiempo real donde 280–1,000 TPS importa para la experiencia del usuario
- Tu stack de modelos funciona con Llama, Qwen, Whisper o los modelos de pesos abiertos de OpenAI
- Necesitas transcripción barata a escala: Whisper Turbo a $0.04/hora es difícil de superar
- Estás prototipando: el nivel gratuito cubre la mayoría de las cargas de trabajo de desarrollo sin tarjeta de crédito
- Tienes cargas de trabajo de lotes asíncronas: el descuento del 50% de la API por lotes cambia significativamente la economía
Busca alternativas cuando:
- Necesitas GPT-4o, Claude o Gemini, no disponibles en GroqCloud
- Necesitas soporte multimodal robusto: Llama 4 Scout está solo en Vista previa
- Necesitas despliegue local con términos de soporte estándar: GroqRack requiere negociaciones empresariales
- Necesitas modelos propietarios ajustados: el ajuste fino con LoRA requiere acceso empresarial
Para una comparación más amplia de características, nuestra reseña de Groq cubre el producto completo en profundidad. Si todavía estás evaluando proveedores, alternativas a Groq compara Together AI, Fireworks, Cerebras y otros en las mismas dimensiones de precio-rendimiento.
Prueba eesel para soporte al cliente impulsado por IA
Si estás evaluando Groq para automatización de soporte al cliente o helpdesk, eesel se complementa bien con él. eesel despliega agentes de IA autónomos directamente dentro de tus herramientas existentes, Zendesk, Freshdesk, Slack, correo electrónico, y enruta los tickets de soporte al modelo correcto según la complejidad. Las consultas simples de alto volumen van a un nivel de modelo rápido y barato (exactamente para lo que están construidos Llama 8B y GPT OSS 20B de Groq); las escalaciones complejas van a un modelo de mayor capacidad.
Los equipos que manejan más de 100,000 tickets por mes usan agentes de eesel que realmente resuelven problemas en lugar de solo desviarlos: sin nueva interfaz que aprender, sin ingeniería de prompts requerida. Instruyes al agente de la misma manera que incorporarías a un nuevo empleado, y él se encarga del resto.

Preguntas frecuentes
¿Cuánto cuesta la API de Groq por 1M de tokens?
¿Groq tiene un nivel gratuito?
¿Cómo se comparan los precios de Groq con los de OpenAI?
¿Cuáles son los límites de tasa de Groq en el nivel de desarrollador de pago?
¿Vale la pena el precio de Groq para cargas de trabajo en producción?

Article by
Rama Adi Nugraha
Rama is a software engineer at eesel AI with two years of experience writing about B2B SaaS, AI tools, and customer support technology. Based in Bali, Indonesia, he brings a developer's perspective to product comparisons — cutting through marketing copy to what the integrations and APIs actually do.