¿Qué es exactamente Sakana Fugu?
Sakana AI es un laboratorio frontier de Tokio fundado en 2023 por tres ex investigadores de Google: el CEO David Ha, el CTO Llion Jones (uno de los ocho coautores del paper original "Attention Is All You Need" sobre Transformers) y el COO Ren Ito. En noviembre de 2025, recaudó $135M en una Serie B a una valoración de $2.65B, convirtiéndose en una de las startups de IA más valiosas de Japón.
El nombre importa. "Sakana" (魚) significa pez, un guiño a la apuesta del laboratorio de que el futuro de la IA se parece menos a un gran cerebro y más a un banco coordinado de especialistas más pequeños. Fugu (llamado así por el pez globo) es esa tesis convertida en un producto. Sakana lo presenta como "One Model to Command Them All": rendimiento a nivel frontier sin depender de ningún proveedor único.
Esta es la forma más clara de imaginarlo. Fugu es en sí mismo un modelo, pero en lugar de generar la respuesta final solo, ensambla dinámicamente un equipo de un grupo de otros modelos poderosos y los coordina. Todo el aparato te llega como un modelo detrás de una sola API. Si has leído nuestra explicación sobre agentes de IA versus chatbots, Fugu es la idea del agente llevada a su extremo lógico: las "herramientas" del agente son otros modelos frontier.
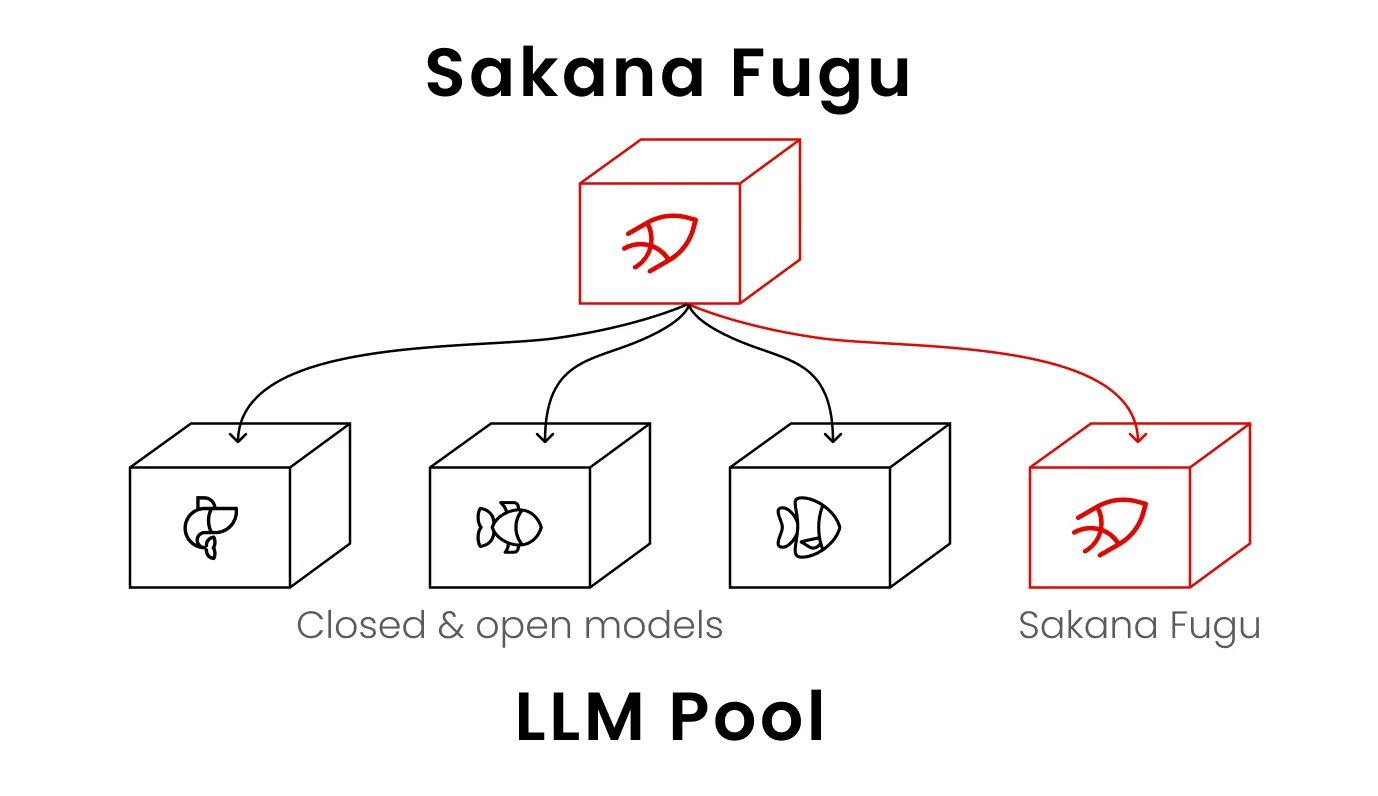
Un detalle importante que mucha gente pasa por alto: Fable 5 y Mythos Preview no están en el grupo de Fugu, porque no son accesibles públicamente. Fugu solo orquesta modelos que puede llamar realmente. Entonces, cuando Sakana dice que Fugu iguala a Fable 5, está diciendo que un equipo coordinado de otros modelos públicos puede rivalizar con el frontier, lo cual es una afirmación más interesante de lo que parece a primera vista.
Cómo funciona Fugu realmente bajo el capó
Aquí es donde Fugu se gana la defensa de "no es solo un router". Está fundamentado en dos papers de ICLR 2026 sobre orquestación de modelos aprendida, y el mecanismo es más elaborado que simplemente elegir un modelo y reenviar la solicitud.
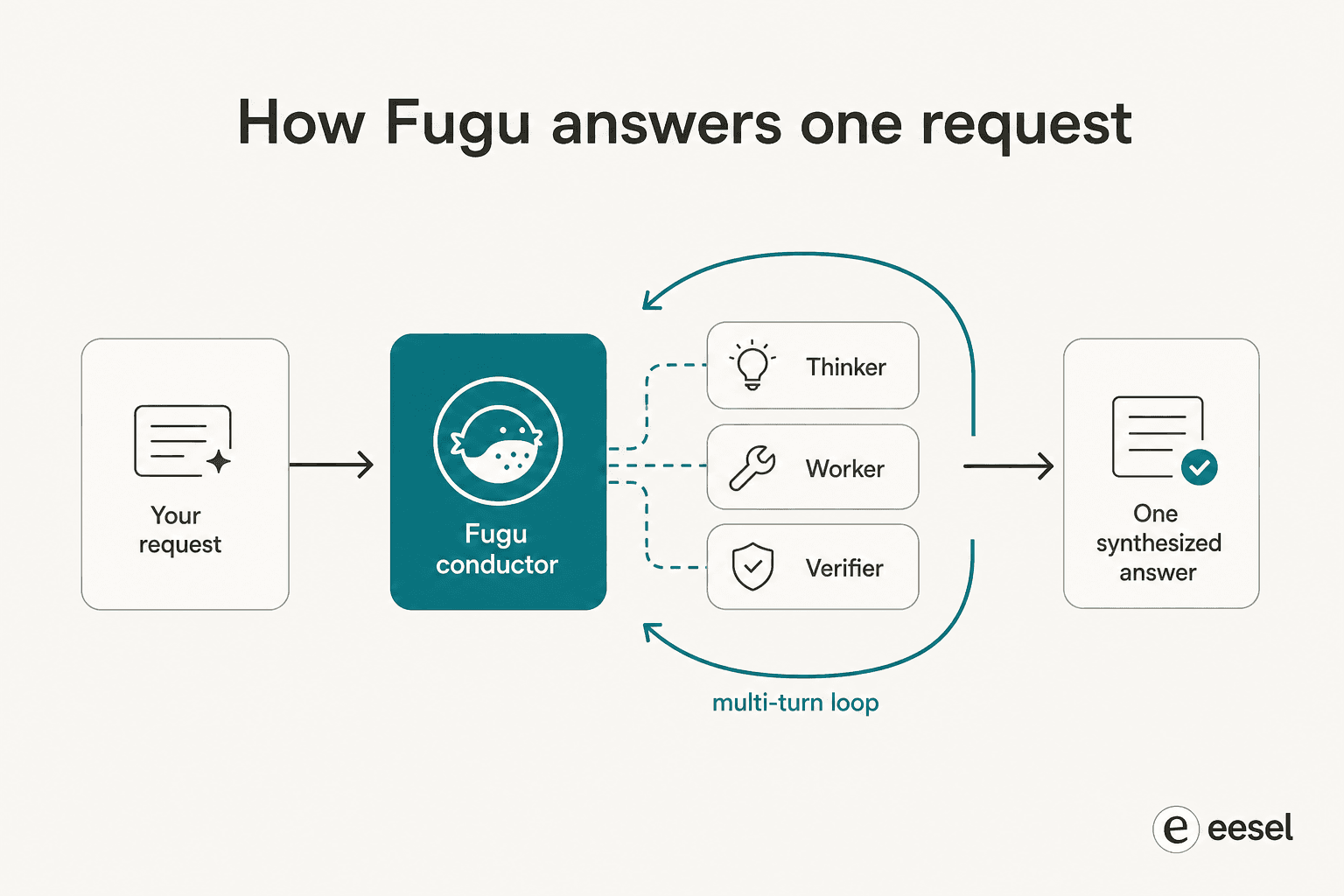
El primer paper, TRINITY, usa un coordinador ligero y evolucionado que orquesta múltiples modelos a lo largo de varios turnos, asignando a cada uno un rol de Thinker, Worker o Verifier y redelegando a medida que la tarea se desarrolla. El segundo, el Conductor, se entrena con aprendizaje por refuerzo para descubrir estrategias de coordinación en lenguaje natural, básicamente aprendiendo a escribir prompts enfocados y a diseñar cómo los modelos se comunican entre sí para que el grupo supere a cualquier miembro individual.
Las dos frases que vale la pena retener son aprendido y multi-turno. Fugu no sigue un guión diseñado por humanos de "primero pregunta al modelo A, luego al modelo B". Aprendió, a través de evolución y RL, a descubrir patrones de colaboración no obvios, y itera, volviendo a verificar y reenrutar en lugar de hacer un solo paso. Por eso los primeros usuarios informan que funciona durante horas en una sola tarea: 123 experimentos en aproximadamente 14 horas en un problema de investigación de ML, o casi cuatro horas reproduciendo autónomamente un paper. Se comporta muy parecido al tipo de bucle de agente sobre el que nos obsesionamos al construir automatización de soporte, solo que apuntado a modelos frontier en lugar de herramientas.
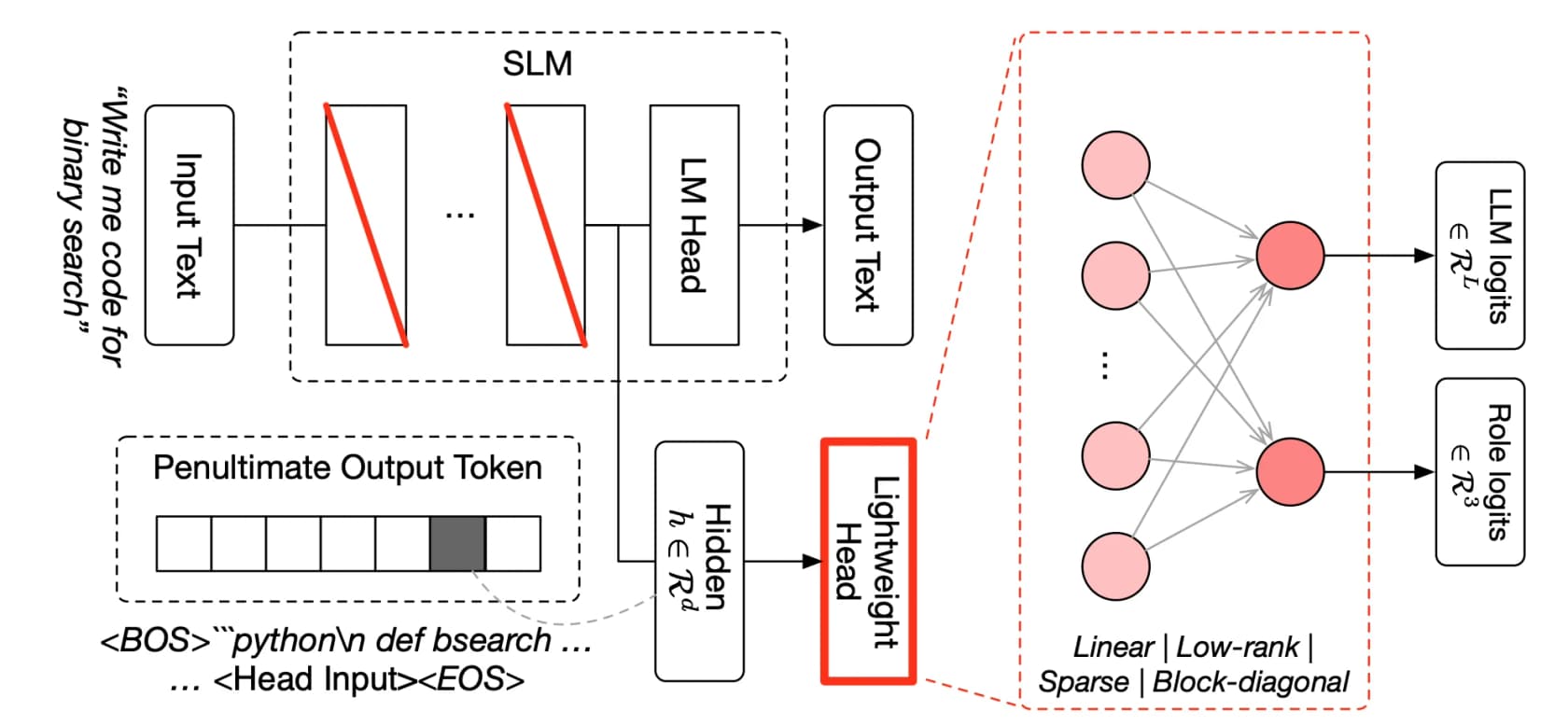
Un trade-off a señalar ahora: el enrutamiento es propietario y opaco por diseño. No puedes ver qué modelo subyacente respondió una consulta determinada. Para algunos equipos eso está bien; para cualquiera con necesidades de cumplimiento, esa estructura de caja negra dentro de caja negra es una consideración real.
Fugu vs Fugu Ultra: cuál es cuál
Fugu se lanza como dos modelos, ambos accesibles a través de la misma API compatible con OpenAI, para que puedas cambiar entre ellos sin tocar tu integración. La diferencia está en cuántos agentes expertos se coordinan, que es el palanca entre velocidad y calidad.
| Fugu | Fugu Ultra | |
|---|---|---|
| Optimizado para | Rendimiento y latencia equilibrados | Máxima calidad de respuesta |
| Grupo de agentes | Coordina un grupo; puedes excluir modelos | Grupo fijo y más profundo; sin exclusión |
| Mejor para | Codificación cotidiana, revisión de código, chatbots | Problemas difíciles, de alto riesgo y multi-paso |
| Compensación | Baja latencia, sólido por defecto | Mayor calidad a costa de velocidad |
En términos simples: usa Fugu cuando quieras un valor predeterminado receptivo, y Fugu Ultra cuando tengas un problema complicado y estés dispuesto a esperar una mejor respuesta. Los primeros usuarios ponen a Ultra a trabajar en competiciones de Kaggle, reproducción de papers, análisis de ciberseguridad e investigaciones de patentes, lo que indica que el punto ideal previsto es la profundidad, no el rendimiento.
Los benchmarks: ¿está realmente a la altura de Fable 5?
La afirmación principal de Sakana es que los modelos Fugu "superan a los modelos frontier públicamente accesibles y están a la altura de Fable 5 y Mythos Preview" en benchmarks de ingeniería, ciencias y razonamiento. Los números respaldan bien la afirmación más acotada.
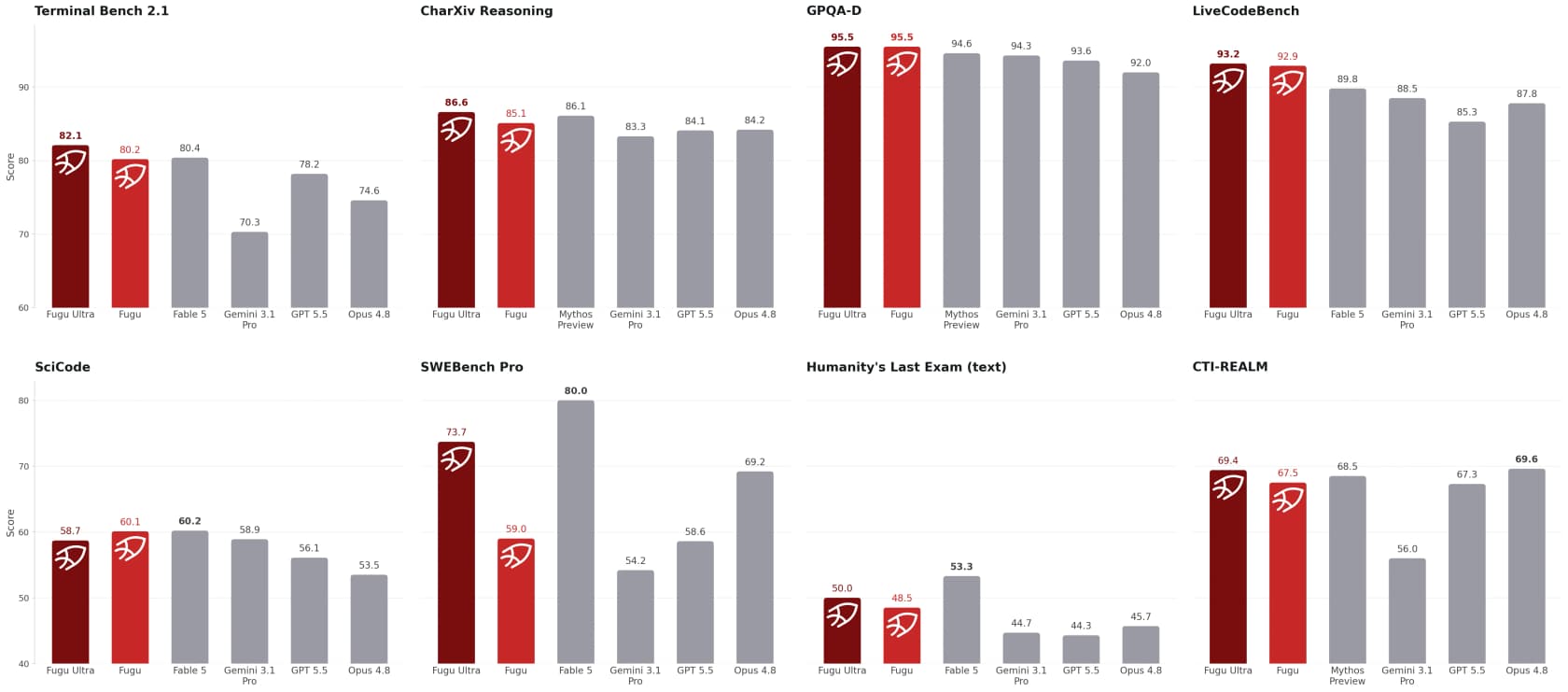
Algunos que destacan de la tabla de Sakana: Fugu Ultra obtiene 73.7 en SWE-Bench Pro (vs 69.2 para Opus 4.8 y 58.6 para GPT-5.5), 93.2 en LiveCodeBench y 95.5 en GPQA-Diamond, por delante de todas las líneas base públicas mostradas. Las demos cualitativas son aún más llamativas: Fugu supuestamente venció a tres modelos frontier y a un motor Stockfish de 2100 de Elo en ajedrez a ciegas, y en una prueba de trading de series temporales hizo crecer $10,000 a $11,943 en una ventana de 50 semanas, un retorno medio de +19.43% que superó a los demás.
Dos advertencias honestas. Primero, estos son benchmarks reportados por el proveedor, y los modelos más fuertes (Fable 5, Mythos) fueron excluidos de la comparación como competidores directos en lugar de ser superados directamente. Segundo, los benchmarks miden la capacidad máxima en problemas difíciles, no si la herramienta es agradable de usar a las 2 de la tarde un martes. Como dijo un beta tester, slopdetector, en Hacker News:
"Usé esto durante la beta. Supera a GPT-5.5 xhigh en tareas complejas. Como es caro y difícil de subsidiar, úsalo para los problemas más desafiantes... los resultados que obtuve de fugu-ultra fueron impresionantes."
Cuánto cuesta Sakana Fugu (y el problema que nadie menciona)
Hay dos formas de pagar, y ambas incluyen acceso a Fugu y Fugu Ultra.
| Nivel de suscripción | Precio | Asignación de uso | Para |
|---|---|---|---|
| Standard | $20/mes | Base | Uso diario ligero |
| Pro | $100/mes | 10× Standard | Sesiones de trabajo enfocadas |
| Max | $200/mes | 30× Standard | Cargas de trabajo pesadas y de larga duración |
(Vale la pena señalar: las tarjetas de precios de Sakana dicen que Max es 30× Standard mientras que una respuesta de FAQ dice 20×, así que confirma la asignación antes de comprometerte.) También hay un plan de tokens de pago por uso donde Fugu Ultra tiene un precio fijo de $5 de entrada, $30 de salida y $0.50 de entrada en caché por millón de tokens, aumentando a $10 / $45 / $1.00 una vez que el contexto supera los 272K tokens. Y hay una promo de lanzamiento: suscríbete antes de finales de julio de 2026 para un segundo mes gratis.
Ahora el problema. Fugu tiene un precio al nivel máximo del grupo que enruta, por lo que el trabajo extra de orquestación tiene que justificarse frente a simplemente pagar directamente por un modelo frontier. Varios usuarios con experiencia práctica sintieron que no lo hacía. La versión más contundente vino de cortesi en Hacker News:
"Por $200/mes obtienes menos de 3 horas de uso por semana, la API es extremadamente lenta, y la calidad de salida en mis pruebas no está ni cerca de Fable. No está ni remotamente cerca de ser utilizable como caballo de batalla diario. Muy decepcionante."
Esa es la experiencia de un tester, no un veredicto, pero rima con varios otros que informan que el límite de 5 horas se agota rápido. Si alguna vez has modelado costos de agentes de IA frente a agentes humanos, la lección es familiar: el precio de catálogo y el costo real por tarea útil son números diferentes.
Aquí hay una verificación rápida sobre si Fugu es la herramienta correcta para lo que estás haciendo:
¿Es justa la crítica de "solo OpenRouter con pasos extra"?
La reacción más ruidosa al lanzamiento de Fugu, repetida de forma independiente en Hacker News, X y Reddit, fue algo como "¿no es esto simplemente OpenRouter?" Es un instinto válido, así que tomémoslo en serio.
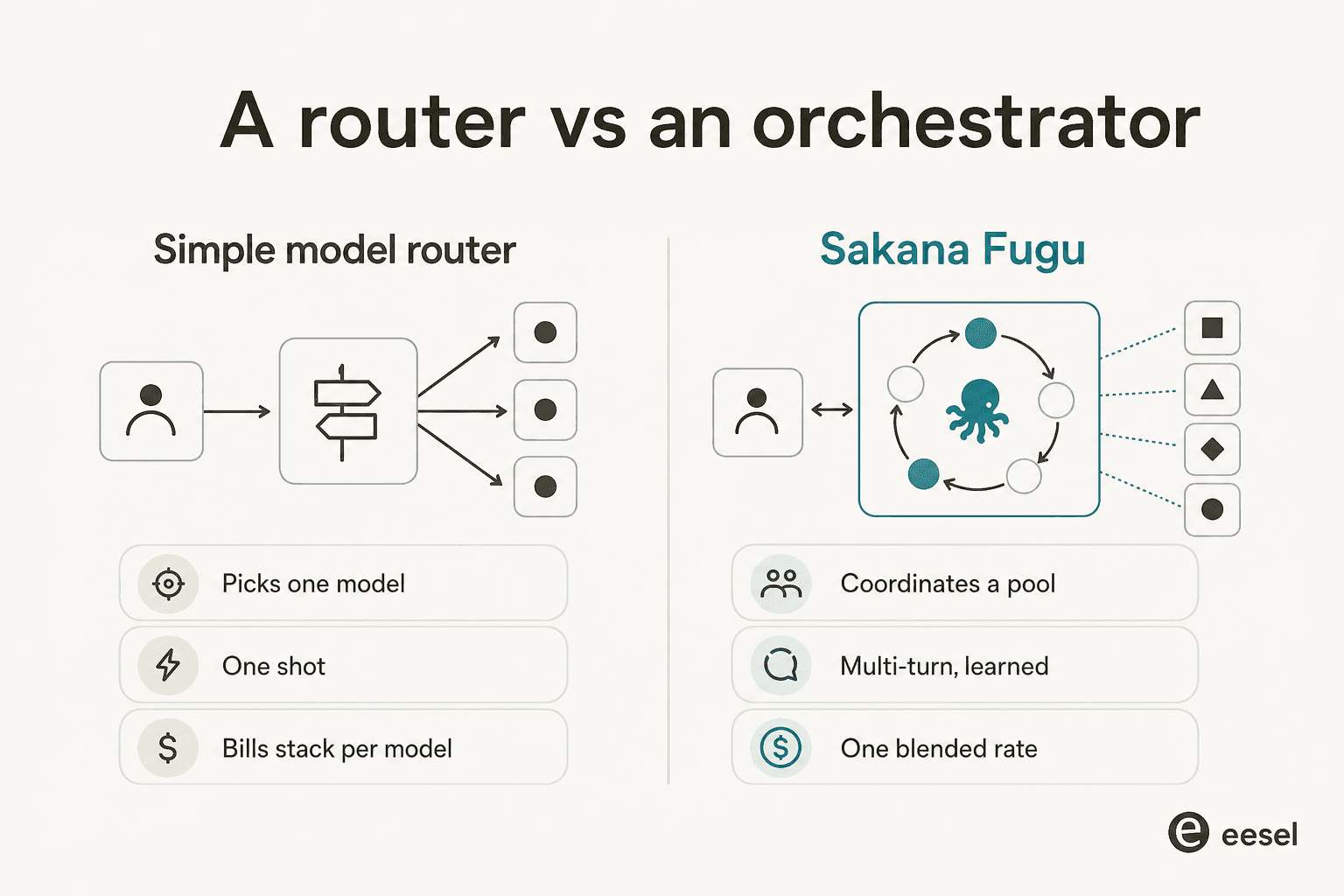
Un router simple elige un modelo y reenvía tu solicitud una vez. Fugu, al menos sobre el papel, hace tres cosas que un router no hace: ejecuta múltiples turnos, hace que los modelos verifiquen el trabajo de los demás, y cobra una tarifa combinada única basada en el modelo superior involucrado en lugar de acumular la factura de cada modelo. La arquitectura es real, y "router avanzado" subestima el bucle multi-turno y de auto-verificación.
Pero los escépticos aciertan en el valor, no en la arquitectura. Como preguntó directamente chenzhekl:
"Pero tiene el mismo precio que los modelos frontier. ¿Por qué no pago directamente por los modelos frontier?"
Ese es todo el debate en una línea. La arquitectura es más que un router; la pregunta abierta es si la coordinación extra te compra suficiente para justificar pagar precios frontier por ello. Mi opinión: en tus problemas más difíciles, posiblemente sí; en el trabajo cotidiano, probablemente no. Este es el mismo cálculo que aparece en las decisiones de agente de IA versus chatbot basado en reglas, donde más sofisticación solo vale la pena cuando la tarea es realmente difícil.
Lo que la gente realmente piensa de Sakana Fugu
El sentimiento de la comunidad, leído con justicia, es mixto a escéptico con un campo pro real. Los partidarios hacen el argumento más interesante: que hacer que los modelos se verifiquen mutuamente es simplemente la apuesta correcta. Como argumentó epsteingpt:
"Todos han entendido durante meses que hacer que diferentes modelos se verifiquen mutuamente es el mejor camino a seguir... Si (gran si) la mecánica de uso funciona, entonces esto es realmente una muy buena estrategia anti-modelo-grande. Estarán incentivados por tu éxito, no por maximizar tokens para sus inversores."
Ese punto de alineación de incentivos es agudo, y es una razón real para apostar por un orquestador frente a un monolito. También hay un hilo de respeto por el camino de investigación de Sakana. Como señaló quanto, David Ha tomó una ruta poco convencional hacia la investigación de IA, y el trabajo anterior del laboratorio (Evolutionary Model Merge, el AI Scientist, Transformer²) es consistentemente distintivo.
Los escépticos, mientras tanto, no son reflexivos. Sus objeciones se agrupan en costo, latencia y el encuadre opaco de "un único proveedor reemplazando a otro único proveedor". Y un par de notas del mundo real que vale la pena conocer antes de registrarse: Fugu aún no está disponible en la UE/EEE, y algunos usuarios expresaron inquietud sobre los contratos militares de Sakana. Si lo estás sopesando frente a los mejores agentes de IA para producción, esos no son notas al pie.
Por qué un modelo que orquesta modelos importa para el soporte
Esta es la parte que más me importa, porque es el trabajo que hago. La idea subyacente de Fugu —no apuestes tu flujo de trabajo en un solo modelo, coordina varios y hazlos verificarse mutuamente— es exactamente correcta para la automatización de alto riesgo como el soporte al cliente. Una respuesta incorrecta de un bot de soporte no es un error en el leaderboard, es un reembolso emitido por error o un cliente furioso.
Pero hay un abismo entre una API de modelo sin procesar y opaca y algo que puedes poner con seguridad frente a los clientes. Fugu te da orquestación; no te da tu centro de ayuda, tus tickets anteriores, la voz de tu marca, tus reglas de escalación, ni una forma de probar la cosa antes de que entre en producción. Esa es la capa que realmente decide si la IA para atención al cliente funciona, y es por eso que elegiría un agente de IA para atención al cliente especializado sobre conectar manualmente una API frontier. La pregunta de orquestación sobre la que nos obsesionamos en construir versus comprar es la misma que Fugu está respondiendo, solo en una capa diferente del stack.
Prueba eesel
eesel toma la lección sobre la que está construido Fugu y la aplica donde realmente tiene que ser confiable: tu cola de soporte. En lugar de darte una API de modelo, es un agente de IA que se conecta al helpdesk que ya usas (Zendesk, Freshdesk, Help Scout, Slack y más) en minutos, se entrena con tus tickets pasados y tu centro de ayuda, y responde con la voz de tu marca, sin necesidad de fontanería de orquestación de modelos.

El diferenciador más importante aquí es la parte que Fugu no puede darte: un modo de simulación que reproduce el agente contra miles de tus tickets históricos antes de que toque a un cliente en vivo, para que veas la tasa de resolución y las respuestas exactas de antemano en lugar de descubrirlas en producción. Los precios son por uso sin tarifas por asiento, por lo que el costo escala con el valor en lugar de la cantidad de empleados. Si quieres ver cómo es un agente de atención al cliente con IA cuando la orquestación es invisible y las salvaguardas están integradas, es gratis probarlo.
Preguntas frecuentes
¿Qué es Sakana Fugu en términos simples?
¿En qué se diferencia Sakana Fugu de OpenRouter?
¿Cuánto cuesta Sakana Fugu?
¿Es Sakana Fugu mejor que Claude o GPT-5.5?
¿Para qué se usa mejor Sakana Fugu?
¿Puedo usar Sakana Fugu para atención al cliente?
¿Está Sakana Fugu disponible en todas partes?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.








