Wie man Zendesk Eskalationspfade nach Priorität im Jahr 2026 einrichtet
Stevia Putri
Zuletzt bearbeitet March 2, 2026
Nicht jedes Support-Ticket verdient die gleiche Reaktionszeit. Ein Passwort-Reset und ein vollständiger Systemausfall sollten sehr unterschiedliche Eskalationspfade durchlaufen, aber beide könnten mit der gleichen Priorität in Ihrer Warteschlange ankommen. Wenn das falsch läuft, bedeutet das verärgerte Kunden, verpasste SLAs und ausgebrannte Agenten.
Das Einrichten von Eskalationspfaden nach Priorität in Zendesk stellt sicher, dass dringende Probleme sofort die richtigen Personen erreichen, während Routineanfragen standardmäßigen Workflows folgen. Dieser Leitfaden führt Sie durch die Konfiguration der prioritätsbasierten Eskalation von grundlegenden Auslösern bis hin zur fortgeschrittenen Automatisierung.
Das Verständnis der prioritätsbasierten Eskalation in Zendesk
Zendesk bietet Ihnen vier Prioritätsstufen: Niedrig, Normal, Hoch und Dringend. Jede sollte unterschiedliche Eskalationsverhalten auslösen, basierend auf der Dringlichkeit und den Auswirkungen des Problems.
So ordnen die meisten Teams die Priorität der Eskalationsreaktion zu:
- Dringend: Kritische Ausfälle, Sicherheitsverletzungen oder alles, was den Geschäftsbetrieb stoppt. Diese sollten Standard-Warteschlangen vollständig umgehen und Manager sofort benachrichtigen.
- Hoch: Signifikante Probleme, die mehrere Benutzer oder Schlüsselfunktionen betreffen. Eskalieren Sie innerhalb von Stunden an leitende Agenten oder spezialisierte Teams.
- Normal: Standard-Supportanfragen, die eine Lösung benötigen, aber die Arbeit nicht blockieren. Folgen Sie der standardmäßigen gestaffelten Eskalation.
- Niedrig: Allgemeine Fragen und Funktionsanfragen. Minimale Eskalation, bearbeitet vom ersten verfügbaren Agenten.
Der Schlüssel ist Konsistenz. Wenn ein Agent "Kann sich nicht anmelden" als dringend markiert, während ein anderer es als normal markiert, werden Ihre Metriken bedeutungslos und Kunden erhalten sehr unterschiedliche Erfahrungen. Hier helfen klare Eskalationspfade allen, aufeinander abgestimmt zu bleiben.
Für einen tieferen Einblick in das Priorität, Dringlichkeit und Auswirkungs-Framework, sehen Sie sich unseren vollständigen Leitfaden zur Ticketpriorisierung an.
Die vier Arten von Eskalationspfaden, die Sie kennen müssen
Bevor Sie etwas konfigurieren, verstehen Sie die vier Eskalationstypen, die in einem vollständigen System zusammenarbeiten:
Funktionale Eskalation leitet Tickets basierend auf der erforderlichen Expertise weiter. Ein technisches Problem geht von einem allgemeinen Support-Agenten an einen Ingenieur. Eine Abrechnungsfrage geht an das Finanzteam. Der Eskalationspfad hängt davon ab, welche Fähigkeiten benötigt werden, nicht von der Hierarchie.
Hierarchische Eskalation bewegt Tickets die Befehlskette hinauf. Wenn ein Kunde nach einem Vorgesetzten fragt oder wenn ein Agent keine Befugnis hat, eine Rückerstattung zu genehmigen, wird das Ticket an jemanden mit mehr Entscheidungsbefugnis eskaliert.
Automatisierte Eskalation verwendet zeitbasierte Regeln und SLA-Schwellenwerte, um Tickets ohne menschliches Zutun zu verschieben. Wenn ein Ticket mit hoher Priorität 4 Stunden lang ungelöst bleibt, stuft die Automatisierung es auf Dringend hoch und benachrichtigt den Teamleiter.
Prioritätseskalation beschleunigt Tickets basierend auf der Dringlichkeit. Dringende Tickets überspringen die First-Line-Warteschlange vollständig und gehen direkt an leitende Agenten oder spezialisierte Teams. Das ist es, was die meisten Leute meinen, wenn sie über Eskalationspfade nach Priorität sprechen.
Die meisten Teams verwenden alle vier Typen zusammen. Ein Ticket könnte mit funktionaler Eskalation beginnen (Weiterleitung an das technische Team), eine automatisierte Eskalation auslösen, wenn die SLA gefährdet ist, und mit einer hierarchischen Eskalation enden, wenn der Kunde einen Manager verlangt.
Einrichten von prioritätsbasierten Auslösern in Zendesk
Auslöser sind Ihre erste Verteidigungslinie für die prioritätsbasierte Eskalation. Sie werden sofort ausgelöst, wenn Tickets erstellt oder aktualisiert werden, und leiten dringende Probleme weiter, bevor sie in einer Warteschlange sitzen.
Schritt 1: Zugriff auf die Auslösereinstellungen
Navigieren Sie zu Admin Center → Objekte und Regeln → Geschäftsregeln → Auslöser. Sie sehen eine Liste der vorhandenen Auslöser. Klicken Sie auf Auslöser hinzufügen, um einen neuen zu erstellen.
Schritt 2: Erstellen von prioritätsbasierten Routing-Auslösern
Richten Sie Auslöser ein, die Tickets automatisch basierend auf der Prioritätsstufe weiterleiten:
Unter Erfüllen ALLE der folgenden Bedingungen:
- Ticket | Ist | Erstellt
- Priorität | Ist | Dringend
Unter Aktionen:
- Gruppe | Support-Manager (oder Ihre Eskalationsgruppe)
- Tags hinzufügen | urgent_escalation
- Benachrichtigungen | E-Mail-Gruppe | Support-Manager
Erstellen Sie einen ähnlichen Auslöser für Tickets mit hoher Priorität, die an Ihre Senior-Agenten-Gruppe weitergeleitet werden. Der Schlüssel ist, dass dedizierte Gruppen bereit sind, eskalierte Tickets zu empfangen.
Schritt 3: Konfigurieren von VIP-Kunden-Auslösern
Bei der Priorität geht es nicht nur um das Problem, sondern auch darum, wer es gemeldet hat. Richten Sie Auslöser für Ihre VIP-Kunden ein:
Unter Erfüllen ALLE der folgenden Bedingungen:
- Ticket | Ist | Erstellt
- Organisation | Ist | VIP-Kunden (oder Ihr VIP-Organisationsname)
Unter Aktionen:
- Priorität | Hoch
- Gruppe | VIP-Supportteam
- Tags hinzufügen | vip_customer
Dies stellt sicher, dass Ihre wertvollsten Kunden die entsprechende Aufmerksamkeit erhalten, unabhängig davon, wie sie ihre Anfrage formulieren. Weitere Informationen zu VIP-Kunden-Workflows finden Sie in unserem detaillierten Einrichtungsleitfaden.
Erstellen von zeitbasierten Eskalationsautomatisierungen
Auslöser verarbeiten das sofortige Routing. Automatisierungen verarbeiten, was passiert, wenn Tickets altern. Hier verhindern Sie, dass Tickets ungelöst bleiben, weil sie nicht von Anfang an als wichtig gekennzeichnet wurden.
Schritt 1: Erstellen von SLA-bewussten Automatisierungen
Navigieren Sie zu Admin Center → Objekte und Regeln → Geschäftsregeln → Automatisierungen. Im Gegensatz zu Auslösern werden Automatisierungen nach einem Zeitplan (stündlich) ausgeführt und überprüfen zeitbasierte Bedingungen.
Schritt 2: Einrichten von "Stunden bis zur nächsten SLA-Verletzung"-Benachrichtigungen
Erstellen Sie eine Automatisierung, die Ihr Team warnt, bevor SLAs verletzt werden:
Unter Erfüllen ALLE der folgenden Bedingungen:
- Stunden bis zur nächsten SLA-Verletzung | Weniger als | 2
- Statuskategorie | Weniger als | Gelöst
- Tags | Enthält keines der folgenden | sla_warning_sent
Unter Aktionen:
- Benachrichtigungen | E-Mail-Gruppe | (Ihre Eskalationsgruppe)
- Tags hinzufügen | sla_warning_sent
Das Tag verhindert, dass die Automatisierung Ihr Team stündlich mit Spam bombardiert. Weitere Informationen zu SLA-basierten Eskalationsautomatisierungen finden Sie in unserem Automatisierungsleitfaden.
Schritt 3: Prioritätsbasierte Zeit-Eskalation
Erstellen Sie Automatisierungen, die die Priorität erhöhen, wenn Tickets zu lange liegen:
Für die Eskalation mit normaler Priorität:
- Stunden seit Erstellung | Größer als | 24
- Priorität | Ist | Normal
- Status | Ist | Offen
Aktionen:
- Priorität | Hoch
- Tags hinzufügen | auto_escalated
Erstellen Sie eine ähnliche Automatisierung für hohe Tickets, die nach 4 Stunden auf dringend eskaliert werden. Dies stellt sicher, dass nichts vergessen wird, nur weil es anfangs nicht dringend war. Erfahren Sie mehr über Zendesk-Automatisierungen und ihre Einschränkungen in unserer detaillierten Übersicht.
Verbinden von SLAs mit Ihren Eskalationspfaden
SLAs definieren, wie schnell Sie sich verpflichten, auf Tickets zu reagieren und diese zu lösen. Ihre Eskalationspfade sollten mit diesen Verpflichtungen übereinstimmen.
So werden typische SLA-Ziele den Prioritätsstufen zugeordnet:
| Priorität | Erste Antwort | Lösungszeit | Eskalationsauslöser |
|---|---|---|---|
| Dringend | 15-60 Minuten | 2-4 Stunden | Sofortige Managerbenachrichtigung |
| Hoch | 1-4 Stunden | 8 Stunden | Eskalieren nach 50 % der verstrichenen SLA |
| Normal | 4-12 Stunden | 24 Stunden | Eskalieren nach 24 Stunden |
| Niedrig | 24 Stunden | 5 Werktage | Keine automatische Eskalation |
Um SLA-Richtlinien einzurichten, gehen Sie zu Admin Center → Objekte und Regeln → Service Level Agreements. Erstellen Sie separate Richtlinien für jede Prioritätsstufe mit entsprechenden Zielen.
Der wichtigste Integrationspunkt: Verwenden Sie "Stunden bis zur nächsten SLA-Verletzung" in Ihren Automatisierungen, nicht "Stunden seit der letzten SLA-Verletzung". Ersteres warnt Sie, bevor eine Verletzung eintritt. Letzteres sagt Ihnen erst, nachdem Sie bereits gescheitert sind.
Für eine vollständige exemplarische Vorgehensweise sehen Sie sich unseren Leitfaden zum Erstellen von Zendesk-SLA-Richtlinien an.
Erstellen von Eskalationsansichten für Ihr Team
Ansichten sind das Dashboard Ihres Teams für die Verwaltung eskalierter Tickets. Richten Sie dedizierte Ansichten ein, damit Agenten genau wissen, was Aufmerksamkeit benötigt.
Warteschlange für dringende/hohe Priorität: Zeigen Sie alle Tickets an, bei denen die Priorität dringend oder hoch ist, sortiert nach aufsteigender nächster SLA-Verletzung. Dadurch werden die zeitkritischsten Tickets oben platziert.
Ansicht für eskalierte Tickets: Filtern Sie nach Tickets mit Eskalations-Tags (wie "urgent_escalation" oder "auto_escalated"). Dies gibt Ihnen eine übersichtliche Liste aller Elemente, die zur Sonderbehandlung eskaliert wurden.
VIP-Kundenansicht: Zeigen Sie Tickets von Ihrer VIP-Organisation an, sortiert nach Erstellungsdatum. Ihre Senior-Agenten können dies den ganzen Tag über überwachen.
Ansicht für überfällige Eskalationen: Filtern Sie nach Tickets, bei denen die SLA bereits verletzt wurde. Diese benötigen sofortige Aufmerksamkeit und möglicherweise die Beteiligung des Managements.
Erstellen Sie diese Ansichten in Admin Center → Arbeitsbereiche → Agenten-Tools → Ansichten. Geben Sie sie für die entsprechenden Gruppen frei, damit jeder sieht, was für seine Rolle wichtig ist.
Häufige Eskalationsfehler und wie man sie vermeidet
Auch bei perfekter Konfiguration können menschliche Faktoren Ihr Eskalationssystem zerstören:
Überexkalation von Routineproblemen trainiert Ihr Team, Eskalationen zu ignorieren. Wenn jedes zweite Ticket als dringend markiert ist, ist nichts dringend. Definieren Sie klare Kriterien für jede Prioritätsstufe und ziehen Sie Agenten zur Rechenschaft.
Fehlender Kontext bei Übergaben frustriert Kunden und verlangsamt die Lösung. Wenn ein Ticket eskaliert wird, sollte der empfangende Agent alles haben, was er benötigt. Verwenden Sie interne Notizen, um zu dokumentieren, was versucht wurde und was der Kunde erwartet.
Das Nichtverfolgen von Eskalationsmetriken bedeutet, dass Sie sich nicht verbessern können. Überwachen Sie Ihre Eskalationsrate (streben Sie 15-20 % für ausgereifte Teams an), die durchschnittliche Lösungszeit nach Priorität und die SLA-Verletzungsraten. Wenn dringende Tickets SLAs konsistent verfehlen, benötigen Sie mehr Senior-Agenten, nicht bessere Regeln.
Das Versäumnis, Kunden zu benachrichtigen erzeugt Angst. Wenn Sie ein Ticket eskalieren, teilen Sie dem Kunden mit, was passiert ist und wann er mit einem Update rechnen kann. Stille lässt sie denken, dass ihr Problem fallen gelassen wurde.
Optimierung der Eskalation mit KI-Automatisierung
Die manuelle Prioritätszuweisung und das Routing funktionieren für kleine Teams. Mit zunehmendem Volumen benötigen Sie Systeme, die den Kontext verstehen, nicht nur Schlüsselwörter.
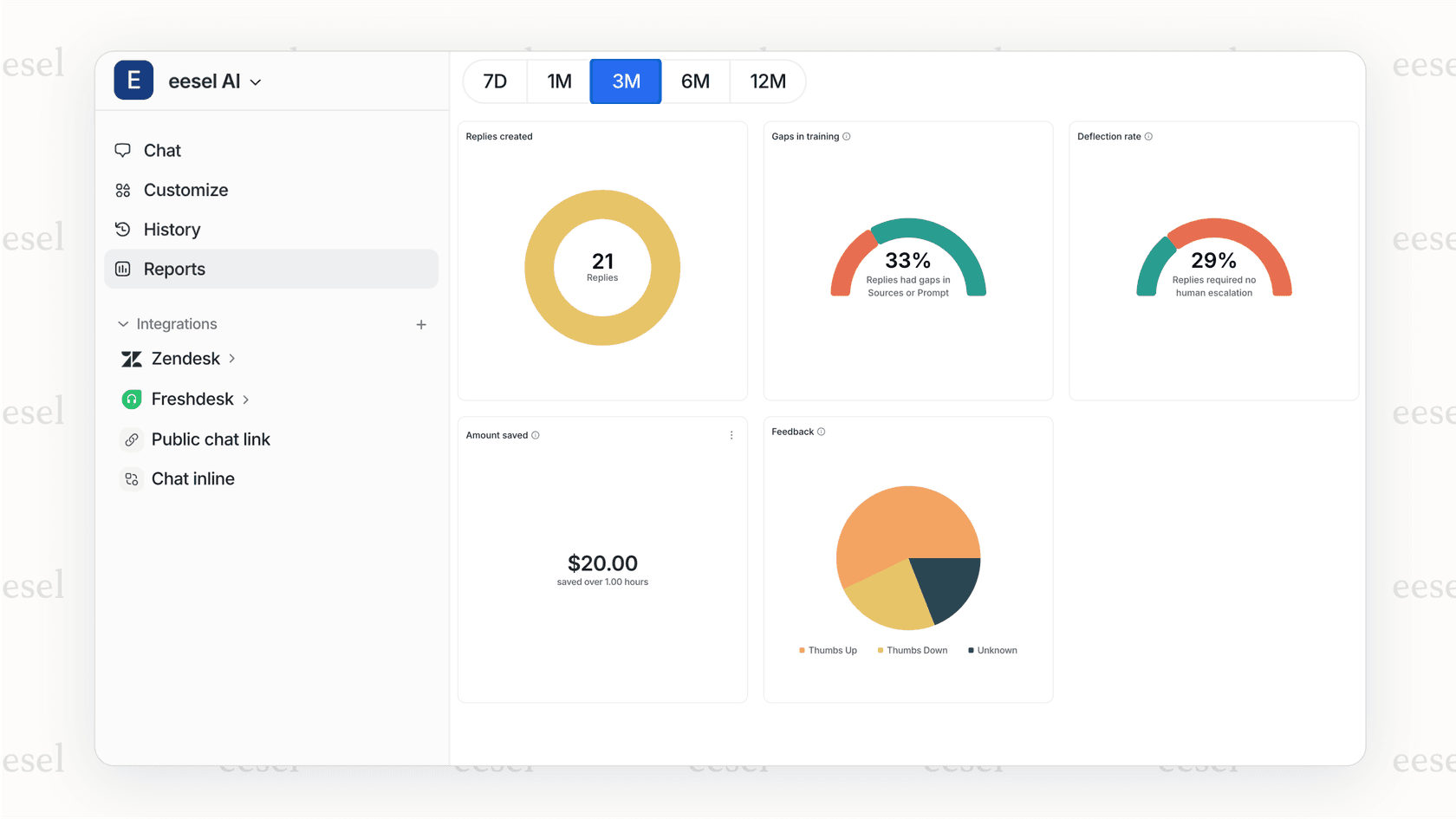
Unsere KI-Triage analysiert Ticketinhalte, Stimmung und Kundenhistorie, um Prioritäten vorzuschlagen oder automatisch festzulegen. Es erfasst Nuancen, die Keyword-Auslöser verpassen. Beispielsweise könnte "leicht besorgt über die Gebühr" von einem VIP-Kunden eine höhere Priorität rechtfertigen als die gleiche Nachricht von einem Benutzer der kostenlosen Testversion.
Die KI lernt aus Ihren vergangenen Ticketlösungen und Agentenaktionen und verbessert ihre Empfehlungen im Laufe der Zeit. Es lässt sich direkt in Zendesk integrieren, um Ihre bestehenden Prioritäts-Workflows zu verbessern, ohne sie zu ersetzen.
Sie können auch unseren KI-Agenten einsetzen, um Routineprobleme zu bearbeiten, bevor sie jemals eskaliert werden müssen. Er löst häufige Anfragen autonom und eskaliert nur das, was wirklich menschliche Aufmerksamkeit benötigt, wobei der vollständige Kontext erhalten bleibt.
Häufig gestellte Fragen
Share this article

Article by
Stevia Putri
Stevia Putri is a marketing generalist at eesel AI, where she helps turn powerful AI tools into stories that resonate. She’s driven by curiosity, clarity, and the human side of technology.


