Wofür Together AI Ihnen tatsächlich Kosten berechnet
Die meisten Beiträge zur Preisgestaltung versuchen, Together AI in ein Schema aus Build / Scale / Enterprise Stufen zu pressen. Die Preisseite funktioniert so jedoch nicht. Es gibt keine benannten Stufen. Es gibt keine Gebühr pro Benutzer. Es gibt keinen monatlichen Mindestumsatz für Self-Service. Was es stattdessen gibt, sind vier parallele Zähler, die jeweils eine andere Verbrauchseinheit messen. Jeder beliebige Arbeitsaufwand kann auf einem, zwei oder allen vier Zählern landen, je nachdem, wie Sie ihn bereitstellen.
Die vier Säulen:
- Serverless Inference - Sie rufen einen OpenAI-kompatiblen
/v1/chat/completionsEndpunkt auf, erhalten eine Antwort und zahlen pro Million Token für Input und Output. Dasselbe gilt für Chat, Vision, Image, Audio, Video, Transkription, Embeddings und Moderation, jeweils mit einer eigenen Rate pro Modell (Together AI Preise). - Dedicated Inference - Together stellt eine Single-Tenant GPU-Instanz für Sie bereit, die Sie rund um die Uhr betriebsbereit halten und pro GPU-Stunde bezahlen. Der Dedicated-Zähler ignoriert das Token-Volumen vollständig; Sie bezahlen für den reservierten Platz, nicht für die Nutzung.
- GPU Cluster - Sie mieten die reine NVIDIA-Hardware (8 bis 4.000+ GPUs, über InfiniBand verbunden) On-Demand oder reserviert für bis zu sechs Monate. Dies ist für Teams gedacht, die ihre eigenen Modelle trainieren oder eigene Inference-Engines betreiben.
- Fine-tuning - Das Training wird pro Token der Trainingsdaten abgerechnet, skaliert nach Modellgröße und Methode (LoRA, Full FT, DPO). Danach wird das resultierende Modell auf einem Dedicated Endpoint bereitgestellt, was einen eigenen stündlichen Zähler darstellt.
Dies ist wichtig, da die Wahl des richtigen Zählers das größte Sparpotenzial bietet. Ein Startup, das 5 Millionen Token pro Tag mit Llama 3.3 70B verarbeitet, hat auf einem Dedicated Endpoint nichts zu suchen; ein stabiler Produktions-Workload mit 500 Millionen Token pro Tag auf demselben Modell hingegen schon. Together AI CEO Vipul Ved Prakash beschreibt die Plattform als die "AI Acceleration Cloud", die zwischen diesen beiden Welten angesiedelt ist (LinkedIn), und die Preisstruktur spiegelt das wider: Serverless für den Start, Dedicated, wenn die Last vorhersehbar ist, und Cluster, wenn Sie trainieren.

Preise für Serverless Inference
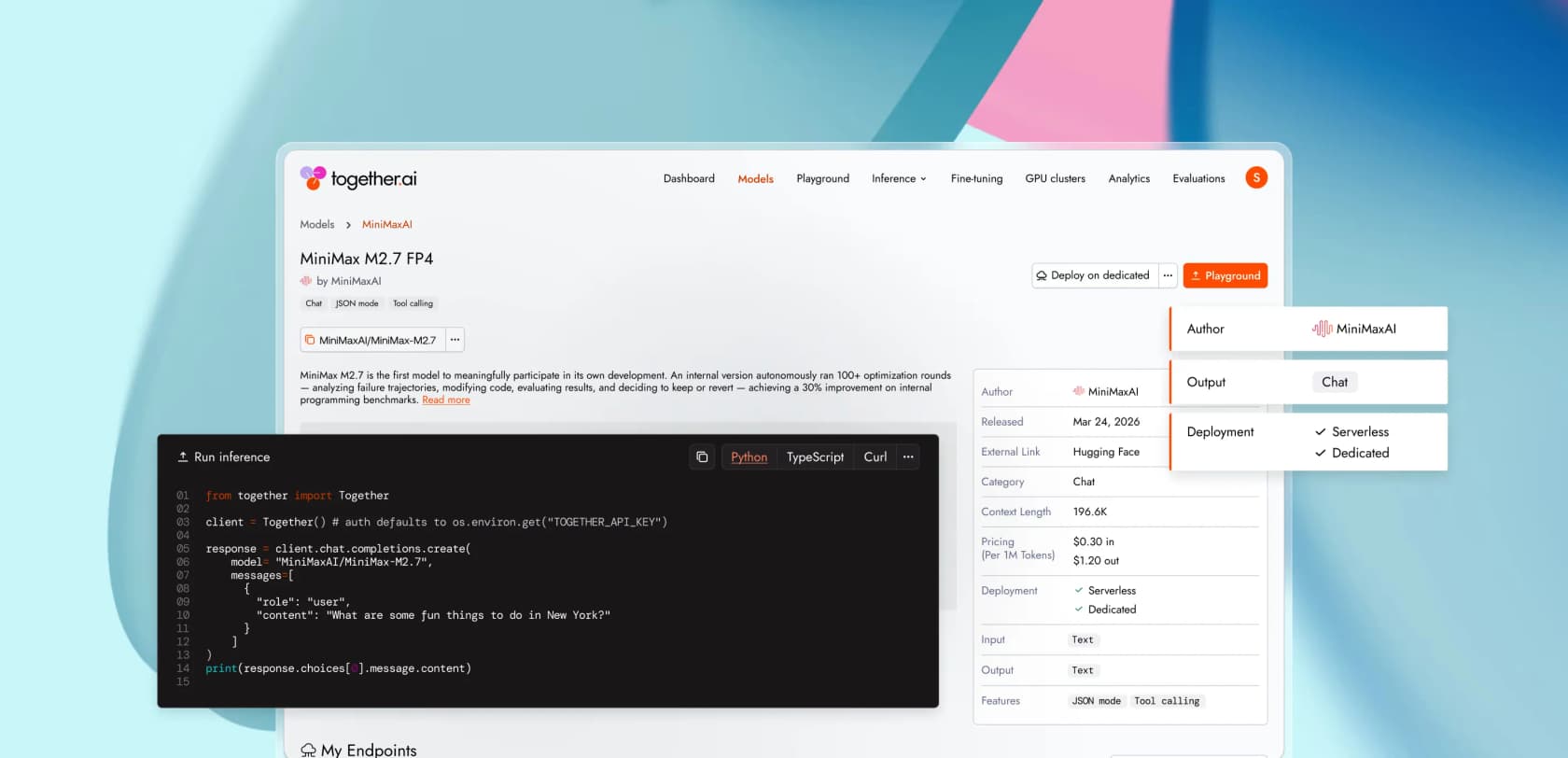
Serverless ist der Einstiegspunkt und der Zähler, den die meisten Teams nutzen werden. Die Chat-Modell-Tabelle auf together.ai/pricing listet die Raten pro Million Token für jedes unterstützte Modell auf, aufgeteilt in Input, Output und (bei einigen Modellen) eine Rate für Cached Input, die deutlich günstiger als die Basisrate ist.
Ein repräsentativer Ausschnitt aus dem Chat-Reiter, wörtlich übernommen (Together AI Preise):
| Modell | Input $/M | Output $/M | Cached Input $/M |
|---|---|---|---|
| GLM-5.1 | $1,40 | $4,40 | - |
| MiniMax M2.7 | $0,30 | $1,20 | $0,06 |
| Kimi K2.6 | $1,20 | $4,50 | $0,20 |
| DeepSeek V4 Pro | $2,10 | $4,40 | $0,20 |
| DeepSeek V4 Flash | - (kein Preis auf der Seite) | - | - |
| Qwen3.6-Plus | $0,50 | $3,00 | - |
| Qwen3.7-Max | $1,25 | $3,75 | $0,13 |
| gpt-oss-120B | $0,15 | $0,60 | - |
| gpt-oss-20B | $0,05 | $0,20 | - |
| Llama 3.3 70B | $1,04 | $1,04 | - |
| Qwen3 235B A22B FP8 Throughput | $0,20 | $0,60 | - |
| LFM2 24B A2B | $0,03 | $0,12 | - |
| Cogito v2.1 671B | $1,25 | $1,25 | - |
Drei Dinge sind an dieser Tabelle besonders bemerkenswert.
Erstens: Das Cached-Input-Pricing ist der Hebel, über den niemand spricht. Die Input-Kosten für DeepSeek V4 Pro sinken von $2,10/M auf $0,20/M, wenn das Prompt-Präfix zwischengespeichert wird - ein Rabatt von 10,5x. Bei Kimi K2.6 sind es 6x, bei MiniMax M2.7 5x. Wenn Ihr Workload einen langen System-Prompt wiederverwendet oder wiederkehrende Benutzerkontexte hat (was bei den meisten Agenten-Loops und RAG-Pipelines der Fall ist), ist die Cached-Rate der eigentliche Preis. Die Nicht-Cached-Zahl in der Tabelle ist der Worst Case.
Zweitens: Die Modell-Welle, auf der Sie reiten, ist wichtiger als der Anbieter. gpt-oss-20B und LFM2 24B stehen auf derselben Preisseite wie DeepSeek V4 Pro und GLM-5.1. Die 100-fache Lücke zwischen $0,03/M (LFM2 Input) und $4,50/M (Kimi K2.6 Output) ist viel größer als die Lücke zwischen Together und seinen Konkurrenten beim gleichen Modell. Die Aussage "Together ist billig" ist nicht hilfreich; "dieses spezifische Modell ist auf Together billig" ist es meistens schon.
Drittens: Vision, Image, Audio und Video haben jeweils separate Zähler pro Modell - Bildmodelle werden pro Megapixel oder pro Bild berechnet (FLUX.2 [pro] kostet $0,03/Bild; Google Imagen 4.0 Ultra kostet $0,06/MP), Videomodelle pro fertigem Video (Sora 2 kostet $0,80, Google Veo 3.0 mit Audio $3,20) und Audio ist aufgeteilt in pro Minute (Whisper Large v3 für $0,0015) und pro 1 Million Zeichen (Cartesia Sonic-3 für $65) (Together AI Preise). Wenn Sie eine multimodale App bauen, nutzen Sie mehrere Zähler gleichzeitig, und Ihre "Together-Rechnung" ist die Summe daraus, nicht eine einzelne Rate.
Der Serverless-Einstieg umfasst auch eine Batch API: Verarbeiten Sie bis zu 30 Milliarden Token pro Modell asynchron bei bis zu 50 % niedrigeren Kosten als bei synchroner Serverless-Nutzung (Batch Inference API Updates 2025). Für Workloads, die keine Echtzeit-Latenz benötigen - Generierung synthetischer Daten, Offline-Klassifizierung, Log-Anreicherung - ist Batch der günstigste offizielle Weg auf der Plattform.
Together bewirbt die Serverless-Stufe sowohl über die Geschwindigkeit als auch über den Preis. Auf der Inference-Produktseite lauten die veröffentlichten Vergleiche: "bis zu 2,75x schneller" bei Qwen3 235B 2507, "über 65 % schneller" bei Kimi K2 0905 und "2x schneller" bei gpt-oss-20B im Vergleich zum jeweils nächstschnellsten Anbieter im Benchmark. Höhere Token-pro-Sekunde-pro-GPU sind letztlich das, was es Together ermöglicht, weniger zu verlangen und trotzdem profitabel zu sein - es ist dieselbe Hardware, die nur mehr Arbeit pro Sekunde leistet.
Unsere Forscher und Ingenieure setzen alles daran, die KI-Inferenz so weit zu beschleunigen, wie es die Gesetze der Physik zulassen.
Ce Zhang, CTO, via Ryan Pollock auf LinkedIn
Preise für Dedicated Inference
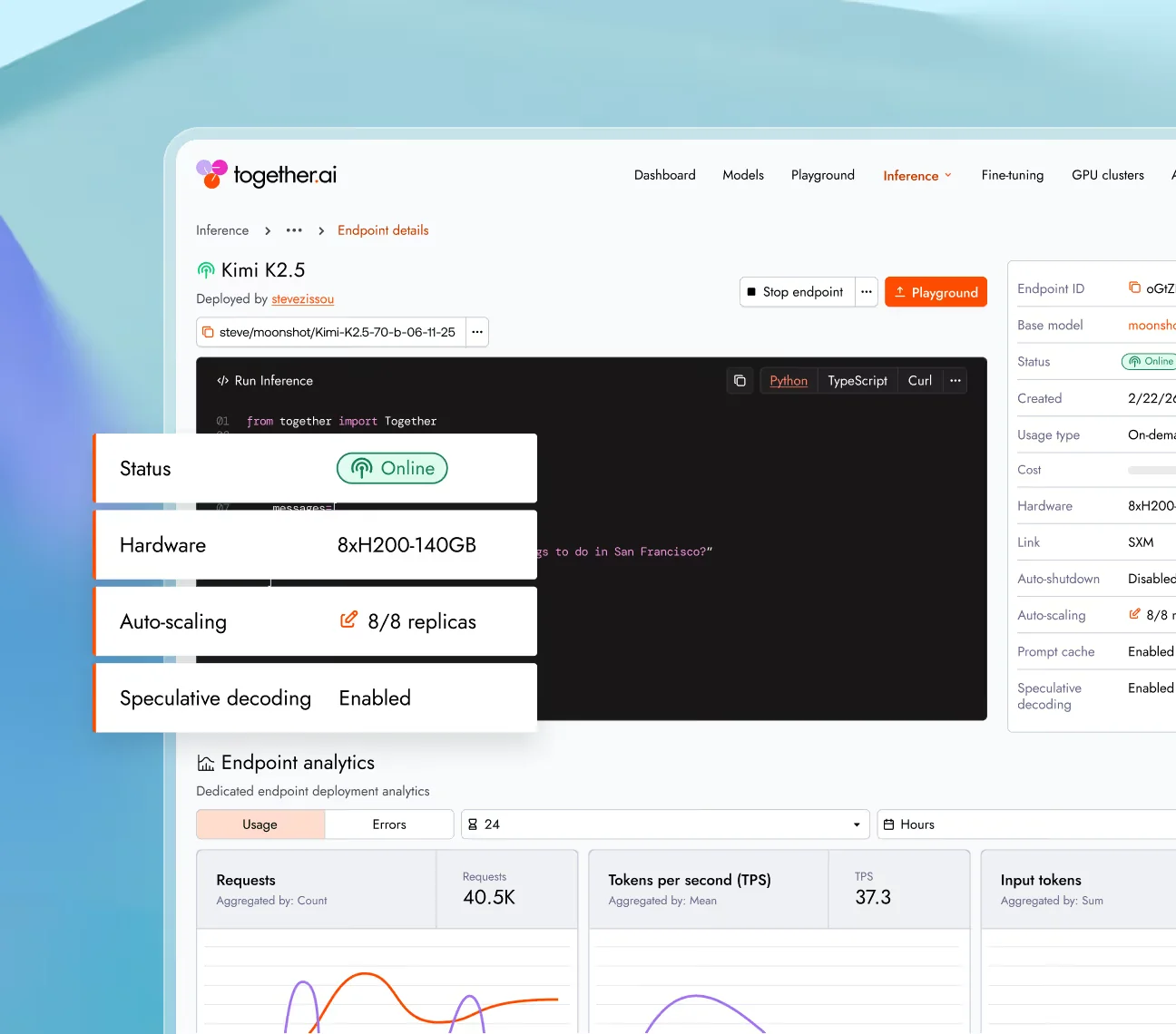
Sobald Ihr Workload aus der geteilten Serverless-Infrastruktur herauswächst - oder, was häufiger vorkommt, sobald unvorhersehbare Latenzen zum Problem für das Produkt werden - ermöglichen Ihnen die Dedicated Endpoints von Together AI, eine Single-Tenant GPU-Instanz bereitzustellen und stündlich zu bezahlen (Together AI Preise):
| Hardware | Preis pro Stunde |
|---|---|
| 1× H100 80 GB | $6,49 |
| 1× H200 140 GB | Kontaktieren Sie uns |
| 1× HGX B200 180 GB | $11,95 |
Die Rechnung ist in einer Hinsicht gnadenlos. Eine H100, die 24 Stunden am Tag und 30 Tage im Monat läuft, kostet $4.672,80/Monat pro GPU. Eine B200 im gleichen Zeitraum kostet $8.604. Das Token-Volumen ist irrelevant - selbst bei null Anfragen läuft der Zähler weiter.
In der anderen Hinsicht ist sie jedoch ebenso vorteilhaft. Bei einem ausreichend hohen Anfragevolumen sinken die effektiven Kosten pro Token auf einem Dedicated Endpoint unter die Serverless-Rate. Der Break-even-Punkt hängt vom Modell ab, aber als grobe Faustregel für ein Modell der 70B-Klasse bei Serverless-Kosten von $1,04/M Token in beide Richtungen fangen Sie an zu sparen, wenn Sie mehr als ca. 5 Milliarden Token pro Monat an stetigem, vorhersagbarem Traffic haben. Darunter gewinnt Serverless fast immer bei den Kosten; darüber gewinnt Dedicated und Sie profitieren zusätzlich von konsistenten Latenzen.
Das Forschungsteam von Salesforce ist einer der öffentlich genannten Referenzpunkte für diese Stufe:
Wir sind von Together absolut beeindruckt. Sie haben eine Reduzierung der Latenz um das Zweifache geliefert und unsere Kosten um etwa ein Drittel gesenkt.
Caiming Xiong, VP, Salesforce AI Research, Together AI Inference-Seite
Wenn Sie Dedicated in Betracht ziehen, lautet die Frage, die Sie beantworten müssen, nicht: "Ist die H100 von Together für $6,49/Std. billiger als Anbieter X?" - sondern: "Habe ich einen ausreichend konstanten Workload, sodass es billiger ist, eine GPU rund um die Uhr zu bezahlen, als für Token zu zahlen, die hauptsächlich während der Geschäftszeiten anfallen?" Für viele Teams lautet die ehrliche Antwort: Nein.
Preise für GPU-Cluster - On-Demand vs. Reserviert
Unterhalb der Dedicated Endpoints liegt die elementarste Ebene des Stacks: gemietete GPU-Cluster, die Sie selbst betreiben (gpu-clusters). Hier landen Teams, die ihre eigenen Modelle trainieren, eigene Inference-Engines betreiben oder über die Möglichkeiten von Dedicated Endpoints hinaus skalieren.
Preise für On-Demand Cluster (Self-Service, Pay-as-you-go, jederzeit kündbar, bis zu 256 GPUs) (Together AI Preise):
| Hardware | Preis pro GPU pro Stunde |
|---|---|
| NVIDIA HGX H100 | $5,49 |
| NVIDIA HGX H200 | $6,79 |
| NVIDIA HGX B200 | $9,95 |
Preise für reservierte Cluster sinken mit der Dauer, mit einer maximal veröffentlichten Bindung von 180 Tagen; alles darüber hinaus wird über ein GPU-Cluster-Anfrageformular für individuelle Unternehmenspreise abgewickelt (Together AI Preise):
| Hardware | 7-30 Tage | 31-90 Tage | 91-180 Tage | 181+ Tage |
|---|---|---|---|---|
| NVIDIA HGX H100 | $4,99 | $4,49 | $3,99 | Kontaktieren Sie uns |
| NVIDIA HGX H200 | $5,95 | $4,99 | $4,55 | Kontaktieren Sie uns |
| NVIDIA HGX B200 | $9,65 | $9,35 | $9,09 | Kontaktieren Sie uns |
| NVIDIA GB200 NVL72 | Kontaktieren Sie uns | Kontaktieren Sie uns | Kontaktieren Sie uns | Kontaktieren Sie uns |
| NVIDIA GB300 NVL72 | Kontaktieren Sie uns | Kontaktieren Sie uns | Kontaktieren Sie uns | Kontaktieren Sie uns |
Drei Dinge machen die Cluster-Stufe im Vergleich zur GPU-Miete bei einem Hyperscaler interessant.
Erstens: Bare-Metal-Performance mit durchgängigem InfiniBand-Interconnect. Together wirbt damit, dass "unser InfiniBand-Interconnect die Gradientensynchronisation schnell und den Kommunikations-Overhead gering hält - damit Ihre Trainingsläufe schneller fertig werden, nicht nur größer" (Together AI gpu-clusters). Das ist wichtig, denn ein um 30 % schnellerer Trainingslauf auf derselben Hardware bedeutet effektiv einen Rabatt von 30 % auf denselben Stundensatz.
Zweitens: Die Together Kernel Collection wird mit dem Cluster ausgeliefert. TKC (entwickelt vom Chief Scientist Tri Dao, dem Schöpfer von FlashAttention) ist dieselbe Optimierungsschicht, die die Serverless Inference von Together antreibt, und sie ist auch auf Clustern verfügbar. Der veröffentlichte Benchmark: "Das Training eines Modells mit 70B Parametern (Llama-Architektur, BF16) mit einem optimierten TorchTitan + Together Kernel Collection (TKC) erreichte 15.264 Token/Sekunde/GPU auf NVIDIA HGX B200, gegenüber 8.080 Token/Sekunde auf NVIDIA HGX H100 - ein Sprung von 90 % in der Trainingsgeschwindigkeit" (Together AI gpu-clusters).
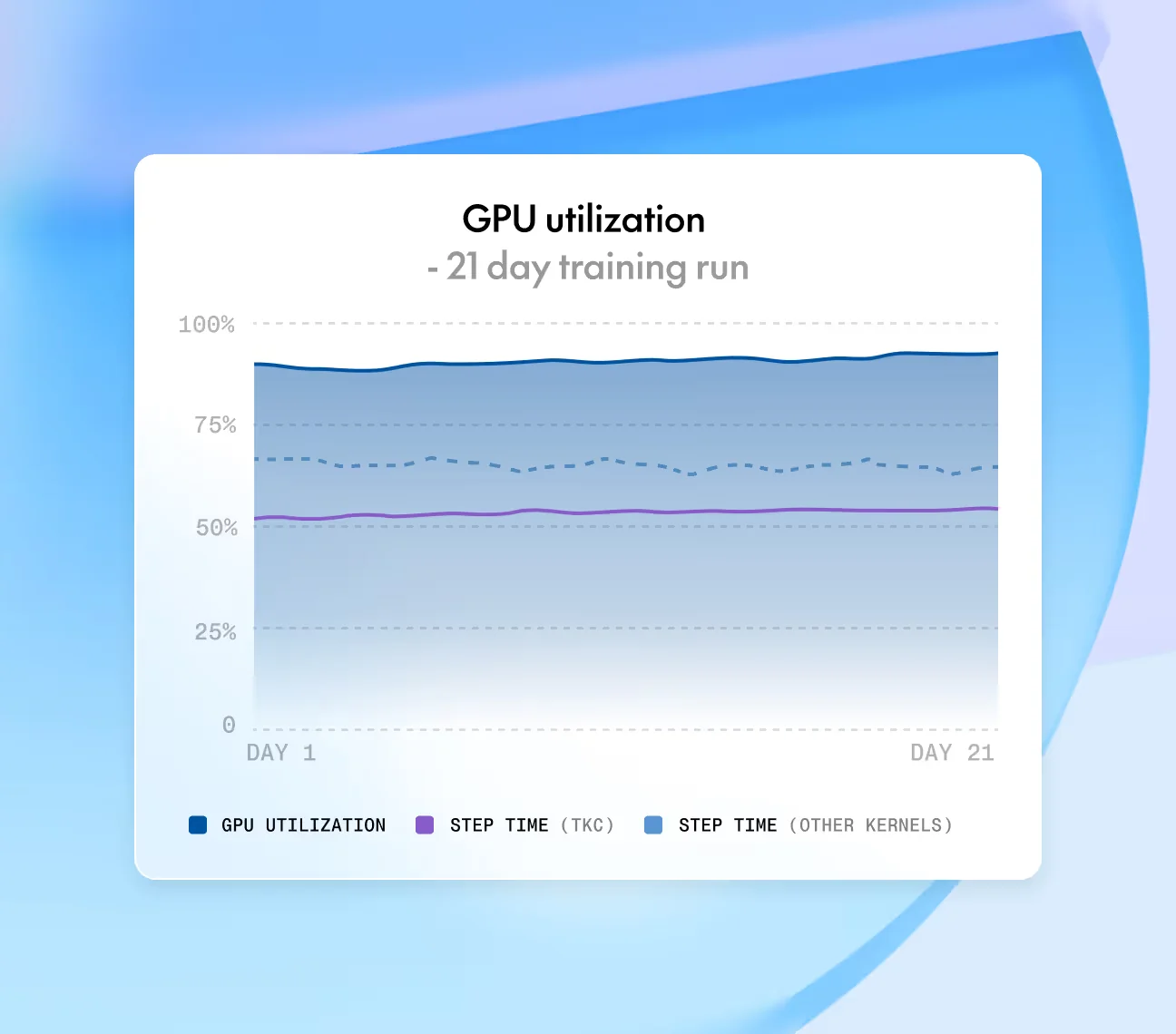
Drittens: Speicher ist kein Nebengedanke. Cluster werden mit parallelen Weka- oder VAST-Dateisystemen für $0,16/GiB/Monat ohne Egress-Gebühren ausgeliefert (Together AI Preise). Jeder, der schon einmal aus Frust über S3-Egress-Gebühren bei einem Hyperscaler aufgegeben hat, wird verstehen, warum das wichtig ist.
Together AI bietet die Leistung und Zuverlässigkeit, die wir für hochwertige Bild- und Videogenerierung in Echtzeit in großem Maßstab benötigen.
Victor Perez, Co-Founder, Krea, Together AI gpu-clusters
Fine-tuning Preise - und die Hosting-Kosten, vor denen niemand warnt
Fine-tuning bei Together wird pro Token der Trainingsdaten abgerechnet, nicht pro Epoche und nicht pro GPU-Stunde (Together AI Fine-tuning Docs). Die Rechnung auf der Preisseite ist explizit: "Der Preis basiert auf der Summe der verarbeiteten Token im Fine-tuning-Trainingsdatensatz (Größe des Trainingsdatensatzes × Anzahl der Epochen) zuzüglich etwaiger Token im optionalen Evaluierungsdatensatz (Größe des Validierungsdatensatzes × Anzahl der Evaluierungen)" (Together AI Preise).
Die Standard-Preistabelle skaliert nach der Größe des Basismodells und der Tuning-Methode (Together AI Preise):
| Basismodell-Größe | SFT - LoRA | SFT - Full | DPO - LoRA | DPO - Full |
|---|---|---|---|---|
| Bis zu 16B | $0,48 / M | $0,54 / M | $1,20 / M | $1,35 / M |
| 17B–69B | $1,50 / M | $1,65 / M | $3,75 / M | $4,12 / M |
| 70B–100B | $2,90 / M | $3,20 / M | $7,25 / M | $8,00 / M |
Ab 100B Parametern bepreist Together das Fine-tuning pro Modell in einer "spezialisierten" Stufe, oft mit einer Mindestgebühr pro Job (Together AI Preise):
| Modell | SFT (LoRA) | DPO (LoRA) | Minimum |
|---|---|---|---|
| DeepSeek-R1 / V3 / V3.1 Familie | $10,00 / M | $25,00 / M | $20,00 |
| GLM-4.6 / 4.7 | $9,00 / M | $22,50 / M | $27,00 |
| GLM-5 / GLM-5.1 | $40,00 / M | $100,00 / M | $60,00 |
| gpt-oss-120B | $5,00 / M | $12,50 / M | $6,00 |
| Kimi K2 (Thinking / Instruct / Base) | $15,00 / M | $37,50 / M | $60,00 |
| Llama 4 Maverick / Maverick Instruct | $8,00 / M | $20,00 / M | $16,00 |
| Llama 4 Scout | $3,00 / M | $7,50 / M | $6,00 |
| Qwen3-Coder-480B-A35B-Instruct | $9,00 / M | $22,50 / M | $18,00 |
| Qwen3-235B-A22B / Instruct-2507 | $6,00 / M | $15,00 / M | Kein Min. |
| Qwen3.5-122B-A10B | $6,00 / M | $15,00 / M | $10,00 |
| Qwen3.5-397B-A17B | $8,00 / M | $20,00 / M | $22,00 |
Die obige Tabelle ist diejenige, die am häufigsten zitiert wird. Was viele jedoch vergessen: Sobald das Modell trainiert ist, stellt das Hosting eine separate, laufende Gebühr dar.
Aus der Dokumentation: "Sobald das Training abgeschlossen ist, wird die Inferenz auf einem Dedicated Endpoint ausgeführt" (Together AI Docs). Dieser Dedicated Endpoint wird zu den gleichen Raten wie die Dedicated Inference-Stufe abgerechnet - $6,49/Std. für eine H100 oder $11,95/Std. für eine B200 (Together AI Preise). Ein LoRA auf einer 16B-Basis mag für weniger als einen Dollar pro Million Trainings-Token trainiert werden, aber das Bereitstellen des resultierenden Modells auf einer einzelnen H100 rund um die Uhr kostet etwa $4.700/Monat pro GPU, egal ob in diesem Monat eine einzige Anfrage bearbeitet wird oder nicht.
Dies ist die größte Preisfalle auf der Plattform. Teams kalkulieren routinemäßig: "Das Fine-tuning wird uns $30 für den Durchlauf kosten" - was korrekt ist - und stellen dann fest, dass die Hosting-Rechnung um zwei Größenordnungen höher ausfällt. Planen Sie den gesamten Lebenszyklus, nicht nur den Trainingsschritt.
Ein paar andere Details zum Fine-tuning, die leicht übersehen werden:
- Keine beworbene kostenlose Stufe. Jeder Trainingslauf wird ab dem ersten Token pro Token abgerechnet.
- LoRA ist der Standard, Full Fine-tuning ist optional. Die Preisunterschiede zwischen LoRA und Full sind gering (ca. $0,30/M in der 70B-Stufe), sodass die Entscheidung meistens wegen der Qualität und nicht wegen der Kosten getroffen wird.
- DPO kostet etwa das 2,5-fache von SFT über alle Größenklassen hinweg. Wenn Sie ein Modell an Präferenzen anpassen, kalkulieren Sie entsprechend.
- BYOM (Bring Your Own Model) ermöglicht es Ihnen, eine eigene Basis außerhalb des Katalogs hochzuladen. Die Preise für das BYOM-Training fallen in die jeweils passende Standard-Größenkategorie; das Hosting erfolgt zu den üblichen Dedicated-Raten.
Sandbox, Code-Interpreter und Managed Storage
Zwei kleinere Zähler sind erwähnenswert, da sie viele Agenten-Entwickler überraschen.
Code Sandbox ermöglicht es Ihnen, isolierte VM-Sandboxes für KI-Agenten zur Codeausführung zu starten. Die Abrechnung erfolgt pro virtueller CPU und pro GiB Arbeitsspeicher pro Stunde (Together AI Preise):
| Ressource | Preis pro Stunde |
|---|---|
| Pro vCPU | $0,0446 |
| Pro GiB RAM | $0,0149 |
Eine bescheidene Sandbox mit 4 vCPUs und 8 GiB RAM, die für einen Arbeitstag (8 Stunden) bereitgehalten wird, kostet etwa $2,39 - einzeln betrachtet ein kleiner Betrag, aber für eine Agenten-Flotte, die Dutzende davon parallel startet, können sich die Gesamtkosten schnell summieren.
Code Interpreter ist die leichtere Variante: eine Einzelsitzungs-Sandbox zur Ausführung von LLM-generiertem Code ohne Vorhalteaufwand, bepreist mit $0,03 pro 60-Minuten-Sitzung (Together AI Preise). Dies ist der vernünftige Standard für die meisten Agenten-Tool-Flows.
Managed Storage ist das parallele Dateisystem, das neben den Clustern existiert. Es kostet $0,16 pro GiB pro Monat ohne Egress-Gebühren (Together AI Preise). Ein Arbeitsdatensatz von 10 TB kostet etwa $1.638/Monat - vergleichbar mit einem Hochleistungsdateisystem eines Hyperscalers, aber ohne die Bandbreitenrechnung beim Datenexport.
Was kostenlos ist (und was nicht)
Dieser Teil ist kurz, da es nicht viel gibt.
- Keine beworbene kostenlose Stufe auf der öffentlichen Preisseite. Dort werden weder ein Anmeldeguthaben noch ein kostenloser Testzeitraum oder ein monatliches Freikontingent aufgeführt.
- Die Batch API ist der einzige direkte Rabattmechanismus: bis zu 50 % Rabatt auf die meisten Chat-Modelle für asynchrone Workloads (Batch Inference API Updates 2025).
- Mengenrabatte / Committed-Use-Rabatte existieren, sind aber nicht veröffentlicht - die Seite verweist für Unternehmenspreise auf Kontakt.
- Cached Input ist das, was einer Gratisleistung am nächsten kommt: Ein 5- bis 10-facher Rabatt auf Input-Token für ausgewählte Chat-Modelle, wenn Präfixe wiederverwendet werden.
Anwender haben in der Vergangenheit von einem Startguthaben berichtet:
Ein Gratisguthaben von 25 $ reicht weit, wenn selbst die teuersten Modelle nur $0,9/Million Token kosten.
Chris Samiullah, ML Ingenieur, LinkedIn
Dieser Betrag ist derzeit nicht als allgemeine Richtlinie auf der Preisseite veröffentlicht. Wenn Sie ein Budget planen, behandeln Sie das Guthaben eher als "Fragen Sie Ihren Account Manager" und nicht als "garantiert".
Wie Together AI im Vergleich zu Fireworks, Groq, Replicate und anderen abschneidet
Die ehrliche Antwort lautet: "Ist Together am günstigsten?" hängt ganz von dem Modell ab, das Sie verwenden, dem Durchsatz, den Sie benötigen, und davon, ob Sie Serverless oder Dedicated nutzen. Hier ist ein direkter Vergleich für die gängigsten geteilten Modelle, basierend auf den Raten der jeweiligen Anbieter-Preisseiten am 05.06.2026:
| Anbieter | Llama 3.3 70B In / Out $/M | DeepSeek R1 In / Out $/M | Mixtral 8x22B In / Out $/M | Gratis-Guthaben | Preismodell |
|---|---|---|---|---|---|
| Together AI | $1,04 / $1,04 | DeepSeek V4 Pro: $2,10 / $4,40 (Cached $0,20 Input) | Nicht im aktuellen Lineup | Keine beworben; Batch 50 % Rabatt | Per-Token Serverless, per-GPU-Stunde Dedicated |
| Fireworks AI | $0,90 / $0,90 (>16B Bucket) | DeepSeek V4 Pro: $1,74 / $3,48 | $1,20 / $1,20 (MoE 56-176B) | $1 Gratis-Guthaben | Per-Token Serverless, per-GPU-Sekunde On-Demand |
| Groq | $0,59 / $0,79 | Nicht im Lineup | Nicht im Lineup | Gratis Konsolen-Anmeldung | Per-Token Serverless |
| Replicate | Per Hardware-Sekunde | $3,75 / $10,00 | Per Hardware-Sekunde | Keine beworben | Per Hardware-Sekunde + per-Token für ausgewählte Modelle |
| Anyscale | Eigene Bereitstellung auf H100 für $9,29/Std. | Gleich | Gleich | $100 Guthaben | Pro GPU-Stunde (Anyscale Compute Units) |
| Modal | Eigenbereitstellung auf H100 ca. $3,95/Std. äquiv. | Gleich | Gleich | $30/Mon. Starter, $100/Mon. Team | Pro Sekunde Compute |
| Hugging Face | Weiterleitung an Inferenz-Anbieter | Weiterleitung | Weiterleitung | PRO $9/Mon. + gratis ZeroGPU | Pro Stunde Endpoints + Weiterleitung Token |
| OpenRouter | $0,10 / $0,32 | $0,50 / $2,15 (R1 0528) | $2,00 / $6,00 | Gratis ratenlimitierte Varianten | Per-Token Marketplace |
Einige Muster lassen sich aus dieser Tabelle ableiten.
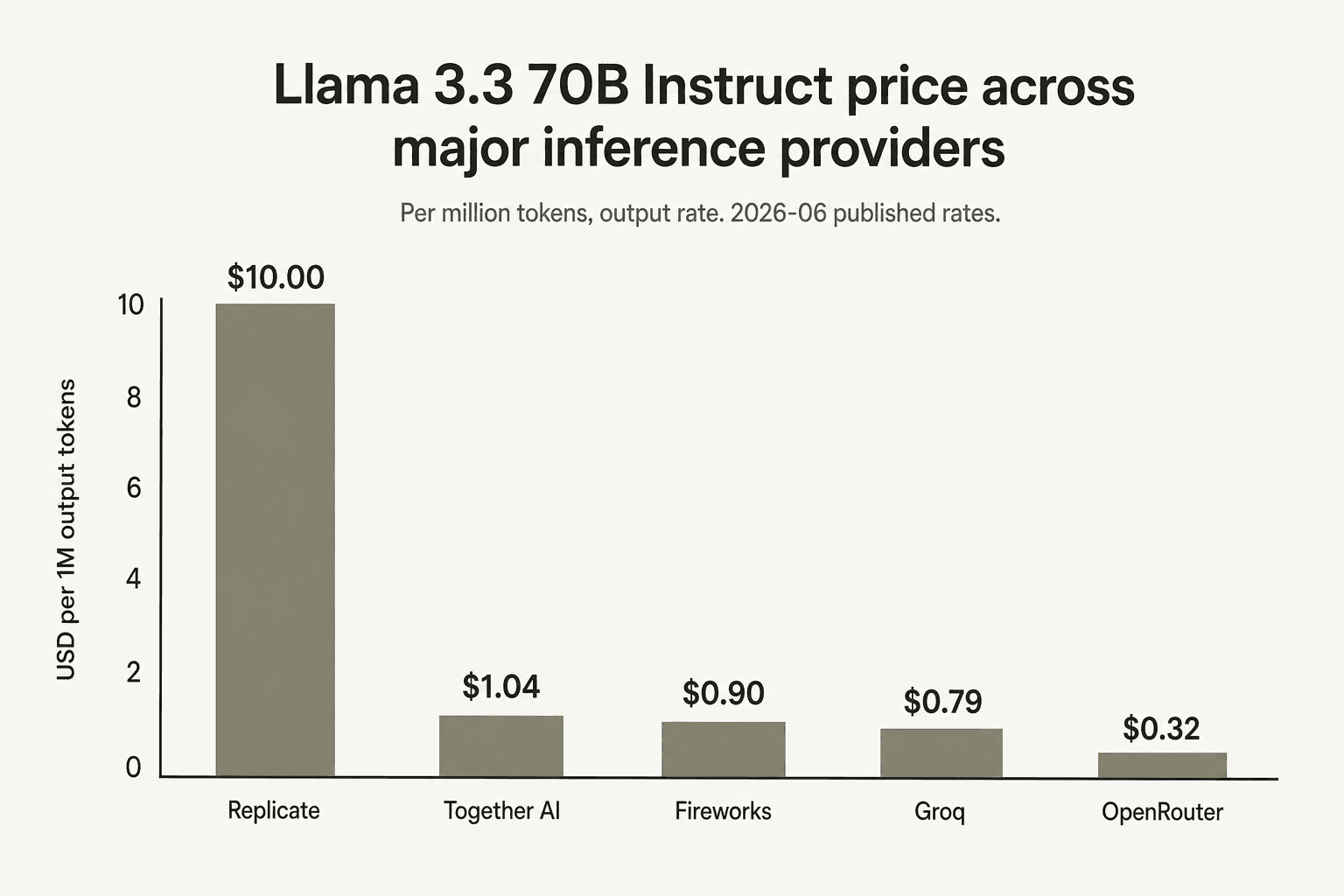
Speziell bei Llama 3.3 70B liegt Together AI im Mittelfeld. Groq ist der günstigste First-Party-Anbieter für dieses beliebte bewährte Modell ($0,59/$0,79), Fireworks folgt ($0,90 pauschal), Together liegt an dritter Stelle ($1,04/$1,04), Replicate listet es gar nicht pro Token auf und OpenRouter - ein Marktplatz, der zum günstigsten Anbieter weiterleitet - unterbietet alle mit $0,10/$0,32. Wenn Ihr Workload aus "viel Llama 3.3 70B Inferenz" besteht, verdienen Groq und der OpenRouter-Marktplatz einen genaueren Blick.
Bei den Modellen der neuen Generation - Kimi K2.6, GLM-5.1, DeepSeek V4, Qwen3.6-Plus - ist Together konkurrenzfähig, aber nicht immer am günstigsten. Fireworks neigt dazu, seine neueren Kimi- und DeepSeek-Modelle einzeln mit Cached-Input-Raten aufzulisten, die die von Together erreichen oder unterbieten. Der Unterschied liegt meist bei 10-30 % und nicht bei der 5- bis 10-fachen Lücke, die manchmal in Marketing-Texten auftaucht.
Für Dedicated GPU-Hosting ist die Landschaft breiter gefächert. Modal unterbietet fast jeden bei der sekundengenauen Abrechnung (H100 ≈ $3,95/Std. Äquivalent bei $0,001097/Sek.). Hugging Face Endpoints veröffentlicht $4,50/Std. für eine H100. Together liegt bei $6,49/Std. für Dedicated Inference, $5,49/Std. für einen On-Demand-Cluster und $3,99/Std. für einen reservierten Cluster (91-180 Tage). Unterschiedliche Produkte, unterschiedliche Abrechnungen - und Ihre tatsächlichen Kosten hängen davon ab, ob Sie die operative Komplexität einer eigenen vLLM-Bereitstellung auf Modal bewältigen können oder ob Sie Together das Hosting eines Modells für Sie überlassen.
Bei Embeddings gehört Together zu den günstigsten Anbietern mit $0,02/M Token (Multilingual e5 large instruct) (Together AI Preise). Together hat in der Vergangenheit mit "bis zu 4x niedrigeren Kosten als OpenAI" bei Embeddings geworben (@togethercompute auf X), und die aktuellen Raten liegen in diesem Bereich.
Für Batch-Workloads ist der 50 % Batch API Rabatt von Together das Hauptargument. Fireworks bietet ebenfalls 50 % Rabatt, ebenso wie Groq. Replicate, Modal und Anyscale haben keine vergleichbare Stufe für asynchrone Rabatte.
Für detailliertere Anbieter-Analysen finden Sie unsere Aufschlüsselungen zu Fireworks AI Preisen, Baseten Preisen und SambaNova Cloud Preisen direkt neben dieser. Die Kurzfassung: Wählen Sie den günstigsten Anbieter für das spezifische Modell, das Sie einsetzen, nicht den günstigsten Anbieter im Abstrakten.
Drei Praxisbeispiele dafür, was Teams tatsächlich zahlen
Token-Mathematik ist billig; die Rechnung am Ende des Monats ist das, was zählt. Hier sind drei Szenarien mit echten Zahlen.
Beispiel 1 - Ein SaaS-Team mit einem produktinternen Chat-Assistenten auf Basis von Llama 3.3 70B
Traffic: 5.000 Konversationen/Tag, durchschnittlich 1.500 Input-Token (System-Prompt + abgerufener Kontext) und 400 Output-Token pro Konversation. Etwa 21 Arbeitstage pro Monat.
Serverless-Rechnung bei Together ($1,04/M Input + $1,04/M Output):
- Input: 5.000 × 1.500 × 21 = 157,5M Token × $1,04 = $163,80/Mon.
- Output: 5.000 × 400 × 21 = 42M Token × $1,04 = $43,68/Mon.
- Gesamt: ca. $207/Mon. für die Inferenz-Zeile
Wenn dasselbe Team stattdessen Groq wählt ($0,59 Input / $0,79 Output):
- 157,5M × $0,59 + 42M × $0,79 = $92,92 + $33,18 = ca. $126/Mon.
Wenn sie über OpenRouter gehen ($0,10 Input / $0,32 Output):
- 157,5M × $0,10 + 42M × $0,32 = $15,75 + $13,44 = ca. $29/Mon.
Fazit: Bei diesem Volumen sind die reinen Inferenzkosten so gering, dass die Entscheidung wahrscheinlich aufgrund von Latenz, regionaler Zuverlässigkeit oder Support-Reaktionszeit getroffen wird - nicht wegen der Inferenzrate.
Beispiel 2 - Ein KI-Startup mit einem Kimi K2.6 Agenten-Loop in großem Maßstab
Traffic: 200M Input-Token/Tag, 50M Output-Token/Tag, wobei etwa 80 % des Inputs cachebar sind (langer System-Prompt + wiederverwendete Tool-Definitionen). 30 Tage pro Monat.
Together-Rechnung mit berücksichtigtem Cached-Pricing:
- Input (cached): 200M × 0,80 × 30 × $0,20/M = $960/Mon.
- Input (uncached): 200M × 0,20 × 30 × $1,20/M = $1.440/Mon.
- Output: 50M × 30 × $4,50/M = $6.750/Mon.
- Gesamt: ca. $9.150/Mon.
Ohne den Cached-Input-Rabatt würde allein der Input-Teil $7.200 kosten. Der Cached-Hebel ist in diesem Szenario also etwa $5.800/Monat wert. Die meisten Teams unterschätzen, wie groß der Cached-Input-Rabatt ist, da die meisten Preisvergleiche die Uncached-Rate zitieren.
Beispiel 3 - Ein Team, das Llama 4 Scout feinabstimmt und rund um die Uhr hostet
Training: 500M Token Trainingsdaten auf Llama 4 Scout. Aus der spezialisierten Stufe ergibt sich $3,00/M LoRA SFT mit einem Minimum von $6.
- Trainingskosten: 500 × $3,00 = $1.500 einmalig
Hosting: 1× H100 Dedicated Endpoint für die Produktion.
- $6,49/Std. × 24 Std. × 30 Tage = $4.672,80/Mon., jeden Monat
Gesamtrechnung im ersten Monat: $1.500 + $4.672,80 ≈ $6.173. Ab dem zweiten Monat: $4.673.
Die Trainingskosten scheinen das Hauptargument zu sein. Die Hosting-Kosten sind die tatsächliche monatliche Rechnung. Wenn Sie das feinabgestimmte Modell auf bestehender Dedicated-Kapazität hosten können oder wenn Ihr Traffic Serverless auf dem Basismodell + gezieltes Prompt-Engineering statt eines vollständigen Fine-tunings rechtfertigt, können Sie die Zeile von $4.673 komplett streichen. Planen Sie den Lebenszyklus.

Wo die Preise von Together Teams unvorbereitet getroffen haben
Der konsistenteste Kritikpunkt in den negativen Bewertungen auf G2 und Trustpilot betrifft nicht die Raten selbst, sondern die Abrechnungsmechanismen. Drei spezifische Beschwerden treten immer wieder auf.
Nicht erstattete Autorisierungsgebühren. Mehrere Trustpilot-Rezensenten beschreiben, dass beim Hinzufügen einer Kreditkarte eine Autorisierungsgebühr von $1 erhoben wurde, die eigentlich rückgängig gemacht werden sollte, aber nie erstattet wurde:
Beim Hinzufügen einer Kreditkarte hieß es ausdrücklich: „Es wird eine sofortige Gebühr von $1 zur Autorisierung erhoben, die wieder gutgeschrieben wird.“ Ich habe meine Kreditkarte hinzugefügt, mir wurde $1 berechnet, aber ich habe es nie zurückerhalten.
Trustpilot-Rezensent, Together AI auf Trustpilot
Abbuchungen in kurzen Intervallen und mangelhafte Erstattungsabwicklung. Ein weiterer Thread zu Abrechnungsmustern:
Die Kreditkarte wurde im Sekundentakt mit seltsamen Beträgen belastet - ich musste die Karte notfallmäßig sperren. Support nicht erreichbar.
Trustpilot-Rezensent, Together AI auf Trustpilot
Nach 2 Wochen haben sie das verbleibende Guthaben auf meinem Prepaid-Konto immer noch nicht zurückerstattet, ebenso wenig wie den Betrag für die Fehlersuche bei dem deaktivierten API-Schlüssel.
G2-Rezensent, Together AI auf G2
Dies sind keine typischen Erfahrungen für den Durchschnittskunden - die meisten G2-Bewertungen sind positiv - aber sie sind konsistent genug, dass die negativen Cluster eindeutig um Abrechnung und Support-Antworten kreisen, nicht um fehlende Funktionen. Wenn Sie ein kleines Team ohne Account Manager sind, richten Sie eine separate Firmenkarte mit einem engen Limit ein und laden Sie keine großen Guthabenbeträge im Voraus auf.
Überraschung beim Fine-tuning-Hosting. Wie oben erwähnt, aber eine Wiederholung wert: Die Kosten für das Betreiben eines feinabgestimmten Modells betragen bei jedem vernünftigen monatlichen Volumen oft das 50- bis 200-fache der Kosten für das Training. Dies trifft viele Teams unvorbereitet. Der Dedicated-Endpoint-Zähler pausiert nicht, wenn das Modell im Leerlauf ist.
Ingenieurszeit ist der größte unsichtbare Kostenfaktor. Aus einer wiederkehrenden Kritik von Anwendern auf LinkedIn und X zum Thema Together AI Preise:
Die Nutzung von Together AI ist nicht gerade ein Plug-and-Play-Erlebnis. Es erfordert eine beträchtliche Menge an Entwicklerzeit, um die API zu integrieren, eine Anwendung drumherum zu bauen und dieses System dann über die Zeit zu warten. Diese Engineering-Kosten können sich schnell summieren und sind oft viel höher als die API-Nutzung selbst.
Wiederkehrende Kritik von Anwendern aus LinkedIn / X Diskussionen über Together AI Preise
Dies ist kein spezieller Vorwurf gegen Together; es gilt für jede reine API-Inferenzplattform. Wenn die Zeit Ihres Ingenieurteams nicht kostenlos ist, sollte die Kalkulation, die Together ($1,04/M Llama 3.3 70B) mit Groq ($0,59/M Llama 3.3 70B) vergleicht, auch die Ingenieurwochen enthalten, die für Authentifizierung, Retry/Backoff, Observability, Validierung strukturierter Ausgaben, Prompt-Versionierung, Eval-Pipelines und Rufbereitschaft benötigt werden. Für viele Teams stellen diese Posten die Inferenzkosten völlig in den Schatten.
Wann Together AI die richtige Wahl ist - und wann nicht
Wo die Preisgestaltung von Together punktet:
- Sie betreiben feinabgestimmte Open-Source-Modelle mit vorhersagbarem, stabilem Produktions-Traffic. Dedicated Endpoints für $6,49/Std. oder reservierte Cluster für $3,99/Std. pro H100 sind konkurrenzfähig zu GPU-Mieten bei Hyperscalern und kosten bei gleicher Qualität nur einen Bruchteil proprietärer APIs.
- Sie benötigen GPU-Cluster mit InfiniBand, ohne Ihr eigenes Rechenzentrum aufzubauen. Die Bandbreite von 8 bis 4.000+ GPUs an über 25 Standorten sowie der Leistungsvorsprung durch die Together Kernel Collection sind außerhalb der größten Hyperscaler absolut konkurrenzfähig (gpu-clusters).
- Sie entwickeln multimodale Anwendungen und möchten eine einzige API. Die Serverless-Stufe deckt Chat, Vision, Image, Audio, Video, Transkription, Embeddings und Moderation ab, sodass Sie nicht Konten bei sechs verschiedenen Anbietern verknüpfen müssen.
- Sie führen große asynchrone / Batch-Workloads aus. Der 50 % Batch API Rabatt zusätzlich zu den ohnehin schon wettbewerbsfähigen Serverless-Raten ist schwer zu schlagen für Offline-Zusammenfassungen, Generierung synthetischer Daten, Log-Anreicherung und Klassifizierung im großen Stil.
Wo die Preisgestaltung von Together das falsche Werkzeug ist:
- Sie benötigen einfach den günstigsten Llama 3.3 70B Endpunkt, den man für Geld kaufen kann. Groq ist bei diesem speziellen Modell schneller und günstiger. OpenRouter ist sogar noch günstiger. Together liegt bei älteren Modellen im Mittelfeld.
- Sie sind ein kleines Team, das einen verwalteten KI-Agenten für einen spezifischen Bereich sucht - Support-Tickets, Sales-Chat, interne Hilfe - und Sie möchten Inferenz + Retrieval + Tool-Nutzung + UI + Eval nicht selbst zusammenbauen. Hier ist eine ergebnisorientierte Plattform sinnvoller; dazu gleich mehr.
- Sie möchten eine vorhersehbare, gedeckelte Preisgestaltung. Pay-as-you-go über mehrere Zähler ist schwer im Voraus zu prognostizieren. Ohne Ausgabenlimit kann ein außer Kontrolle geratener Agenten-Loop echtes Geld kosten, bevor es jemand bemerkt.
- Sie benötigen ein garantiertes SLA für die Reaktionszeit des Supports. Mehrere negative Bewertungen kritisieren die Reaktionsfähigkeit des Supports bei Abrechnungsstreitigkeiten, was man vorab in einem Unternehmensvertrag aushandeln sollte.
Für tiefergehende Vergleiche alternativer Anbieter siehe unsere Zusammenstellung von Together AI Alternativen, den Together AI Review und den umfassenden Was ist Together AI Leitfaden.
Testen Sie eesel, wenn Sie lieber Ergebnisse als Token kaufen möchten
Ein Beitrag über die Preise von Together AI ist fast immer ein Beitrag über die Rohstoffe eines KI-Produkts - Token, GPU-Stunden, Inferenz-Latenz, Fine-tuning-Trainings-Token. Das sind die richtigen Bausteine, wenn Sie ein Unternehmen für Basismodelle oder eine eigene Inferenz-Engine aufbauen. Es sind jedoch die falschen Bausteine, wenn Sie eigentlich nur einen funktionierenden KI-Agenten in Ihren bestehenden Tools haben möchten.

eesel verfolgt den entgegengesetzten Ansatz: Preisgestaltung pro Aufgabe für einen voll verwalteten KI-Teamkollegen, der in den Helpdesks, Chat-Apps und Posteingängen läuft, die Sie bereits nutzen (Zendesk, Freshdesk, Intercom-Integration, Slack, Gmail, Shopify und über 100 andere). Ein Support-Ticket kostet $0,40. Eine Frage im Dashboard ist kostenlos. Die Erstellung eines langen Blogbeitrags kostet $4. Inferenz, Retrieval, Prompt-Iteration, Retries, Eval und Observability sind alle in dieser Zahl enthalten - Sie sehen sie nicht auf der Rechnung und müssen sie nicht selbst bauen.
Stellen Sie KI-Teamkollegen ein. Vollständig autonome und unglaublich fähige Teamkollegen, die in Ihren bestehenden Apps leben und in wenigen Minuten einsatzbereit sind.
Ein Vergleich für das SaaS-Team aus Beispiel 1 - 5.000 Konversationen/Tag, produktinterner Chat-Assistent. Bei Together liegen die Inferenzkosten bei ca. $207/Mon. plus der Ingenieurszeit für Retrieval, Retry-Logik, Output-Validierung, Prompt-Versionierung und Analysen. Bei eesel kosten dieselben 5.000 Konversationen × 21 Tage = 105.000 Aufgaben/Mon. bei $0,40 pro Stück = $42.000/Mon. für dasselbe Ergebnis - auf dem Papier viel teurer, aber es beinhaltet ein funktionierendes End-to-End-Produkt und ein SLA für die Lösungsrate. Die richtige Antwort hängt davon ab, ob Ihr Team seine Zeit besser mit dem Aufbau von Infrastruktur oder dem Aufbau des Produkts verbringt.
Für die meisten Teams, bei denen KI-Support, KI-Chat oder KI-Inhalte das Ergebnis und nicht die Kerntechnologie sind, gewinnt das Pro-Aufgabe-Modell. Mit dem 50-$-Gratistest von eesel können Sie einen echten Workload ausprobieren - einen Helpdesk-Agenten, einen Blog-Schreiber, einen E-Commerce-Agenten - ohne Kreditkarte. Der Rabatt für ein Jahresabonnement beträgt 25 %, wenn Sie mehr als $300/Monat ausgeben. Keine Gebühr pro Sitzung, keine Plattformgebühr für Self-Service, kein monatlicher Mindestumsatz.
Wenn Sie bereits Together AI nutzen und mit dem Angebot zufrieden sind, sollten Sie dabei bleiben. Wenn Sie Together AI nutzen, weil Sie keine höherwertige Alternative finden konnten - genau für diese Lücke wurde eesel gebaut.
Häufig gestellte Fragen
Wie viel kostet die Nutzung von Together AI im Jahr 2026?
Bietet Together AI eine kostenlose Stufe oder Startguthaben an?
Wie funktioniert die Preisgestaltung für Together AI Fine-tuning?
Ist Together AI günstiger als Fireworks AI, Groq oder Replicate?
Welche versteckten Kosten sollte ich bei Together AI beachten?

Article by
Rama Adi Nugraha
Rama is a software engineer at eesel AI with two years of experience writing about B2B SaaS, AI tools, and customer support technology. Based in Bali, Indonesia, he brings a developer's perspective to product comparisons — cutting through marketing copy to what the integrations and APIs actually do.