Kustomer AI-Deflection: Wie Concierge Tickets in 2026 ablenkt
Alicia Kirana Utomo
Katelin Teen
Zuletzt bearbeitet June 17, 2026

Kurzfassung
Kustomer AI-Deflection läuft größtenteils über Kustomer Concierge, die kundenseitige KI, die den vollständigen Kundendatensatz liest und Fragen über Chat, E-Mail, SMS, WhatsApp und Sprache beantwortet, bevor sie einen Agenten erreichen. Die Technologie ist wirklich stark, insbesondere für umsatzstarke Retail- und DTC-Marken, die bereits in Kustomers CRM arbeiten.
Zwei Dinge sollten Sie wissen, bevor Sie darauf setzen. Erstens, die Preise sind nur auf Anfrage erhältlich und die KI wird zusätzlich zu einem bereits hohen Platzpreis abgerechnet (Drittanbieter-Analysen beziffern ihn auf etwa 0,60 $ pro geführtem Gespräch plus 89–139 $/Platz), „Kustomer AI" ist also ein Zusatzkostenposten, keine Grundausstattung. Zweitens ist die genannte Deflection-Rate größtenteils Fiktion: Branchenweit lenkt KI über 45 % der Anfragen ab, aber nur etwa 14 % werden wirklich eigenständig gelöst. Der Rest wird unterdrückt, nicht gelöst.
Wenn Sie eine Deflection wollen, die Tickets tatsächlich löst, sind die entscheidenden Faktoren nicht das Modell, sondern die Qualität der Wissensdatenbank, die Integrationstiefe und ein Konfidenz-Schwellenwert, der so eingestellt ist, dass die KI nur das angeht, was sie mit Sicherheit beherrscht. Das ist der Teil, den die meisten Teams überspringen – und genau dort würde ich ansetzen.
Was „Ticket-Deflection" bei Kustomer bedeutet
Ich sollte zunächst meinen Standpunkt darlegen, denn er prägt die Einschätzung. Ich habe die letzten drei-plus Jahre damit verbracht, KI-Agenten auf Live-Support-Queues zu setzen, und das Muster ist immer dasselbe: Die Demo-Deflection-Zahl und die echte sind zwei verschiedene Tiere. Ein Team, mit dem wir gearbeitet haben – eine Gig-Economy-Fahreranalyse-App auf Zendesk – löste 73 % seiner Tier-1-Anfragen im ersten Monat. Ein anderes, ein interner IT-Helpdesk, startete mit 15 % Deflection und musste sich mühsam auf ein Ziel von 55 % hocharbeiten. Gleiche Kategorie von Tool, völlig unterschiedliche Ergebnisse, und der Unterschied hatte fast nichts mit dem KI-Modell zu tun. (Wir entwickeln KI für Helpdesks wie Zendesk und Gorgias, also lesen Sie meine Einschätzung eines Konkurrenz-CRM mit diesem Vorbehalt.)
Deflection ist die Strategie, eine Frage zu beantworten oder dem Kunden die Selbstbedienung zu ermöglichen, bevor sie zu einem Ticket wird, das ein Mensch anfassen muss. Bei Kustomer geschieht das hauptsächlich über Concierge. Das Versprechen auf der Concierge-Seite lautet „agentische KI, die Kunden von Anfang bis Ende betreut, Probleme löst und nicht nur beantwortet" – das ist der richtige Rahmen: moderne KI-Ticketautomatisierung ist weit entfernt von den Keyword-Matching-Chatbots von 2018.
Was Kustomers Version auszeichnet, ist das Datenmodell. Es ist eine CX-Plattform, die um den Kundendatensatz herum aufgebaut ist, nicht um das Ticket, sodass die KI aus einer vollständigen Zeitleiste arbeitet (Bestellungen, Treuestufe, frühere Gespräche) statt aus einer isolierten Nachricht. Kustomer nennt das „KI, die mit Kontext arbeitet, nicht mit Raten." Für eine Retail- oder DTC-Marke, bei der die meisten Fragen „Wo ist meine Bestellung?" oder „Kann ich mein Abo ändern?" lauten, ist dieser Kontext der Unterschied zwischen einer echten und einer konservierten Antwort.
Wie Kustomer Concierge ein Ticket ablenkt
Mechanisch folgt eine autonome Deflection auf Concierge derselben Pipeline wie jeder moderne KI-Agent, nur verdrahtet mit Kustomers Zeitleiste:
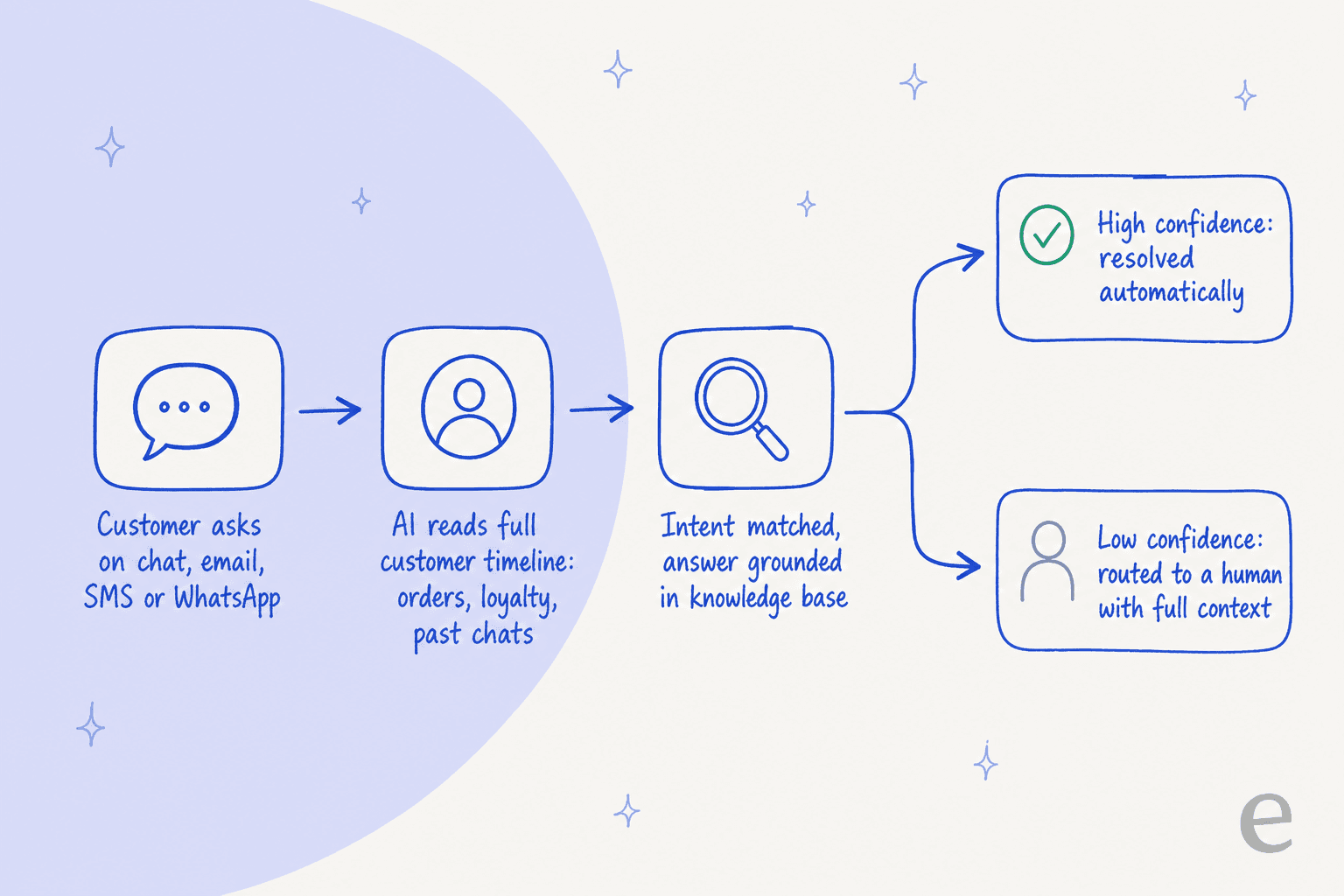
Der Kunde fragt auf einem beliebigen Kanal, Concierge führt eine Echtzeit-Absichtserkennung gegen den vollständigen Datensatz durch, verankert eine Antwort in Ihrem Wissen und den verbundenen Systemen, und dann entscheidet eine Konfidenzprüfung, ob autonom gelöst oder an einen Menschen übergeben wird – mit beigefügtem Kontext statt nur einem leeren Ticket. Entscheidend ist, dass die Hilfecenter-Dokumente KI-Agenten beschreiben, die Tools (Kundendaten, Bestelldaten, Inventar) nutzen können, um eine Aktion durchzuführen und nicht nur einen Hilfeartikel anzuzeigen. Das ist der Teil, der echte Deflection von einem aufgemotzten FAQ-Widget unterscheidet.
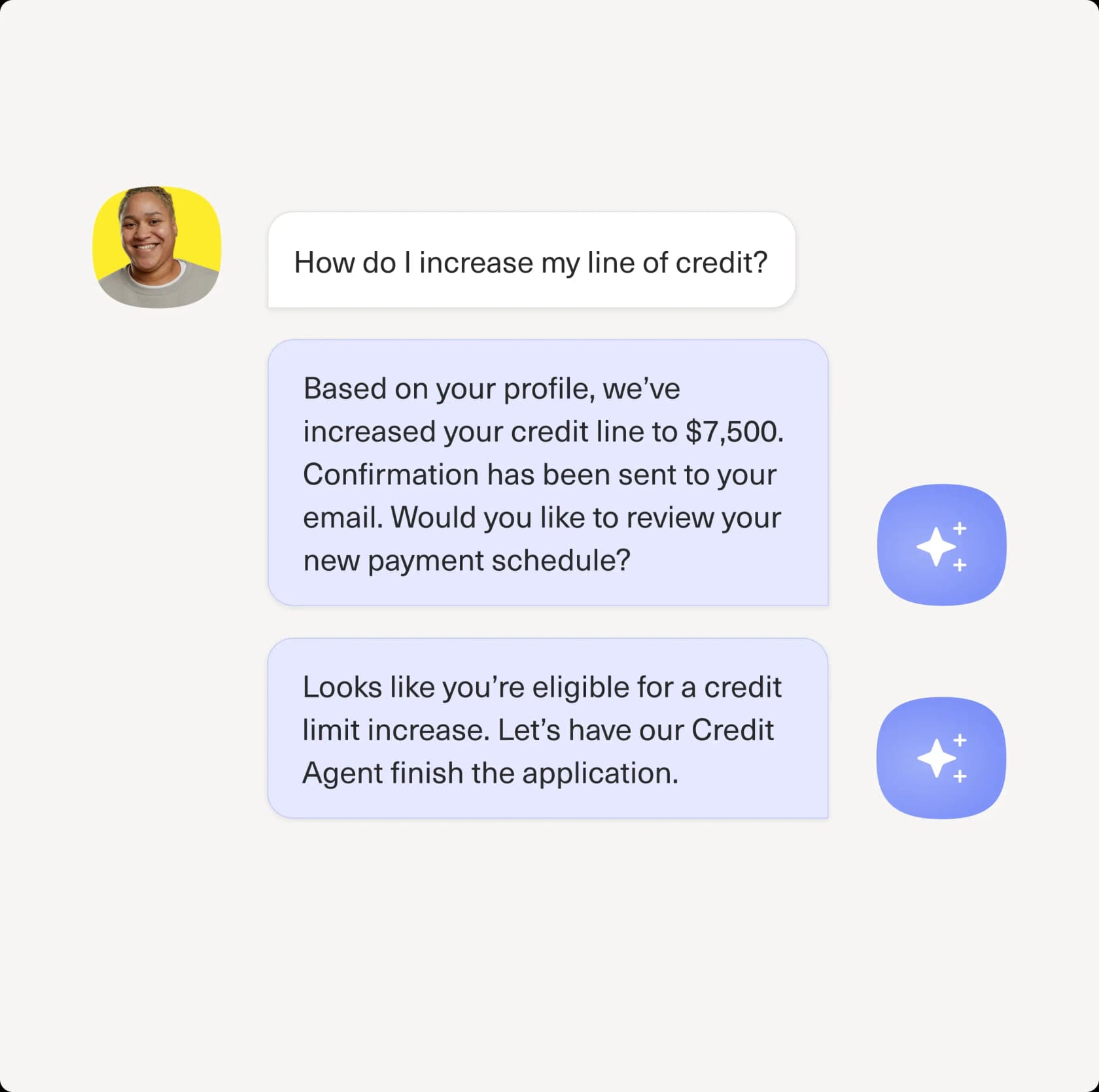
Hier löst Concierge eine kontospezifische Anfrage von Anfang bis Ende, also genau die Art von Anfrage, die eine statische Wissensdatenbank nie schließen könnte:
Kustomer untermauert das mit echten Zahlen. Die Concierge-Seite zitiert Vuori mit 70 % automatisierten Chat-Gesprächen, Aplazo mit 40 % CSAT-Steigerung und (auf der Plattformseite) 98 % aller WhatsApp-Gespräche von Aplazo als KI-gesteuert. Diese Zahlen stammen vom Anbieter und spiegeln die besten Kunden wider, aber sie sind tendenziell plausibel für B2C mit hohem Volumen – genau die Zielgruppe, für die Kustomer gebaut wurde.
Die Deflection-Zahl, die niemand nennt
Jetzt der Teil, den die meisten „Kustomer AI-Deflection"-Artikel übergehen. Eine Deflection-Rate und eine Lösungsrate sind nicht dasselbe, und der Unterschied zwischen ihnen ist enorm.
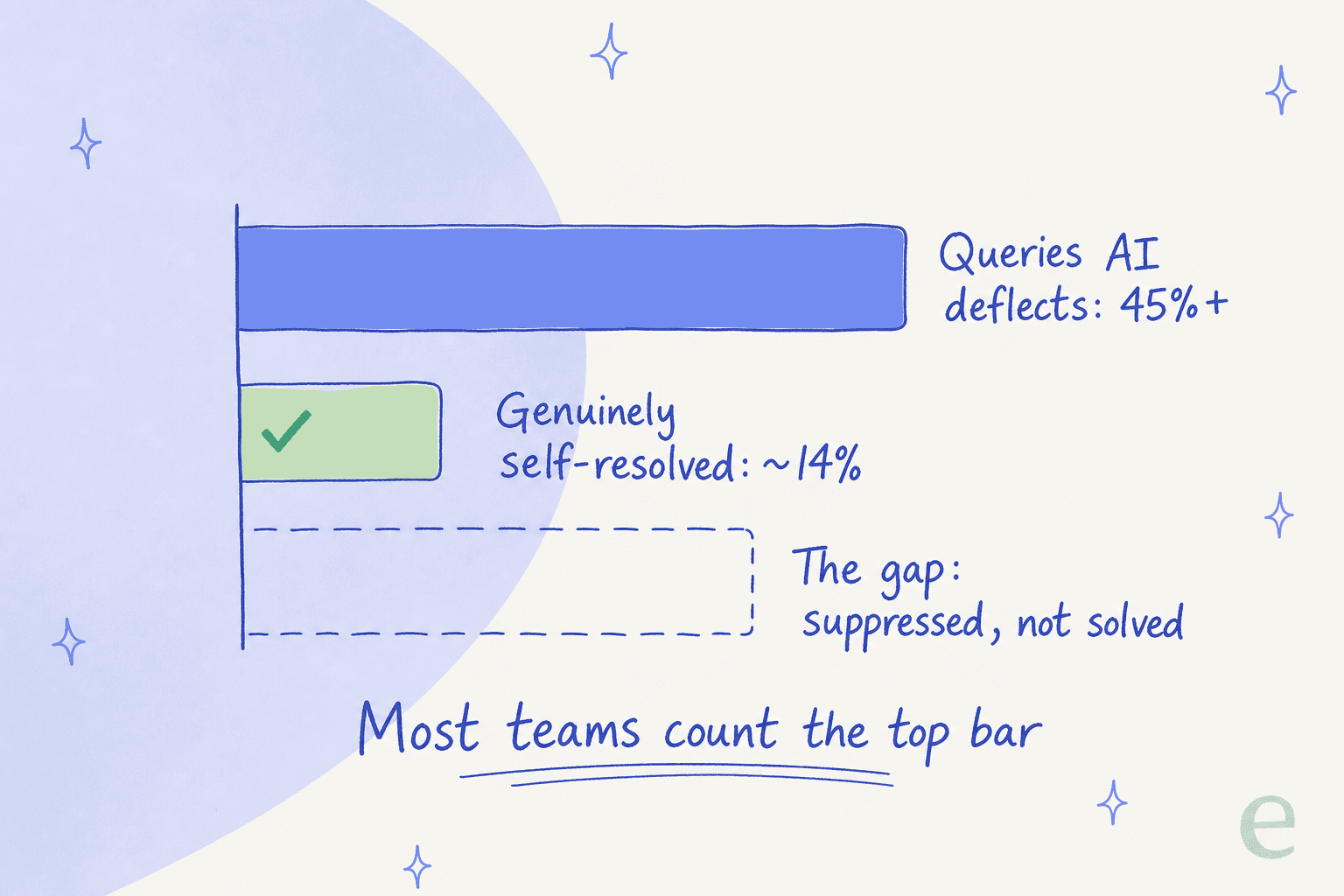
Branchen-Benchmarks beziffern die mittlere Tier-1-Deflection für Unternehmen auf etwa 41 %, mit Top-Performern bei knapp 59 % und besten agentischen Setups bei 86–92 %. Aber Gartners Daten für 2026 ergaben, dass KI zwar über 45 % der Anfragen ablenkt, aber nur etwa 14 % wirklich zur Selbstbedienung geführt werden. Die restlichen ~31 % sind „falsche Deflections": Kunden, die unterdrückt wurden, aufgegeben haben oder über einen anderen Kanal zurückgekehrt sind. Die meisten Teams überschätzen ihre tatsächliche Deflection um 15–25 %.
Das ist für Kustomer besonders relevant, weil Deflection-Berichte Anreize setzen. Jede Plattform, die eine Deflection-KPI optimiert, schafft perverse Anreize. Wie eine vielzitierte Analyse von über 50 Practitioner-Threads es ausdrückt:
„Die Optimierung auf Ticket-Deflection mit KI hat fast unsere Churn-Rate ruiniert. Hören Sie auf, Bots als Türsteher einzusetzen."
Wenn Sie also Kustomer Concierge (oder irgend etwas anderes) bewerten, fragen Sie nicht „Wie hoch ist die Deflection-Rate." Fragen Sie, wie hoch die Wiederanfragerate innerhalb von 48 Stunden ist und welcher Anteil der Gespräche die KI wirklich ohne menschliche Beteiligung abgeschlossen hat. Das ist die Zahl, die dem Realitätscheck standhält.
Was Kustomer AI-Deflection wirklich kostet
Hier wird es frustrierend, und hier würde ich am stärksten widersprechen. Kustomers Preisseite ist vollständig auf Anfrage. Es gibt ein einziges „Kustomer AI + Platform"-Paket, jeder Preis führt zu „Vertrieb kontaktieren", und es gibt nirgendwo auf der Seite eine veröffentlichte Preis-pro-Platz- oder Preis-pro-Lösung-Angabe. Für einen Deflection-Käufer, der die Kosten pro gelöstem Ticket modellieren möchte, ist das eine Mauer.
Die einzigen konkreten Zahlen stammen aus einer Wettbewerberanalyse – also mit entsprechender Vorsicht zu genießen –, sind aber konsistent mit dem, was Käufer berichten. Hier das Bild aus Gorgias' Preisanalyse:
| Kostenkomponente | Was Sie zahlen | Hinweise |
|---|---|---|
| Plätze (Enterprise) | ~89 $/Platz/Monat | Jährliche Abrechnung, Minimum 8 Plätze |
| Plätze (Ultimate) | ~139 $/Platz/Monat | Jährliche Abrechnung, Minimum 8 Plätze |
| Kundenseitige KI | ~0,60 $ pro geführtem Gespräch | Concierge-Deflection, separat abgerechnet |
| Agenten-Assistenz-KI (Envoy) | ~40 $/Nutzer/Monat | Copilot, separat abgerechnet |
| Datenspeicher | 50 $/GB (Daten), 1 $/GB (Anhänge) | Überschreitungsgebühren |
| HIPAA-Konformität | +25 $/Nutzer/Monat | Add-on |
| Voice / WhatsApp | Pay as you go | Tarife auf einer separaten Seite |
Der entscheidende Punkt: Die KI wird separat vom Platzpreis abgerechnet. Deflection ist keine Funktion, die Sie in Ihrem Plan aktivieren, sondern ein per-Gespräch-Posten, der auf eine 8-Platz-, jährliche Verpflichtung aufgesetzt wird. Bei einigen tausend Gesprächen pro Monat summieren sich diese 60 Cent schnell – das ist die wiederkehrende Beschwerde in Nutzerbewertungen. Den vollständigen Überblick finden Sie in unserem aktualisierten Kustomer-Preisleitfaden und einem umfassenderen Kostenvergleich von KI-Helpdesk-Apps.
Es lohnt sich, das Modell zu vergleichen, nicht seine Moral. Eine Gebühr pro Gespräch ist in Ordnung, wenn jedes Gespräch gelöst wird. Sie schmerzt, wenn Sie auch für die ~31 % falschen Deflections aus dem vorherigen Abschnitt zahlen. Sie werden für Versuche abgerechnet, nicht für Ergebnisse.
Wo Kustomer-Deflection an Grenzen stößt
Kustomer ist eine wirklich leistungsfähige Plattform, und seine G2-Bewertung von 4,4 aus 555 Bewertungen ist solide (ignorieren Sie das „5,0 aus 500+"-Badge auf der Startseite, das tatsächliche Aggregat ist 4,4). Rezensenten loben durchgehend, wie übersichtlich die einheitliche Zeitleiste ist und wie der Co-Pilot bei Richtlinienerklärungen hilft. Aber einige Muster tauchen häufig genug auf, dass sie in eine Deflection-Entscheidung einfließen sollten.
Der Kanal, auf den Deflection am stärksten angewiesen ist – Sprache –, zieht die schärfste Kritik auf sich. Ein Operator, der ein Telefon- und Social-Media-Team leitet, beschrieb es unverblümt auf Reddit:
„Nach meiner Erfahrung ist der Voice-Kanal unglaublich fehlerhaft. Mein Telefonteam kämpft ständig mit wiederkehrenden Problemen wie abgebrochenen Gesprächen, Audioausfällen und falsch gerouteten Anrufen."
Es gibt auch ein wiederkehrendes UI-Komplexitäts-Thema und eine Onboarding-Eigenheit, die mich überrascht hat. Ein Team mitten im Onboarding berichtete, dass Kustomer E-Mails standardmäßig im Rohformat statt als HTML anzeigt und bezeichnete das als „so absonderlich, dass es jeder Logik widerspricht." Nichts davon ist disqualifizierend, aber es ist die Textur, die Sie von der Marketingseite nicht bekommen – und es beeinflusst, wie viel Begleitung Ihr Team braucht, bevor die Deflection reibungslos läuft. Den vollständigen Überblick bietet unser Kustomer-Testbericht, und das Alternativen-Roundup behandelt andere Optionen.
Kontrolle: Die KI auf die richtigen Tickets beschränken
Wenn es einen Punkt gibt, dem ich besondere Aufmerksamkeit widmen würde, dann diesen. Der größte Einwand, den ich von Teams höre, die ein Deflection-Tool evaluieren, ist nicht „Wird es funktionieren", sondern „Wird es zuversichtlich etwas Falsches antworten". Ein CX-Leiter einer DTC-Supplement-Marke mit etwa 7.000 Tickets pro Monat fasste die gesamte These in einem Satz zusammen:
„Die KI wird nie in der Lage sein, 100 % der Fragen zu beantworten … Ich brauche eine KI, die nur die Tickets bearbeitet, bei denen sie sicher ist, und alles andere in Ruhe lässt."
Das ist der richtige Instinkt – und er trennt Deflection, die hilft, von Deflection, die Kunden verliert. Kustomer adressiert das mit sogenannter progressiver Autonomie und KI-Leitplanken: Konfidenz-Schwellenwerte, die festlegen, wo Concierge handelt und wo es abwartet, plus eingebaute Auswertungen zum Testen der Genauigkeit vor und nach dem Go-Live. Sie können die Auswertungsoberfläche hier sehen, die Antworten gegen Testfälle bewertet, bevor sie je einen Kunden berühren:
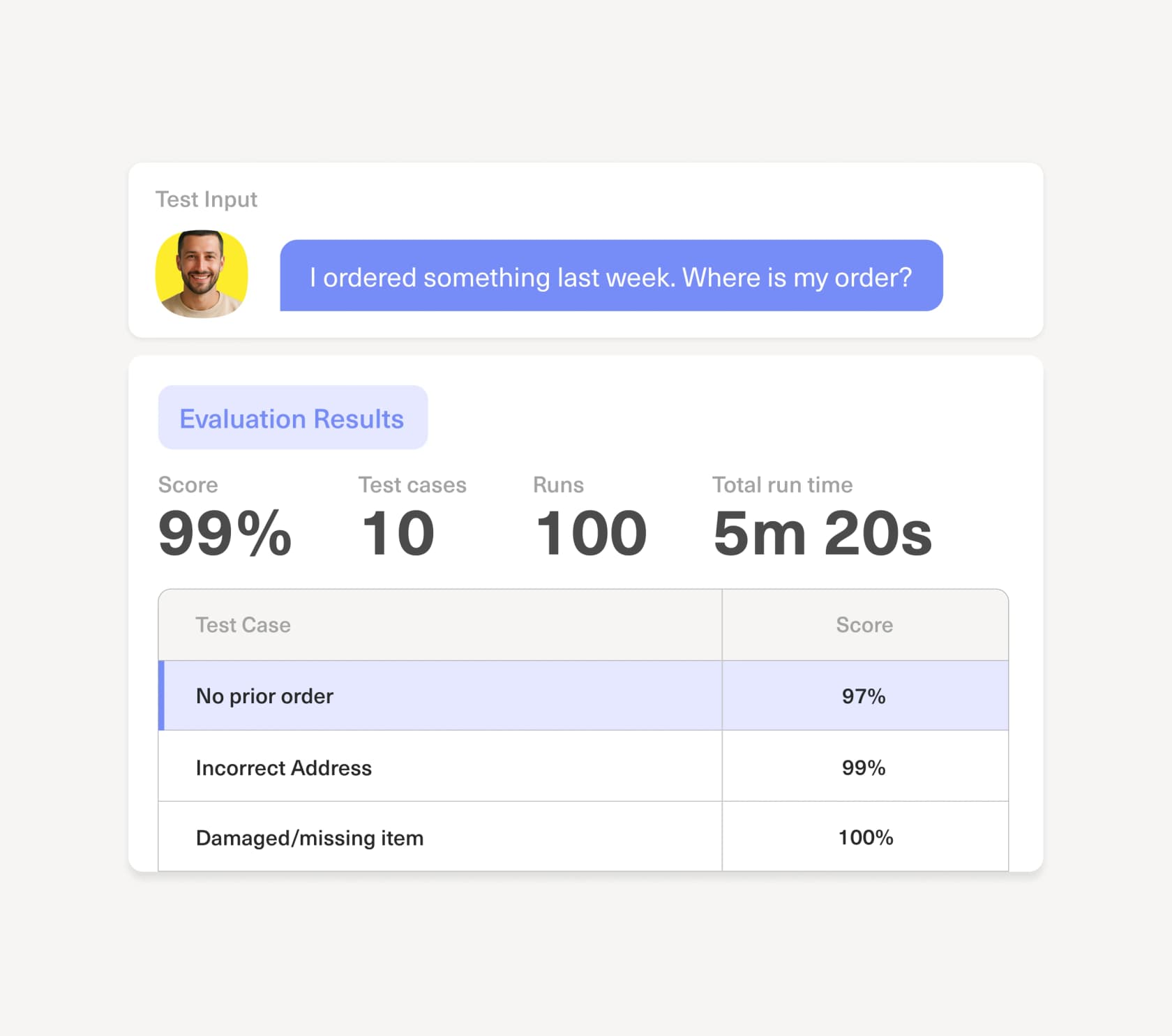
Dieser Evaluation-first-Ansatz ist die richtige Idee, und es ist etwas, das ich von jedem Anbieter einfordern würde: Sie sollten die KI gegen echte historische Tickets simulieren können, bevor Sie sie auf eine Live-Anfrage loslassen. Wenn eine Plattform Ihnen keine projizierte Lösungs- und Genauigkeitsrate vor dem Go-Live zeigen kann, fliegen Sie blind – und so schleichen sich falsche Deflection-Zahlen ein.
Wie Sie echte Deflection wirklich erreichen
Die strukturelle Erkenntnis, die sich aus jeder Implementierung wiederholt: Der Unterschied zwischen 40 % echter Deflection und 70 %+ ist fast nie das KI-Modell. Es sind vier Hebel, und die liegen alle in Ihrer Hand.

- Qualität der Wissensdatenbank zuerst. Das ist die Obergrenze für alles. Die Qualität eines Deflection-Systems wird durch das Wissen, das es abruft, bestimmt, nicht durch das Modell. Gut strukturierte, aktuelle Dokumente steigern die echte Lösungsrate um 15–25 %. Ist Ihre Wissensdatenbank veraltet, produziert die KI nur schneller selbstbewusst falsche Antworten. Deshalb schlägt das Training der KI auf Ihrer Wissensdatenbank und ein gutes Wissensdatenbankmanagement jedes Modell-Upgrade.
- Tiefe Integrationen. Die meisten echten Fragen brauchen kontospezifischen Kontext, nicht einen generischen Artikel. CRM-, Abrechnungs- und Auftragsverwaltungsintegrationen steigern die Deflection-Qualität um 20–30 %. Kustomers Zeitleiste ist hier wirklich stark – das ist ihr größter Deflection-Vorteil.
- Kalibrierte Konfidenz-Schwellenwerte. Legen Sie sie durch Tests fest, nicht durch Intuition, und kalibrieren Sie sie vierteljährlich neu. Das ist der Hebel, der das Prinzip „Lass den Rest in Ruhe" oben berücksichtigt. Unser Leitfaden zum Intent-Konfidenz-Schwellenwert erläutert den Trade-off.
- Nahtlose Eskalation. Jede Eskalation ist ein Signal für eine Wissenslücke, kein Versagen. Die Übergabe sollte den vollständigen Kontext mitführen, damit der Kunde nie neu erklären muss. Behandeln Sie Ihr Ticket-Triage und Routing als Teil des Deflection-Systems, nicht getrennt davon.
Beherrschen Sie diese vier Punkte, und das Modell spielt kaum eine Rolle. Überspringen Sie sie, und kein noch so ausgefeiltes „agentisches KI"-Branding wird Sie retten.
Probieren Sie eesel für Deflection auf dem Helpdesk, den Sie bereits haben
Hier ist die ehrliche Einschätzung. Wenn Sie eine B2C-Marke mit hohem Volumen sind, die eine Plattform als CRM und KI möchte, ist Kustomer eine ernsthafte Option, und das Kunden-Zeitleisten-Modell ist ein echter Deflection-Vorteil. Aber wenn Sie bereits einen Helpdesk betreiben und nur Deflection wollen, die Tickets löst, ohne eine CRM-Migration, ein 8-Platz-Minimum und eine gesprächsbasierte KI-Abrechnung – das ist die Lücke, für die eesel AI gebaut wurde.
eesel legt einen KI-Agenten auf Helpdesks wie Zendesk, Freshdesk und Gorgias, lernt ab Tag eins aus Ihren bisherigen Tickets und Dokumenten und – was mir am wichtigsten ist – lässt Sie es gegen Tausende historischer Tickets simulieren, um die projizierte Lösungsrate zu sehen, bevor es ein Live-Gespräch berührt. Die Abrechnung erfolgt pro Lösung, nicht pro Platz, ohne Mindestmengen – Sie zahlen also für Ergebnisse, nicht für Versuche.

Genau dieser Simulation-first-, konfidenz-gesteuerte Ansatz hat dazu geführt, dass das Gig-Economy-Team im ersten Monat 73 % Tier-1-Lösungsrate erreicht hat. Wenn das die Art von Deflection ist, die Sie suchen, können Sie eesel in wenigen Minuten auf Ihren eigenen Tickets ausprobieren.
Häufig gestellte Fragen
Was ist Kustomer AI-Deflection?
Wie viel kostet Kustomer AI-Deflection?
Welche Deflection-Rate kann ich realistischerweise erwarten?
Ist Kustomer AI-Deflection gut für kleine Teams?
Wie verhindere ich, dass Kustomer AI Tickets ablenkt, die es nicht sollte?
Was macht KI-Deflection wirklich erfolgreich?
Kann ich KI-Deflection nutzen, ohne meinen gesamten Helpdesk zu ersetzen?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.