
Was ein KI-FAQ-Seiten-Generator wirklich tut
Ich verbringe die letzten paar Jahre damit, Keywords auf das abzubilden, wonach die Leute wirklich suchen, und bei eesel habe ich beobachtet, wie unser KI-Helpdesk-Agent Tausende von echten Support-Tickets über Live-Kundenseiten hinweg liest. Wenn ich also einen "FAQ-Generator" anschaue, schaue ich nicht wirklich auf ein Schreibwerkzeug. Ich schaue auf ein Fragen-Auswahlwerkzeug, das zufällig auch schreibt.
Im einfachsten Fall nimmt ein KI-FAQ-Seiten-Generator eine Eingabe (ein Produkt, eine URL oder eine Liste von Themen) und gibt eine strukturierte Seite mit Fragen und kurzen Antworten zurück, normalerweise in deiner Markenstimme und bereit für dein CMS. Er ist ein enger Verwandter eines vollständigen KI-Blog-Writers: Statt einem langen Artikel bekommst du einen kompakten Satz von Q&A-Blöcken.
Der Schreibteil ist im Grunde gelöst. Jedes halbwegs anständige Modell produziert zwanzig flüssige FAQ-Einträge in einer Minute. Was eine Seite, die ihren Platz verdient, von einer, die ignoriert wird, trennt, ist die Frage, welche zwanzig Fragen ausgewählt wurden und ob die Antworten in deinem echten Produkt, deiner Wissensdatenbank und deinen Dokumenten verankert sind oder in der Vorstellungskraft des Modells.
Der Fehler, den die meisten KI-FAQ-Generatoren machen
Hier ist die Umdeutung, auf der alles andere aufbaut. Das Standardverhalten eines FAQ-Generators ist Raten. Du gibst ein "Wir verkaufen Projektmanagement-Software" ein, und er gibt selbstsicher "Was ist Projektmanagement-Software?", "Wie viel kostet es?" und "Sind meine Daten sicher?" zurück. Vernünftig aussehende Fragen. Das Problem: Du weißt nicht, ob irgendjemand sie wirklich stellt, und die Antworten sind nach einer generischen Vorlage geschrieben, nicht danach, wie dein Produkt wirklich funktioniert.
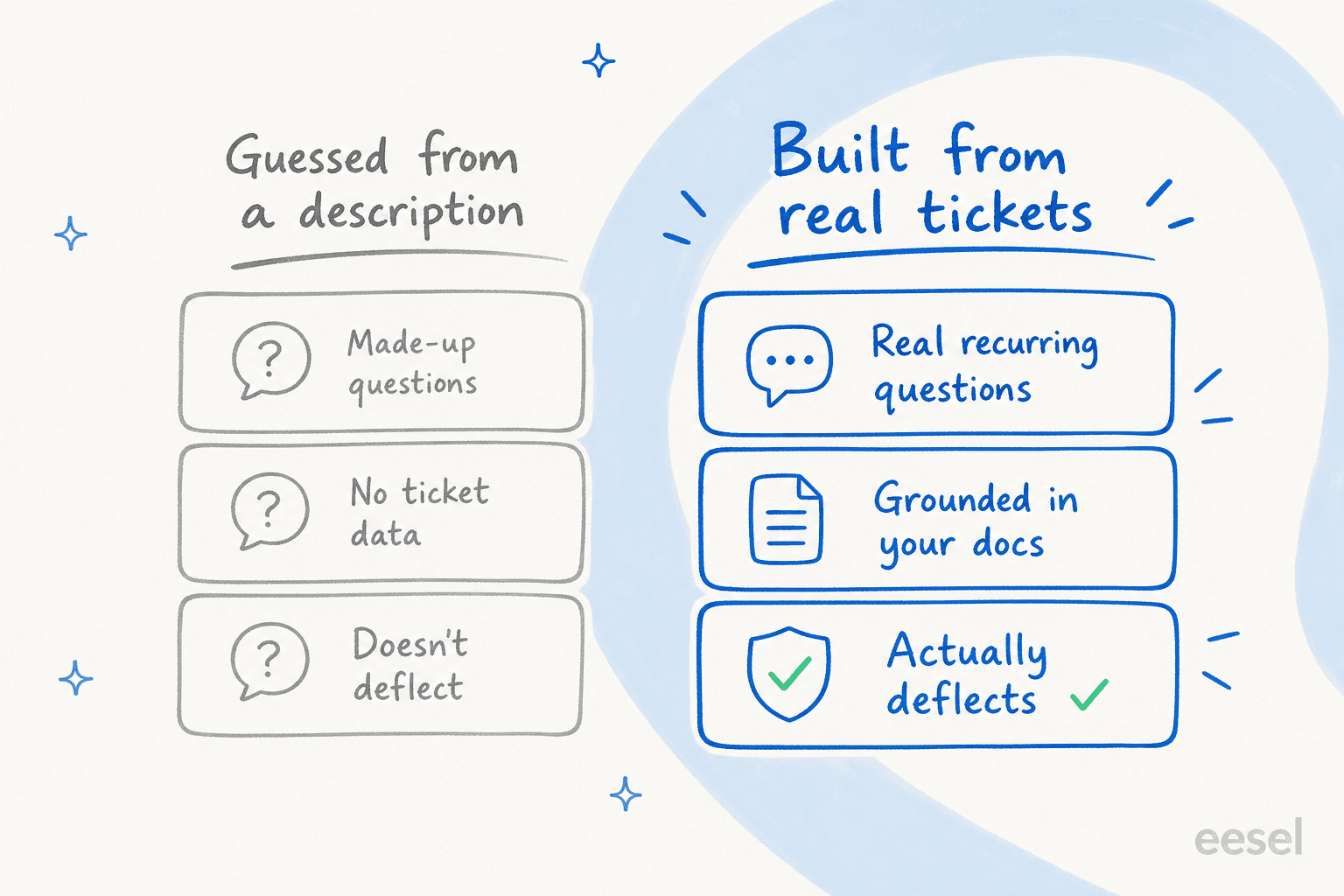
Ich habe beobachtet, wie das auf eine bestimmte, teure Weise scheitert. Ein Muster, das ich immer wieder sehe: eine Wissensdatenbank, die für eine Zielgruppe geschrieben wurde, aber von einer anderen gelesen wird. Ein Support-Team für Bus-Tracking-Apps, von dem ich weiß, hatte seinen gesamten Hilfeinhalt für Transit-Administratoren geschrieben, während die Tickets alle von normalen Fahrgästen kamen. Ein Generator, der auf diese Admin-Dokumente zeigt, produziert eine FAQ, die technisch korrekt und für die lesende Person völlig nutzlos ist. Die Fragen sind falsch formuliert, die Antworten setzen den falschen Leser voraus, und die Ablenkung ist null.
Die Lösung ist kein besserer Prompt. Es ist ein besserer Input. Die Fragen, die es wert sind, beantwortet zu werden, sitzen bereits in deiner Ticket-Warteschlange.
Wo die echten Fragen stecken: deine Ticket-Daten
Wenn du irgendeine Art von Support betreibst, sammelst du bereits die perfekte FAQ-Forschung – du hast sie nur noch nicht als Forschung gelesen. Jedes wiederkehrende Ticket ist eine Stimme für einen FAQ-Eintrag. Die Frage, die ein Kunde auf drei verschiedene Arten in vierzig Tickets formuliert, gehört auf die Seite – in seinen Worten.
Das ist das meistgewünschte Ding, das ich von Teams höre, die KI-Kundenservice-Software einsetzen: trainiere sie auf unseren eigenen vergangenen Tickets, denn dort liegt die Wahrheit. Dort häufen sich auch die wiederkehrenden Fragen, was genau das ist, was du brauchst, um eine FAQ zu erstellen. Einige Tausend Tickets von Hand zu lesen, um die Muster zu finden, ist jedoch eine Qual – das ist der Teil, bei dem KI ungewöhnlich gut ist.

Hier erledigt die KI-Ticket-Analyse die schwere Arbeit. Richte sie auf deine Historie, und sie gruppiert Tickets in Themen und sortiert sie nach Volumen, sodass du eine sortierte Liste erhältst: "Hier sind die 20 Dinge, die die Leute am häufigsten fragen, nach Häufigkeit." Diese sortierte Liste ist deine FAQ-Gliederung. Das ist der Unterschied zwischen Raten und Wissen, und es ist der Grund, warum das Verankern einer FAQ in deiner Wissensdatenbank und deinen Tickets jedes clevere Prompting übertrifft.
Derselbe Ansatz zeigt eine zweite Liste, die genauso wertvoll ist: die Fragen, die Leute stellen, auf die deine Dokumente keine Antwort geben. Diese Lücken sind deine nächsten Help-Center-Artikel, und Tools, die Help-Center-Lückenmapping betreiben, machen diese Schleife kontinuierlich. Wenn du Software dafür auswählst, ist meine Zusammenfassung der Wissensdatenbank-Management-Tools ein guter Ausgangspunkt.
So baust du eine FAQ-Seite mit KI, Schritt für Schritt
Hier ist der Workflow, den ich tatsächlich nutzen würde. Er funktioniert mit jedem anständigen Generator; der Wert liegt in Schritten 1 und 2, die die meisten Tutorials völlig überspringen.
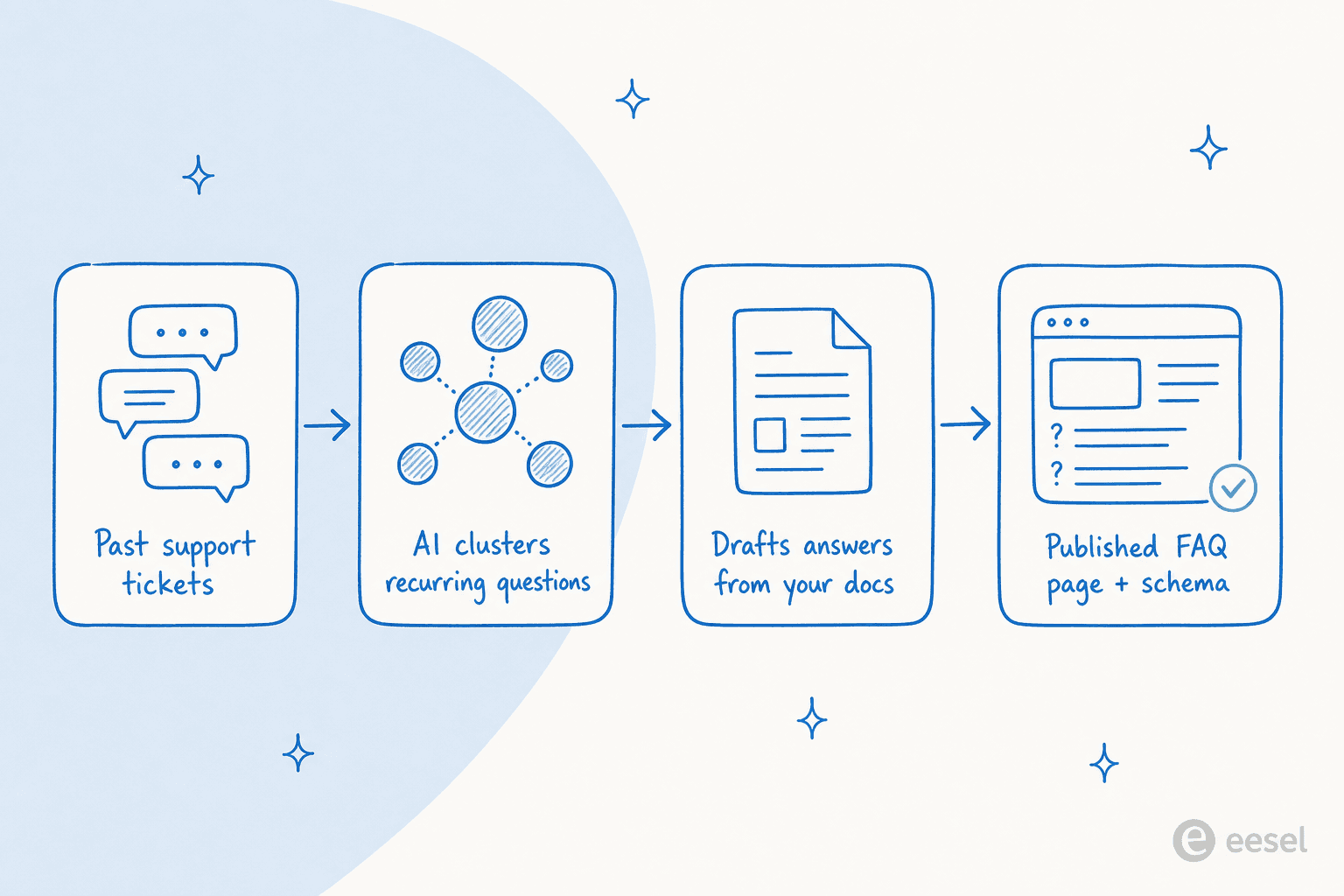
1. Hol dir deine echten Fragen. Exportiere oder analysiere deine letzten Monate an Tickets und Chats, und lass KI sie in nach Volumen gerankte Themen gruppieren. Wenn du noch keine Ticket-Historie hast, nutze Suchanfragen aus deinem Help Center und deinen Site-Suchprotokollen als Ersatz. Füge einen schnellen Durchlauf durch eesels kostenlosen SEO-Keyword-Generator hinzu, um zu sehen, wie die Leute diese Fragen in der Suche formulieren – was sich oft von der Formulierung in einem Ticket unterscheidet.
2. Verankere die Antworten in deinen eigenen Dokumenten. Gib dem Generator deine Hilfe-Artikel, Produktdokumentationen und Richtlinien als Quelle, und weise ihn an, nur aus diesem Material zu antworten. Das ist der Schritt, der generischen, KI-typischen Fülltext verhindert und die Antworten spezifisch für dein Produkt hält. Ein KI-Blog-Writer mit Markenstimmen-Training hilft außerdem, den Ton an den Rest deiner Seite anzupassen.
3. Entwurf, dann für die Kundenstimme überarbeiten. Lass das Tool den ersten Entwurf schreiben, dann formuliere jede Frage so um, wie ein Kunde sie wirklich stellen würde – kurz, verständlich, ohne internen Fachjargon. Halte Antworten bei zwei oder drei Sätzen mit einem Link zum weiterführenden Artikel. Die Aufgabe einer FAQ-Antwort ist es, die Frage zu lösen oder sauber weiterzuleiten, nicht umfassend zu sein.
4. Mit FAQ-Schema veröffentlichen und verlinken. Füge FAQPage-Strukturdaten hinzu, damit Suchmaschinen und KI-Tools das Q&A sauber parsen können, und verlinke jede Antwort auf die relevante Seite. Es gibt eine Kunst beim Schreiben von FAQ-Inhalten, die gut lesbar ist und rankt; diese internen Links machen die FAQ auch zu einem kleinen Hub, was gut für Leser und thematische Autorität ist.
5. Am Leben erhalten und messen. Neue Ticket-Themen tauchen ständig auf. Führe die Analyse monatlich erneut durch, füge neue wiederkehrende Fragen hinzu und entferne die, nach denen niemand fragt. Verfolge, ob die Seite wirklich etwas bewegt, indem du ihre Deflection misst im Vergleich zu deinem Ticket-Volumen. Eine veraltete FAQ ist fast so schlimm wie keine FAQ.
Was eine FAQ-Seite im Jahr 2026 wirklich wert ist
Hier muss ich ein Versprechen entkräften, das fast jede "KI-FAQ-Generator"-Landingpage noch macht: dass eine FAQ-Seite dir diese erweiterbaren Rich Snippets in Google bringt. Für die meisten Unternehmen tut sie das nicht mehr.
Im Jahr 2023 hat Google FAQ-Rich-Results zurückgezogen. Laut seiner eigenen Dokumentation zu strukturierten Daten:
"FAQ-Rich-Results sind auf bekannte, maßgebliche Behörden- und Gesundheitswebseiten beschränkt."
Google Search Central, FAQPage-Dokumentation zu strukturierten Daten
Wenn du also keine Behörde oder ein Krankenhaus bist, bringt dir das FAQ-Schema auf deiner Seite nicht mehr dieses schöne Ergebnis. Viel FAQ-Generator-Marketing hat das einfach noch nicht aufgeholt.
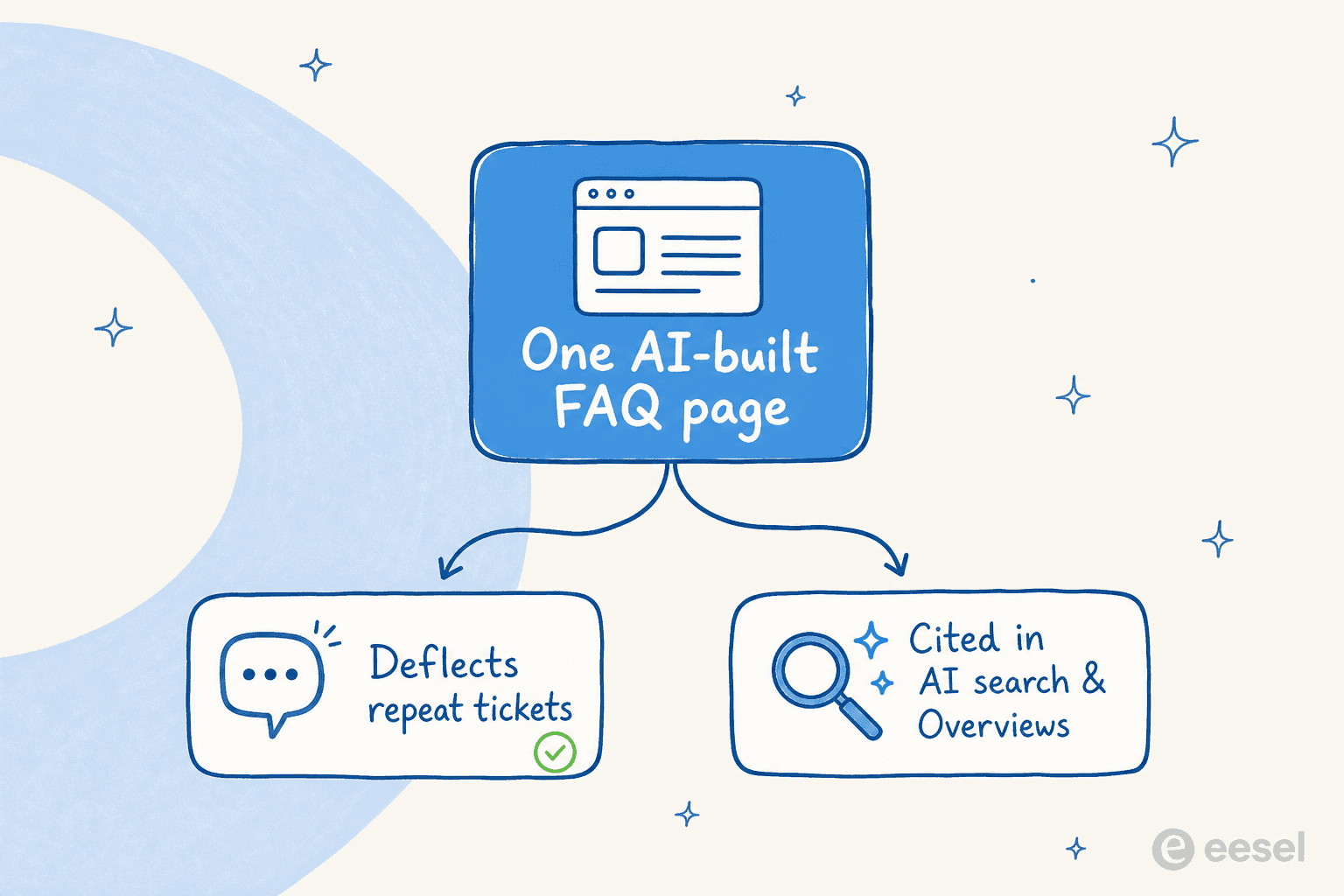
Aber der Wert ist nicht verschwunden – er hat sich verlagert. Eine gute FAQ-Seite zahlt sich jetzt auf zwei Wegen aus. Erstens Deflection: Sie beantwortet die Frage, bevor sie zum Ticket wird – das ist der direkteste Weg, das Support-Volumen zu reduzieren ohne zusätzliches Personal. Zweitens KI-Suche: Sauberes, strukturiertes Q&A ist das am leichtesten zitierfähige Format für KI-Suchmaschinen und KI-Overviews, was bedeutet, dass eine FAQ mit echten, spezifischen Antworten genau das ist, was angezeigt und zitiert wird. Das ist der ganze Punkt der Answer Engine Optimization.
Beide Vorteile hängen vom Gleichen ab: echten, spezifischen Antworten, die in deinem Produkt verankert sind. Das Schema ist Infrastruktur; die Substanz ist das, was dir Deflection und Zitate einbringt.
Häufige Fehler, die du vermeiden solltest
Ein paar Fallen, in die ich Teams tappen sehe – über das "geratene Fragen"-Problem hinaus:
- Aus Trainingsdaten statt aus deinen Dokumenten antworten. Wenn ein Generator die Antwort in deinem Material nicht findet, erfinden die schwachen einfach etwas. Ich habe einen Support-Bot erlebt, der echten Kunden erzählte, er biete ein Produkt an, das er nicht hatte, weil niemand einen Konfidenz-Schwellenwert gesetzt hatte. Verankere jede Antwort, und mache "Ich weiß es nicht, hier erfährst du, wie du uns erreichst" zu einem akzeptablen Output.
- Für SEO statt für den Leser schreiben. Eine Seite mit keyword-geformten Fragen zu füllen, die niemand stellt, bringt weder Deflection noch Rankings. Googles Spam-Richtlinien nennen minderwertige skalierte Inhalte direkt, und eine aufgeblähte FAQ ist ein Lehrbuchbeispiel. Setze lieber auf richtige KI-Suchoptimierung statt auf Volumen.
- Veralten lassen. Eine FAQ, die keine neuen Ticket-Themen verfolgt, hört langsam auf, die Realität widerzuspiegeln. Behandle sie als lebende Seite, nicht als einmal-veröffentlich-und-vergess-Asset.
- Quellen aufteilen. Wenn deine statische FAQ und dein FAQ-Chatbot aus verschiedenen Inhalten schöpfen, werden sie sich widersprechen. Verweise beide auf eine einzige Quelle der Wahrheit.
Probiere eesel für die Fragen, die eine Seite nicht beantworten kann
Eine statische FAQ-Seite behandelt die vorhersehbaren Fragen und unterstützt den wissensbasierten Self-Service. Der Long Tail – die seltsam formulierten, die "aber was ist mit meiner spezifischen Situation"-Nachfragen – kommt weiterhin als Tickets an. Das ist die Hälfte, die eine FAQ-Seite nicht erreicht, und dort passt eesel.
eesel lernt ab dem ersten Tag aus deinen vergangenen Tickets und Hilfedokumenten, sodass es in deiner Stimme antwortet und löst, was dein Team bereits löst – ob das FAQ-ähnliche Inhalte mit dem KI-Blog-Writer entwirft oder Live-Fragen über den KI-Helpdesk-Agenten bearbeitet. Es nutzt konfidenzbasiertes Routing, sodass Fragen mit geringer Konfidenz an einen Menschen weitergeleitet werden, statt geraten zu werden – das ist die Absicherung, die das oben genannte Halluzinationsproblem stoppt.
Ein Team, eine Gig-Economy-Fahrer-App auf Zendesk, hat 73 % der Tier-1-Anfragen gelöst in ihrem ersten Monat, mit Ergebnissen innerhalb einer 7-Tage-Testphase. Du kannst deinen Helpdesk verbinden und es gegen deine eigenen historischen Tickets simulieren, bevor es jemals mit einem Kunden spricht. Kostenlos testen.









