
Kurzfassung
AA-Briefcase ist ein neuer Benchmark von Artificial Analysis, der KI-Modelle an echter, mehrwöchiger Wissensarbeit bewertet (Finanzmodelle, Vorstandspräsentationen, Produktspezifikationen) – nicht an sauberen Einzelfragen. Jedes Modell erhält Tausende ungeordneter Dateien (E-Mails, Slack-Threads, Tabellen) und muss echte Ergebnisse liefern, die auf Korrektheit, analytische Qualität und Präsentation bewertet werden.
Der Hauptbefund ist ernüchternd: Selbst das beste Modell besteht alle Rubrikprüfungen nur bei 3 % der Aufgaben, und bei 31 von 91 Aufgaben schafft kein Modell 50 %. Claude Fable 5 führt das Leaderboard an, wobei das Open-Weight-Modell GLM-5.2 weit über seinem Preis abschneidet.
Hier ist der Teil, den die meisten Berichte übergehen: Ein hoher Benchmark-Score sagt aus, dass ein Modell generell leistungsfähig ist, nicht dass es auf Ihren Daten sicher ist. Diese Lücke ist der genaue Grund, warum ich jeden, der nach KI-Kundenservice sucht, empfehle, zunächst auf eigenen historischen Daten zu testen, bevor er live geht – anstatt einfach einer Rangliste zu vertrauen.
Ich entwickle bei eesel beruflich KI-Agenten. Ein Benchmark, der endlich ungeordnete echte Arbeit statt Trivialwissen misst, ist etwas, für das ich alles stehen und liegen lasse. Im Folgenden wird erklärt, was AA-Briefcase tatsächlich misst, wie er bewertet, wer führt und die eine Lektion, die ich daraus für jeden KI-Agenten-Rollout mitnehmen würde.
Was AA-Briefcase tatsächlich misst
Die meisten KI-Benchmarks stellen kurze, in sich geschlossene Fragen: ein Matheproblem, ein Coding-Rätsel, ein Multiple-Choice-Quiz. Das ist gut geeignet, um reine Schlussfolgerungsfähigkeiten zu messen, entspricht aber nicht dem, wie Menschen diese Modelle tatsächlich bei der Arbeit einsetzen. Echte Wissensarbeit ist lang, mehrdeutig und in Unordnung vergraben.
AA-Briefcase wurde entwickelt, um diese Lücke zu schließen. Anstatt eines Prompts wird jedes Modell in ein mehrwöchiges Geschäftsprojekt mit vielen verknüpften Aufgaben und Tausenden von Quelldateien geworfen und gebeten, die Art von Ergebnissen zu liefern, die ein echter Analyst oder ein Product Manager erbringen würde: Finanzmodelle, Vorstandspräsentationen, Design-Mockups, Strategiememos. Die Szenarien wurden über Monate von Branchenexperten von Unternehmen wie Google, McKinsey und Boston Consulting Group entwickelt, sodass die Arbeit dem ähnelt, was diese Firmen tatsächlich tun.
Die Zahlen verdeutlichen den Umfang. Es gibt vier zurückgehaltene Projektszenarien und insgesamt 91 Aufgaben aus den Bereichen Data Science, Produktmanagement und Unternehmensstrategie. Darin befinden sich fast 2.000 Quelldateien, darunter mehr als 3.500 E-Mails und 25.000 Slack-Nachrichten – absichtlich fragmentiert und voller realistischer Widersprüche. Die vier Bewertungsszenarien sind ein Data-Science-Projekt, ein Produktmanagement-Projekt, eine Banking-Operations-Transformation und ein Heavy-Industry-Strategy-Build. Ein fünftes Due-Diligence-Szenario ist öffentlich und fließt nicht in die Scores ein.
Diese Rahmung ist wichtig, weil sie den Fehlerfall jedes KI-Agenten widerspiegelt, den ich je ausgeliefert habe: Das Modell kämpft selten mit der Idee, sondern damit, die eine Anforderung zu finden, die in Datei 1.400 versteckt ist, ohne der E-Mail zu widersprechen, die sie stillschweigend überschrieben hat.
Wie AA-Briefcase ein Modell bewertet
Hier wird AA-Briefcase clever. Ein einziger Score würde das Interessanteste am KI-Output verbergen: Professionell aussehen und korrekt sein sind zwei völlig verschiedene Fähigkeiten. Daher wird jede Aufgabe nach drei separaten Dimensionen bewertet.
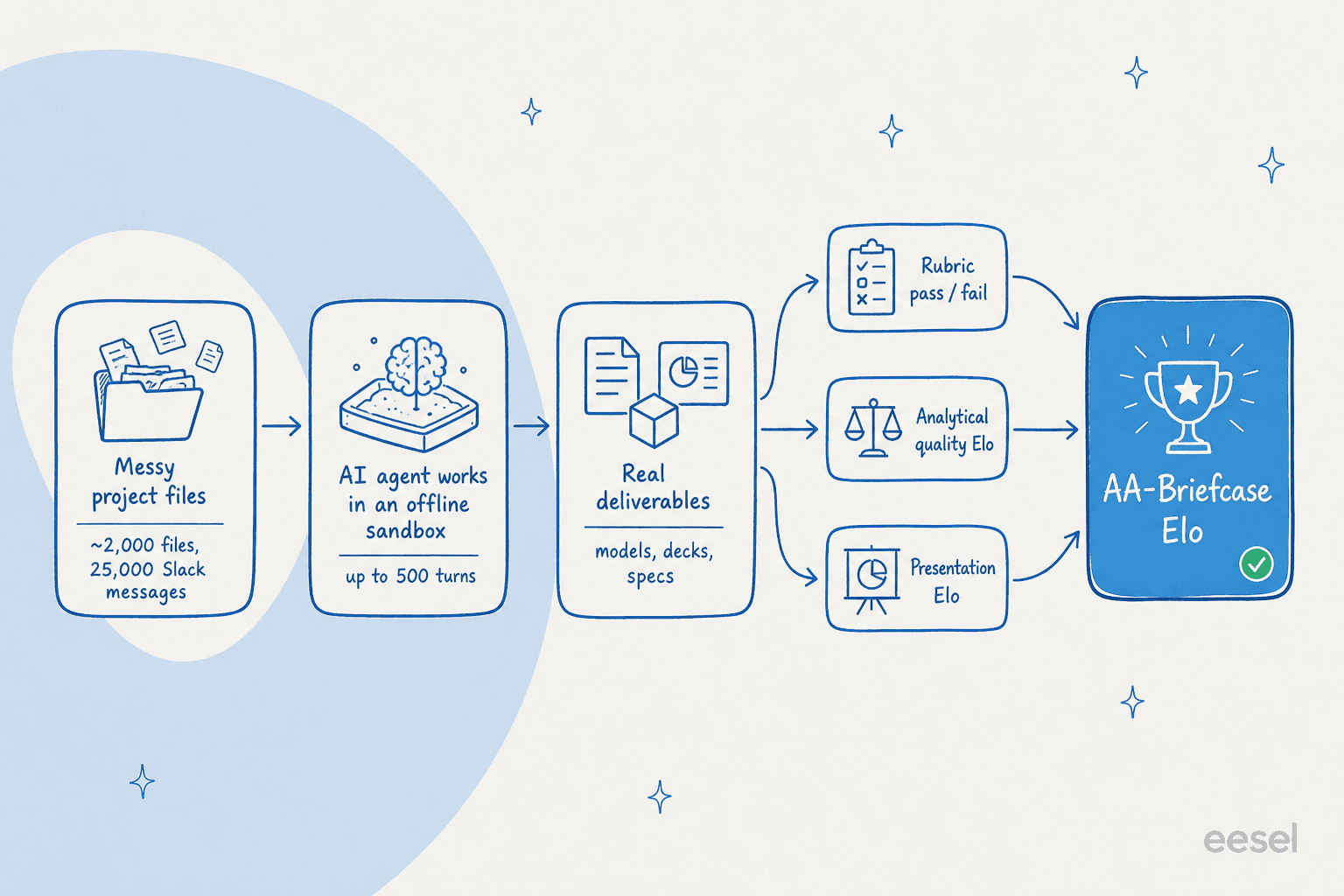
Erstens gibt es eine binäre Rubrik: Bestanden oder nicht bestanden für jede Prüfung, ohne Teilpunkte. Hat das Modell die Anweisungen befolgt, über Dateien verteilte Anforderungen gefunden, die richtigen Belege verwendet und die korrekte Schlussfolgerung gezogen? Zweitens gibt es analytische Qualität, die durch paarweisen Vergleich mit der Einreichung eines anderen Modells beurteilt wird: Welches Ergebnis ist gründlicher und besser belegt? Drittens gibt es Präsentation, ebenfalls paarweise: Welches Ergebnis ist professioneller aufbereitet?
Diese drei fließen in eine einzige Gesamtkennzahl ein, den AA-Briefcase Elo, der analytischen Elo, Präsentations-Elo und Rubrik-Bestehensquote durch Maximum-Likelihood-Elo-Aggregation kombiniert. Damit keine Modellfamilie sich selbst bevorzugt bewertet, wird jeder Vergleich von einem Gremium aus drei Richtern entschieden: Claude Opus 4.8, GPT-5.5 und Gemini 3.1 Pro Preview.
Die Infrastruktur ist ebenfalls offen. Modelle laufen auf Stirrup, dem Open-Source-Agent-Harness von Artificial Analysis, in einer Offline-Sandbox ohne Internet, für bis zu 500 Turns pro Aufgabe. Das ist ein anspruchsvolles Setup und einem echten agentischen Workflow deutlich näher als ein Chat-Fenster.
Was die Ergebnisse tatsächlich aussagen
Das Leaderboard oben erzählt die erfreuliche Geschichte (Claude Fable 5 vorne, Leistungsstufen ordentlich gestapelt). Die schwierigere Geschichte steckt in den Bestehensquoten.
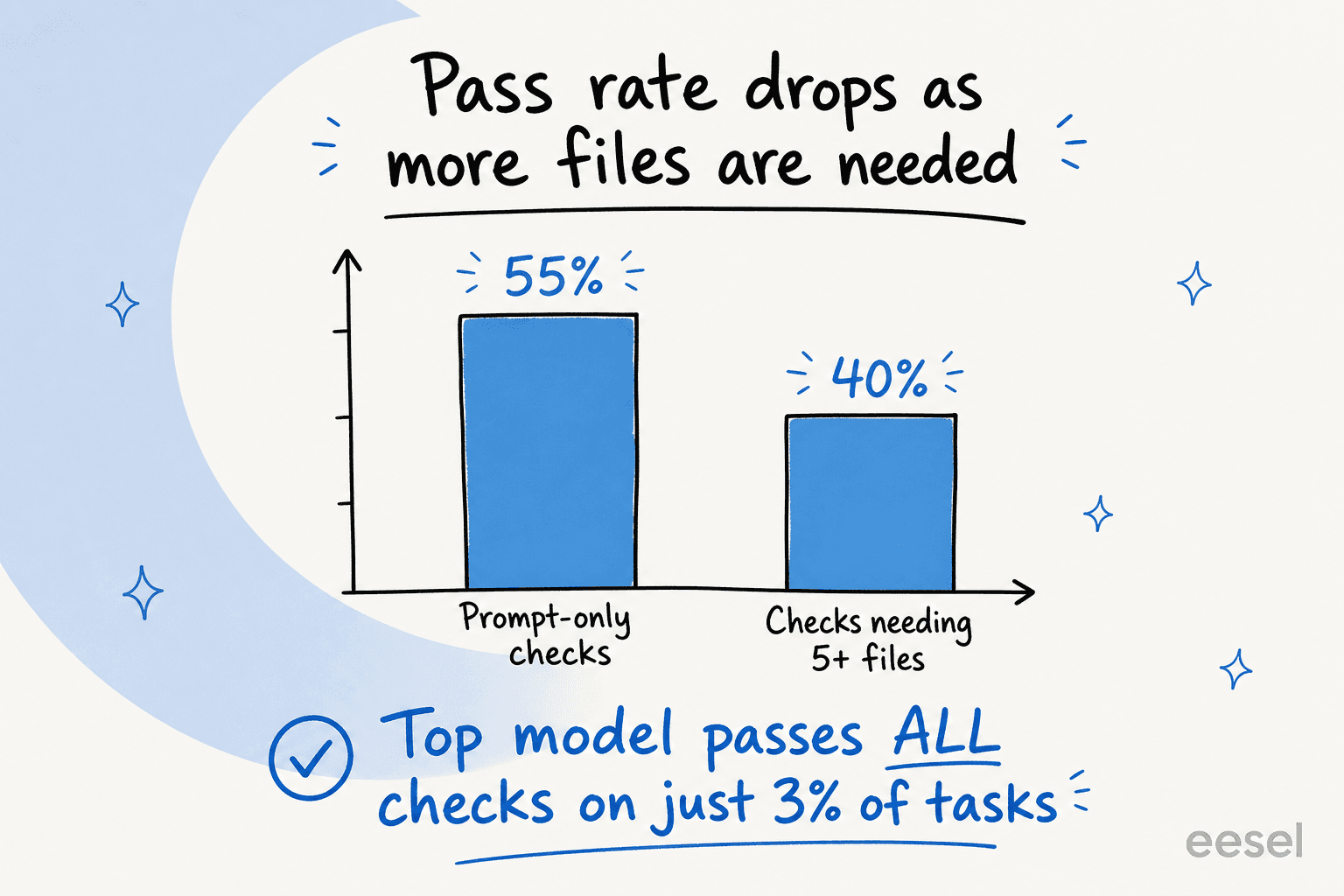
Selbst das führende Modell erfüllt alle Rubrikkriterien nur bei 3 % der Aufgaben, und bei 31 der 91 Aufgaben erzielt kein Modell über 50 %. Der Schwierigkeitsgrad steigt auch mit der Anzahl der benötigten Dateien: High-Intelligence-Modelle fallen von rund 55 % bei Prompt-only-Prüfungen auf etwa 40 %, sobald eine Aufgabe fünf oder mehr erfordert. Je mehr eine Aufgabe echter Arbeit ähnelt, desto schlechter schneiden alle ab.
Das Leaderboard liefert einige bemerkenswerte Erkenntnisse. GLM-5.2 ist der klare Open-Weight-Spitzenreiter und das Preis-Leistungs-Highlight – rund 90 Elo hinter Claude Opus 4.8 für weniger als ein Viertel der Kosten. MiniMax-M3 und GLM-5.2 übertreffen beide ihre allgemeinen Intelligenz-Scores, während Googles Gemini-Modelle bei AA-Briefcase tatsächlich schlechter abschneiden als in breiten Intelligenzrankings. Und wie die Kostenansicht im Widget zeigt, beträgt der Spread zwischen dem teuersten und günstigsten Modell über 800× – eine nützliche Erinnerung, wenn man die tatsächlichen Kosten eines KI-Agenten gegen die Metriken abwägt, die wirklich zählen.
Das Problem "sieht richtig aus, ist aber falsch"
Mein Lieblingsbefund der gesamten Veröffentlichung ist ein verhaltensbezogener, und er erklärt viel darüber, warum KI-Arbeit sich unzuverlässig anfühlen kann.
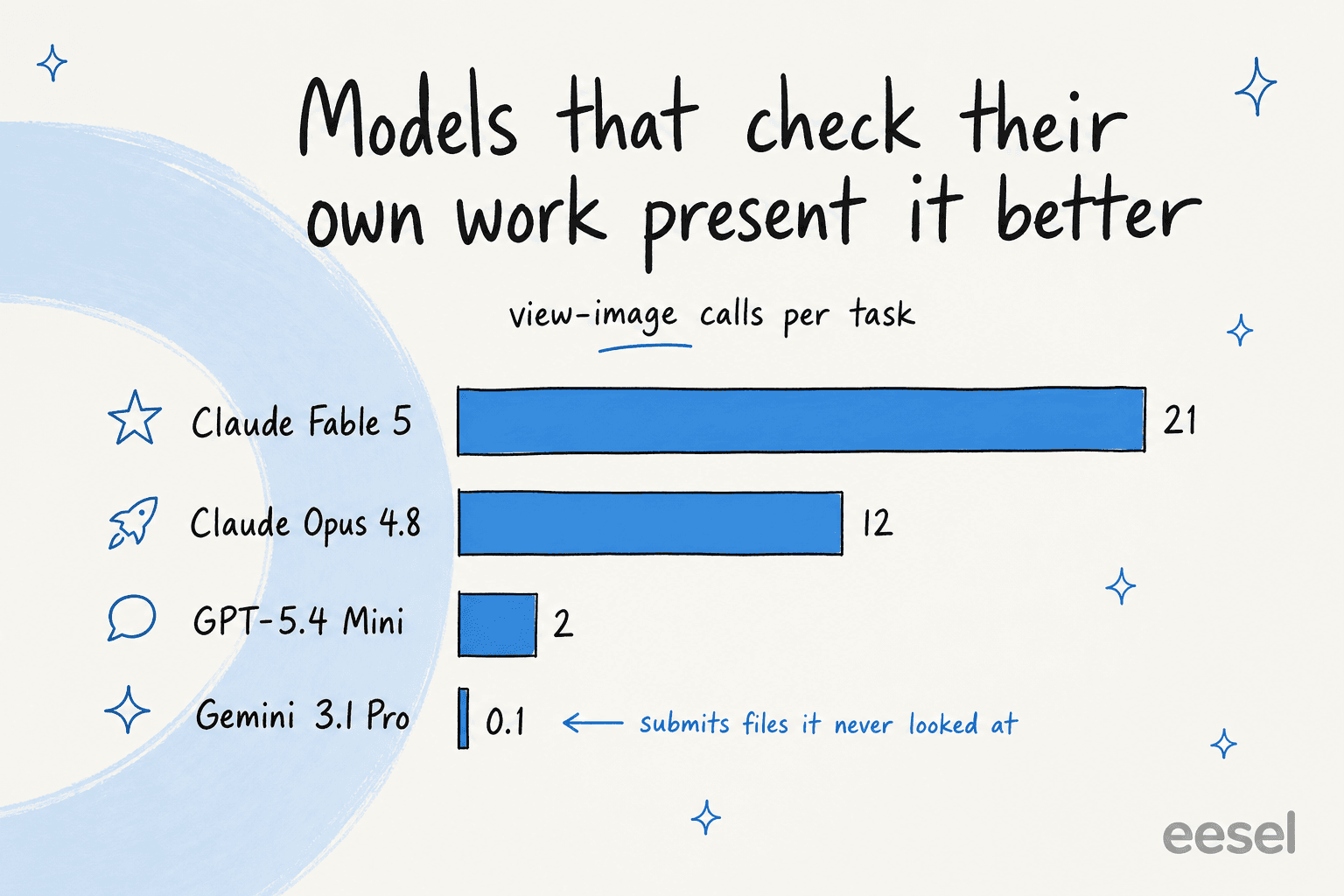
Die Modelle, die bei der Präsentation am besten abschneiden, sind diejenigen, die ihre eigenen gerenderten Ergebnisse tatsächlich betrachten. Claude Fable 5 machte etwa 21 View-Image-Aufrufe pro Aufgabe und Opus 4.8 etwa 12, während einige Modelle Dateien einreichten, die sie kaum angeschaut hatten (Gemini 3.1 Pro Preview durchschnittlich rund 0,1 View-Image-Aufrufe). Es stellt sich heraus, dass "Überprüfe deine Arbeit, bevor du sie abgibst" für eine KI genauso guter Rat ist wie für einen Menschen.
Darunter liegt ein tieferer Punkt. AA-Briefcase trennt Politur von Korrektheit, weil eine selbstsichere, gut formatierte Antwort, die leise falsch ist, gefährlicher ist als eine offensichtlich unvollständige. Genau dieses Risiko taucht auf, wenn ein KI-Chatbot einem Kunden antwortet, und deshalb ist das Verhindern von Halluzinationen im Support das Wichtigste – kein nettes Zusatzfeature.
Warum ein Leaderboard-Score kein Deployment-Plan ist
Ein Frontier-Modell kann also echte Wissensarbeit leisten – manchmal brillant –, und dennoch bei den schwierigsten, dateireichsten Aufgaben meist scheitern. Wenn Sie eine Sache aus AA-Briefcase mitnehmen, dann diese: Eine Benchmark-Platzierung ist ein allgemeines Leistungssignal, keine Garantie dafür, wie sich ein Modell auf Ihren ungeordneten Daten verhält.
Ich habe das aus erster Hand erlebt. Wir haben jahrelang KI-Agenten auf Live-Support-Queues gesetzt, und das, woran Teams scheitern, ist nicht, ob das Basismodell abstrakt klug genug ist – sondern ob es auf ihren spezifischen Tickets, ihren Produkteigenheiten und ihren Randfällen genau bleibt. Ein Modell, das jedes öffentliche Leaderboard anführt, kann am ersten Tag trotzdem selbstsicher Ihre Rückgaberichtlinie falsch zitieren, lange bevor es zur automatisierten Ticket-Auflösung kommt. Das ist kein Vorwurf gegen das Modell; es ist der Unterschied zwischen einem Benchmark und der Produktion.
Die Lösung folgt demselben Instinkt, auf dem AA-Briefcase aufgebaut ist: Bewerten Sie die Arbeit anhand von Grundwahrheiten, bevor Sie ihr vertrauen. Für ein Helpdesk bedeutet das, die KI gegen eigene historische Tickets zu testen und genau zu sehen, was sie geantwortet hätte, anstatt ein Datenblatt zu lesen und zu hoffen. Betrachten Sie es als Ihr eigenes privates AA-Briefcase, bei dem der Testsatz Ihre echte Support-Historie ist.
eesel für KI-Support ausprobieren, dem Sie wirklich vertrauen können
Wenn AA-Briefcase Sie überzeugt hat, dass Leistungsfähigkeit und Zuverlässigkeit nicht dasselbe sind, ist das genau das Problem, für das eesel AI entwickelt wurde. eesel funktioniert wie ein neues Support-Teammitglied, das sich in Minuten in Ihr bestehendes Helpdesk und Ihre Wissensbasis einklinkt und Sie dann auf Tausenden vergangener Tickets simulieren lässt, bevor es je mit einem Kunden spricht – so sehen Sie die echte Lösungsrate und genaue Antworten im Voraus, statt aus einem Leaderboard zu schätzen.

Sie behalten die Kontrolle darüber, was beantwortet werden darf und wann eskaliert wird, und es ist kostenlos, auf Ihren eigenen Daten auszuprobieren. Wenn Sie KI für den Kundenservice evaluieren, ist dieser Simulate-First-Ansatz das Nächste, was es gibt, um die "Beweise es an echter Arbeit"-Strenge von AA-Briefcase auf Ihre eigene Queue zu übertragen.
Häufig gestellte Fragen
Was ist der AA-Briefcase-Benchmark?
Welches KI-Modell schneidet bei AA-Briefcase am besten ab?
Wie wird AA-Briefcase bewertet?
Warum erzielen KI-Modelle bei AA-Briefcase so niedrige Scores?
Bedeutet ein hoher AA-Briefcase-Score, dass das Modell sicher einsetzbar ist?
Wie unterscheidet sich AA-Briefcase von anderen KI-Benchmarks?
Kann ich AA-Briefcase nutzen, um ein KI-Tool für den Kundensupport auszuwählen?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.








