Como automatizar a triagem de tickets: um guia passo a passo para equipes de suporte
Stevia Putri
Katelin Teen
Última edição May 15, 2026
Quando sua caixa de entrada abre toda manhã, todos os tickets estão marcados como URGENTE. Os mesmos agentes passam a primeira hora do turno não resolvendo problemas - apenas organizando-os. 15-25% dos tickets atribuídos serão reatribuídos pelo menos uma vez, acrescentando aproximadamente 47 minutos a cada tempo de resolução. Para uma equipe que processa 2.000 tickets por mês com uma taxa de roteamento incorreto de 35%, isso representa $329.000 por ano em retrabalho evitável - sem contar penalidades de SLA, churn por resolução lenta ou o custo para o moral de agentes qualificados atuando como organizadores de caixa de entrada.
O agente de helpdesk do eesel AI lê cada ticket recebido, classifica-o, define a prioridade, roteia-o para a fila correta e sinaliza riscos de escalonamento - tudo em menos de um segundo, antes que um humano o abra. Equipes que utilizam a automação de suporte do eesel tipicamente atingem 73%+ de resolução autônoma no primeiro mês. Este guia cobre exatamente como chegar lá: o que a triagem realmente envolve, onde as abordagens manuais atingem seu limite e os nove passos para configurar uma triagem automatizada que se sustente ao longo do tempo.
O que a triagem de tickets realmente envolve
A triagem é o trabalho que acontece entre a chegada de um ticket e o início da resolução por um agente. São quatro decisões, tomadas para cada ticket individualmente:
Classificação. Do que trata este ticket? Área do produto, tipo de problema, segmento do cliente, causa raiz, sentimento. Sem classificação consistente, o roteamento é uma adivinhação e os relatórios de tendências não têm sentido. A SentiSum descreve isso como construir uma "taxonomia de etiquetas" - um conjunto definido de categorias com definições de uma frase para que cada agente (e cada IA) aplique os mesmos rótulos. No mínimo: área do produto, tipo de problema, sinal de urgência, sentimento, causa raiz e segmento do cliente.
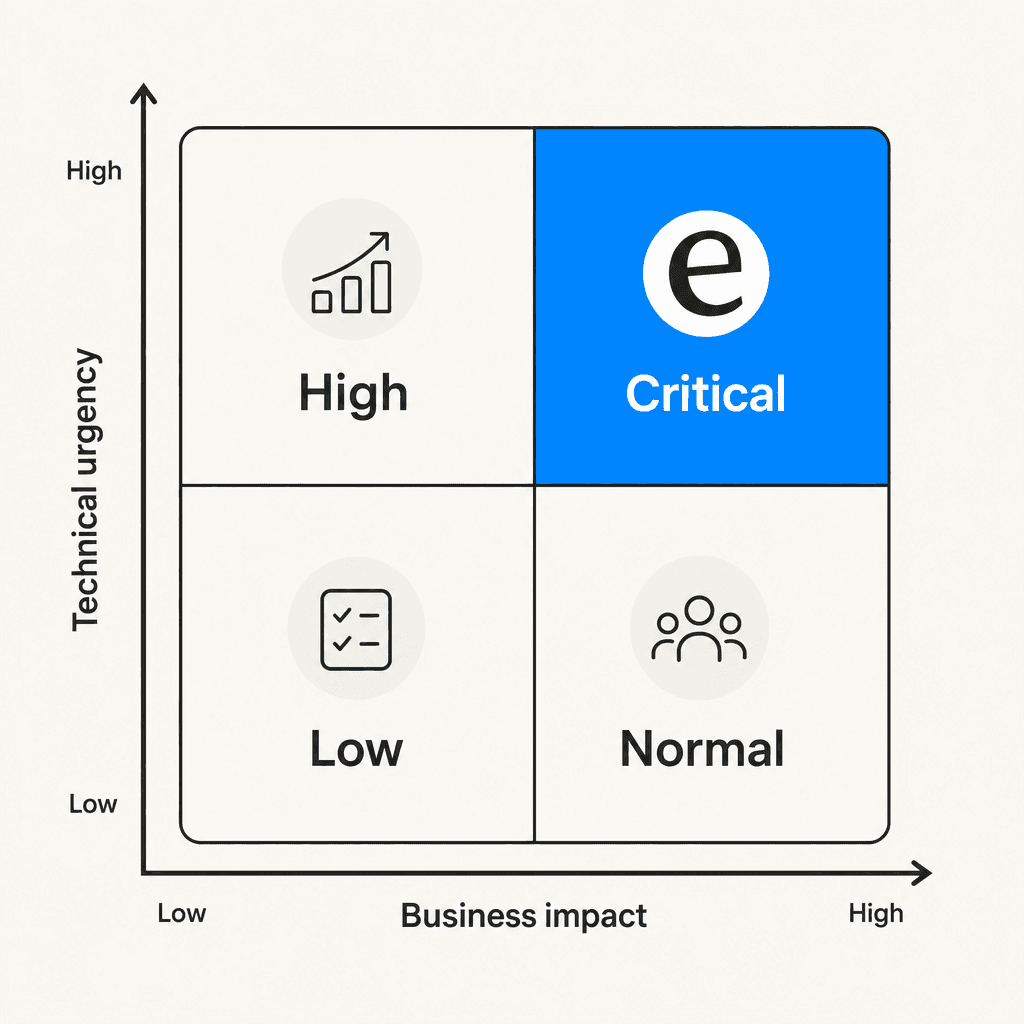
Priorização. Quão urgente é este ticket em relação a tudo mais que está aberto? O framework ITIL mapeia duas variáveis: impacto nos negócios (quantos usuários ou operações são afetados - o domínio do cliente) e urgência técnica (quão grave é o problema técnico - o domínio da equipe de suporte). Juntas, elas produzem um nível de prioridade. A regra de design fundamental: os clientes não definem seu próprio rótulo de urgência. Eles relatam o impacto. A equipe de suporte determina a urgência.
Roteamento. Para onde vai este ticket? Fila, equipe, agente individual. Os critérios de roteamento tipicamente incluem tipo de problema, habilidade do agente, nível do cliente (enterprise vs. PME), idioma e canal de origem.
Escalonamento. Este ticket precisa ser movido para um nível superior antes que a situação piore? O escalonamento manual depende de um agente notar um problema - uma cadeia que se rompe sob volume, especialmente para tickets de alto sentimento que não parecem urgentes à primeira vista.
O custo de errar qualquer uma dessas quatro decisões é concreto. Uma equipe que processa 2.000 tickets por mês com uma taxa de roteamento incorreto de 35% - 700 tickets reatribuídos, cada um acrescentando 47 minutos de retrabalho - gera um custo de mão de obra de $329.000 por ano antes de contar uma única violação de SLA. Isso a $50/hora. Escale para $75/hora e o número sobe para quase $500.000.
Por que a triagem manual e baseada em regras fica aquém
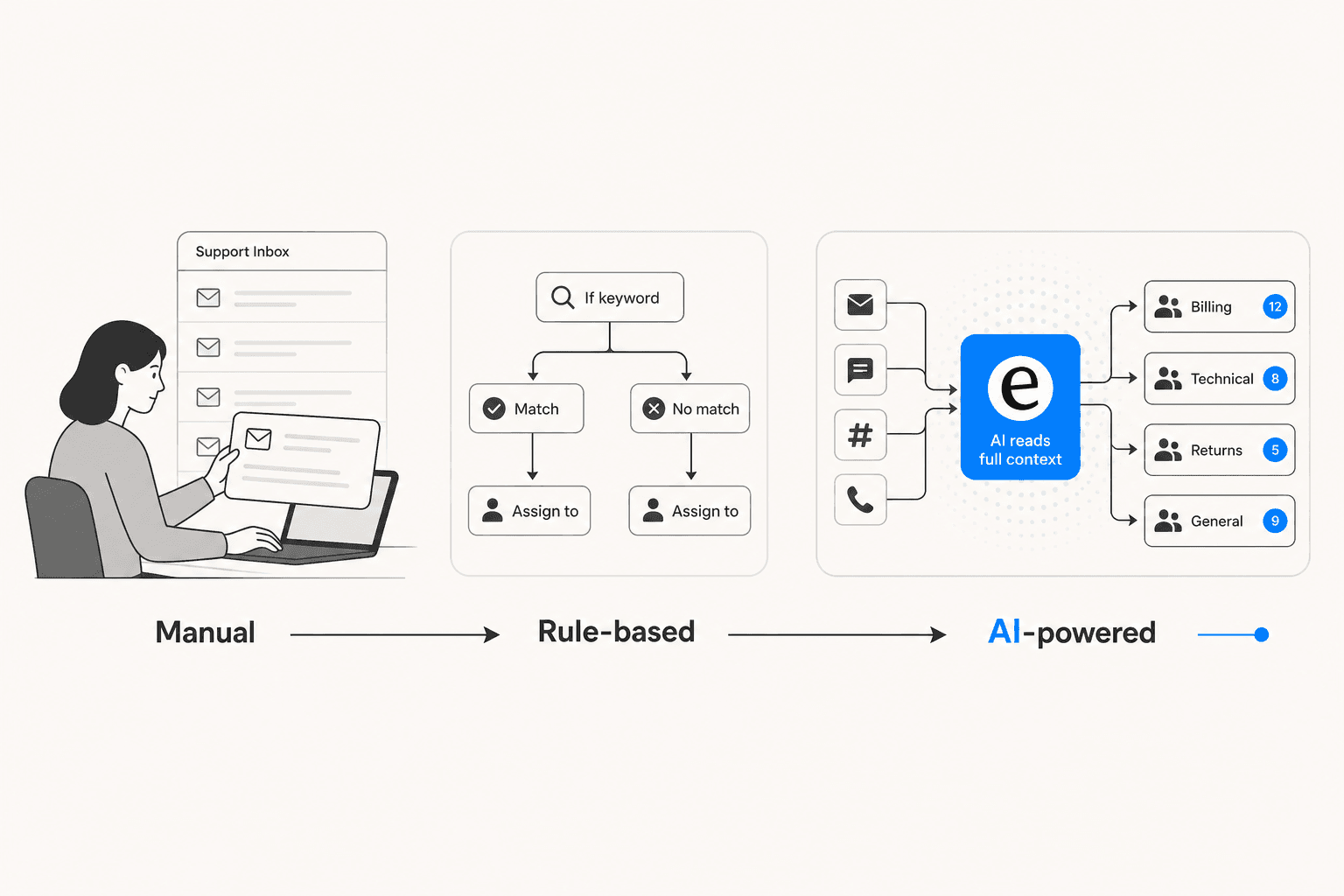
A maioria das equipes de suporte começa com uma de duas abordagens. Ambas têm limites difíceis.
Triagem manual significa que uma pessoa - ou um rodízio de triagem entre a equipe - lê cada ticket recebido e toma todas as quatro decisões manualmente. A SentiSum documentou o caso da GoCardless com dois agentes dedicados em tempo integral apenas para classificação de tickets, usando três tags de severidade (B1, B2, B3). O trabalho de classificação era suficientemente consistente para que automatizá-lo recuperasse ambos os FTEs. A triagem manual leva de 1 a 3 minutos por ticket, degrada-se sob volume e varia conforme o humor e o turno do agente.
Automação baseada em regras é a atualização óbvia: lógica de if/then baseada em palavras-chave, domínios de e-mail, campos de formulário e linhas de assunto. Todo helpdesk oferece isso - triggers do Zendesk, automações do Freshdesk, filas de SLA do Jira. Funciona bem para tipos de tickets simples e estáveis e é rápido de configurar. O teto é baixo: a IrisAgent situa a precisão do roteamento baseado em regras em 40-50%. As regras quebram em sinônimos e erros de digitação, falham em tickets com múltiplos problemas, não têm consciência de sentimento e exigem atualizações manuais constantes à medida que o produto muda. O lançamento de um novo recurso desencadeia uma nova rodada de manutenção de regras.
Uma observação de um tópico do r/msp com 86 comentários sobre sobrecarga de triagem captura o modo de falha operacional comum a ambas as abordagens:
"A lição MAIS importante que aprendi tarde demais: você DEVE FAZER A TRIAGEM DE TODOS OS TICKETS ANTES DE DESPACHAR QUALQUER UM. Faça a triagem de todos, depois despache todos. Não um de cada vez."
Quando triagem e despacho acontecem simultaneamente - o padrão em qualquer configuração manual ou baseada em regras simples - tickets urgentes ficam enterrados sob chegadas anteriores não urgentes. A caixa de entrada torna-se uma fila ordenada por hora de chegada, e não por prioridade.
A triagem com IA quebra ambos os tetos. Ela lê o conteúdo completo do ticket, o histórico de conversas, o sentimento do cliente e o contexto da conta, e toma todas as quatro decisões de triagem em menos de um segundo. A IrisAgent situa a precisão do roteamento com IA em 85-95% em implantações maduras - contra o teto de 40-50% para regras - com mais de 90% de consistência de etiquetas e 50% menos reatribuições.
Como automatizar a triagem de tickets com eesel AI
O agente de helpdesk do eesel AI conecta-se ao seu helpdesk existente - Zendesk, Freshdesk, Gorgias, HubSpot e outros - e aprende sua operação imediatamente a partir de tickets passados, macros, artigos da central de ajuda e documentação conectada. Sem treinamento manual, sem assistentes de configuração.
Para triagem, o eesel lida com as quatro decisões:
- Classificação: Etiqueta tickets por tipo de problema, área do produto, sentimento e segmento do cliente com base na sua taxonomia existente
- Priorização: Pontua cada ticket em relação à sua matriz de prioridade definida, considerando o nível do cliente, a proximidade do SLA e o sentimento em tempo real
- Roteamento: Atribui tickets à fila ou agente certo com base em habilidades, idioma, capacidade e canal
- Escalonamento: Monitora sinais de churn, risco de SLA e deterioração do sentimento, e escala antes que uma situação se agrave
O que diferencia o eesel de um motor de regras é o modo de simulação. Antes de entrar em operação, o eesel processa milhares de seus tickets históricos e mostra exatamente como teria feito a triagem de cada um - para que você possa comparar as decisões da IA com o que seus agentes realmente fizeram, calibrar onde divergem e entrar em operação com confiança. Nenhum ticket de cliente ao vivo fica em risco durante os testes.
Implantações maduras do eesel atingem até 81% de resolução autônoma. A Gridwise resolveu 73% das solicitações de nível 1 no primeiro mês. A Smava processa mais de 100.000 tickets por mês pelo eesel em alemão, totalmente automatizado.
A implantação é deliberadamente progressiva: comece com o eesel redigindo respostas para revisão dos agentes em alguns tipos de tickets, verifique a precisão e, em seguida, expanda sua autonomia conforme a confiança aumenta - da mesma forma que você promoveria qualquer novo membro da equipe com base no desempenho demonstrado.
Configurando a triagem automatizada: os 9 passos
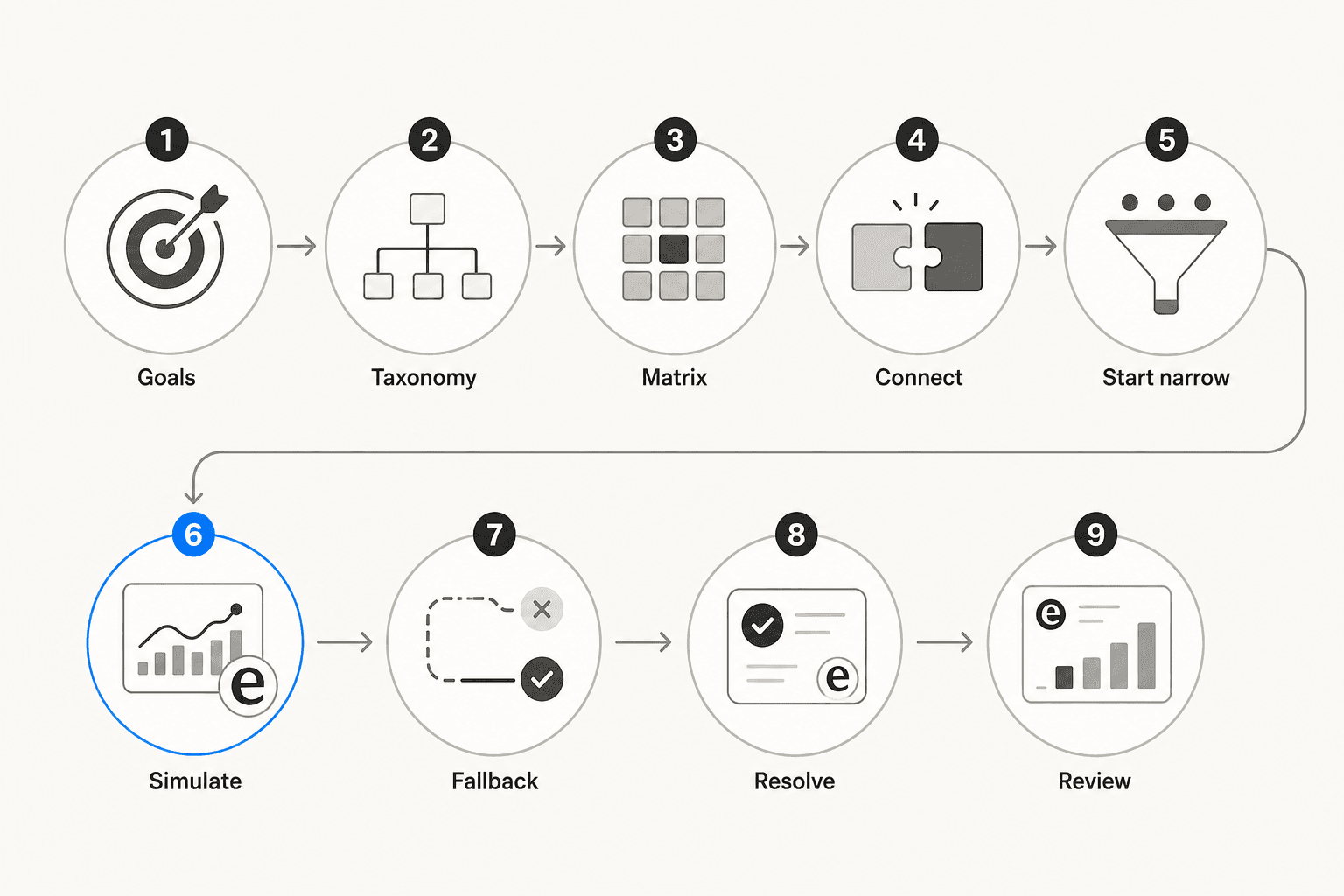
Passo 1: Defina suas metas e SLAs
Antes de tocar em qualquer ferramenta, decida como é o sucesso. A SentiSum recomenda ancorar em perguntas específicas e mensuráveis: Qual segmento de clientes precisa de resposta mais rápida? Qual tipo de ticket causa mais violações de SLA? Qual é o tempo atual de primeira resposta para tickets Críticos?
Defina metas explícitas de SLA por nível de prioridade. As melhores práticas do eesel AI sugerem algo como: Crítico = resposta em 15 minutos, Alto = 1 hora, Normal = 8 horas, Baixo = 24 horas. Os números exatos importam menos do que a consistência. Uma vez definidos os SLAs, a automação de triagem tem uma condição clara de sucesso.
Passo 2: Crie uma taxonomia de etiquetas limpa
Mapeie cada categoria de ticket em que você precisa agir e escreva uma definição de uma frase para cada uma. O guia da IrisAgent é direto: "Se sua taxonomia de etiquetas tem 200 categorias sobrepostas, a automação apenas acelera a bagunça. Limpe a taxonomia antes de treinar qualquer modelo."
Consolide etiquetas redundantes, exclua as não utilizadas e padronize antes de conectar qualquer automação. Cubra no mínimo: área do produto, tipo de problema, sinal de urgência, sentimento, causa raiz e segmento do cliente. O teto de precisão da IA é definido pela clareza das categorias - uma taxonomia confusa produz um modelo confuso.
Passo 3: Crie uma matriz de prioridade
Construa uma grade 2×2 mapeando impacto × urgência para quatro níveis: Crítico, Alto, Normal, Baixo. O guia do eesel AI e múltiplos profissionais do r/msp recomendam essa abordagem, baseada no framework ITIL.
Regra de design fundamental: os clientes controlam o impacto ("quantos usuários estão bloqueados?"), sua equipe controla a urgência ("quão grave é o problema técnico?"). Nunca permita que os clientes auto-atribuam um rótulo de prioridade. Use perguntas estruturadas de entrada que produzam respostas objetivas - "Existe uma solução alternativa?" e "Quantos usuários são afetados?" - e mapeie essas respostas para um nível automaticamente.
Passo 4: Conecte seu helpdesk e importe o histórico de tickets
Instale o eesel AI pelo marketplace do seu helpdesk e importe de 6 a 12 meses de tickets resolvidos. A IrisAgent recomenda essa importação histórica como o caminho mais rápido para etiquetagem precisa desde o primeiro dia - o modelo treina com seus dados reais, terminologia e padrões de resolução, em vez de uma linha de base genérica do setor.
Para triagem baseada em regras: identifique os gatilhos (domínio de e-mail, palavras-chave do assunto, canal) e configure-os diretamente nas configurações do seu helpdesk.
Passo 5: Comece com seus 3-5 intents de maior volume
Não automatize tudo no primeiro dia. A IrisAgent é explícita: escolha os 3-5 intents de maior volume - redefinições de senha, status de pedidos, questões de faturamento - e comprove 90%+ de precisão nesses antes de expandir. Cobertura total desde o primeiro dia significa precisão medíocre em tudo, o que corrói a confiança da equipe antes que ela tenha chance de se construir.
Passo 6: Simule antes de entrar em operação
Execute sua configuração de triagem em tickets históricos no modo de simulação antes de tocar em um cliente ao vivo. O recurso de simulação do eesel AI mostra como a IA teria tratado milhares de tickets passados - quais teria roteado corretamente, quais incorretamente e quais teria escalonado - para que você possa calibrar antes do lançamento. Isso elimina o risco de descobrir problemas por meio de reclamações de clientes.
Passo 7: Projete o caminho de fallback
Quando a pontuação de confiança da IA cair abaixo do seu limite, ela deve rotear o ticket para triagem humana com seu raciocínio anexado - não forçar uma decisão de baixa confiança. A IrisAgent chama isso de mecanismo de confiança: fallbacks de falha rígida destroem a confiança mais rapidamente do que roteamentos incorretos ocasionais. A fila de fallback também é a rede de segurança para tickets novos que não correspondem aos padrões de treinamento.
Passo 8: Resolva na triagem, não depois
A triagem é a primeira oportunidade de resolver um ticket, não apenas organizá-lo. A Wrangle e a DevRev descrevem IA agêntica fechando respostas de problemas conhecidos, consultas de instruções (extraindo da base de conhecimento), consultas de conta e reconhecimentos de solicitações de recursos - sem rotear para um agente. O cliente da DevRev, BILL, alcançou mais de 70% de resolução autônoma ao incorporar a resolução na etapa de triagem. O benchmark para triagem de IA madura é de cerca de 60% de resolução automática.
Passo 9: Feche o ciclo semanalmente
Cada correção manual feita por um agente após um roteamento incorreto é um sinal de treinamento. A IrisAgent recomenda revisar tickets mal etiquetados semanalmente e alimentar as correções de volta ao modelo. Equipes que mantêm essa cadência atingem 100% de cobertura de triagem automática em 60-90 dias. Pule o ciclo por um trimestre e a precisão decai silenciosamente - o que a IrisAgent chama de "drift de automação" - à medida que o produto evolui e o mix de tickets muda.
Erros comuns que destroem projetos de triagem automatizada
A maioria das falhas em automação de triagem são falhas de processo, não de modelo.
Permitir que os clientes auto-relatem a prioridade. Kirsty Pinner, Chefe de Produto de uma empresa de análise de atendimento ao cliente, via SentiSum: "Uma das coisas que a maioria das empresas erra é permitir que os clientes auto-relatem problemas em formulários. Isso causa desconfiança inerente em qualquer análise subsequente." Quando todo cliente pode marcar seu próprio ticket como Crítico, a palavra deixa de ter significado. Use perguntas estruturadas de entrada vinculadas a critérios objetivos.
Automatizar uma taxonomia bagunçada. Se suas etiquetas estiverem sobrepostas e aplicadas de forma inconsistente antes da automação, elas estarão sobrepostas e aplicadas de forma inconsistente mais rapidamente após a automação. A IA não corrige a taxonomia - ela a amplifica.
Tentar cobrir tudo no primeiro dia. O que acontece quando as equipes correm para a cobertura total, do r/automation:
"Alguns erros são suficientes para fazer sua equipe perder a confiança no agente, o que é a pior coisa que pode acontecer. Uma vez que eles não confiam nele, vão verificar tudo duas vezes e a automação basicamente morre."
Lógica de escalonamento confusa. Esta é a fonte da maioria das reclamações sobre triagem de IA em produção:
"A maioria dos problemas não são problemas de modelo. São problemas de política. Se sua lógica de escalonamento é confusa, a IA apenas amplifica a confusão."
u/DFSautomations, r/automation
Antes de culpar o modelo por decisões de escalonamento incorretas, verifique se suas regras de escalonamento são claras o suficiente para um humano seguir de forma consistente. Se não forem, nenhuma quantidade de configuração de IA as corrigirá.
Despachar antes de triar a fila completa. Do r/msp: faça a triagem de todos os tickets na fila primeiro, depois despache. O despacho um a um enterra tickets urgentes sob os não urgentes que simplesmente chegaram antes.
Pular a revisão de correção semanal. A precisão decai conforme seu produto evolui e o mix de tickets muda. O ciclo de correção é o que mantém o modelo atualizado. Sem ele, você está operando com um modelo desatualizado e não saberá até que violações de SLA comecem a aparecer.
Experimente o eesel AI
O agente de helpdesk do eesel AI lida com a triagem de tickets de ponta a ponta - classificação, priorização, roteamento e escalonamento - sobre seu helpdesk existente. Você o conecta, executa simulações em tickets passados para verificar a qualidade antes de entrar em operação e expande sua autonomia no seu próprio ritmo conforme ele ganha confiança. O preço é baseado em tarefas a $0,40 por ticket regular, com nenhum cartão de crédito necessário para o teste gratuito.