Together AI が実際に課金する対象
多くの料金解説記事では、Together AI を「構築 / スケール / エンタープライズ」といったティアに当てはめようとします。しかし、価格ページ はそのような仕組みにはなっていません。名前の付いたティアはなく、ユーザーごとの料金も、セルフサービスにおける月額最低料金もありません。あるのは、消費の単位を測定する 4つの並行したメーターであり、ワークロードのデプロイ方法によって 1つ、2つ、あるいは 4つすべてが課金対象となります。
4つの柱:
- サーバーレス推論 - OpenAI 互換の
/v1/chat/completionsエンドポイントを呼び出し、レスポンスを受け取ります。インプットとアウトプットの100万トークンごとに支払います。チャット、ビジョン、画像、オーディオ、動画、書き起こし、埋め込み、モデレーションをカバーし、それぞれモデルごとのレートが設定されています(Together AI pricing)。 - 専用推論 - Together がシングルテナントの GPU インスタンスをプロビジョニングします。これを 24時間 365日稼働させ、GPU 時間単位で支払います。専用メーターはトークン量を完全に無視します。座席を予約しているのであって、乗車回数に対して払うわけではありません。
- GPU クラスター - NVIDIA のハードウェア(8基から 4,000基以上、InfiniBand 接続)をオンデマンドまたは最大 6ヶ月の予約でレンタルします。これは、独自のモデルをトレーニングしたり、独自の推論エンジンを実行したりするチーム向けです。
- ファインチューニング - トレーニングは、モデルのサイズと手法(LoRA、フル FT、DPO)に応じて、トレーニングデータのトークンごとに請求されます。その後、生成されたモデルは専用エンドポイントに配置され、別の時間単位のメーターで課金されます。
これが重要なのは、適切なメーターを選ぶことが節約に直結するからです。Llama 3.3 70B で 1日 500万トークンを処理するスタートアップが専用エンドポイントを使う必要はありませんが、同じモデルで 1日 5億トークンを処理する安定したプロダクションワークロードなら、通常は専用エンドポイントのほうが適しています。Together AI の CEO、Vipul Ved Prakash 氏は、プラットフォームをその中間にある「AI アクセラレーションクラウド」と位置づけており(LinkedIn)、価格構造もそれを反映しています。最初はサーバーレス、負荷が予測できるようになったら専用エンドポイント、トレーニングを行うならクラスター、という流れです。

サーバーレス推論の料金
サーバーレスは入り口であり、ほとんどのチームが利用するメーターです。together.ai/pricing のチャットモデルの表には、サポートされているすべてのモデルの 100万トークンあたりのレートが、インプット、アウトプット、および(一部のモデルでは)ベースよりも大幅に安いキャッシュ済みインプットのレートに分けて記載されています。
チャットタブからの代表的な抜粋です(Together AI pricing よりそのまま引用):
| モデル | インプット $/M | アウトプット $/M | キャッシュ済みインプット $/M |
|---|---|---|---|
| GLM-5.1 | $1.40 | $4.40 | - |
| MiniMax M2.7 | $0.30 | $1.20 | $0.06 |
| Kimi K2.6 | $1.20 | $4.50 | $0.20 |
| DeepSeek V4 Pro | $2.10 | $4.40 | $0.20 |
| DeepSeek V4 Flash | - (価格表示なし) | - | - |
| Qwen3.6-Plus | $0.50 | $3.00 | - |
| Qwen3.7-Max | $1.25 | $3.75 | $0.13 |
| gpt-oss-120B | $0.15 | $0.60 | - |
| gpt-oss-20B | $0.05 | $0.20 | - |
| Llama 3.3 70B | $1.04 | $1.04 | - |
| Qwen3 235B A22B FP8 Throughput | $0.20 | $0.60 | - |
| LFM2 24B A2B | $0.03 | $0.12 | - |
| Cogito v2.1 671B | $1.25 | $1.25 | - |
この表から注目すべき 3つの点があります。
第一に、キャッシュ済みインプットの価格は、あまり語られませんが強力なレバーです。 DeepSeek V4 Pro のインプットコストは、プロンプトの接頭辞(prefix)がキャッシュされると $2.10/M から $0.20/M へと 10.5倍安くなります。Kimi K2.6 は 6倍、MiniMax M2.7 は 5倍安くなります。長いシステムプロンプトを再利用したり、ユーザーコンテキストを繰り返したりするワークロード(ほとんどのエージェントループや RAG パイプライン)では、キャッシュ済みレートこそが実質的な価格となります。表にある非キャッシュの数字はワーストケースです。
第二に、どのモデルウェーブに乗っているかが、プロバイダー選びよりも重要です。 gpt-oss-20B や LFM2 24B は、DeepSeek V4 Pro や GLM-5.1 と同じ価格ページに並んでいます。$0.03/M(LFM2 インプット)と $4.50/M(Kimi K2.6 アウトプット)の間の 100倍以上の差は、Together とその競合他社との同一モデルにおける差よりもはるかに大きいです。「Together は安い」という主張はあまり役に立ちませんが、「この特定のモデルは Together で安い」という主張は多くの場合正しいです。
第三に、ビジョン、画像、オーディオ、動画にはそれぞれ個別のモデルごとのメーターがあります。 画像モデルはメガピクセル単位または画像単位(FLUX.2 [pro] は $0.03/画像、Google Imagen 4.0 Ultra は $0.06/MP)、動画モデルは完成した動画単位(Sora 2 は $0.80、オーディオ付き Google Veo 3.0 は $3.20)、オーディオは分単位(Whisper Large v3 は $0.0015)と 100万文字単位(Cartesia Sonic-3 は $65)に分かれています(Together AI pricing)。マルチモーダルなアプリを構築している場合、同時に複数のメーターに触れることになり、あなたの「Together への支払い」は単一のレートではなくそれらの合計になります。
サーバーレスの入り口には Batch API も含まれています。非同期でモデルあたり最大 300億トークンを処理でき、同期型のサーバーレスよりも最大 50% 低コストで利用できます(Batch Inference API updates 2025)。リアルタイムのレイテンシを必要としないワークロード(合成データの生成、オフライン分類、ログのエンリッチメントなど)にとって、バッチ処理はプラットフォーム上で最も安価で正当な手段です。
Together は、サーバーレスティアの価格だけでなく速度もアピールしています。推論製品ページ によると、公開されている比較では Qwen3 235B 2507 で「最大 2.75倍高速」、Kimi K2 0905 で「65% 以上高速」、gpt-oss-20B で各ベンチマークの次のプロバイダーと比較して「2倍高速」とされています。GPU あたりの 1秒間トークン処理数(TPS)が高いことこそが、最終的に Together が低価格で利益を出し続けられる理由です。 同じハードウェアでも、1秒間により多くの仕事をさせているのです。
私たちの研究者とエンジニアは、AI 推論を物理法則が許す限り高速化することに全力を注いでいます。
Ce Zhang, CTO, Ryan Pollock 氏の LinkedIn 投稿より
専用推論の料金
ワークロードが共有型のサーバーレスを上回った場合、あるいは(より頻繁にあるのは)共有インフラによる予測不能なレイテンシが製品の課題となった場合、Together AI の専用エンドポイントを使用して、シングルテナントの GPU インスタンスをプロビジョニングし、時間単位で支払うことができます(Together AI pricing)。
| ハードウェア | 1時間あたりの価格 |
|---|---|
| 1× H100 80 GB | $6.49 |
| 1× H200 140 GB | お問い合わせ |
| 1× HGX B200 180 GB | $11.95 |
この計算はある側面では過酷です。H100 を 1日 24時間、1ヶ月 30日間稼働させ続けると、GPU 1基あたり月額 $4,672.80 かかります。B200 の場合は $8,604 です。トークン量は関係ありません。リクエストがゼロであってもメーターは進みます。
しかし、別の側面では非常に有利に働きます。リクエストボリュームが十分に大きければ、専用エンドポイントにおけるトークンあたりの実質コストはサーバーレスレートを下回ります。損益分岐点はモデルによりますが、サーバーレスで送受信 $1.04/M トークンの 70B クラスのモデルであれば、安定的で予測可能なトラフィックが月間約 50億トークンを超えたあたりから専用エンドポイントのほうが安くなり始めます。それ以下ならほぼ確実にサーバーレスが安上がりですが、それ以上なら専用エンドポイントが勝ち、一貫したレイテンシも手に入ります。
Salesforce のリサーチチームは、このティアの導入事例として公開されています:
Together には非常に感銘を受けました。レイテンシを 2倍削減し、コストを約 3分の 1 にカットすることができました。
Caiming Xiong, VP, Salesforce AI Research, Together AI inference page
専用エンドポイントを検討する際、本当に答えるべき問いは「Together の $6.49/時 の H100 は他社より安いか?」ではなく、「GPU を 24時間体制で支払うほうが、主に営業時間内に発生するトークン料金を払うよりも安くなるほど、安定したワークロードがあるか?」です。多くのチームにとって、正直な答えは「いいえ」でしょう。
GPU クラスター料金 - オンデマンド vs 予約済み
専用エンドポイントの下にあるのが、スタックの最も素に近いティアである、自分たちで運用するレンタル GPU クラスターです(gpu-clusters)。独自のモデルをトレーニングしたり、カスタム推論エンジンを動かしたり、専用エンドポイント以上の規模にスケールしたりするチームが最終的に行き着く場所です。
オンデマンドクラスターの料金(セルフサービス、従量課金、いつでも解約可能、最大 256基の GPU)(Together AI pricing):
| ハードウェア | GPU 1基あたりの時間単価 |
|---|---|
| NVIDIA HGX H100 | $5.49 |
| NVIDIA HGX H200 | $6.79 |
| NVIDIA HGX B200 | $9.95 |
予約済みクラスターの料金は、期間が長くなるほど安くなります。公開されている最長コミットメントは 180日間で、それ以上は GPU クラスターリクエストフォーム からカスタムのエンタープライズ価格を問い合わせる必要があります(Together AI pricing):
| ハードウェア | 7-30日間 | 31-90日間 | 91-180日間 | 181日間以上 |
|---|---|---|---|---|
| NVIDIA HGX H100 | $4.99 | $4.49 | $3.99 | お問い合わせ |
| NVIDIA HGX H200 | $5.95 | $4.99 | $4.55 | お問い合わせ |
| NVIDIA HGX B200 | $9.65 | $9.35 | $9.09 | お問い合わせ |
| NVIDIA GB200 NVL72 | お問い合わせ | お問い合わせ | お問い合わせ | お問い合わせ |
| NVIDIA GB300 NVL72 | お問い合わせ | お問い合わせ | お問い合わせ | お問い合わせ |
ハイパースケーラーの GPU レンタルと比較して、クラスターティアが興味深い理由は 3つあります。
第一に、全体にわたる InfiniBand インターコネクトを備えたベアメタルパフォーマンスです。Together は、「当社の InfiniBand インターコネクトは、勾配同期を高速に保ち、通信オーバーヘッドを低く抑えます。そのため、トレーニングは単に規模を拡大するだけでなく、完了までの時間が短縮されます」とアピールしています(Together AI gpu-clusters)。同じハードウェアでトレーニングが 30% 速く終わるなら、実質的に同じ時間単価で 30% の割引を受けているのと同じだからです。
第二に、Together Kernel Collection (TKC) がクラスターに同梱されていることです。TKC(FlashAttention の開発者であるチーフサイエンティスト Tri Dao 氏によって構築)は、Together のサーバーレス推論を支える最適化レイヤーと同じものであり、クラスターでも利用可能です。公開されているベンチマークでは、「最適化された TorchTitan + Together Kernel Collection (TKC) を使用して 70B パラメータの Llama アーキテクチャモデル(BF16)をトレーニングしたところ、NVIDIA HGX B200 で GPU あたり 15,264 トークン/秒に達し、NVIDIA HGX H100 の 8,080 トークン/秒から 90% のトレーニング速度向上が見られました」とされています(Together AI gpu-clusters)。
第三に、ストレージが後回しにされていないことです。クラスターには Weka または VAST のパラレルファイルシステムが付属しており、月額 $0.16/GiB で利用でき、エグレス料金(データ転送量課金)はゼロです(Together AI pricing)。S3 のエグレス料金に悩まされてハイパースケーラーから撤退した経験がある人なら、これがどれほど重要か分かるでしょう。
Together AI は、高品質な画像や動画をリアルタイムで大規模に生成するために必要なパフォーマンスと信頼性を提供してくれます。
Victor Perez, Co-Founder, Krea, Together AI gpu-clusters
ファインチューニング料金 - そして誰も教えてくれないホスティングコスト
Together でのファインチューニングは、エポック単位や GPU 時間単位ではなく、トレーニングデータのトークンごとに課金されます(Together AI fine-tuning docs)。価格ページには明確な計算式があります。「価格は、ファインチューニング学習データセット内の処理されたトークンの合計(学習データセットサイズ × エポック数)に、オプションの評価データセット内のトークン(検証データセットサイズ × 評価回数)を加えたものに基づきます」(Together AI pricing)。
標準価格表は、ベースモデルのサイズとチューニング方法に応じてスケールします(Together AI pricing):
| ベースモデルサイズ | SFT - LoRA | SFT - フル | DPO - LoRA | DPO - フル |
|---|---|---|---|---|
| 最大 16B | $0.48 / M | $0.54 / M | $1.20 / M | $1.35 / M |
| 17B–69B | $1.50 / M | $1.65 / M | $3.75 / M | $4.12 / M |
| 70B–100B | $2.90 / M | $3.20 / M | $7.25 / M | $8.00 / M |
1,000億パラメータ(100B)を超えるモデルの場合、Together は「特殊(specialized)」ティアとして、モデルごとに価格を設定しており、多くの場合 1ジョブあたりの最低料金が設定されています(Together AI pricing):
| モデル | SFT (LoRA) | DPO (LoRA) | 最低料金 |
|---|---|---|---|
| DeepSeek-R1 / V3 / V3.1 family | $10.00 / M | $25.00 / M | $20.00 |
| GLM-4.6 / 4.7 | $9.00 / M | $22.50 / M | $27.00 |
| GLM-5 / GLM-5.1 | $40.00 / M | $100.00 / M | $60.00 |
| gpt-oss-120B | $5.00 / M | $12.50 / M | $6.00 |
| Kimi K2 (Thinking / Instruct / Base) | $15.00 / M | $37.50 / M | $60.00 |
| Llama 4 Maverick / Maverick Instruct | $8.00 / M | $20.00 / M | $16.00 |
| Llama 4 Scout | $3.00 / M | $7.50 / M | $6.00 |
| Qwen3-Coder-480B-A35B-Instruct | $9.00 / M | $22.50 / M | $18.00 |
| Qwen3-235B-A22B / Instruct-2507 | $6.00 / M | $15.00 / M | 設定なし |
| Qwen3.5-122B-A10B | $6.00 / M | $15.00 / M | $10.00 |
| Qwen3.5-397B-A17B | $8.00 / M | $20.00 / M | $22.00 |
上記の表は、よく引用されるものです。しかし、多くの人が忘れているのは、トレーニングが終わった後、そのモデルを ホスティングする のに別途継続的な費用がかかるという点です。
ドキュメントより:「トレーニングが終了すると、推論は専用エンドポイントで実行されます」(Together AI docs)。この専用エンドポイントは、専用推論ティアと同じレート、つまり H100 で $6.49/時、B200 で $11.95/時で課金されます(Together AI pricing)。16B ベースの LoRA ならトレーニング自体は数ドル(100万トークンあたり)で済むかもしれませんが、その結果得られたモデルを 1基の H100 で 24時間稼働させ続けると、リクエストを 1件も処理しなくても、GPU 1基あたり月額約 $4,700 かかります。
これがこのプラットフォームにおける最大級の料金の落とし穴です。チームはよく「ファインチューニングの実行には $30 かかる」と計算しますが、これはトレーニングについては正しいものの、その後のホスティング費用が 2桁も大きいことに後で気づくのです。トレーニング工程だけでなく、ライフサイクル全体を計画してください。
ファインチューニングに関して見落としがちなその他の詳細:
- 公表されている無料枠はない。トレーニングの最初のトークンから課金されます。
- デフォルトは LoRA で、フルファインチューニングはオプトイン(選択制)です。LoRA とフルファインチューニングの価格差は小さいため(70B ティアで 100万トークンあたり約 $0.30 の差)、通常はコストではなく品質で判断されます。
- DPO は SFT の約 2.5倍のコストがかかります。モデルを好みに合わせて調整(アライメント)する場合は、それに応じた予算を組んでください。
- **BYOM(自前モデルの持ち込み)**では、カタログ外のベースモデルをアップロードできます。BYOM トレーニングの価格は、モデルが該当する標準サイズバケットの料金に従い、ホスティングも同じ専用レートが適用されます。
サンドボックス、コードインタープリター、マネージドストレージ
エージェント開発者を驚かせることが多い、2つの小さなメーターについても触れておきます。
Code Sandbox は、AI エージェントがコードを実行するための隔離された VM サンドボックスを起動できます。仮想 CPU ごと、および GiB メモリごとに、時間単位で課金されます(Together AI pricing)。
| リソース | 1時間あたりの価格 |
|---|---|
| vCPU あたり | $0.0446 |
| RAM GiB あたり | $0.0149 |
控えめな 4-vCPU, 8 GiB のサンドボックスを 1日の勤務時間(8時間)稼働させ続けると約 $2.39 かかります。単体ではわずかですが、数十個のサンドボックスを並列で動かすエージェントフリート(艦隊)の場合、合計額は急速に膨らみます。
Code Interpreter はその軽量版です。ウォームプール(待機状態のサーバー群)のオーバーヘッドなしで LLM 生成コードを実行するためのシングルセッションサンドボックスで、1セッション(60分)あたり $0.03 です(Together AI pricing)。ほとんどのエージェントのツール利用フローには、これが賢明なデフォルト設定です。
Managed Storage は、クラスターの隣にあるパラレルファイルシステムです。月額 $0.16/GiB で、エグレス料金は無料です(Together AI pricing)。10 TB のワーキングセットなら月額約 $1,638 です。ハイパースケーラーの高性能ファイルシステムと同等ですが、外に出る際の帯域幅料金がかからないのがメリットです。
無料で使えるもの、使えないもの
これについては、無料のものはほとんどないため、手短に説明します。
- 公表されている無料枠はない。公開されている 価格ページ には、サインアップ時のクレジット額、フリートライアル期間、または毎月の無料タスク枠などの記載はありません。
- Batch API が唯一のインライン割引制度。非同期ワークロードに対して、多くの対話モデルで最大 50% オフになります(Batch Inference API updates 2025)。
- ボリューム割引 / コミットメント割引は存在するが、公開されていません。エンタープライズ価格については お問い合わせ する必要があります。
- キャッシュ済みインプットは「ほぼ無料」に近いもの。特定の対話モデルで接頭辞を再利用すると、インプットトークンが 5-10倍安くなります。
技術者の間では、過去にスタータークレジットが言及されたことがあります:
最も高価なモデルでも 100万トークンあたり $0.9 であることを考えると、$25 の無料クレジットはかなり長く使えます。
Chris Samiullah, ML engineer, LinkedIn
この数字は現在、価格ページに一律のポリシーとして掲載されていません。予算を立てる際は、クレジットは「保証されているもの」ではなく「担当者に確認すべきもの」として扱ってください。
Together AI の料金を Fireworks、Groq、Replicate などと比較する
正直なところ、「Together が最安か」は、動かしているモデル、必要なスループット、そしてサーバーレスか専用エンドポイントかによって完全に異なります。主要な共有モデルにおける比較を、2026-06-05 時点の各プロバイダーの公開価格ページからまとめました:
| プロバイダー | Llama 3.3 70B 入 / 出 $/M | DeepSeek R1 入 / 出 $/M | Mixtral 8x22B 入 / 出 $/M | 無料クレジット | 料金モデル |
|---|---|---|---|---|---|
| Together AI | $1.04 / $1.04 | DeepSeek V4 Pro: $2.10 / $4.40 (キャッシュ時 $0.20 入力) | 現在のラインナップになし | 公表なし。バッチ 50% オフ | サーバーレス(トークン)、専用(GPU時間) |
| Fireworks AI | $0.90 / $0.90 (>16B 枠) | DeepSeek V4 Pro: $1.74 / $3.48 | $1.20 / $1.20 (MoE 56-176B) | $1 クレジット | サーバーレス(トークン)、オンデマンド(GPU秒) |
| Groq | $0.59 / $0.79 | ラインナップになし | ラインナップになし | コンソール登録無料 | サーバーレス(トークン) |
| Replicate | ハードウェア秒単位 | $3.75 / $10.00 | ハードウェア秒単位 | 公表なし | ハードウェア秒 + 一部トークン課金 |
| Anyscale | H100 自前デプロイ $9.29/時 | 同様 | 同様 | $100 クレジット | GPU 時間単位 (Anyscale Compute Units) |
| Modal | H100 自前デプロイ 約 $3.95/時相当 | 同様 | 同様 | 月 $30 (Starter), $100 (Team) | コンピュート秒単位 |
| Hugging Face | パススルー推論プロバイダー | パススルー | パススルー | PRO $9/月 + 無料 ZeroGPU | エンドポイント時間 + パススルートークン |
| OpenRouter | $0.10 / $0.32 | $0.50 / $2.15 (R1 0528) | $2.00 / $6.00 | 無料(制限あり)版あり | トークン単位のマーケットプレイス |
この表からいくつかのパターンが見えてきます。
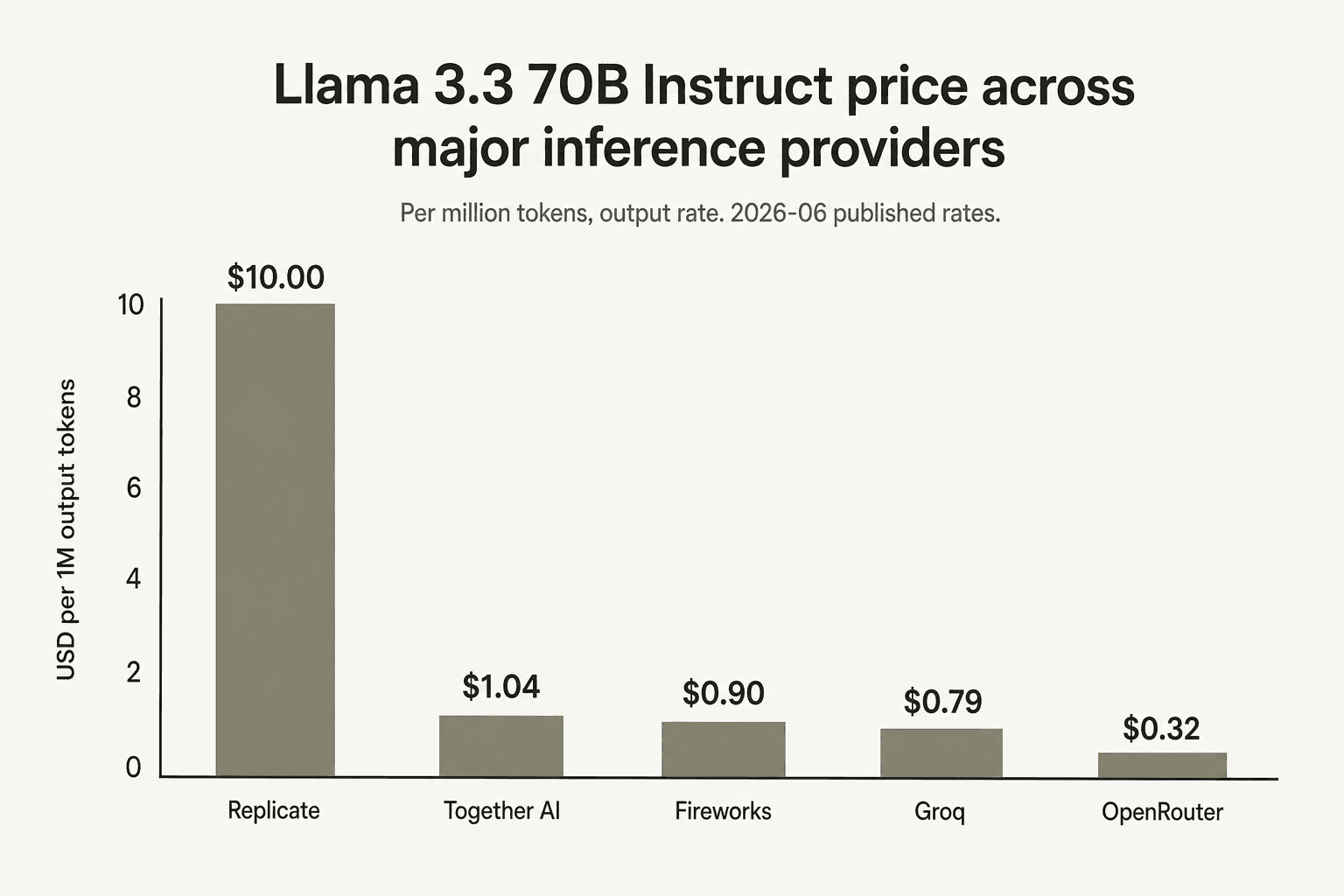
特に Llama 3.3 70B において、Together AI は中位に位置します。 人気のあるこの旧来モデルでは、Groq が最安の第1当事者プロバイダー($0.59/$0.79)であり、次に Fireworks(一律 $0.90)、その次に Together($1.04/$1.04)が続きます。Replicate はトークン単位の価格を掲載していません。そして、最安のプロバイダーへルーティングするマーケットプレイスである OpenRouter は、$0.10/$0.32 と全員を圧倒しています。大量の Llama 3.3 70B 推論を行うなら、Groq や OpenRouter を真剣に検討すべきです。
最新モデル(Kimi K2.6、GLM-5.1、DeepSeek V4、Qwen3.6-Plus)では、Together は競争力がありますが、必ずしも最安ではありません。 Fireworks は新しい Kimi や DeepSeek を個別にリストアップする傾向があり、キャッシュ済みインプットレートを含めると Together と並ぶか、上回ることがあります。差は通常 10-30% 以内であり、マーケティング資料でよく見かけるような 5-10倍の差ではありません。
専用 GPU ホスティングについては、選択肢がより広がります。 Modal は秒単位のコンピュート料金でほぼ全員を出し抜いています(H100 ≈ $3.95/時相当)。Hugging Face Endpoints は H100 で $4.50/時と公表しています。Together は、専用推論で $6.49/時、オンデマンドクラスターで $5.49/時、91-180日の予約クラスターで $3.99/時です。製品が異なれば請求も異なります。実質的なコストは、Modal で自前の vLLM デプロイを運用する手間を許容できるか、それとも Together にホスティングを任せるかという、運用の複雑さによって決まります。
埋め込み(embeddings)については、Together は最安クラスです。 Multilingual e5 large instruct で 100万トークンあたり $0.02 です(Together AI pricing)。Together の公式アカウントは、埋め込みについて「OpenAI よりも最大 4倍低コスト」と宣伝してきましたが(@togethercompute on X)、現在のレートもその範囲内にあります。
バッチ処理については、Together の 50% 割引の Batch API が強力な武器です。 Fireworks も 50% 割引を提供しており、Groq も同様です。Replicate、Modal、Anyscale には、同等の非同期割引ティアはありません。
プロバイダーごとのより詳細な解説については、Fireworks AI pricing、Baseten pricing、SambaNova Cloud pricing の記事も併せてご覧ください。手短に言えば、抽象的な「最安プロバイダー」ではなく、提供しようとしている特定のモデルにおいて最安のプロバイダーを選ぶべきです。
実際のチームが支払っている金額の 3つの具体例
トークンの計算は机上の空論に過ぎません。月末の請求書こそが現実です。3つのシナリオで実際の数字を見てみましょう。
例 1 - Llama 3.3 70B で製品内チャットアシスタントを運営する SaaS チーム
トラフィック:1日 5,000 会話。1会話あたり平均 1,500 インプットトークン(システムプロンプト + 取得されたコンテキスト)と 400 アウトプットトークン。月 21営業日。
Together のサーバーレス料金(送受信 $1.04/M)での計算:
- インプット:5,000 × 1,500 × 21 = 1億 5,750万トークン × $1.04 = $163.80/月
- アウトプット:5,000 × 400 × 21 = 4,200万トークン × $1.04 = $43.68/月
- 合計:推論費用として 月額約 $207
同じチームが Groq(インプット $0.59 / アウトプット $0.79)を選んだ場合:
- 157.5M × $0.59 + 42M × $0.79 = $92.92 + $33.18 = 月額約 $126
OpenRouter(インプット $0.10 / アウトプット $0.32)の場合:
- 157.5M × $0.10 + 42M × $0.32 = $15.75 + $13.44 = 月額約 $29
結論:このボリュームでは、純粋な推論コストは小さいため、選択基準は推論レートではなく、レイテンシ、地域の信頼性、サポートの対応などになるでしょう。
例 2 - Kimi K2.6 エージェントループを大規模に実行する AI ネイティブスタートアップ
トラフィック:1日あたりインプット 2億トークン、アウトプット 5,000万トークン。インプットの約 80% がキャッシュ可能(長いシステムプロンプト + 再利用されるツール定義)。月 30日間。
キャッシュ価格を適用した Together での計算:
- インプット(キャッシュあり):200M × 0.80 × 30 × $0.20/M = $960/月
- インプット(キャッシュなし):200M × 0.20 × 30 × $1.20/M = $1,440/月
- アウトプット:50M × 30 × $4.50/M = $6,750/月
- 合計:月額約 $9,150
キャッシュ済みの割引がなければ、インプット部分だけで $7,200 かかっていたはずです。つまり、このシナリオではキャッシュというレバーによって月額約 $5,800 節約できています。ほとんどの料金比較は非キャッシュレートを引用するため、多くのチームはキャッシュ済みインプットの割引効果を過小評価しています。
例 3 - Llama 4 Scout をファインチューニングして 24時間 365日ホスティングするチーム
トレーニング:Llama 4 Scout で 5億トークンのトレーニングデータ。特殊ティアの設定により、LoRA SFT は $3.00/M(最低料金 $6)。
- トレーニング費用:500 × $3.00 = 1回限り $1,500
ホスティング:プロダクション用に H100 専用エンドポイントを常時稼働。
- $6.49/時 × 24時間 × 30日間 = 毎月 $4,672.80
初月の合計請求額:$1,500 + $4,672.80 ≈ $6,173。2ヶ月目以降の継続費用:$4,673。
トレーニング費用が目立って見えますが、実際の継続的な負担はホスティング費用です。ファインチューニングしたモデルを既存の専用キャパシティでホスティングできる場合、あるいはトラフィック的にベースモデルへのサーバーレス利用 + 精緻なプロンプトエンジニアリングで十分な場合は、$4,673 のラインを完全に消すことができます。ライフサイクルを計画しましょう。

Together の料金体系でチームが不意を突かれたポイント
G2 や Trustpilot で一貫して見られる不満は、公表されているレートではなく、請求の仕組みに関するものです。特に 3つの不満が繰り返し挙げられています。
返金されない認証費用。 複数の Trustpilot のレビュアーが、クレジットカードを登録した際に $1 の認証課金が発生したが、返金されるはずなのに戻ってこなかったと述べています:
クレジットカードを追加したとき、「認証のために直ちに $1 が課金されますが、後にクレジットとして戻されます」とはっきり書いてありました。カードを追加し、$1 課金されましたが、戻ってきませんでした。
Trustpilot レビュアー, Together AI on Trustpilot
短期間の頻繁な課金と返金の遅れ。 別の請求パターンに関する指摘:
数秒おきに変な金額でカードに請求が来ました。緊急でカードを止める必要がありました。サポートとも連絡がつきません。
Trustpilot レビュアー, Together AI on Trustpilot
2週間経っても、プリペイドアカウントの残高が返金されません。無効化された API キーのトラブルシューティングにかかった費用も返金してくれません。
G2 レビュアー, Together AI on G2
これらは中央値的なカスタマーエクスペリエンスではありません(G2 のほとんどのレビューは肯定的です)。しかし、不満の多くが「機能の不足」ではなく「請求とサポート対応」に集中していることは間違いありません。アカウントマネージャーのいない小規模チームであれば、限度額を絞った法人カードを使い、多額のクレジットを事前チャージしないようにすることをお勧めします。
ファインチューニングホスティングの驚き。 前述しましたが、繰り返す価値があります。ファインチューニングしたモデルを 維持する ためのコストは、通常の月間ボリュームにおいて、トレーニング費用の 50倍から 200倍に達することがよくあります。これに多くのチームが不意を突かれます。専用エンドポイントのメーターは、モデルがアイドル状態であっても止まりません。
エンジニアリング工数は最大の目に見えないコスト。 Together AI の料金に関する LinkedIn や X のスレッドで見られる、共通の技術的批判:
Together AI を使うのは、決して「プラグアンドプレイ」な体験ではありません。その API を統合し、アプリケーションを構築し、システムを長期的に維持するには、かなりの開発工数が必要です。これらのエンジニアリングコストはすぐに積み上がり、API 使用料自体よりもはるかに高くなることがよくあります。
LinkedIn / X での議論 で見られる、技術者の批判の要約
これは Together 特有の批判ではなく、素の API を提供する推論プラットフォームすべてに当てはまります。エンジニアの時間が無料でないなら、Together の $1.04/M の Llama 3.3 70B と Groq の $0.59/M を比較するスプレッドシートには、認証、リトライ/バックオフ、オブザーバビリティ、構造化出力の検証、プロンプトのバージョン管理、評価パイプライン、オンコール対応にかかるエンジニア週数も含めるべきです。多くのチームにとって、これらのエンジニアリング項目は推論費用を完全に上回ります。
Together AI が正しい選択である場合、そうでない場合
Together の料金が積極的に輝くケース:
- ファインチューニングされたオープンソースモデルを、予測可能で安定したプロダクション環境で動かしている。 H100 で $6.49/時の専用エンドポイントや、$3.99/時の予約クラスターは、ハイパースケーラーの GPU レンタルと同等かそれ以下であり、同等の品質を持つ商用 API よりもはるかに安価です。
- データセンターを自前で用意せずに、InfiniBand を備えた GPU クラスターが必要。 8基から 4,000基以上の GPU 規模、世界 25都市以上の拠点、そして Together Kernel Collection によるパフォーマンスの優位性は、巨大ハイパースケーラー以外とは十分に戦えます(gpu-clusters)。
- マルチモーダルな体験を構築しており、一つの API で済ませたい。 サーバーレスティアでチャット、ビジョン、画像、オーディオ、動画、書き起こし、埋め込み、モデレーションがカバーされているため、6つの異なるプロバイダーアカウントを繋ぎ合わせる必要がありません。
- 大規模な非同期 / バッチワークロードがある。 競争力のあるサーバーレスレートに加え、Batch API の 50% 割引は、大規模な要約、合成データ生成、ログエンリッチメント、分類などにおいて強力な味方になります。
Together の料金が不適切なツールであるケース:
- とにかく最安の Llama 3.3 70B エンドポイントが欲しい。 この特定のモデルに関しては、Groq のほうが速くて安いです。OpenRouter はさらに安いです。Together は旧来モデルでは中位です。
- 特定の用途(サポート、営業チャット、社内ヘルプなど)に特化した管理型 AI エージェントを求めており、推論 + リトリーバル + ツール利用 + UI + 評価を自分で組み立てたくない。 この場合は成果報酬型のプラットフォームのほうが理にかなっています。
- 予測可能で上限のある価格設定を求めている。 複数のメーターによる従量課金は予測が困難です。利用制限を設定していないと、エージェントループが暴走した際に、誰かが気づく前に多額の費用が発生する可能性があります。
- 公式サポートのレスポンスタイムについて、公開された SLA が必要。 請求に関する紛争などでサポートの対応が遅いという否定的なレビューが散見されるため、エンタープライズ契約で事前交渉しておくべき項目です。
代替手段の詳細については、Together AI alternatives roundup、Together AI review、および包括的な what is Together AI guide をご覧ください。
トークンを買うよりも成果を買いたいなら eesel をお試しください
Together AI の料金に関する記事は、ほとんどの場合、AI 製品の「原材料」であるトークン、GPU 時間、推論レイテンシ、学習トークンに関するものです。これらは、基盤モデルの企業を作ったり、カスタム推論エンジンを構築したりする場合には正しいプリミティブ(基本構成要素)です。しかし、既存のツール内で動作する AI エージェントが欲しいだけなら、これらは「間違った」プリミティブです。

eesel はその逆の形をとります。すでにお使いのヘルプデスク、チャットアプリ、受信トレイ(Zendesk、Freshdesk、Intercom、Slack、Gmail、Shopify など 100以上)で動作する、フルマネージドな AI チームメイトのタスク単位の料金設定です。サポートチケット 1件 $0.40、ダッシュボードでの質問は無料、長文ブログの生成は $4 です。推論、リトリーバル、プロンプトの改善、リトライ、評価、オブザーバビリティはすべてその価格に 含まれて います。請求書にそれらが個別に現れることはありませんし、自分で構築する必要もありません。
AI チームメイトを雇いましょう。完全に自律的で非常に有能なチームメイトが、既存のアプリの中に住み着き、数分で使い始めることができます。
前述の例 1(1日 5,000会話の SaaS チーム)で比較してみましょう。Together では、推論費用は約 $207/月ですが、これにリトリーバル、リトライロジック、出力検証、プロンプト管理、分析などを組み立てるエンジニアリング工数が 加算 されます。eesel では、5,000会話 × 21日 = 105,000タスク/月を 1件 $0.40 で行うと 月額 $42,000 になります。数字の上でははるかに高価ですが、これにはエンドツーエンドで動作する製品と解決に対する SLA が含まれています。チームの時間をインフラ構築に費やすべきか、プロダクト開発に費やすべきかによって、正しい答えは決まります。
AI サポート、AI チャット、または AI コンテンツが「コア技術」ではなく「アウトプット(成果物)」である多くのチームにとって、タスク単位のモデルは理にかなっています。eesel の $50 クレジット付き無料トライアル では、カード登録不要で実際のワークロード(ヘルプデスクエージェント、ブログライター、Eコマースエージェントなど)を試すことができます。また、月額 $300 以上の利用であれば 年間契約割引 で 25% オフになります。ユーザーごとの料金も、セルフサービスにおけるプラットフォーム利用料も、月額最低料金もありません。
もしすでに Together AI を利用しており、その提供価値に満足しているなら、そのまま使い続けるべきです。しかし、より高レイヤーな選択肢が見つからなかったために Together AI を使っているのであれば、それこそが eesel が解決するために構築されたギャップなのです。
よくある質問
2026年に Together AI を利用するといくらかかりますか?
Together AI には無料枠やスタータークレジットはありますか?
Together AI のファインチューニング料金はどのような仕組みですか?
Together AI は Fireworks AI、Groq、Replicate よりも安いですか?
Together AI で注意すべき隠れたコストはありますか?

Article by
Rama Adi Nugraha
Rama is a software engineer at eesel AI with two years of experience writing about B2B SaaS, AI tools, and customer support technology. Based in Bali, Indonesia, he brings a developer's perspective to product comparisons — cutting through marketing copy to what the integrations and APIs actually do.