AIの世界は急速に進化していますが、2026年4月16日にリリースされたClaude Opus 4.7は、根本的な方向転換を感じさせるものです。過去2年間は速度と低レイテンシを競うレースが続いてきましたが、Anthropicの最新フラッグシップモデルは異なる道を歩んでいます。必ずしも「最速」を目指して構築されたわけではなく、「最も厳密」であるために構築されたのです。
本レビューでは、Opus 4.7がなぜ「推論の飛躍」と言えるのか、なぜモデルの退化(レグレッション)に関する激しい議論を巻き起こしているのか、そして企業がどのようにしてこれまでのモデルでは対応できなかった複雑で自律的なタスクを処理しているのかを掘り下げます。
Opus 4.7の新機能
Claude Opus 4.7は、アーキテクチャを完全に刷新したものではなく、「長期的なエージェントの信頼性」に焦点を当てたアップグレードです。Opus 4.6が「正しい答えを素早く出す」ことに重点を置いていたのに対し、4.7は「回答を提示する前に、それが正しいことを証明する」ことに重点を置いています。

ソフトウェアエンジニアリングの卓越性
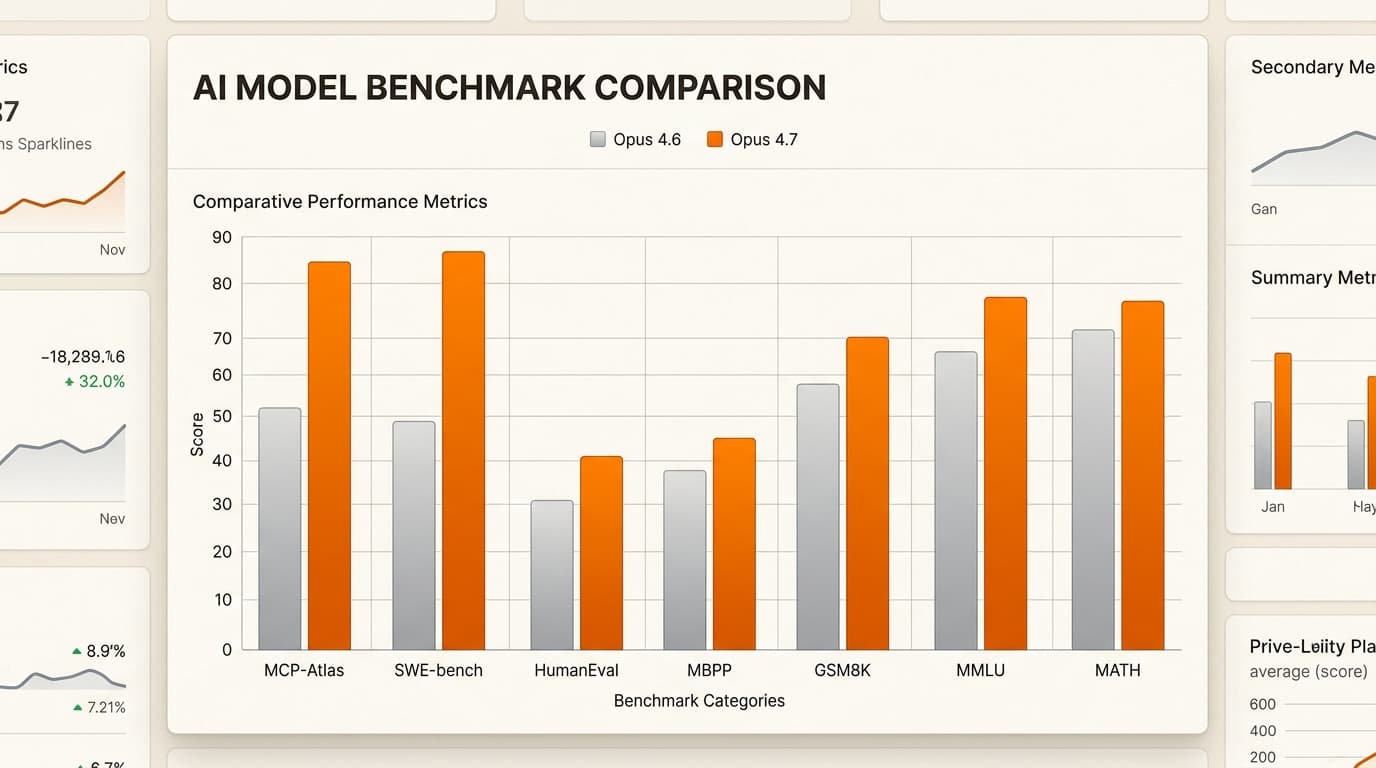
最大の改善点はコーディング能力です。Opus 4.7は、**SWE-bench Verifiedで87.6%という驚異的なスコアを達成し、Opus 4.6の80.8%から向上しました。さらに印象的なのはSWE-bench Proでのパフォーマンス(+10.9ポイント)**であり、一般的なパターンだけでなく、最も難解でユニークなソフトウェアエンジニアリングの問題に対してその能力が集中していることを示唆しています。
自己検証と厳密さ
4.7の最も「人間らしい」機能は、自身の出力を検証する能力かもしれません。実際、Opus 4.7に複雑なタスクを与えると、単に実行して報告するだけではありません。自らテストを書き、健全性チェックを実行し、自身の作業を検査します。この「報告前の検証(Verify before Report)」ループにより、長時間実行されるエージェント作業におけるエラー率が大幅に削減されます。
強化された視覚機能
Opus 4.7は、長辺2,576ピクセル(約375万画素)までの画像をサポートするようになりました。これは以前のモデルと比較して解像度が3.3倍に向上したことを意味します。企業にとってこれは、AIがこれまでぼやけていて信頼性の高い抽出が困難だった、高密度のスクリーンショット、複雑な建築図面、ピクセル単位で設計されたUI要素を「読み取れる」ようになったことを意味します。
「思考」モデル:パフォーマンスベンチマーク
Anthropicは4.7を「思考する人のためのAI」として位置づけています。単に次のトークンを予測するのではなく、ステップごとに「推論」しています。これは、全体的なベンチマークパフォーマンスに反映されています。
| ベンチマーク | Claude Opus 4.7 | Claude Opus 4.6 | 差分 |
|---|---|---|---|
| SWE-bench Verified | 87.6% | 80.8% | +6.8 |
| GPQA Diamond | 94.2% | 91.3% | +2.9 |
| MCP-Atlas (ツール) | 77.3% | 62.7% | +14.6 |
| Finance Agent (SOTA) | 64.4% | 60.7% | +3.7 |
**MCP-Atlasでの飛躍(+14.6ポイント)**は、自律型エージェントを構築している人にとって特に注目すべき点です。これは、4.7がデータベースの検索やAPIとの対話といったツール利用において、プロセスを見失うことなく、大幅に優れていることを示しています。
論争への対処:これは退化なのか?
輝かしいベンチマーク結果にもかかわらず、リリースには論争が伴いました。Redditなどのプラットフォームでは、一部のユーザーがOpus 4.7を「退化(レグレッション)」と呼んでいます。
主な不満は速度です。
Opus 4.7はより深く「思考」するため、特に新しいxhighおよびmaxの努力レベルでは、4.6よりも大幅に遅く感じられることがあります。一部のユーザーは、単純なタスクに対して「考えすぎ」であると評しています。また、非技術的な文章作成において、モデルが「創造的な魂」を失い、より文字通りで無機質になったという認識もあります。
Project Glasswingの要因
この変化の一部は意図的なものです。Opus 4.7は、Project Glasswingセーフガードスタックを組み込んだ最初の広範なリリースモデルです。Anthropicは、トレーニング中に攻撃的なサイバーセキュリティ能力を低減させる実験を明示的に行いました。これらのセーフガードは、高リスクなサイバー利用を示すリクエストを自動的に検出し、ブロックします。これにより企業にとってモデルはより安全になりますが、パワーユーザーにとっては制約のように感じられる「文字通りの厳格さ」が加わっています。
実践的なビジネスユースケース
多くの企業にとって、「退化」の議論はモデルの真の価値である「信頼性」から目を逸らさせるものです。eesel AIでは、Opus 4.7をAIチームメイトのための完璧なエンジンであると考えています。
複雑なサポートワークフロー
以下のようなカスタマーサポートのリクエストを想像してみてください。
- Stripeでユーザーのサブスクリプション状況を確認する。
- ConfluenceのWikiにある返金ポリシーと照合する。
- Zendeskでチケットを更新する。
- Slackで財務チームに通知を送る。
以前のモデルではステップを見落としたり、詳細をハルシネーション(幻覚)したりする可能性がありました。Opus 4.7の「自己検証」機能は、各ステップが前のステップと照合されることを保証します。これは、推測するボットと、理解しているAIチームメイトとの違いです。
ドキュメントとスライドの生成
向上した視覚機能と創造的なセンスにより、4.7は高品質なインターフェース、スライド、専門的なドキュメントを作成する能力も大幅に向上しています。既存のブランド資産を3.3倍の鮮明さで「認識」し、生成されたコンテンツがClaude AIプログラミングツールやデザイン基準に完璧に従っていることを保証できます。
利用開始と料金
幸いなことに、Claude Opus 4.7はAPIのドロップイン置換が可能であり、料金は変更されていません。
- 入力: 100万トークンあたり5ドル
- 出力: 100万トークンあたり25ドル
ただし、注意点があります。Opus 4.7は更新されたトークナイザーを使用しています。同じテキストでも、4.6と比較して1.0〜1.35倍多くのトークンに変換される可能性があります。つまり、トークンあたりの単価は同じでも、タスクあたりのコストはわずかに上昇する可能性があります。
4.7へのプロンプトのヒント
- 文字通りに指示する: 4.7は指示をより正確に従うため、「曖昧な雰囲気」での指示は避け、何を求めているかを明示してください。
- xhighレベルを使用する: この新しい努力レベルはhighとmaxの中間に位置し、推論とレイテンシの最適なバランスを提供します。
- タスク予算を設定する: 新しいベータ版のタスク予算機能を使用して、長時間実行される自律型ジョブのトークン消費量に上限を設けてください。
結論:速さよりも正確さを
Claude Opus 4.7は専門的なツールです。夕食のメニューについて簡単にチャットしたいだけなら、おそらく過剰(そして遅すぎる)でしょう。しかし、重要なビジネスオペレーション、ソフトウェアエンジニアリング、複雑なデータ抽出を処理するための自律型AIチームメイトを構築しているなら、これが新しいゴールドスタンダードです。
このモデルは、速さよりも正確さを、そして「雰囲気」よりも厳密さを選択しました。自律的な仕事の未来にとって、それこそがまさに必要なトレードオフなのです。
よくある質問
Share this article

Article by
Stevia Putri
Stevia Putri is a marketing generalist at eesel AI, where she helps turn powerful AI tools into stories that resonate. She’s driven by curiosity, clarity, and the human side of technology.