AIの世界は目まぐるしい速さで動いています。ようやくチームが特定のモデルを使いこなせるようになったと思ったら、Claude Opus 4.5のようなものが登場し、再びゲームのルールを変えると約束してきます。
誇大広告やベンチマークスコアに惑わされるのは簡単です。しかし、これらのアップデートはチームの日常的なワークフローにとって実際に何を意味するのでしょうか?これは単なる小さな一歩に過ぎないのでしょうか、それとも仕事の進め方を変える真の飛躍なのでしょうか?
本記事のClaude Opus 4.5レビューでは、コーディングスキル、自律型エージェント(autonomous agent)機能、制限事項、そして新しい価格体系を詳しく調べ、特にカスタマーサポートにおけるビジネスへの影響を探ります。
Claude Opus 4.5とは?
Claude Opus 4.5とは、具体的にどのようなものでしょうか?これはAnthropic社が2025年11月にリリースした、最新かつ最上位の大規模言語モデル(large language model)です。Anthropic社は、これを「コーディング、エージェント、コンピュータ使用、およびエンタープライズワークフローにおいて世界最高のモデル」と称しています。
これは単なるマイナーアップデートではありません。同社は、推論能力の向上と、混乱を招くような、あるいは不明確な情報を扱う能力を強調しています。さらに、旧バージョンよりも効率的でコストも抑えられているため、ハイエンドなAIをコスト効率よく利用したい企業にとって有益です。
GoogleのGemini 3 ProやOpenAIのGPT-5.1といった主要モデルと競合する位置づけにあります。複雑で専門的な仕事をこなすのが特に得意な、万能選手のような存在だと考えると分かりやすいでしょう。
主な機能と実力
公式情報やユーザーの声に基づき、新機能の核心と、それがユーザーにとって何を意味するのかを詳しく見ていきましょう。
コーディングと開発におけるリードモデル
Opus 4.5は開発者から大きな注目を集めています。
実際のGitHubの問題を修正する難易度の高いテストであるSWE-bench Verifiedベンチマークにおいて、80.9%というスコアを記録しました。これは特筆すべき成果であり、その高度なコーディング能力を示しています。
特筆すべきは、Anthropic社独自の過酷なエンジニアリング試験において、すべての人間応募者の成績を上回ったことです。これは、熟練の開発者のように、プレッシャーの下で困難な技術的判断を下せることを示唆しています。
その実力はコード生成にとどまりません。Claude Codeでアップデートされた「プランモード(Plan Mode)」では、モデルがユーザーの意図を明確にするために質問を投げかけ、編集可能な「plan.md」ファイルを作成してくれます。これにより、最初から正しいアウトプットを得られるようになります。
実際のエンジニアリング作業に関してはClaudeの方が優れていると思います。特に高度な機能を使用する場合、Claude CodeはGemini CLIよりも単純に優れています
自律型AIエージェントの登場
一部のAIモデルは、構造化されていない現実世界のビジネスデータを苦手としています。例えば、Nate's Newsletterによるテストでは、Opus 4.5が活字の出荷目録と、構造化されていない手書きの集計表を照合できることが示されました。これは、非構造化情報を深く理解する必要があるタスクです。
Opus 4.5は、時間をかけて物事をじっくり考える必要があるタスクでも優れたパフォーマンスを発揮します。サブエージェントのチームを統括することができ、コンテキストの圧縮(context compaction)と呼ばれる機能を使用して、複雑なワークフロー中も軌道を外れないように自己管理します。そのため、常にチェックし続ける必要がありません。これは公式発表における主要なポイントでした。
次のサイドプロジェクトのための基礎ドキュメントをすべて、これほど短時間でこれほど高品質にまとめ上げてくれました。まるで世界最高のインターンや大学院生のチームが、トップの座を競い合っているかのようです。
長期間にわたって自律的に作業できる能力により、単なるツールというよりも、プロセスの最初から最後までを任せられる信頼できるチームメンバーのように感じられます。
コストと効率の劇的な改善
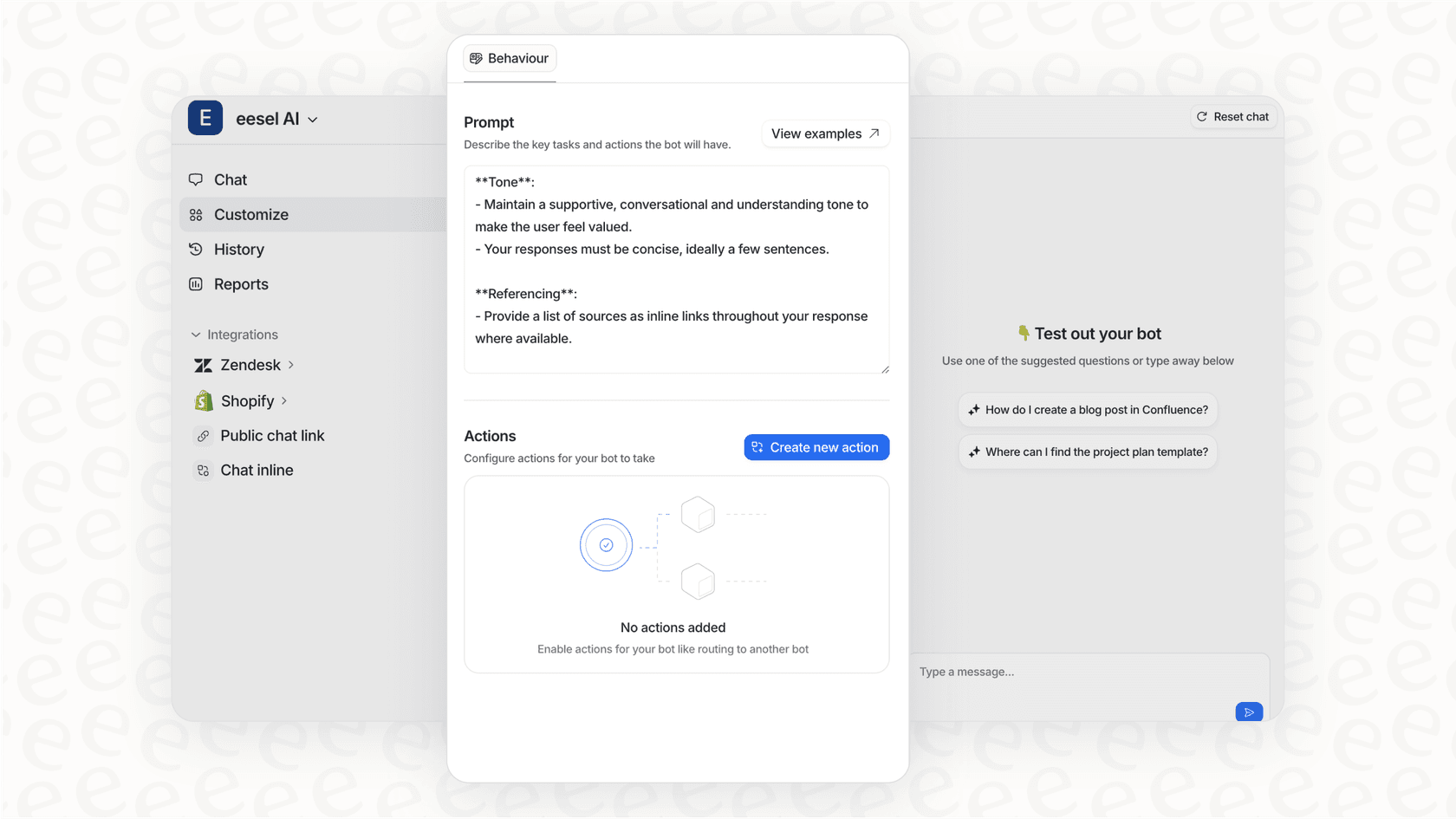
APIには現在、「努力(effort)」パラメータが搭載されています。これは注目すべき機能で、開発者が速度、コスト、パワーのバランスを調整できるようになります。タスクの難易度に応じて、低、中、高の努力設定を選択できます。
効率の違いは顕著です。中程度の努力設定において、Opus 4.5は強力なSonnet 4.5モデルと同等のパフォーマンスを発揮しながら、出力トークンを76%少なく抑えて仕事を完了させます。
このような効率性は、より多くの企業が高度なAIを活用するための扉を開きます。以前は日常的に使うには高価すぎた複雑なワークフローも、突然利用しやすくなります。
パフォーマンス分析:強みと弱み
他者からの報告に基づき、現実世界でのパフォーマンスを詳しく見てみましょう。
強み:開発者のための共同作業ツール
開発者はOpus 4.5を、ツールというよりもチームメイトとして見ているようです。Mediumのテクニカルレビューでは、コードの大きなブロックを単に書き換えるのではなく、「外科的で的を絞った変更」を行うことが指摘されています。これは、既存のコードをきめ細かく理解していることを示しています。
巨大なコンテキストウィンドウ(context window)により、コードベース全体を取り込み、公式ドキュメントに忠実に従うことができます。新しいSDKやカスタムハードウェアを扱う開発者にとって、これは大きな利点です。あるユーザーは次のように述べています。「最初にドキュメントを読んでいないモデルからのコードは、文字通り一切受け入れません。」Opus 4.5はまさにそのために設計されています。
強み:非構造化ビジネスデータの処理
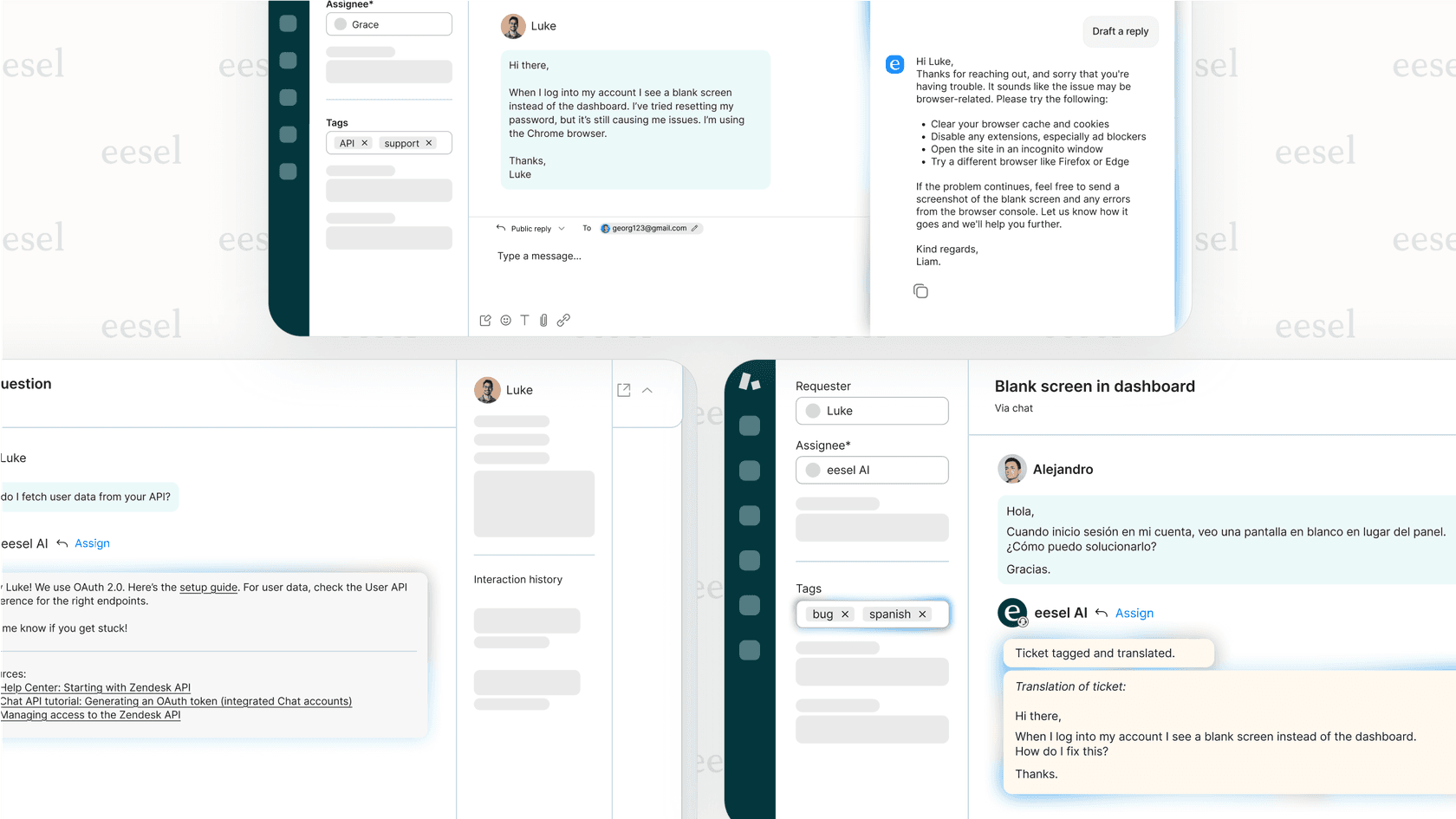
ほとんどの企業の知識は、完璧に整理されたデータベースに保存されているわけではありません。サポートチケット、社内Wiki、終わりのないSlackの会話など、あちこちに散らばっています。「クリスマスツリー・チャレンジ(Christmas tree challenge)」では、Opus 4.5がこのような乱雑な情報の整理に長けていることが示されました。
これこそが、eesel AIのようなAIチームメイトが、貴社特有のトーンやルールを把握できる理由です。手動で設定したり、複雑な構成を行ったりする必要はありません。既存のヘルプデスクのデータ、古いチケット、ナレッジベースから学習するだけです。そうすることで、ブランドの声を使いながら、すぐに問題を正しく解決し始めることができます。
強み:高レベルの安全性と信頼性
AIを利用する企業にとって、セキュリティ、特にプロンプトインジェクション攻撃(prompt injection attacks)は重大な懸念事項です。この問題を検証したテストにおいて、Opus 4.5は最も安全なモデルとして浮上しました。
Vellum.aiのテストによると、Opus 4.5においてこの種の攻撃が成功した割合はわずか**4.7%**でした。これはGemini 3 Pro(12.5%)やGPT-5.1(21.9%)よりも低い数値であり、顧客向けアプリケーションや機密情報を扱う用途において、より安全な選択肢となります。
弱み:抽象的な推論に関する賛否両論
多くの強みがある一方で、コミュニティのフィードバックは必ずしも肯定的ではありません。Reddit上の一部の開発者は、「誤検出(false positives)があまりにも多い」と報告しています。彼らは実際にはGPT-5.1 Codexのような競合他社を好み、「製品としてより洗練されており」、「より注意深く体系的なアプローチをとっている」と述べています。
Opusの問題点は、プログラミングのアプローチに確かな科学的・数学的推論が欠けていることです。
コーディングプランに従うことには長けていますが、非常に抽象的な博士号レベルの推論では効果が薄れる可能性があります。例えば、GPQA Diamondベンチマークにおいて、Opus 4.5のスコアは**82.4%でしたが、最大のライバルであるGPT-5.1 Codex Maxは89.4%**に達しました。
結論として、Opus 4.5はスペシャリストであると言えそうです。複雑なコーディングやエージェントのようなタスクを実行するには、おそらく現時点で最高のモデルですが、あらゆる種類の抽象的な問題において最高というわけではありません。
価格設定と提供状況
価格と利用方法の詳細を確認しましょう。
より身近になった価格帯
公式API価格は、入力トークン100万個あたり5ドル、出力トークン100万個あたり25ドルです。
これは、以前は入力15ドルだった旧モデルのOpus 4.1から大幅に値下げされています。この新しい価格設定により、企業は特別なプロジェクトだけでなく、日常的にこのモデルを利用できるようになります。
他のモデルとの価格比較
Claude Opus 4.5は旧バージョンよりも大幅に安くなりましたが、競合他社と比較すると依然としてプレミアムモデルとしての価格設定です。しかし、トークンの効率が非常に高いため、価格表を見るだけでは分からないほど、実際の利用コストは低くなる可能性があります。
標準的な従量課金制の価格比較は以下の通りです。
| モデル | 入力コスト(100万トークンあたり) | 出力コスト(100万トークンあたり) |
|---|---|---|
| Claude Opus 4.5 | $5.00 | $25.00 |
| Claude Sonnet 4.5 | $3.00 | $15.00 |
| OpenAI GPT-5.1 | $1.25 | $10.00 |
| Google Gemini 3 Pro | $2.00 | $12.00 |
価格データは2025年後半時点のAnthropic、OpenAI、Googleの公式ページに基づいています。
Claude Opus 4.5へのアクセス方法
このモデルは、公式Claude API、Claudeのウェブおよびデスクトップアプリ、およびAWS BedrockやGoogle Cloud Vertex AIといった主要なクラウドプラットフォームを通じて利用可能です。
個人またはチームとして利用する場合、Opus 4.5はMax、Team、およびEnterpriseプランで利用できます。ユーザーの間では、Proユーザーがどこでも利用するためには「追加利用(extra usage)」をオンにするか、より上位のプランにアップグレードする必要があるかもしれないという声も上がっています。
追加利用がオンになっているのかもしれませんね。あなたの銀行口座が無事であることを祈ります。
ビジネスへの影響
さて、これらすべては貴社のビジネスにとって何を意味するのでしょうか?
Opus 4.5のようなモデルによる最大の変化は、AIが単に情報を取ってくるだけの「アシスタント」から、自ら行動を起こす「AIチームメイト」へと進化しつつあることです。
カスタマーサポートの例で考えてみましょう。旧来のAIであれば、ヘルプ記事を見つけてリンクを送るだけかもしれません。Opus 4.5を利用したAIなら、顧客の問題を理解し、Shopifyで注文を特定し、Googleドキュメントで返品ポリシーを確認し、社内ツールを使用して返品を処理し、Zendeskでチケットをクローズすることができます。これら一連の工程をすべて一手に引き受けます。
これはeesel AI Agentが推進しているコンセプトでもあります。硬直的なルールベースのボットを構築する代わりに、実質的にAIチームメイトを「採用」するのです。既存のツールやデータから学習し、顧客の問題を自律的に解決します。そして、人間による個人的な対応が本当に必要な場合にのみ、人間の担当者に引き継ぎます。
Claude Opus 4.5が現実世界のエンジニアリングタスクをどのように処理するかを実演したデモは、以下のビデオでご覧いただけます。実践的なコーディング課題に挑む際のモデルの実力を、詳しく確認することができます。
AIチームメイトの台頭
Claude Opus 4.5は、重要な発展を象徴しています。優れたコーディングスキル、長期にわたる自動化タスクをこなす能力、そして手頃な価格設定により、新世代のAIツールの強固な基盤となっています。
何よりも、これは基本的なチャットボットから、複雑でエンドツーエンドのビジネスワークフローを任せられる、真のAIパートナーへのシフトを意味しています。
未来はチームを置き換えることではなく、有能なAIチームメイトでチームを補強することにあります。この新しいAIがどのようにカスタマーサービスチームをサポートできるか、eesel AIを無料でお試しください。
よくある質問
主な要点は、Opus 4.5が単なるツールではなく、コーディングパートナーのように機能するということです。コードベース全体を理解し、正確な変更を加え、ドキュメントに従うことに優れているため、複雑で現実的な開発タスクに非常に有用です。
完全にはそう言えません。コーディングや自律的なマルチステップ・タスクではトップクラスのパフォーマンスを発揮しますが、GPT-5.1 Codex Maxなどの一部の競合他社と比較すると、非常に抽象的な博士号レベルの推論では遅れをとる場合があります。汎用モデルというよりは、スペシャリストとしての側面が強いモデルです。
価格設定は大幅に改善されました。100万トークンあたり入力5ドル、出力25ドルとなっており、以前のOpus 4.1モデルよりも大幅に安価です。この値下げにより、企業が日常的に利用しやすくなりました。
特にカスタマーサポートにおいて「AIチームメイト」として機能する能力が強調されています。単純なチャットボットの回答を超えて、[複数のアプリを連携](https://www.mckaywrigley.com/posts/opus-4.5)(Shopify、Zendeskなど)させて返品処理を行うといった、複雑なエンドツーエンドのワークフローを処理できます。
業界をリードするセキュリティを備えていると考えられています。テストの結果、プロンプトインジェクション攻撃に対して非常に高い耐性を示し、攻撃者の成功率はわずか4.7%でした。これにより、セキュリティを優先する顧客向けアプリケーションにとって信頼できる選択肢となります。
タスクによります。Opus 4.5は、特定のコーディングベンチマーク(SWE-benchなど)やエージェント的なワークフローで優れています。しかし、[GPT-5.1 Codex Maxの方が抽象的な推論のベンチマークで高いスコアを獲得](https://www.reddit.com/r/GeminiAI/comments/1p8tx82/comparing_claude_opus_45_vs_gpt51_vs_gemini_3/)しているため、どちらのモデルが「良い」かは具体的なユースケースに依存します。
Share this article

Article by
Kenneth Pangan
10年以上のキャリアを持つライター兼マーケター。歴史、政治、アートに時間を費やしながら、愛犬たちの遊びの誘いに応じる日々を送っています。