ブログ
AIチームメイト、スマートなサポート、より良いチーム作りに関するヒント、ガイド、インサイト。


Zendesk AIエージェントレビュー(2026年):機能、料金、ユーザーの本音
2026年版Zendesk AIエージェントの実態レビュー:エージェンティックAIが何をこなせるか、AR料金モデルの仕組み、G2の6,837件のレビューとRedditコミュニティの本音。
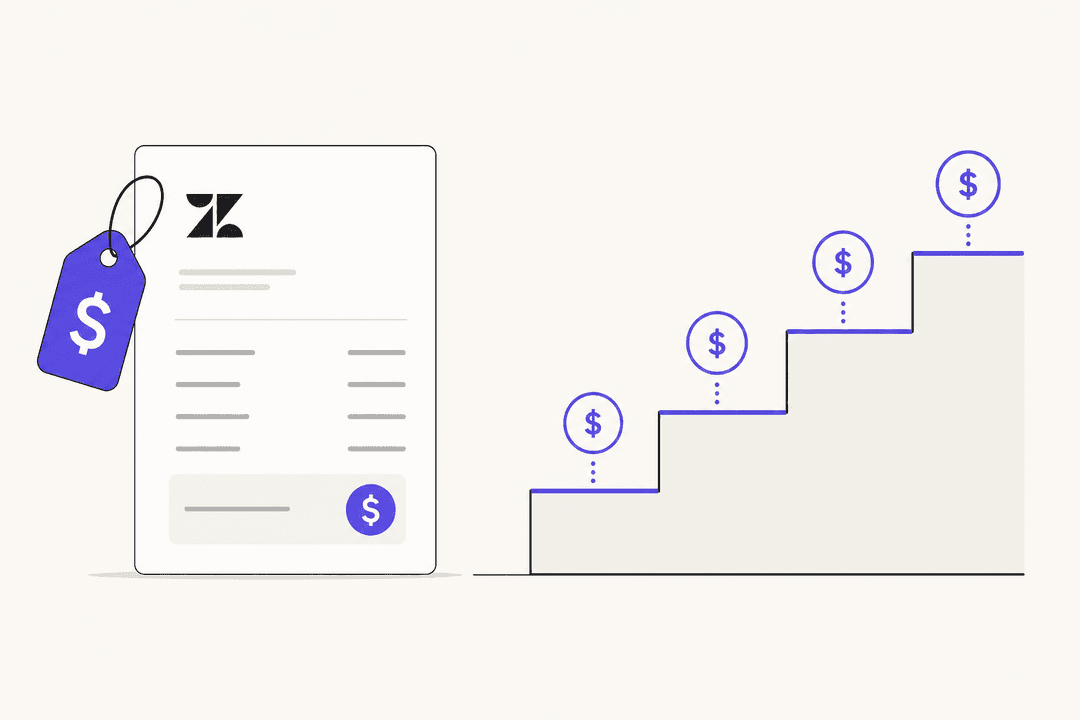
Zendeskの最低費用:2026年に実際に支払う金額
Zendeskは$19/エージェント/月からのプランを宣伝していますが、アドオン、年間契約、シート数を考慮すると、実際の運用チームのほとんどはその2〜5倍を支払っています。

CapCutの料金体系(2026年):無料、スタンダード、プロプランの完全ガイド
CapCutの最近の料金変更に混乱していませんか?ご安心ください。2026年版ガイドでは、無料、スタンダード、プロプランを詳しく解説し、機能、費用、そして実際にお支払いいただく金額を比較します。
2026年のSlack連携ヘルプデスクソフトウェアおすすめ7選
ヘルプデスクのSlack連携はツールによって大きく異なります。Slackを離れずにチケットを管理できるものもあれば、通知を送るだけのものもあります。7つのツールを比較します。
2026年のJira Service Management代替ツールトップ5
よりシンプルな設定、優れたAI、エンタープライズスケール、またはAtlassianに縛られないツールを必要とするチームのためのJira Service Management代替ツール5選。
2026年のServiceNowの最良の代替製品
ServiceNowはFortune 500規模向けに構築されています。ここでは、複雑さが少なく透明な価格設定で同じITSMを実現できる5つの代替製品を紹介します。

Freshdesk AIレビュー:2026年にFreddy AIができること(できないこと)
Freshdesk の Freddy AI に関する正直なレビュー — AI Agent、Copilot、Insights が実際に何をするのか、プランの制限がどのように影響するのか、そして誰のために作られているのかを解説します。

Freshdesk vs Jira Service Management 2026年版:あなたのチームに合うのはどちら?
FreshdeskとJira Service ManagementのITSM機能、AI、価格を実践的に比較し、カスタマーサポートチームとITサービスデスクチームのどちらに適したツールかを解説します。

Helpshift vs Zendesk:2026年にあなたに最適なサポートプラットフォームはどちら?
HelpshiftとZendeskはかつて直接競合していました。2026年、両者はまったく異なる市場にサービスを提供しています。何が変わったのか、そして正しい選択をする方法をご説明します。
AIチームメイトを採用する準備はできましたか?
数分でセットアップ。クレジットカード不要。