
Por qué conceptos te factura realmente Together AI
La mayoría de los posts sobre precios intentan encajar a Together AI en una narrativa de niveles Build / Scale / Enterprise. La página de precios simplemente no funciona así. No hay niveles con nombre. No hay tarifa por asiento. No hay un mínimo mensual en el autoservicio. Lo que hay son cuatro medidores paralelos, cada uno midiendo una unidad de consumo diferente, y cualquier carga de trabajo puede caer en uno, dos o en los cuatro, dependiendo de cómo la despliegues.
Los cuatro pilares:
- Inferencia serverless: llamas a un endpoint
/v1/chat/completionscompatible con OpenAI, obtienes una respuesta y pagas por millón de tokens de entrada y salida. La misma superficie cubre chat, visión, imagen, audio, video, transcripción, embeddings y moderación, cada uno con su propia tarifa por modelo (Precios de Together AI). - Inferencia dedicada: Together reserva para ti una instancia de GPU de un solo inquilino, la mantienes activa las 24 horas del día, los 7 días de la semana, y pagas por hora de GPU. El medidor dedicado ignora por completo el volumen de tokens; pagas por un asiento reservado, no por los viajes.
- Clústeres de GPU: alquilas el hardware de NVIDIA puro (de 8 a más de 4,000 GPUs, conectadas por InfiniBand) bajo demanda o reservado hasta por seis meses. Esto es para equipos que entrenan sus propios modelos o ejecutan sus propios motores de inferencia.
- Fine-tuning: el entrenamiento se factura por token de datos de entrenamiento, escalado por el tamaño del modelo y el método (LoRA, FT completo, DPO). Luego, el modelo resultante va a un endpoint dedicado, que tiene su propio medidor por hora.
Esto importa porque elegir el medidor correcto es donde residen los ahorros. Una startup que genera 5 millones de tokens al día en Llama 3.3 70B no tiene por qué estar en un endpoint dedicado; una carga de trabajo de producción en estado estable que genera 500 millones de tokens al día en el mismo modelo, generalmente sí. El CEO de Together AI, Vipul Ved Prakash, define la plataforma como la "Nube de Aceleración de IA" situada entre ambos (LinkedIn), y la estructura de precios lo refleja: serverless para empezar, dedicado cuando puedes predecir la carga, clústeres cuando estás entrenando.

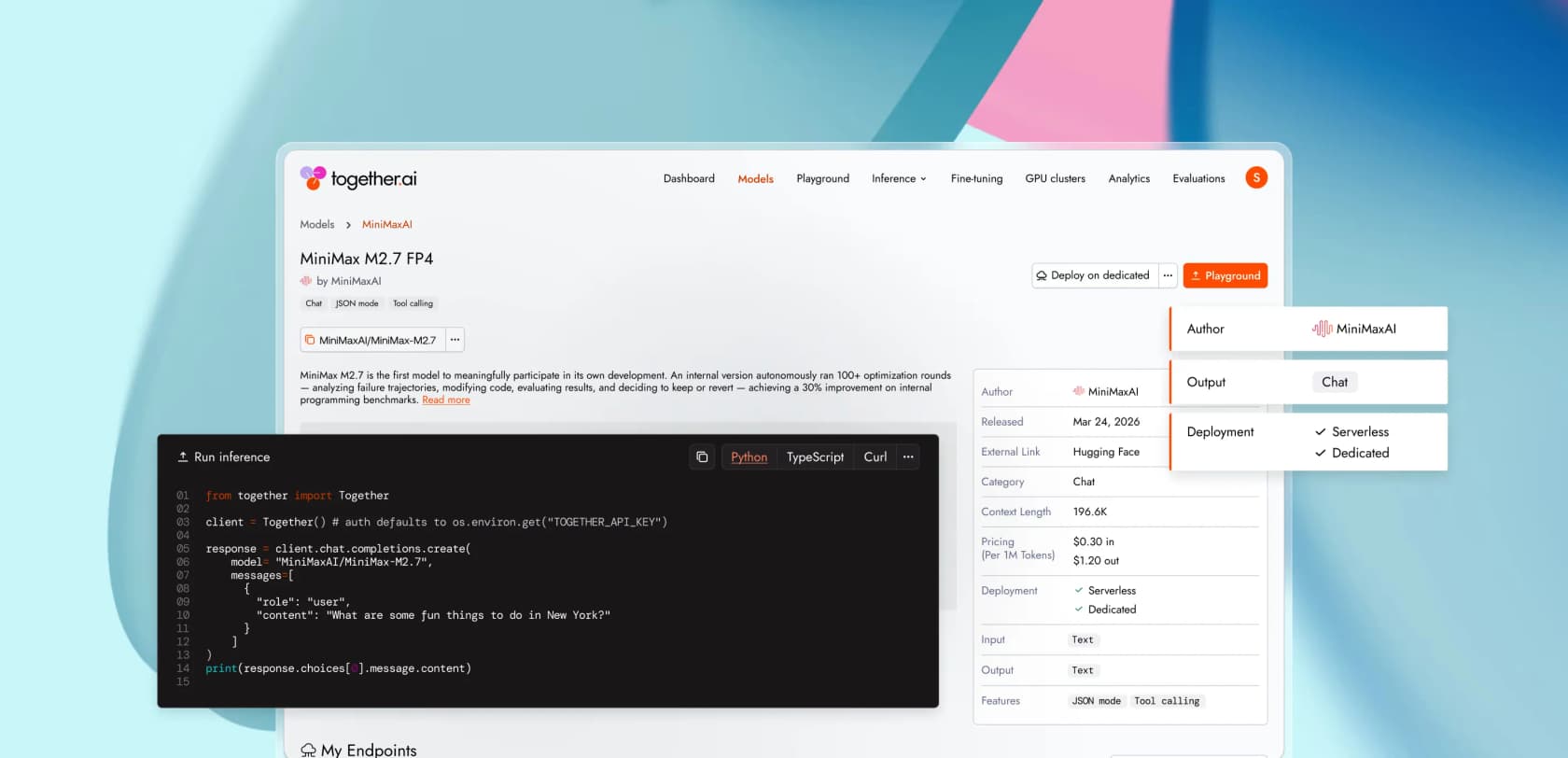
Precios de inferencia serverless
Serverless es la puerta de entrada y es el medidor en el que vivirán la mayoría de los equipos. La tabla de modelos de chat en together.ai/pricing enumera las tarifas por millón de tokens para cada modelo compatible, divididas en entrada, salida y (en algunos modelos) una tarifa de entrada en caché que es significativamente más barata que la base.
Una muestra representativa de la pestaña de chat, extraída literalmente (Precios de Together AI):
| Modelo | Entrada $/M | Salida $/M | Entrada en caché $/M |
|---|---|---|---|
| GLM-5.1 | $1.40 | $4.40 | - |
| MiniMax M2.7 | $0.30 | $1.20 | $0.06 |
| Kimi K2.6 | $1.20 | $4.50 | $0.20 |
| DeepSeek V4 Pro | $2.10 | $4.40 | $0.20 |
| DeepSeek V4 Flash | - (sin precio mostrado) | - | - |
| Qwen3.6-Plus | $0.50 | $3.00 | - |
| Qwen3.7-Max | $1.25 | $3.75 | $0.13 |
| gpt-oss-120B | $0.15 | $0.60 | - |
| gpt-oss-20B | $0.05 | $0.20 | - |
| Llama 3.3 70B | $1.04 | $1.04 | - |
| Qwen3 235B A22B FP8 Throughput | $0.20 | $0.60 | - |
| LFM2 24B A2B | $0.03 | $0.12 | - |
| Cogito v2.1 671B | $1.25 | $1.25 | - |
Tres cosas que vale la pena destacar de esa tabla.
Primero, los precios de entrada en caché son la palanca de la que nadie habla. El costo de entrada de DeepSeek V4 Pro cae de $2.10/M a $0.20/M cuando el prefijo del prompt está en caché, un descuento de 10.5x. Kimi K2.6 cae 6x. MiniMax M2.7 cae 5x. Si tu carga de trabajo reutiliza un prompt de sistema largo o tiene contextos de usuario repetidos (la mayoría de los bucles de agentes, la mayoría de los pipelines RAG), la tarifa en caché es la tarifa real. El número no almacenado en caché de la tabla es el peor de los casos.
Segundo, la ola de modelos en la que te encuentras importa más que el proveedor. gpt-oss-20B y LFM2 24B existen en la misma página de precios que DeepSeek V4 Pro y GLM-5.1. La brecha de 100x entre $0.03/M (entrada de LFM2) y $4.50/M (salida de Kimi K2.6) es mucho mayor que la brecha entre Together y sus competidores con el mismo modelo. Decir "Together es barato" no es una afirmación útil; decir "este modelo específico es barato en Together" suele serlo.
Tercero, visión, imagen, audio y video tienen medidores independientes por modelo: los modelos de imagen cobran por megapixel o por imagen (FLUX.2 [pro] cuesta $0.03/imagen; Google Imagen 4.0 Ultra cuesta $0.06/MP), los modelos de video cobran por video terminado (Sora 2 cuesta $0.80, Google Veo 3.0 con audio cuesta $3.20), y el audio se divide entre por minuto (Whisper Large v3 a $0.0015) y por 1 millón de caracteres (Cartesia Sonic-3 a $65) (Precios de Together AI). Si estás creando una aplicación multimodal, estás tocando varios medidores a la vez y tu "factura de Together" es la suma, no una tarifa única.
La puerta de entrada serverless también incluye una Batch API: procesa hasta 30 mil millones de tokens por modelo de forma asíncrona con un costo hasta un 50% menor que el serverless síncrono (Actualizaciones de Batch Inference API 2025). Para cargas de trabajo que no necesitan latencia en tiempo real (generación de datos sintéticos, clasificación fuera de línea, enriquecimiento de registros), el procesamiento por lotes (batch) es el camino legítimo más barato en la plataforma.
Together promociona el nivel serverless tanto por velocidad como por precio. En la página del producto de inferencia, las comparativas publicadas indican que es "hasta 2.75 veces más rápido" en Qwen3 235B 2507, "más de un 65% más rápido" en Kimi K2 0905 y "2 veces más rápido" en gpt-oss-20B en comparación con el siguiente proveedor más rápido en cada benchmark. Un mayor número de tokens por segundo por GPU es, en última instancia, lo que permite a Together cobrar menos y seguir obteniendo margen; es el mismo hardware, solo que realiza más trabajo por segundo.
Nuestros investigadores e ingenieros están comprometidos a acelerar la inferencia de IA para que sea tan rápida como lo permitan las leyes de la física.
Ce Zhang, CTO, vía Ryan Pollock en LinkedIn
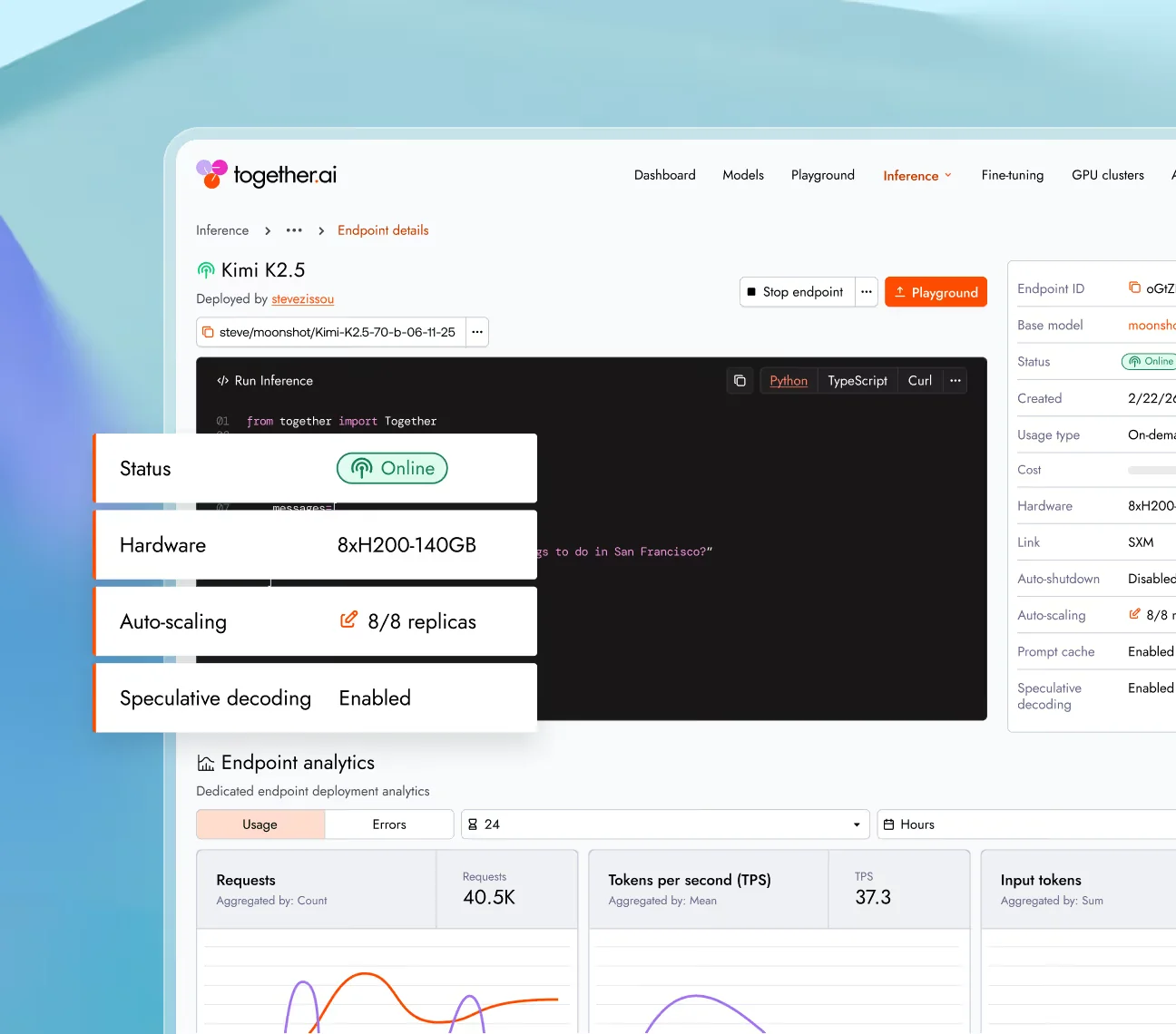
Precios de inferencia dedicada
Una vez que tu carga de trabajo supera el serverless compartido (o, más a menudo, una vez que la latencia impredecible de la infraestructura compartida se convierte en un problema del producto), los endpoints dedicados de Together AI te permiten reservar una instancia de GPU de un solo inquilino y pagar por hora (Precios de Together AI):
| Hardware | Precio por hora |
|---|---|
| 1× H100 80 GB | $6.49 |
| 1× H200 140 GB | Contactar |
| 1× HGX B200 180 GB | $11.95 |
Las matemáticas son brutales en una dirección. Una H100 encendida las 24 horas del día, 30 días al mes, cuesta $4,672.80/mes por GPU. Una B200 en el mismo periodo cuesta $8,604. El volumen de tokens es irrelevante; incluso con cero solicitudes, el medidor sigue corriendo.
También son brutales en la otra dirección, en el buen sentido. Con un volumen de solicitudes suficientemente alto, el costo efectivo por token en un endpoint dedicado cae por debajo de la tarifa serverless. El punto de equilibrio depende del modelo, pero como regla general para un modelo de clase 70B en serverless a $1.04/M de tokens en ambas vías, empiezas a ahorrar en dedicado en algún punto por encima de los ~5 mil millones de tokens al mes de tráfico constante y predecible. Por debajo de eso, serverless casi siempre gana en costo; por encima, dedicado gana y también obtienes una latencia constante.
El equipo de investigación de Salesforce es uno de los puntos de referencia publicados para este nivel:
Hemos estado profundamente impresionados con Together. Lograron una reducción de 2x en la latencia y redujeron nuestros costos en aproximadamente un tercio.
Caiming Xiong, VP, Salesforce AI Research, página de inferencia de Together AI
Si estás considerando el nivel dedicado, la pregunta que realmente debes responder no es "¿es la H100 de Together a $6.49/h más barata que X?", sino "¿tengo una carga de trabajo lo suficientemente constante como para que pagar por una GPU las 24 horas sea más barato que pagar por tokens que ocurren principalmente durante el horario comercial?". Para muchos equipos, la respuesta honesta es no.
Precios de clústeres de GPU: bajo demanda vs. reservados
Debajo de los endpoints dedicados se encuentra el nivel más puro de la infraestructura: clústeres de GPU alquilados que tú mismo operas (gpu-clusters). Aquí es donde terminan los equipos que entrenan sus propios modelos, ejecutan motores de inferencia personalizados o escalan más allá de lo que ofrecen los endpoints dedicados.
Precios de clúster bajo demanda (autoservicio, pago por uso, terminación en cualquier momento, hasta 256 GPUs) (Precios de Together AI):
| Hardware | Precio por GPU por hora |
|---|---|
| NVIDIA HGX H100 | $5.49 |
| NVIDIA HGX H200 | $6.79 |
| NVIDIA HGX B200 | $9.95 |
Precios de clúster reservados se reducen según la duración, con un compromiso máximo publicado de 180 días; cualquier periodo superior se gestiona a través de un formulario de solicitud de clúster de GPU para precios empresariales personalizados (Precios de Together AI):
| Hardware | 7-30 días | 31-90 días | 91-180 días | 181+ días |
|---|---|---|---|---|
| NVIDIA HGX H100 | $4.99 | $4.49 | $3.99 | Contactar |
| NVIDIA HGX H200 | $5.95 | $4.99 | $4.55 | Contactar |
| NVIDIA HGX B200 | $9.65 | $9.35 | $9.09 | Contactar |
| NVIDIA GB200 NVL72 | Contactar | Contactar | Contactar | Contactar |
| NVIDIA GB300 NVL72 | Contactar | Contactar | Contactar | Contactar |
Tres cosas hacen que el nivel de clúster sea interesante en comparación con el alquiler de GPU de un hiperescalador.
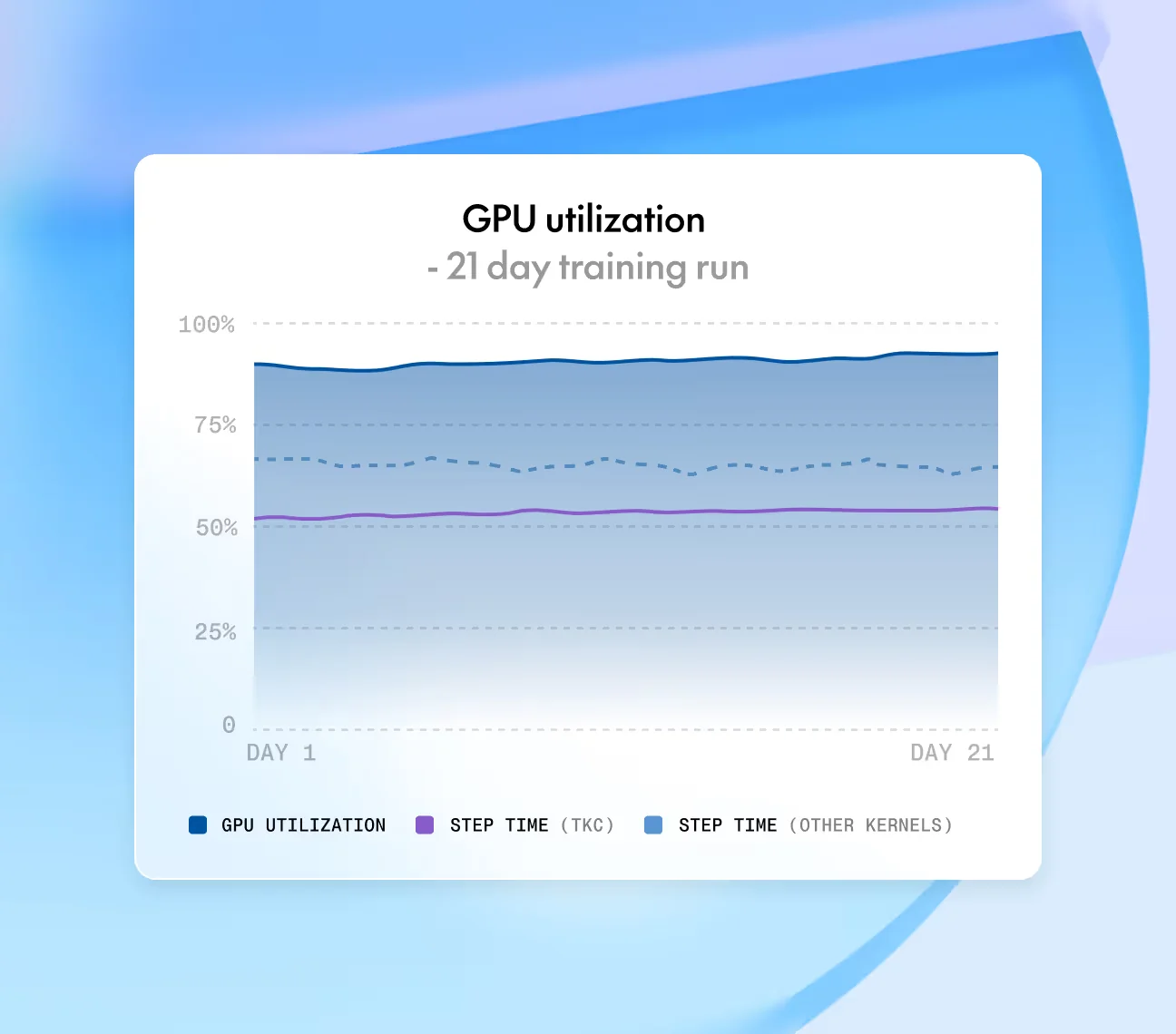
Primero, rendimiento bare-metal con interconexión InfiniBand en todo el sistema. La propuesta de Together es que "nuestra interconexión InfiniBand mantiene rápida la sincronización de gradientes y baja la sobrecarga de comunicación, para que tus ejecuciones de entrenamiento terminen más rápido, no solo sean más grandes" (Together AI gpu-clusters). Eso importa porque un entrenamiento un 30% más rápido en el mismo hardware es, en efecto, un descuento del 30% sobre la misma tarifa horaria.
Segundo, el Together Kernel Collection se incluye con el clúster. TKC (creado por el científico jefe Tri Dao, creador de FlashAttention) es la misma capa de optimización que potencia la inferencia serverless de Together, y también está disponible en los clústeres. El benchmark publicado: "Entrenar un modelo de arquitectura Llama de 70B parámetros (BF16) con un TorchTitan optimizado + Together Kernel Collection (TKC) alcanzó 15,264 tokens/segundo/GPU en NVIDIA HGX B200, frente a los 8,080 tokens/segundo en NVIDIA HGX H100: un salto del 90% en la velocidad de entrenamiento" (Together AI gpu-clusters).
Tercero, el almacenamiento no es una ocurrencia tardía. Los clústeres vienen con sistemas de archivos paralelos Weka o VAST conectados a $0.16/GiB/mes con cero tarifas de salida (egress) (Precios de Together AI). Cualquiera que haya abandonado un hiperescalador por los cargos de salida de S3 reconocerá por qué esto es importante.
Together AI proporciona el rendimiento y la fiabilidad que necesitamos para la generación de imágenes y videos de alta calidad en tiempo real a escala.
Victor Perez, Co-Fundador, Krea, Together AI gpu-clusters
Precios de fine-tuning y el costo de hosting del que nadie te advierte
El fine-tuning en Together se factura por token de datos de entrenamiento, no por época ni por hora de GPU (Documentación de fine-tuning de Together AI). La matemática es explícita en la página de precios: "El precio se basa en la suma de los tokens procesados en el conjunto de datos de entrenamiento del ajuste fino (tamaño del conjunto de datos de entrenamiento × número de épocas) más cualquier token en el conjunto de datos de evaluación opcional (tamaño del conjunto de datos de validación × número de evaluaciones)" (Precios de Together AI).
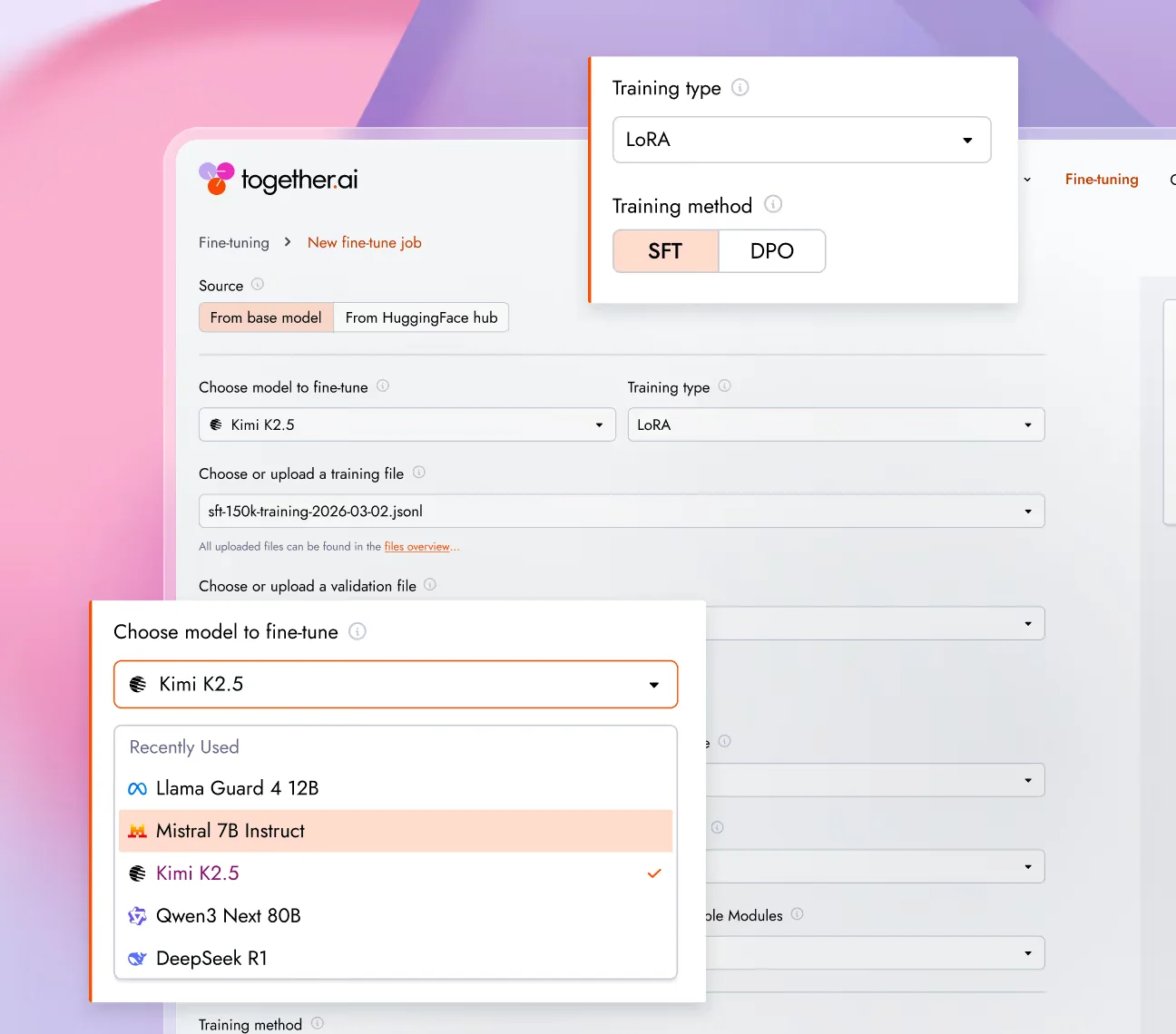
La tabla de precios estándar escala según el tamaño del modelo base y el método de ajuste (Precios de Together AI):
| Tamaño del modelo base | SFT - LoRA | SFT - Full | DPO - LoRA | DPO - Full |
|---|---|---|---|---|
| Hasta 16B | $0.48 / M | $0.54 / M | $1.20 / M | $1.35 / M |
| 17B–69B | $1.50 / M | $1.65 / M | $3.75 / M | $4.12 / M |
| 70B–100B | $2.90 / M | $3.20 / M | $7.25 / M | $8.00 / M |
Más allá de los 100 mil millones de parámetros, Together pone precio al fine-tuning por modelo en un nivel "especializado", a menudo con un cargo mínimo por trabajo (Precios de Together AI):
| Modelo | SFT (LoRA) | DPO (LoRA) | Mínimo |
|---|---|---|---|
| Familia DeepSeek-R1 / V3 / V3.1 | $10.00 / M | $25.00 / M | $20.00 |
| GLM-4.6 / 4.7 | $9.00 / M | $22.50 / M | $27.00 |
| GLM-5 / GLM-5.1 | $40.00 / M | $100.00 / M | $60.00 |
| gpt-oss-120B | $5.00 / M | $12.50 / M | $6.00 |
| Kimi K2 (Thinking / Instruct / Base) | $15.00 / M | $37.50 / M | $60.00 |
| Llama 4 Maverick / Maverick Instruct | $8.00 / M | $20.00 / M | $16.00 |
| Llama 4 Scout | $3.00 / M | $7.50 / M | $6.00 |
| Qwen3-Coder-480B-A35B-Instruct | $9.00 / M | $22.50 / M | $18.00 |
| Qwen3-235B-A22B / Instruct-2507 | $6.00 / M | $15.00 / M | Sin mín. |
| Qwen3.5-122B-A10B | $6.00 / M | $15.00 / M | $10.00 |
| Qwen3.5-397B-A17B | $8.00 / M | $20.00 / M | $22.00 |
La tabla anterior es la que la mayoría de la gente cita. El número que olvidan es que una vez que has entrenado el modelo, alojarlo es un cargo aparte y continuo.
Según la documentación: "Una vez que el entrenamiento termina, la inferencia se ejecuta en un endpoint dedicado" (Documentación de Together AI). Ese endpoint dedicado se factura a las mismas tarifas que el nivel de inferencia dedicada: $6.49/h por una H100 o $11.95/h por una B200 (Precios de Together AI). Un LoRA en una base de 16B puede entrenarse por menos de un dólar por millón de tokens de entrenamiento, pero mantener el modelo resultante activo en una sola H100 las 24 horas del día cuesta aproximadamente $4,700/mes por GPU, independientemente de si atiende una sola solicitud ese mes.
Esta es la mayor trampa de precios de la plataforma. Los equipos suelen calcular "el ajuste fino nos costará $30 por la ejecución" (lo cual es correcto) y luego descubren que la factura de hosting es dos órdenes de magnitud mayor. Planifica el ciclo de vida, no solo el paso de entrenamiento.
Otros detalles sobre el fine-tuning que son fáciles de pasar por alto:
- No hay un nivel gratuito anunciado. Cada ejecución de entrenamiento factura por token desde el primer token.
- LoRA es la opción predeterminada, el fine-tuning completo es opcional. Las diferencias en la página de precios entre LoRA y Full son pequeñas (alrededor de $0.30/M en el nivel 70B), por lo que la elección suele ser por calidad, no por costo.
- DPO cuesta aproximadamente 2.5x que SFT en todos los niveles de tamaño. Si estás alineando un modelo a preferencias, ajusta tu presupuesto en consecuencia.
- BYOM (trae tu propio modelo) te permite cargar una base fuera del catálogo. El precio del entrenamiento BYOM se incluye en el bloque de tamaño estándar correspondiente; el hosting tiene las mismas tarifas dedicadas.
Sandbox, intérprete de código y almacenamiento gestionado
Vale la pena señalar otros dos medidores más pequeños porque sorprenden a muchos creadores de agentes.
Code Sandbox te permite lanzar sandboxes de VM aisladas para que los agentes de IA ejecuten código. Se factura por vCPU virtual y por GiB de memoria, por hora (Precios de Together AI):
| Recurso | Precio por hora |
|---|---|
| Por vCPU | $0.0446 |
| Por GiB RAM | $0.0149 |
Un sandbox modesto de 4 vCPU y 8 GiB mantenido activo durante una jornada laboral (8 horas) cuesta unos $2.39; es poco individualmente, pero para una flota de agentes que lanza docenas de estos en paralelo, los totales pueden acumularse rápidamente.
Code Interpreter es el primo ligero: un sandbox de una sola sesión para ejecutar código generado por LLM sin sobrecarga de grupo activo (warm-pool), con un precio de $0.03 por sesión de 60 minutos (Precios de Together AI). Es la opción predeterminada sensata para la mayoría de los flujos de uso de herramientas de agentes.
Managed Storage es el sistema de archivos paralelo que acompaña a los clústeres. Cuesta $0.16 por GiB al mes con cero tarifas de salida (Precios de Together AI). Un conjunto de trabajo de 10 TB cuesta unos $1,638/mes, comparable a un sistema de archivos de alto rendimiento de un hiperescalador, pero sin la factura de ancho de banda al salir.
Qué es gratis y qué no
Esta parte es corta, porque no hay mucho.
- No hay un nivel gratuito anunciado en la página de precios pública. La página no muestra un monto de crédito por registro, un periodo de prueba gratuito ni una asignación mensual de tareas gratuitas.
- La Batch API es el único mecanismo de descuento en línea: hasta un 50% de descuento en la mayoría de los modelos de chat para cargas de trabajo asíncronas (Actualizaciones de Batch Inference API 2025).
- Existen descuentos por volumen / uso comprometido pero no están publicados; la página te redirige a Contactar ventas para precios empresariales.
- La entrada en caché es lo más parecido a un regalo: descuento de 5-10x en tokens de entrada para modelos de chat seleccionados cuando se reutilizan los prefijos.
Históricamente, los profesionales han mencionado un crédito inicial:
Un crédito gratuito de $25 rinde mucho cuando incluso los modelos más caros cuestan $0.9/millón de tokens.
Chris Samiullah, ingeniero de ML, LinkedIn
Ese número no está publicado actualmente en la página de precios como una política fija. Si estás planeando un presupuesto, trata el crédito como algo que debes consultar con tu gerente de cuenta en lugar de algo garantizado.
Cómo se comparan los precios de Together AI con Fireworks, Groq, Replicate y los demás
La respuesta honesta es que "si Together es el más barato" depende totalmente del modelo que estés ejecutando, el rendimiento que necesites y si estás en serverless o dedicado. Aquí tienes una comparativa para los modelos compartidos más comunes, con tarifas extraídas de la página de precios en vivo de cada proveedor al 05-06-2026:
| Proveedor | Llama 3.3 70B $/M ent / sal | DeepSeek R1 $/M ent / sal | Mixtral 8x22B $/M ent / sal | Créditos gratuitos | Modelo de precios |
|---|---|---|---|---|---|
| Together AI | $1.04 / $1.04 | DeepSeek V4 Pro: $2.10 / $4.40 (caché $0.20 ent) | No está en la lista actual | Ninguno anunciado; Batch 50% desc. | Serverless por token, dedicado por hora de GPU |
| Fireworks AI | $0.90 / $0.90 (bloque >16B) | DeepSeek V4 Pro: $1.74 / $3.48 | $1.20 / $1.20 (MoE 56-176B) | $1 de crédito gratuito | Serverless por token, bajo demanda por segundo de GPU |
| Groq | $0.59 / $0.79 | No está en la lista | No está en la lista | Registro gratuito en consola | Serverless por token |
| Replicate | Por segundo de hardware | $3.75 / $10.00 | Por segundo de hardware | Ninguno anunciado | Por segundo de hardware + por token para selección propia |
| Anyscale | Despliegue propio en H100 a $9.29/h | Igual | Igual | Crédito de $100 | Por hora de GPU (Anyscale Compute Units) |
| Modal | Auto-despliegue en H100 equiv. ~$3.95/h | Igual | Igual | $30/mes Starter, $100/mes Team | Por segundo de cómputo |
| Hugging Face | Proveedores de inferencia externos | Externos | Externos | PRO $9/mes + ZeroGPU gratis | Endpoints por hora + tokens externos |
| OpenRouter | $0.10 / $0.32 | $0.50 / $2.15 (R1 0528) | $2.00 / $6.00 | Variantes gratuitas limitadas | Marketplace por token |
Se observan algunos patrones en esa tabla.
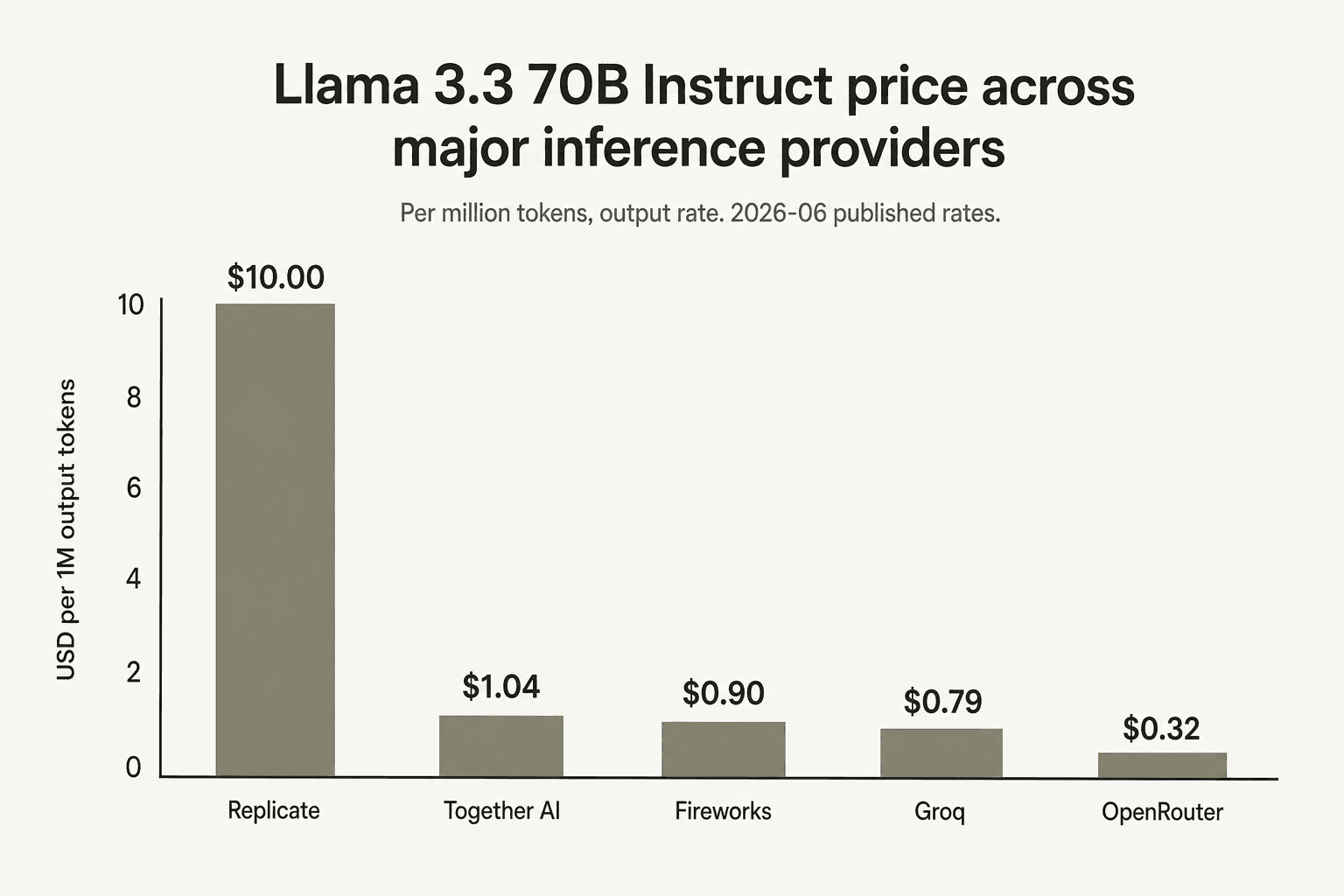
En Llama 3.3 70B específicamente, Together AI está en el medio. Groq es el proveedor directo más barato para este popular modelo heredado ($0.59/$0.79), Fireworks es el siguiente ($0.90 fijo), Together es el tercero ($1.04/$1.04), Replicate no lo lista por token en absoluto, y OpenRouter, que es un marketplace que redirige al proveedor subyacente más barato, supera a todos con $0.10/$0.32. Si tu carga de trabajo consiste en "mucha inferencia de Llama 3.3 70B", vale la pena considerar seriamente a Groq y al marketplace de OpenRouter.
En los modelos de la nueva ola (Kimi K2.6, GLM-5.1, DeepSeek V4, Qwen3.6-Plus), Together es competitivo pero no siempre el más barato. Fireworks suele listar sus nuevos Kimi y DeepSeek individualmente con tarifas de entrada en caché que igualan o superan a las de Together. La diferencia suele estar entre el 10% y el 30%, no la brecha de 5-10x que a veces se menciona en los textos de marketing.
Para el hosting de GPU dedicado, el panorama es más amplio. Modal supera a casi todos en cómputo por segundo (H100 ≈ equivalente a $3.95/h a $0.001097/seg). Hugging Face Endpoints publica $4.50/h por una H100. Together está a $6.49/h para inferencia dedicada, $5.49/h para un clúster bajo demanda y $3.99/h para un clúster reservado de 91 a 180 días. Productos diferentes, facturas diferentes; y tu costo real depende de si puedes absorber la complejidad operativa de ejecutar tu propio despliegue de vLLM en Modal frente a dejar que Together aloje un modelo por ti.
Para los embeddings, Together se encuentra entre los más baratos con $0.02/M de tokens (Multilingual e5 large instruct) (Precios de Together AI). La cuenta corporativa de Together ha anunciado históricamente un "costo hasta 4 veces menor que OpenAI" en embeddings (@togethercompute en X), y las tarifas actuales están en ese rango.
Para cargas de trabajo por lotes, el descuento del 50% de la Batch API de Together es la palanca principal. Fireworks iguala el descuento del 50%; Groq también. Replicate, Modal y Anyscale no tienen un nivel de descuento asíncrono comparable.
Para análisis más profundos de cada proveedor, nuestros desgloses de precios de Fireworks AI, precios de Baseten y precios de SambaNova Cloud complementan este artículo. La versión corta: elige el proveedor más barato para el modelo específico que estés lanzando, no el proveedor más barato en abstracto.
Tres ejemplos prácticos de lo que pagan los equipos reales
Las matemáticas de los tokens son baratas; la factura al final del mes es lo que importa. Aquí tienes tres escenarios con cifras reales.
Ejemplo 1 - Un equipo de SaaS con un asistente de chat integrado en el producto basado en Llama 3.3 70B
Tráfico: 5,000 conversaciones/día, con un promedio de 1,500 tokens de entrada (prompt de sistema + contexto recuperado) y 400 tokens de salida por conversación. Unos 21 días laborables al mes.
Cálculo serverless con $1.04/M entrada + $1.04/M salida de Together:
- Entrada: 5,000 × 1,500 × 21 = 157.5M tokens × $1.04 = $163.80/mes
- Salida: 5,000 × 400 × 21 = 42M tokens × $1.04 = $43.68/mes
- Total: ~$207/mes en la línea de inferencia
Si el mismo equipo elige Groq a $0.59 entrada / $0.79 salida:
- 157.5M × $0.59 + 42M × $0.79 = $92.92 + $33.18 = ~$126/mes
Si optan por OpenRouter a $0.10 entrada / $0.32 salida:
- 157.5M × $0.10 + 42M × $0.32 = $15.75 + $13.44 = ~$29/mes
Conclusión: a este volumen, el costo puro de la inferencia es lo suficientemente bajo como para que la elección probablemente dependa de la latencia, la fiabilidad regional y la capacidad de respuesta del soporte, no de la tarifa de inferencia.
Ejemplo 2 - Una startup nativa de IA con un bucle de agentes Kimi K2.6 a gran escala
Tráfico: 200M tokens de entrada/día, 50M tokens de salida/día, con aproximadamente un 80% de entrada almacenable en caché (prompt de sistema largo + definiciones de herramientas reutilizadas). 30 días al mes.
Cálculo de Together con precios de caché aplicados:
- Entrada (en caché): 200M × 0.80 × 30 × $0.20/M = $960/mes
- Entrada (no en caché): 200M × 0.20 × 30 × $1.20/M = $1,440/mes
- Salida: 50M × 30 × $4.50/M = $6,750/mes
- Total: ~$9,150/mes
Sin el descuento por entrada en caché, la parte de entrada por sí sola sería de $7,200, por lo que la palanca de caché supone un ahorro de aproximadamente $5,800/mes en este escenario. La mayoría de los equipos subestiman lo grande que es el descuento por entrada en caché, porque la mayoría de las comparativas de precios citan la tarifa no almacenada en caché.
Ejemplo 3 - Un equipo que ajusta Llama 4 Scout y lo aloja 24/7
Entrenamiento: 500M tokens de datos de entrenamiento en Llama 4 Scout. Del nivel especializado, eso es $3.00/M LoRA SFT con un mínimo de $6.
- Costo de entrenamiento: 500 × $3.00 = $1,500 pago único
Hosting: 1× endpoint dedicado H100 mantenido activo para producción.
- $6.49/h × 24 h × 30 días = $4,672.80/mes, cada mes
Factura total del primer mes: $1,500 + $4,672.80 ≈ $6,173. Estado estable a partir del segundo mes: $4,673.
El costo del entrenamiento parece ser el titular. El costo del hosting es la factura recurrente real. Si puedes alojar el modelo ajustado en una capacidad dedicada existente, o si tu tráfico justifica serverless en el modelo base + ingeniería de prompts dirigida en lugar de un fine-tune completo, puedes eliminar la línea de $4,673 por completo. Planifica el ciclo de vida.

Dónde los precios de Together han tomado por sorpresa a los equipos
El hilo más constante en las reseñas negativas en G2 y Trustpilot no trata sobre las tarifas principales, sino sobre la mecánica de facturación. Tres quejas específicas surgen repetidamente.
Cargos de autorización no reembolsados. Varios revisores de Trustpilot describen cómo agregaron una tarjeta de crédito, recibieron un cargo de autorización de $1 que se suponía que debía revertirse, y luego no recuperaron el dólar:
Al añadir una tarjeta de crédito decía explícitamente: "Se realizará un cargo inmediato de $1 para la autorización, que se te devolverá". Añadí mi tarjeta, me cobraron el dólar, pero nunca me lo devolvieron.
Revisor de Trustpilot, Together AI en Trustpilot
Cargos en intervalos rápidos y seguimiento deficiente de reembolsos. Otro hilo sobre patrones de facturación:
Estaban cobrando a la tarjeta de crédito en intervalos de segundos con importes extraños; tuve que bloquear la tarjeta de emergencia. Soporte inalcanzable.
Revisor de Trustpilot, Together AI en Trustpilot
Después de 2 semanas todavía no han reembolsado el saldo restante de mi cuenta prepago, ni reembolsarían el importe por solucionar problemas de la clave API desactivada.
Revisor de G2, Together AI en G2
Estos casos no son típicos de la experiencia media del cliente (la mayoría de los revisores en G2 son positivos), pero son lo suficientemente constantes como para que el grupo negativo se centre claramente en la facturación y la respuesta del soporte, no en carencias de funciones. Si eres un equipo pequeño sin un gerente de cuenta, configura una tarjeta corporativa aparte con un límite estricto y no cargues grandes saldos de crédito por adelantado.
Sorpresa por el hosting de fine-tuning. Cubierto anteriormente, pero vale la pena repetirlo: el costo de mantener vivo un modelo ajustado suele ser de 50 a 200 veces el costo de entrenarlo para cualquier volumen mensual razonable. Esto pilla a muchos equipos desprevenidos. El medidor del endpoint dedicado no se detiene cuando el modelo está inactivo.
El tiempo de ingeniería es el mayor costo invisible. Extraído de una crítica recurrente de profesionales surgida en hilos de LinkedIn y X sobre los precios de Together AI:
Usar Together AI no es exactamente una experiencia plug-and-play. Se necesita una buena cantidad de tiempo de desarrollo para integrar su API, construir una aplicación a su alrededor y luego mantener ese sistema a lo largo del tiempo. Estos costos de ingeniería pueden acumularse rápido y a menudo terminan siendo mucho más altos que el uso de la API en sí.
Crítica recurrente de profesionales surgida vía discusiones en LinkedIn / X sobre los precios de Together AI
Esto no es una crítica específica a Together; se aplica a todas las plataformas de inferencia de API pura. Si el tiempo de tu equipo de ingeniería no es gratis, la hoja de cálculo que compara el Llama 3.3 70B de Together a $1.04/M frente al Llama 3.3 70B de Groq a $0.59/M también debería incluir las semanas de ingeniería necesarias para gestionar la autenticación, los reintentos/esperas, la observabilidad, la validación de salida estructurada, el versionado de prompts, los pipelines de evaluación y las guardias técnicas. Para muchos equipos, esas partidas de ingeniería eclipsan por completo la partida de inferencia.
Cuándo Together AI es la opción correcta y cuándo no
Donde los precios de Together realmente brillan:
- Ejecutas modelos de código abierto ajustados con un tráfico de producción constante y predecible. Los endpoints dedicados a $6.49/h o los clústeres reservados a $3.99/h por H100 son competitivos con los alquileres de GPU de hiperescaladores y una fracción del precio de las API propietarias de vanguardia en bandas de calidad equivalentes.
- Necesitas clústeres de GPU con InfiniBand sin montar tu propio centro de datos. El rango de 8 a más de 4,000 GPUs de Together y su presencia en más de 25 ciudades, además de la ventaja de rendimiento de Together Kernel Collection, son genuinamente competitivos con cualquier opción fuera de los hiperescaladores más grandes (gpu-clusters).
- Estás creando experiencias multimodales y quieres una sola API. El nivel serverless cubre chat, visión, imagen, audio, video, transcripción, embeddings y moderación, para que no tengas que enlazar seis cuentas de proveedores distintos.
- Ejecutas grandes cargas de trabajo asíncronas / por lotes. El descuento del 50% de la Batch API sobre unas tarifas serverless ya competitivas es difícil de superar para el resumen fuera de línea, la generación de datos sintéticos, el enriquecimiento de registros y la clasificación a escala.
Donde los precios de Together son la herramienta equivocada:
- Solo necesitas el endpoint de Llama 3.3 70B más barato que el dinero pueda comprar. Groq es más rápido y más barato para ese modelo específico. OpenRouter es aún más barato. Together está en el punto medio para modelos heredados.
- Eres un equipo pequeño que quiere un agente de IA gestionado para una superficie específica (tickets de soporte, chat de ventas, ayuda interna) y no quieres ensamblar inferencia + recuperación + uso de herramientas + UI + evaluación por tu cuenta. Aquí es donde una plataforma por resultado tiene más sentido; más sobre esto a continuación.
- Quieres precios predecibles y limitados. El pago por uso en múltiples medidores es difícil de pronosticar por adelantado. Sin un límite de gasto, un bucle de agentes descontrolado puede costar mucho dinero antes de que alguien se dé cuenta.
- Necesitas un SLA publicado sobre el tiempo de respuesta del soporte de primer nivel. Varias reseñas negativas señalan la falta de respuesta del soporte en disputas de facturación, algo que conviene negociar de antemano en un contrato empresarial.
Para desgloses más detallados de alternativas, consulta nuestro resumen de alternativas a Together AI, la reseña de Together AI y la guía más amplia sobre qué es Together AI.
Prueba eesel cuando prefieras comprar resultados en lugar de tokens
Un post de precios sobre Together AI es casi siempre un post sobre las materias primas de un producto de IA: tokens, horas de GPU, latencia de inferencia, tokens de entrenamiento de ajuste fino. Esas son las primitivas correctas si estás construyendo una empresa de modelos fundacionales o un motor de inferencia personalizado. Son las primitivas equivocadas si lo que realmente quieres es un agente de IA funcional dentro de tus herramientas actuales.

eesel toma la forma opuesta: precios por tarea para un compañero de equipo de IA totalmente gestionado que se ejecuta dentro de los helpdesks, aplicaciones de chat y bandejas de entrada que ya usas (Zendesk, Freshdesk, integración con Intercom, Slack, Gmail, Shopify y más de 100 otros). Un ticket de soporte cuesta $0.40. Una pregunta en el panel de control es gratis. La generación de un blog de formato largo cuesta $4. La inferencia, la recuperación, la iteración de prompts, los reintentos, la evaluación y la observabilidad están todos dentro de ese número; no los ves en la factura y no tienes que construirlos tú mismo.
Contrata compañeros de equipo de IA. Compañeros totalmente autónomos e increíblemente capaces, que viven en tus aplicaciones actuales y están listos para funcionar en minutos.
Una comparativa práctica para el equipo SaaS del Ejemplo 1 mencionado antes: 5,000 conversaciones/día, asistente de chat en el producto. En Together, la línea de inferencia es de aproximadamente $207/mes más el tiempo de ingeniería para ensamblar la recuperación, la lógica de reintentos, la validación de salida, el versionado de prompts y la analítica. En eesel, esas mismas 5,000 conversaciones × 21 días = 105,000 tareas/mes a $0.40 cada una = $42,000/mes por el mismo resultado. Es mucho más caro sobre el papel, pero incluye un producto funcional de extremo a extremo y un SLA sobre resoluciones. La respuesta correcta depende de si el tiempo de tu equipo se emplea mejor construyendo infraestructura o construyendo el producto.
Para la mayoría de los equipos donde el soporte de IA, el chat de IA o el contenido de IA es el resultado y no la tecnología principal, el modelo por tarea gana. La prueba gratuita de $50 de crédito de eesel te permite probar una carga de trabajo real (un agente de helpdesk, un escritor de blogs, un agente de comercio electrónico) sin necesidad de tarjeta, y el descuento por compromiso anual es del 25% si superas los $300/mes de gasto. Sin cuota por asiento, sin cuota de plataforma en autoservicio, sin mínimo mensual.
Si ya estás en Together AI y estás contento con lo que te ofrece, deberías quedarte ahí. Si estás en Together AI porque no pudiste encontrar una alternativa de nivel superior, ese es exactamente el hueco para el que se construyó eesel.
Preguntas frecuentes
¿Cuánto cuesta usar Together AI en 2026?
¿Tiene Together AI un nivel gratuito o crédito inicial?
¿Cómo funcionan los precios de fine-tuning de Together AI?
¿Es Together AI más barato que Fireworks AI, Groq o Replicate?
¿Qué costos ocultos debo tener en cuenta en Together AI?

Article by
Rama Adi Nugraha
Rama is a software engineer at eesel AI with two years of experience writing about B2B SaaS, AI tools, and customer support technology. Based in Bali, Indonesia, he brings a developer's perspective to product comparisons — cutting through marketing copy to what the integrations and APIs actually do.






