If you ask most IT teams what their service desk does, you'll get some version of "we handle tickets." That's accurate but incomplete - the way "I keep the car running" describes Formula 1 engineering. IT Service Management, done well, is the structured approach to designing, delivering, and continuously improving the technology services an organization depends on. Not reacting to what breaks, but building systems that fail less and recover faster when they do.
Most teams are stuck on the reactive side. Only 13% of end users say they're happy with how their IT support team works, and 90% of IT service agents expect their work to get harder over the next three years. The gap between "handling tickets" and running a high-functioning IT service operation is exactly where this guide lives.
What ITSM is (and isn't)
IT Service Management (ITSM) is the set of policies, processes, and tools IT teams use to design, deliver, manage, and improve IT services throughout their lifecycle. The core concept is treating IT as a service - aligning what IT delivers with what the business actually needs, not just keeping infrastructure running.
ITSM is not the same as running a helpdesk. A helpdesk handles break/fix issues reactively. ITSM encompasses helpdesk functions but adds proactive service management, knowledge sharing, self-service infrastructure, SLA governance, and structured continual improvement. Atlassian defines the service desk as "the single point of contact between the service provider and the users" - broader than a ticketing queue, responsible for the full lifecycle of each service.
ITSM vs ITIL
These two terms get used interchangeably, and they shouldn't be. ITSM is the discipline - the "what" of managing IT as a service. ITIL (Information Technology Infrastructure Library) is the most widely adopted framework for implementing it - the "how." Think of ITSM as the goal and ITIL as one well-established playbook for getting there.
ITIL 4, released in 2019, is the current standard. It introduced the Service Value System, which replaced the process-heavy model of earlier versions with a more holistic framework built around value creation. Its seven guiding principles - focus on value, start where you are, progress iteratively, collaborate, think holistically, keep it simple, and optimize and automate - are genuinely useful as decision-making tools, not just certification content.
Other frameworks exist: COBIT handles IT governance, ISO/IEC 20000 is the international certification standard, and DevOps principles address the development-operations interface. ITIL 4 is what most IT teams reference when they talk about doing ITSM properly.
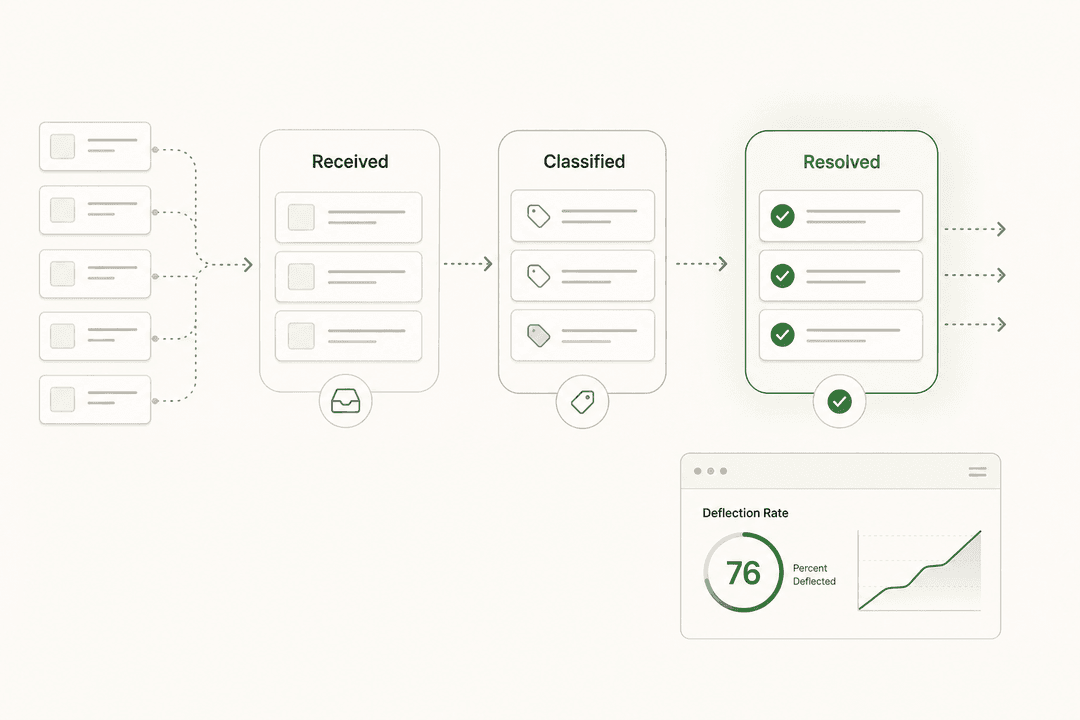
The 5 core ITSM processes
Modern ITSM work flows through five key practices. They're not independent - incident data feeds problem analysis, problem analysis drives change decisions, and knowledge management makes everything else run faster. Understanding how they connect is the foundation for everything else.
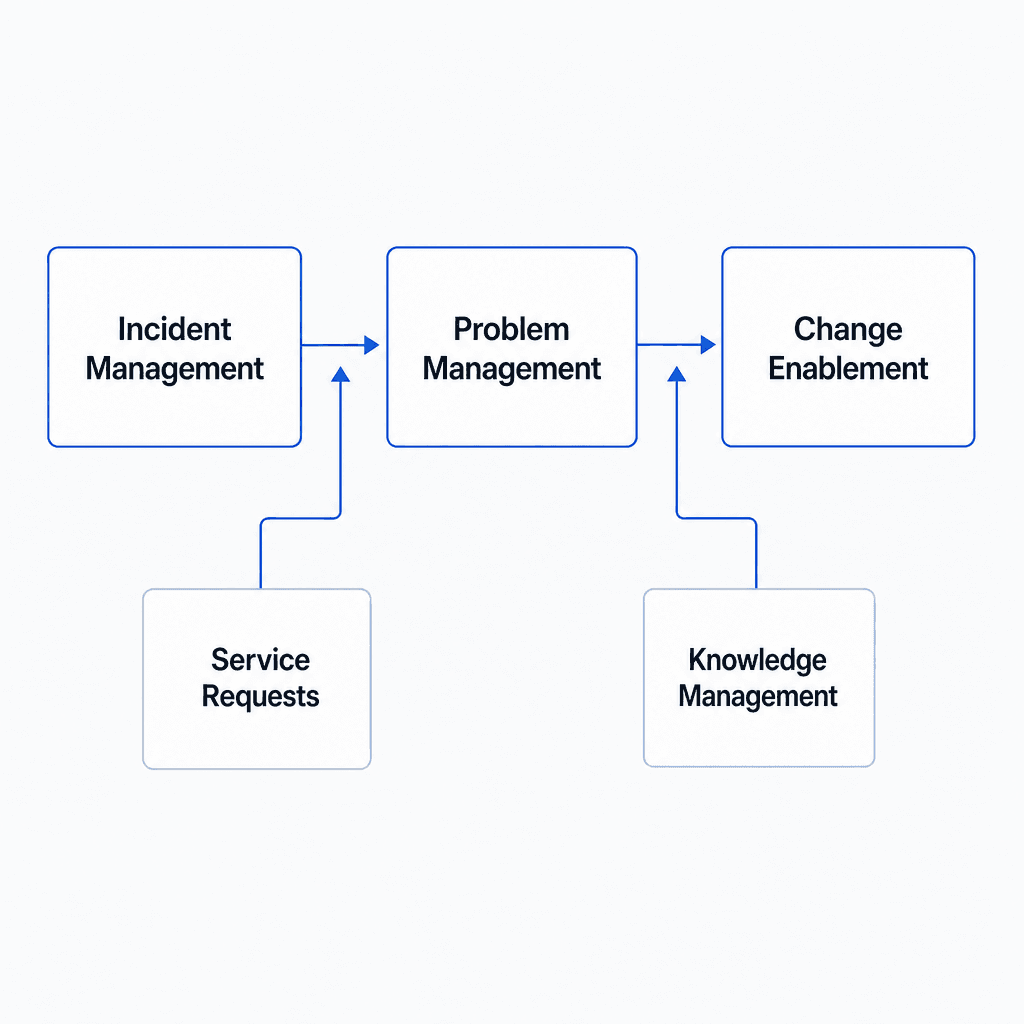
Each practice covers a distinct part of the service lifecycle.
Incident management
Incident management is the process of responding to unplanned service disruptions and restoring normal operation as quickly as possible. An incident is any unplanned interruption - a system outage, a failed authentication service, an application error affecting users. The goal is speed of recovery, not finding the underlying cause.
incident.io's 2026 incident management guide identifies the bottleneck clearly: detection is rarely the problem (monitoring flags issues fast); assembling the right people with the right context instantly is where time gets lost. The typical manual process - alert fires, on-call engineer checks dashboards, creates a Slack channel, opens a document, files a Jira ticket, updates a status page - burns roughly 12 minutes of coordination overhead before anyone starts working the problem.
Problem management
Problem management identifies the underlying causes of incidents - not the immediate fix, but the reason the incident happened. Where incident management asks "how do we restore service fast?", problem management asks "why did this happen and how do we stop it recurring?"
The Known Error Database (KEDB) is central here: a documented record of known issues, their root causes, and approved workarounds. A good KEDB turns tribal knowledge into searchable institutional memory that survives staff turnover and supports faster resolution across the whole team.
Change enablement
ITIL 4 deliberately renamed "change management" to "change enablement" to signal the intent: enabling beneficial changes safely, not blocking them. Every change falls into one of three categories:
- Standard changes - pre-approved, low-risk, repeatable (adding a standard software package, resetting account permissions)
- Normal changes - require full assessment and Change Advisory Board (CAB) review before implementation
- Emergency changes - accelerated approval process for urgent fixes that can't wait for normal review
A structured CAB with the right stakeholders is the mechanism for keeping normal changes from introducing unintended disruptions. eesel's guide to Atlassian Intelligence AI automation rules covers how automation fits into change workflows for teams on Atlassian platforms.
Service request management
Service requests are routine, pre-defined requests - password resets, software access, new hardware, onboarding tasks. They're distinct from incidents because they're expected and predictable rather than unplanned. This distinction matters because service requests are where automation and self-service have the clearest return on investment.
88% of users globally expect companies to offer self-service for quicker resolution. Service requests are exactly the category where self-service is both straightforward to build and high-value to deliver.
Knowledge management
Knowledge management is the systematic process of creating, sharing, and maintaining the organization's collective knowledge. This includes how-to documentation, troubleshooting guides, FAQs, known error records, post-mortem findings, and onboarding materials.
It's the multiplier that makes every other ITSM process faster. An agent with a good knowledge base resolves a ticket in minutes that would otherwise require a specialist. An AI agent with a good knowledge base handles it before the ticket is filed. A knowledge base that hasn't been maintained in 18 months creates false confidence - users follow outdated steps and call back, which is worse than no self-service at all.
10 ITSM best practices that move the needle
These practices are drawn from where real IT teams get stuck - the gaps between how ITSM is supposed to work and how it actually does, based on data from practitioner surveys, case studies, and community research.
1. Separate incident response from problem management in practice, not just on paper
Most teams have both processes defined in their documentation. Fewer actually separate the work. When incident responders are doing root cause analysis in real time, you get neither: the incident drags while the analysis is rushed.
Allocate dedicated capacity for problem management reviews after major incidents, on a different timeline (within days) than incident response (hours or minutes), by people who weren't in the incident response itself.
HDI SupportWorld contributor Matt Beran put the stakes plainly in his December 2025 review of ITSM trends:
"Incident Management has carried too much weight for too long. Somewhere along the way, we convinced ourselves that being good at putting out fires meant we were providing good service. But deep down, practitioners have always known that Incident Management is the receipt that proves something went wrong."
The metric shift he describes: from counting tickets resolved to counting the absence of avoidable failures.
2. Build the knowledge base before deploying automation
Every high-value ITSM improvement - self-service, AI agents, chatbots - depends on knowledge quality. Deploy any of them onto a sparse or stale knowledge base and you get confident wrong answers at scale, not automation.
91% of users say they would use a knowledge base if it met their needs, but 40% still call support after trying to self-serve. That gap is entirely a knowledge quality problem. The knowledge they found didn't solve their actual issue.
The practical sequence: identify your top 20 ticket types by volume over the past 90 days, write clear resolution guides for each, then automate. eesel's AI helpdesk implementation guide walks through this sequencing for teams adding AI to an existing service desk.
3. Classify changes and stop rubber-stamping approvals
Change management rubber-stamping is one of the most cited failure modes in practitioner ITSM discussions. NetSuite's analysis of the top ITSM challenges names it directly: "Failure to follow a structured change management or change enablement process - often reflected in frequent emergency changes or rubber-stamped approvals - injects unnecessary risk as IT organizations struggle to balance speed with control."
The fix is structural: pre-approve standard changes so your CAB reviews only changes that actually need review, then make those reviews substantive with CMDB-backed impact analysis rather than verbal sign-offs.
4. Set SLAs by request type, not by catch-all timeframe
Generic SLAs obscure performance and frustrate users. A password reset with a 48-hour SLA is a problem. A server migration with the same SLA might be optimistic. Define SLAs by request type, calibrated to actual resolution times from your ticket history, and review them quarterly.
A 1% gain in First Contact Resolution (FCR) leads to a 1% increase in customer satisfaction, according to Contact Center Pipeline research. FCR is a direct function of whether agents have the knowledge and tools to resolve on the first touch - SLAs create the accountability structure that tracks whether that's actually happening.
5. Keep the CMDB accurate
A Configuration Management Database is the backbone of intelligent ITSM. Change management without current CMDB data is guesswork - you can't accurately assess the blast radius of a change if you don't know what depends on what. Yet only 43% of IT professionals have full visibility into their own technology stacks, down from 47% the year before.
Start with the assets and dependencies that matter most: production services, identity systems, network infrastructure. Update the CMDB as part of every change process, not as a separate periodic cleanup project.
6. Enable self-service for tier-0 and tier-1
Password resets, account unlocks, software access requests, VPN setup questions - these represent a large share of ticket volume in most IT organizations, and all of them are candidates for self-service resolution that never touches an agent.
81% of users attempt to resolve issues independently before contacting support. The question isn't whether users want to self-serve; it's whether your self-service offering actually resolves what they're looking for. A portal with accurate, maintained content diverts real volume. A portal with outdated articles adds a second step of frustration before users call anyway.
The Freshservice alternatives comparison covers which ITSM platforms have the strongest self-service capabilities for mid-market teams.
7. Automate the repeatable before the complex
Automation works best on high-volume, low-variance workflows: ticket routing by category, SLA notification emails, escalation policies when SLAs approach breach, access provisioning for standard roles. These can be automated reliably because the decision logic is consistent.
Where automation fails is on complex or context-dependent flows with frequent edge cases. Over 40% of agentic AI projects are projected to fail by 2027 because organizations automate broken or unclear processes rather than first redesigning the underlying workflow. Fix the process, then automate it.
8. Run blameless post-mortems after major incidents
Post-mortems matter because major incidents are your best source of information about where your systems are fragile. A culture that assigns blame after incidents teaches people to minimize what they report. A blameless culture teaches honest accounting of what happened.
Target: every SEV1 and SEV2 incident has a published post-mortem within 48 hours of resolution, answering five questions - what happened, what was the user impact, what actions were taken, what was the systemic root cause, and what specific changes will prevent recurrence. Track at least 90% of post-mortem action items with named owners and due dates.
9. Measure outcomes, not just ticket activity
"We closed 847 tickets this month" doesn't tell a business leader anything useful. "We reduced average resolution time for priority-1 incidents from 6 hours to 2 hours, keeping payroll available for Monday's deadline" does.
Translate MTTR, SLA compliance, and ticket deflection into business terms: downtime cost avoided, employee hours recovered, support cost per headcount served. The ITSM.tools 2025 community poll placed "value demonstration" at #4 on practitioners' priority list - stubbornly high because most teams communicate in operational language their business stakeholders don't act on.
10. Govern AI before scaling it
74% of IT organizations use AI in at least one service management function, and 82% say they've realized value from those investments. But governance is practitioners' top concern for 2026 in the same survey - above GenAI itself.
Good AI governance in ITSM means clear accountability for AI decisions and escalation paths, regular review of AI output quality for accuracy drift, documented confidence thresholds that determine when AI defers to a human, and audit trails for AI-handled tickets. Doug Tedder, 2025 HDI Lifetime Achievement Award winner, was direct about the prerequisite:
"Make no mistake: bad service management will result in bad AI. So, the trend that I am looking forward to is how efforts to adopt AI will result in better service management, shifting the focus from internal IT operations activities to business-outcome-based success."
ITSM metrics that matter
Not every metric is worth close tracking. These six correlate most directly with service quality and business impact:
| Metric | What it measures | Benchmark context |
|---|---|---|
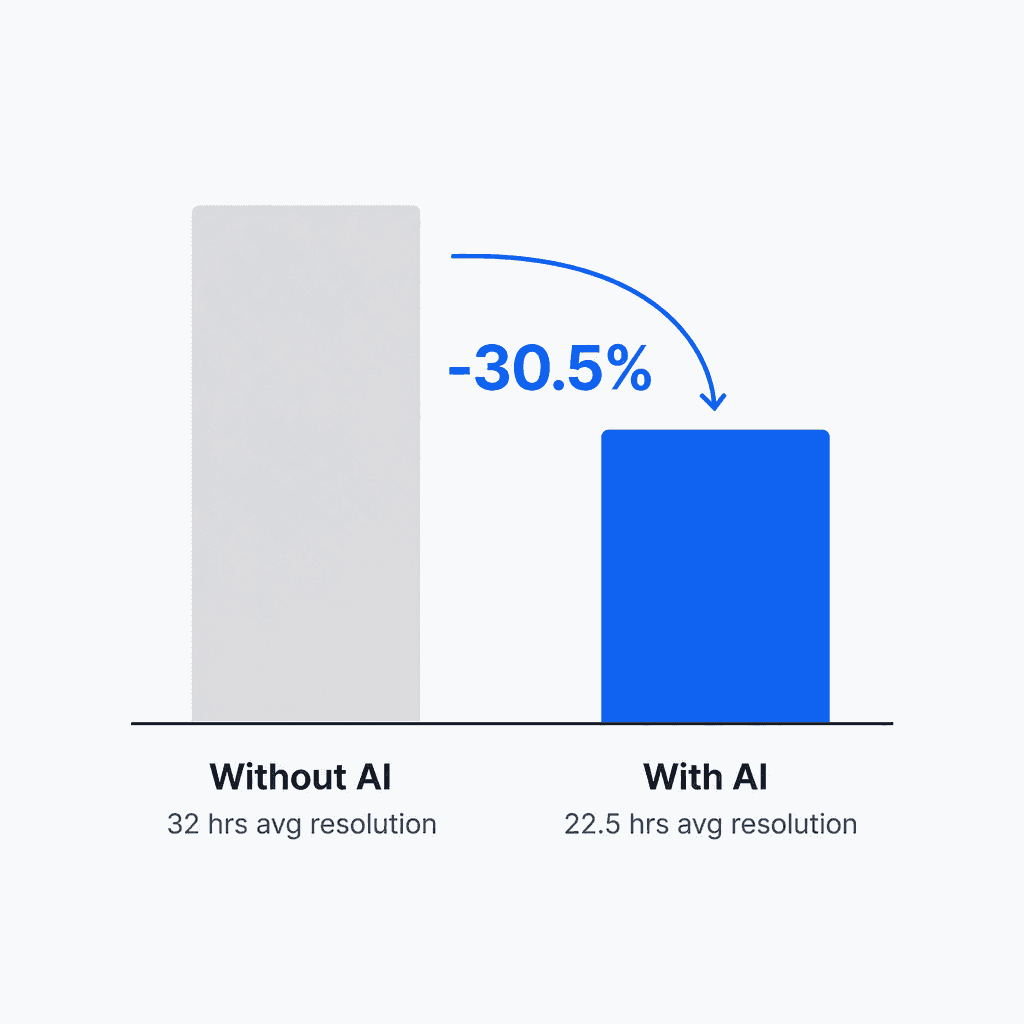
| Mean Time to Resolution (MTTR) | Average time from incident detection to full service restoration | Teams using GenAI resolve tickets 30.5% faster on average; top performers 54.3% faster (SolarWinds 2025) |
| First Contact Resolution (FCR) | % of tickets resolved without escalation or callback | Each 1% FCR gain equals 1% CSAT improvement (Contact Center Pipeline) |
| SLA compliance rate | % of tickets resolved within agreed timeframes | Non-compliance is the earliest signal of resource or process gaps |
| Ticket deflection rate | % of potential tickets resolved through self-service | AI-enabled teams achieve 40-60%; best-in-class hit 85% (Pylon) |
| First Response Time (FRT) | Time from ticket submission to first acknowledgment | 90% of users expect an "immediate" response; 60% define that as 10 minutes or less |
| Customer Satisfaction (CSAT) | User-reported satisfaction with the resolution | 84% of respondents say the service desk is the most important factor in overall IT satisfaction |
Review these as a set. MTTR improving while CSAT declining suggests faster resolution but worse communication. Deflection rate improving while FCR declining suggests self-service is taking tickets but not actually solving the problems behind them.
How AI is reshaping ITSM in 2026
The headline number from the SolarWinds 2025 State of ITSM Report, which analyzed data from 2,000+ ITSM systems and 60,000+ anonymized incident records: organizations using GenAI-enabled features resolved tickets 30.5% faster on average. The top 10 GenAI-adopting organizations cut average resolution time from 51 hours to 23 hours - a 54.3% reduction. Collectively, those customers saved 323,000 hours between August 2024 and July 2025.
The report's key finding about how those gains happened: the top performers didn't treat GenAI as a side project. They built it into their workflows, updated processes around it, and aligned teams around consistent usage.
AI in modern ITSM works across several layers:
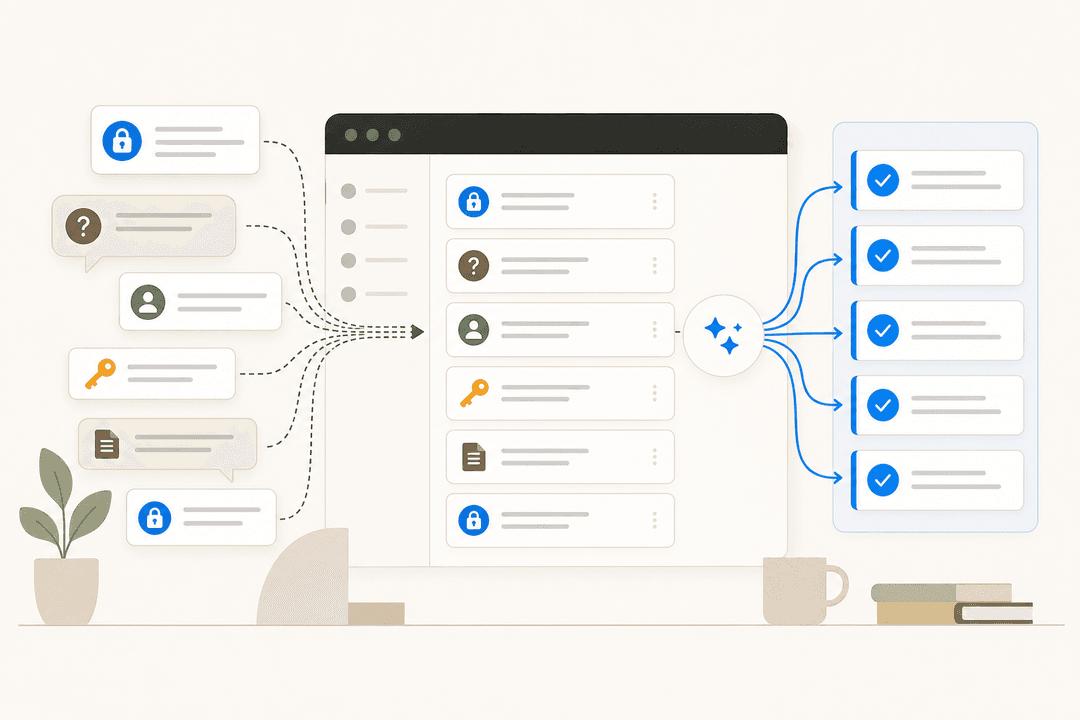
Ticket triage and routing - AI reads incoming tickets, categorizes them by type and priority, and routes to the right team without keyword matching rules. This eliminates a high-volume manual step that's prone to misrouting errors and creates backlogs. eesel's guide to AI for DevOps support covers how this works for engineering-adjacent IT teams specifically.
Resolution drafting and execution - For recognized request types (password resets, VPN access, software requests, standard IT how-tos), AI drafts a response or executes the resolution directly. Teams using supervised mode review before sending; fully autonomous mode handles end-to-end resolution for high-confidence cases. Confidence-based routing - where AI defers to a human when it's uncertain rather than sending a potentially wrong answer - is what separates reliable AI ITSM from confident wrong answers at scale.
Knowledge gap analysis - AI surfaces ticket themes your knowledge base doesn't cover, then drafts articles to fill those gaps. InDebted's IT team, a 5-10 person group supporting 250+ employees across 5 markets, uses eesel as their Jira Service Management first-responder. Jason Loyola, Head of IT, described it simply: "It essentially acts just like an agent would."
Predictive incident detection - Integrating ITSM with infrastructure monitoring lets AI create tickets automatically when systems show early failure signs, before users report them. This converts incident management from reactive to proactive for the categories where it matters most.
For teams evaluating tools, the automated IT ticketing comparison for 2026 covers the distinction between tools that offer genuine end-to-end AI resolution and those that stop at triage and routing.
Common ITSM failure modes to avoid
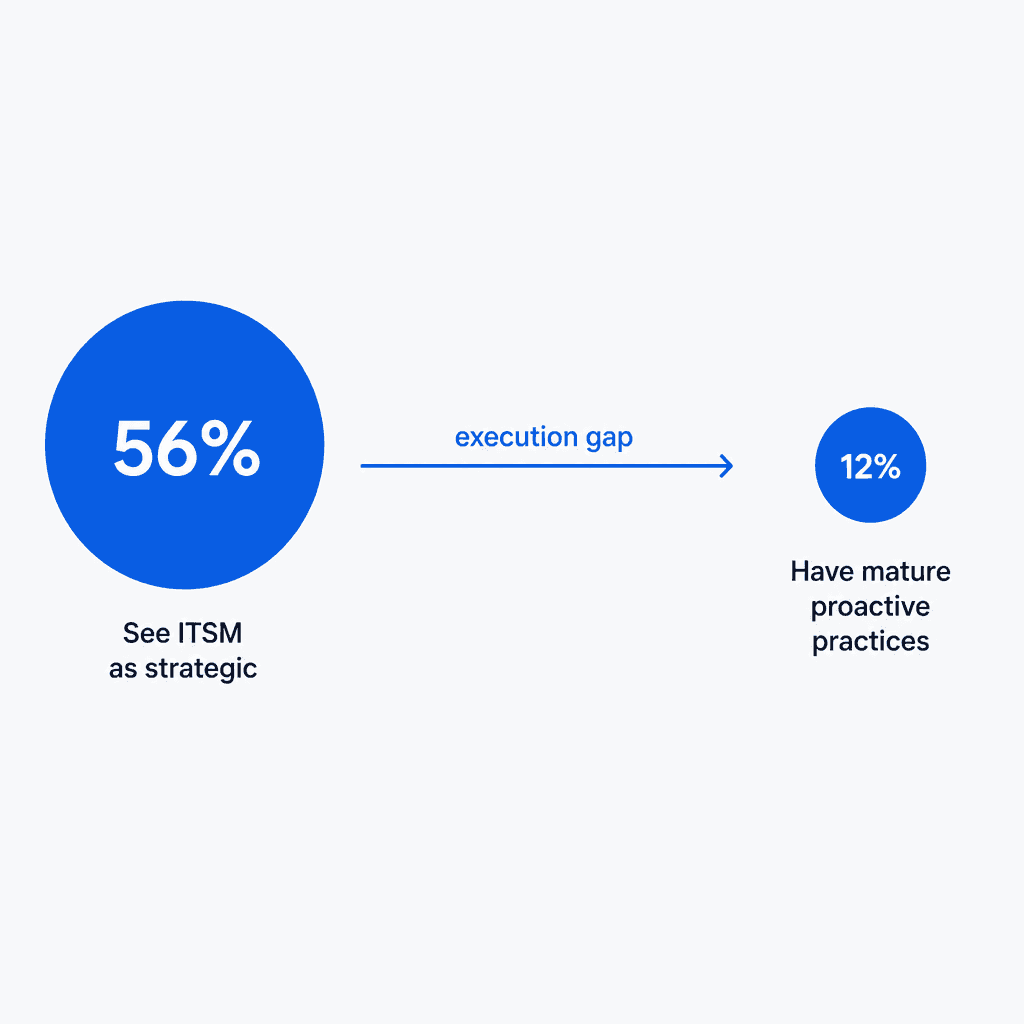
The aspiration-execution gap in ITSM is well-documented. A 2025 joint survey by EasyVista and OTRS Group found that 56% of SMBs see ITSM as a strategic opportunity - but only 12% describe their ITSM approach as "mature and proactive." Nearly 40% still operate without consistent processes.
Five failure modes explain most of that gap:
ITIL compliance theater - Implementing ITIL processes for certification or audit reasons, not because they make practical sense for the organization's scale and context. The practitioner community is consistent here: ITIL is direction, not documentation. A large organization service management consultant Sophie Hussey evaluated wanted to implement all ITIL processes; her assessment found they only needed 16 of them - and that talent management and operational risk management were bigger gaps than any ITIL process they were missing.
Automating broken processes - The most cited AI failure mode in current research. If ticket routing is inconsistent today, AI will route inconsistently faster. Deloitte and Gartner both project that over 40% of agentic AI projects will fail by 2027, primarily because organizations automate broken workflows rather than redesigning them first.
Tool silos - Treating the ticketing system as an isolated queue rather than an integrated workflow connected to identity management, asset management, HR systems, and communication platforms. Over half of IT organizations handle requests via email and spreadsheets while describing their ITSM as strategic.
Tribal knowledge dependency - Critical resolution knowledge living in individuals' heads rather than in documented, searchable processes. 13% of tickets cause 80% of all lost productivity - and most of that 13% involves knowledge that exists somewhere in the team but isn't findable by whoever picks up the ticket. This is also the failure mode that blocks self-service and AI from working: they can only surface what's documented.
Measuring activity instead of outcomes - Reporting ticket counts and resolution times without translating them into business impact. The most common barrier to ITSM improvement is lack of senior management buy-in - and the most common reason for that is ITSM teams communicating in operational language that executives don't act on.
Try eesel AI
eesel AI is an AI teammate platform built to add autonomous resolution to the ITSM you already have - Zendesk, Jira Service Management, Freshservice, Freshdesk, and 100+ other tools. Rather than replacing your service desk infrastructure, eesel sits on top of it and handles the repeatable work: first-response drafts, ticket triage, knowledge-based resolutions, and escalation to humans when confidence is low.
Gridwise resolved 73% of tier-1 requests in the first month. InDebted currently deflects 15% of Jira helpdesk tickets with 55% projected after full training on historical tickets. The free trial starts with $50 in credits - no credit card required.