Afinal, o que é o Sakana Fugu?
A Sakana AI é um laboratório frontier de Tóquio fundado em 2023 por três ex-pesquisadores do Google: o CEO David Ha, o CTO Llion Jones (um dos oito coautores do paper original "Attention Is All You Need" sobre Transformers) e o COO Ren Ito. Em novembro de 2025, captou $135M em uma Série B com avaliação de $2,65B, tornando-se uma das startups de IA mais valiosas do Japão.
O nome importa. "Sakana" (魚) significa peixe, uma referência à aposta do laboratório de que o futuro da IA se parece menos com um grande cérebro e mais com um cardume coordenado de especialistas menores. Fugu (batizado assim em referência ao peixe-baiacu) é essa tese transformada em produto. A Sakana o apresenta como "One Model to Command Them All": desempenho de nível frontier sem depender de nenhum único fornecedor.
A forma mais clara de imaginar: o Fugu é em si mesmo um modelo, mas em vez de gerar a resposta final sozinho, ele monta dinamicamente uma equipe de um conjunto de outros modelos poderosos e os coordena. Todo o aparato é exposto para você como um único modelo por trás de uma única API. Se você leu nossa explicação sobre agentes de IA versus chatbots, o Fugu é a ideia do agente levada ao seu extremo lógico: as "ferramentas" do agente são outros modelos frontier.
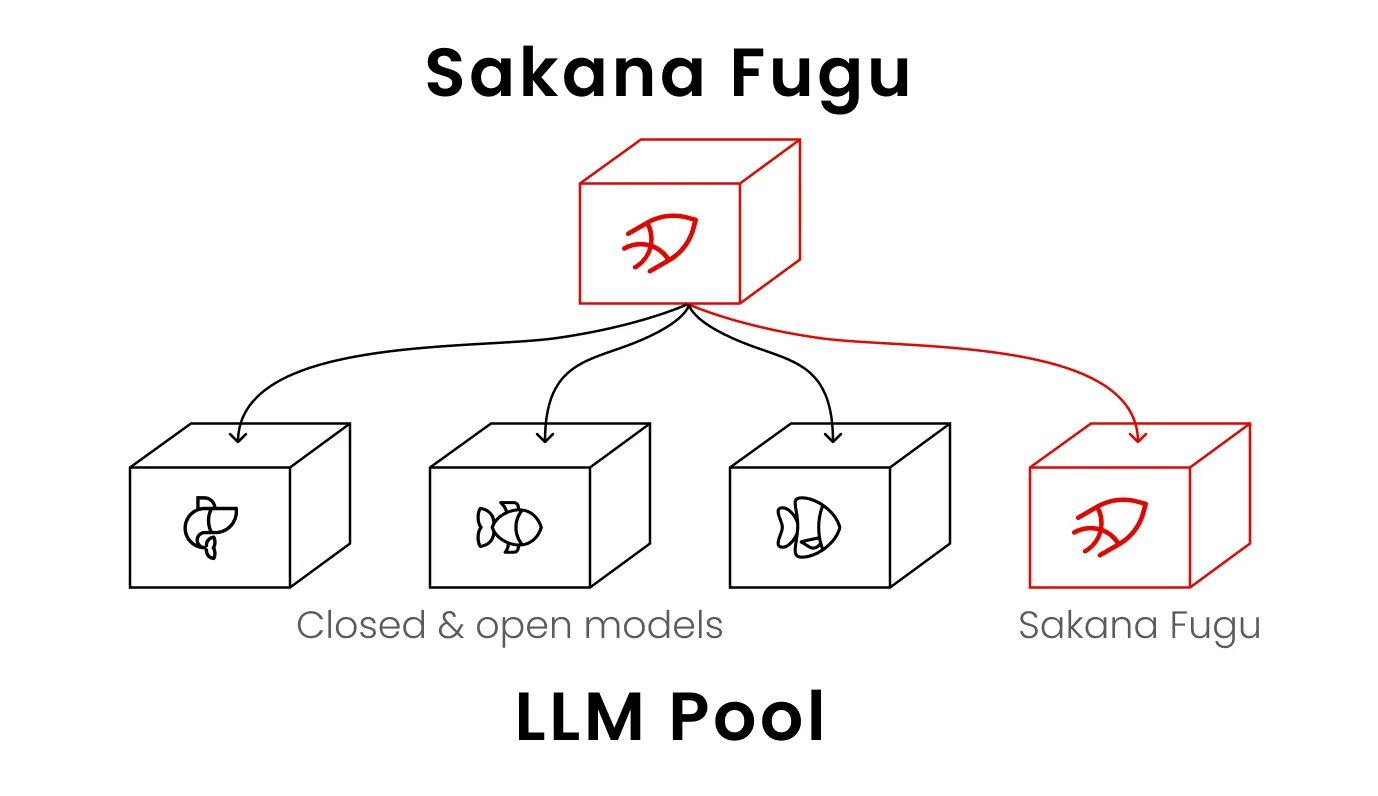
Um detalhe importante que muita gente perde: o Fable 5 e o Mythos Preview não estão no conjunto do Fugu, porque não são acessíveis publicamente. O Fugu orquestra apenas modelos que ele pode realmente chamar. Então, quando a Sakana diz que o Fugu iguala o Fable 5, está dizendo que uma equipe coordenada de outros modelos públicos pode rivalizar com o frontier, o que é uma afirmação mais interessante do que parece à primeira vista.
Como o Fugu realmente funciona por dentro
É aqui que o Fugu merece a defesa de "não é apenas um roteador". Ele é fundamentado em dois papers do ICLR 2026 sobre orquestação de modelos aprendida, e o mecanismo é mais elaborado do que simplesmente escolher um modelo e encaminhar a solicitação.
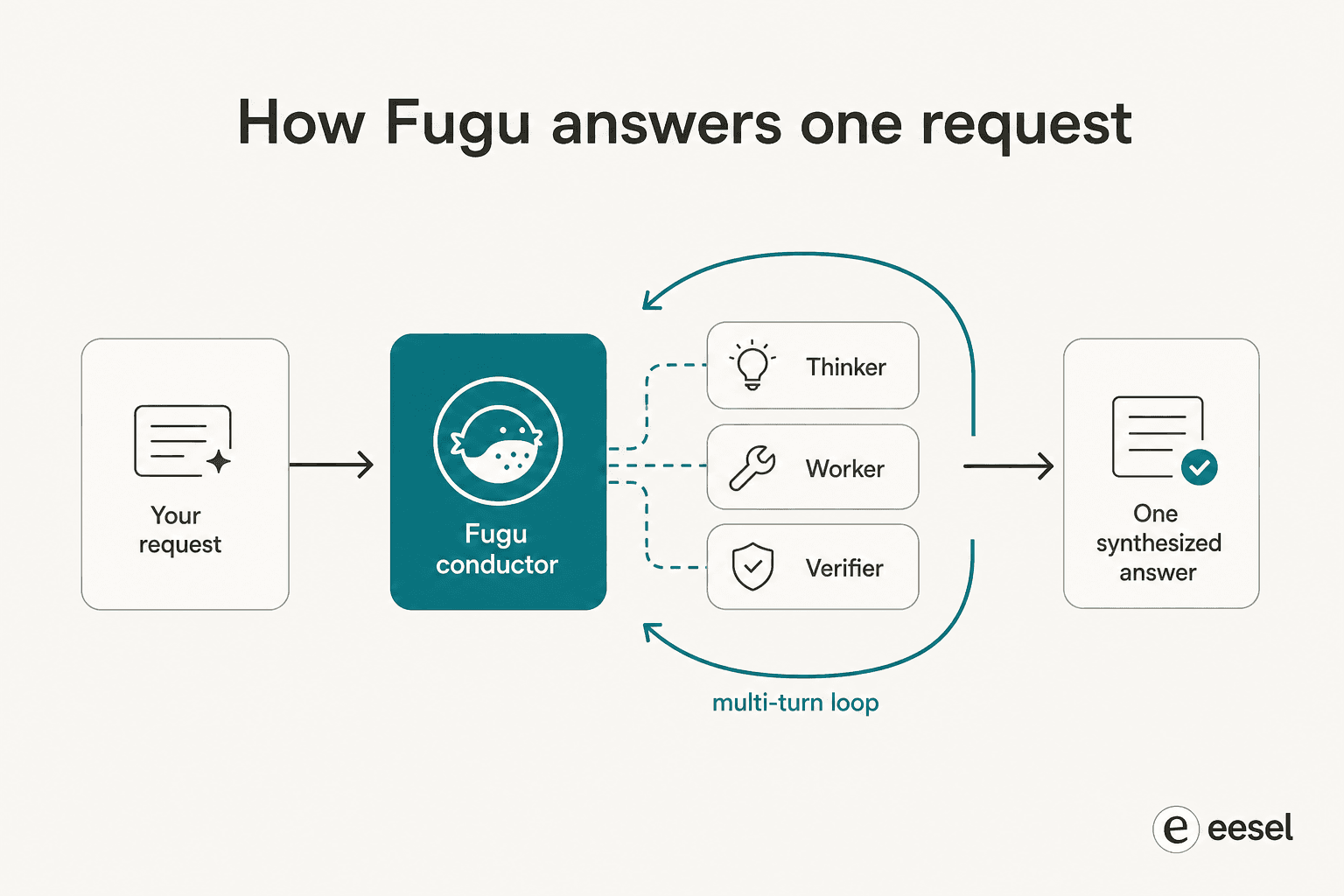
O primeiro paper, TRINITY, usa um coordenador leve e evoluído que orquestra múltiplos modelos ao longo de vários turnos, atribuindo a cada um um papel de Thinker, Worker ou Verifier e redelegando conforme a tarefa se desenrola. O segundo, o Conductor, é treinado com aprendizado por reforço para descobrir estratégias de coordenação em linguagem natural, basicamente aprendendo a escrever prompts focados e a projetar como os modelos se comunicam entre si para que o conjunto supere qualquer membro individual.
As duas frases que valem a pena reter são aprendido e multi-turno. O Fugu não segue um script projetado por humanos de "primeiro pergunte ao modelo A, depois ao modelo B". Ele aprendeu, por meio de evolução e RL, a descobrir padrões de colaboração não óbvios, e itera, verificando novamente e reroteando em vez de fazer uma única passagem. É por isso que os primeiros usuários relatam que ele funciona por horas em uma única tarefa: 123 experimentos ao longo de aproximadamente 14 horas em um problema de pesquisa de ML, ou quase quatro horas reproduzindo autonomamente um paper. Ele se comporta muito parecido com o tipo de loop de agente sobre o qual obcecamos ao construir automação de suporte, só que apontado para modelos frontier em vez de ferramentas.
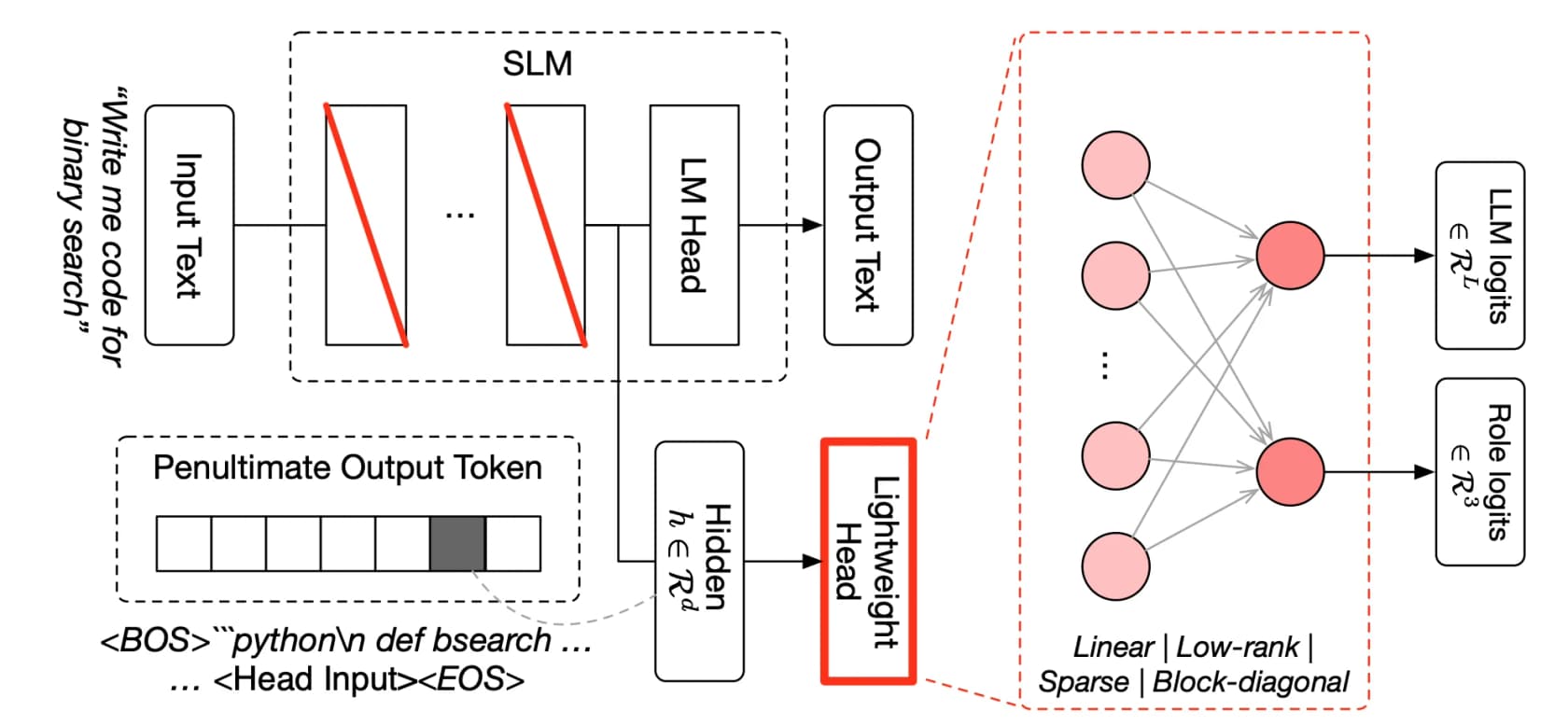
Um trade-off a sinalizar agora: o roteamento é proprietário e opaco por design. Você não pode ver qual modelo subjacente respondeu a uma determinada consulta. Para algumas equipes isso está bem; para qualquer pessoa com necessidades de conformidade, essa estrutura de caixa-preta dentro de caixa-preta é uma consideração real.
Fugu vs Fugu Ultra: qual é qual
O Fugu é lançado como dois modelos, ambos acessíveis pela mesma API compatível com OpenAI, para que você possa alternar entre eles sem tocar na sua integração. A diferença está em quantos agentes especialistas são coordenados, que é a alavanca entre velocidade e qualidade.
| Fugu | Fugu Ultra | |
|---|---|---|
| Otimizado para | Desempenho e latência equilibrados | Máxima qualidade de resposta |
| Conjunto de agentes | Coordena um conjunto; você pode excluir modelos | Conjunto fixo e mais profundo; sem exclusão |
| Melhor para | Codificação cotidiana, revisão de código, chatbots | Problemas difíceis, de alto risco e multi-etapa |
| Trade-off | Baixa latência, padrão sólido | Maior qualidade ao custo de velocidade |
Em termos simples: use o Fugu quando quiser um padrão responsivo, e o Fugu Ultra quando tiver um problema complicado e estiver disposto a esperar por uma resposta melhor. Os primeiros usuários colocam o Ultra para trabalhar em competições no Kaggle, reprodução de papers, análise de cibersegurança e investigações de patentes, o que indica que o ponto ideal pretendido é profundidade, não throughput.
Os benchmarks: ele está realmente de igual para igual com o Fable 5?
A afirmação principal da Sakana é que os modelos Fugu "superam os modelos frontier publicamente acessíveis e estão de igual para igual com o Fable 5 e o Mythos Preview" em benchmarks de engenharia, científicos e de raciocínio. Os números sustentam bem a afirmação mais restrita.
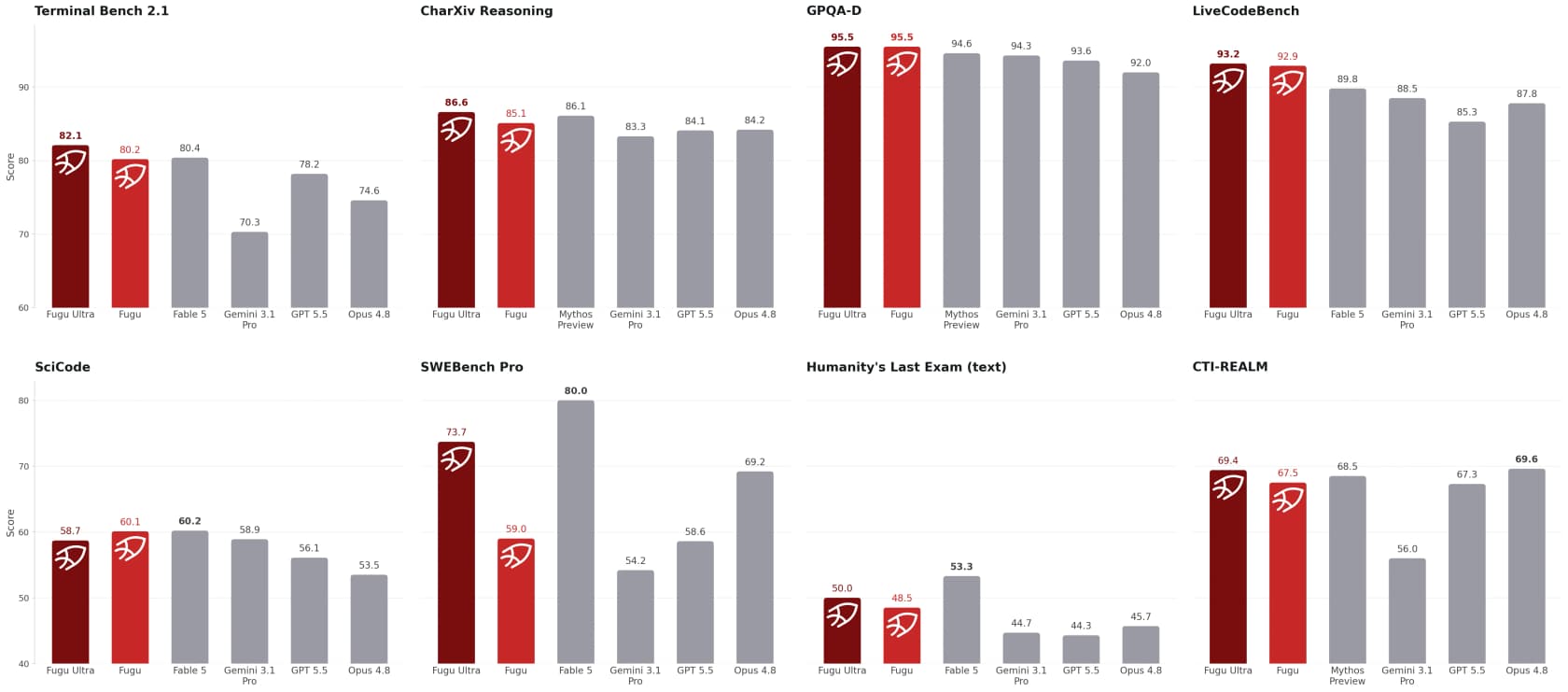
Alguns que se destacam da tabela da Sakana: o Fugu Ultra marca 73,7 no SWE-Bench Pro (vs 69,2 para o Opus 4.8 e 58,6 para o GPT-5.5), 93,2 no LiveCodeBench e 95,5 no GPQA-Diamond, à frente de todas as baselines públicas mostradas. As demos qualitativas são ainda mais interessantes: o Fugu supostamente venceu três modelos frontier e um motor Stockfish de 2100 de Elo no xadrez às cegas, e em um teste de trading de séries temporais fez $10.000 crescerem para $11.943 em uma janela de 50 semanas, um retorno médio de +19,43% que superou os demais.
Dois ressalvas honestas. Primeiro, esses são benchmarks reportados pelo fornecedor, e os modelos mais fortes (Fable 5, Mythos) foram excluídos da comparação como concorrentes diretos em vez de serem vencidos de frente. Segundo, os benchmarks medem a capacidade máxima em problemas difíceis, não se a ferramenta é agradável de usar às 2 da tarde numa terça-feira. Como disse um beta tester, slopdetector, no Hacker News:
"Usei isso durante o beta. Supera o GPT-5.5 xhigh em tarefas complexas. Como é caro e difícil de subsidiar, use-o para os problemas mais desafiadores... os resultados que obtive do fugu-ultra foram impressionantes."
Quanto custa o Sakana Fugu (e o problema que ninguém menciona)
Há duas formas de pagar, e ambas incluem acesso ao Fugu e ao Fugu Ultra.
| Nível de assinatura | Preço | Cota de uso | Para |
|---|---|---|---|
| Standard | $20/mês | Base | Uso diário leve |
| Pro | $100/mês | 10× Standard | Sessões de trabalho focadas |
| Max | $200/mês | 30× Standard | Cargas de trabalho pesadas e de longa duração |
(Vale notar: os cartões de preços da Sakana dizem que o Max é 30× Standard enquanto uma resposta de FAQ diz 20×, então confirme a cota antes de se comprometer.) Há também um plano de tokens por uso onde o Fugu Ultra tem preço fixo de $5 de entrada, $30 de saída e $0,50 de entrada em cache por milhão de tokens, subindo para $10 / $45 / $1,00 quando o contexto ultrapassa 272K tokens. E há uma promo de lançamento: assine antes do final de julho de 2026 para um segundo mês grátis.
Agora o problema. O Fugu tem preço no teto do conjunto que roteia, então o overhead de orquestação precisa se justificar frente a simplesmente pagar diretamente por um modelo frontier. Vários usuários com experiência prática sentiram que não se justificava. A versão mais contundente veio de cortesi no Hacker News:
"Por $200/mês você tem menos de 3 horas de uso por semana, a API é extremamente lenta, e a qualidade de saída nos meus testes não chega nem perto do Fable. Não está nem remotamente perto de ser utilizável como cavalo de batalha diário. Muito decepcionante."
Essa é a experiência de um tester, não um veredito, mas ressoa com vários outros relatando que o limite de 5 horas se esgota rápido. Se você já modelou custos de agentes de IA versus agentes humanos, a lição é familiar: o preço de tabela e o custo real por tarefa útil são números diferentes.
Aqui uma verificação rápida sobre se o Fugu é a ferramenta certa para o que você está fazendo:
A crítica de "apenas OpenRouter com passos extras" é justa?
A reação mais barulhenta ao lançamento do Fugu, repetida independentemente no Hacker News, X e Reddit, foi algo como "isso não é simplesmente OpenRouter?" É um instinto válido, então vamos levá-lo a sério.
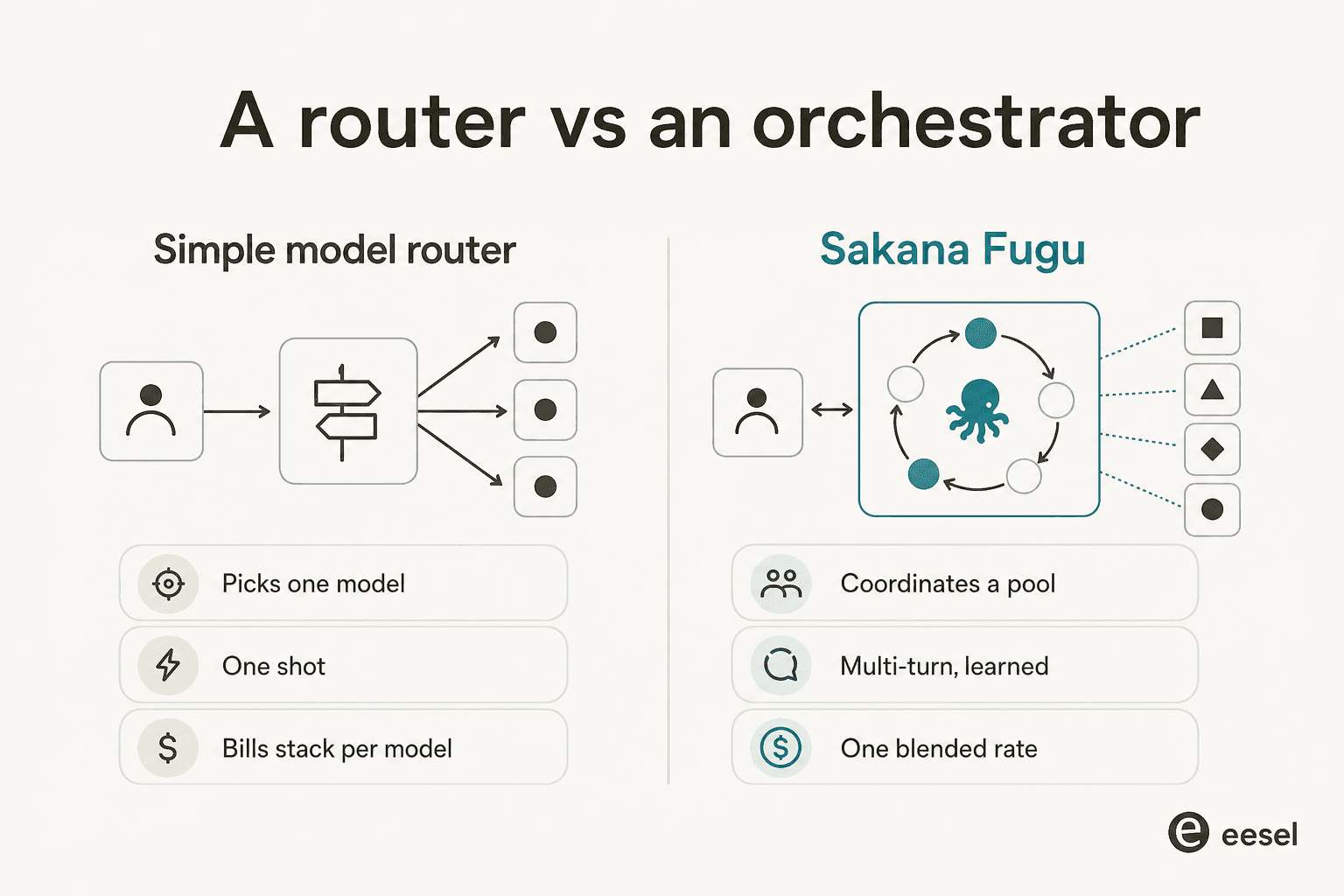
Um roteador simples escolhe um modelo e encaminha sua solicitação uma vez. O Fugu, pelo menos no papel, faz três coisas que um roteador não faz: ele executa múltiplos turnos, faz os modelos verificarem o trabalho uns dos outros e cobra uma única taxa combinada com base no modelo superior envolvido em vez de acumular a conta de cada modelo. A arquitetura é real, e "roteador avançado" subestima o loop multi-turno e de auto-verificação.
Mas os céticos acertam no valor, não na arquitetura. Como chenzhekl perguntou diretamente:
"Mas tem o mesmo preço que os modelos frontier. Por que não pago diretamente pelos modelos frontier?"
Esse é todo o debate em uma linha. A arquitetura é mais que um roteador; a questão em aberto é se a coordenação extra compra suficiente para justificar pagar preços frontier por isso. Minha avaliação: nos seus problemas mais difíceis, possivelmente sim; no trabalho cotidiano, provavelmente não. Este é o mesmo cálculo que aparece nas decisões de agente de IA versus chatbot baseado em regras, onde mais sofisticação só vale a pena quando a tarefa é realmente difícil.
O que as pessoas realmente pensam sobre o Sakana Fugu
O sentimento da comunidade, lido com justiça, é misto a cético, com um campo pró real. Os defensores fazem o argumento mais interessante: que fazer os modelos se verificarem mutuamente é simplesmente a aposta certa. Como argumentou epsteingpt:
"Todos entenderam há meses que fazer diferentes modelos se verificarem mutuamente é o melhor caminho a seguir... Se (grande se) a mecânica de uso funcionar, então isso é na verdade uma estratégia anti-modelo-grande muito boa. Eles serão incentivados pelo seu sucesso, não maximizando tokens para seus investidores."
Esse ponto de alinhamento de incentivos é preciso, e é uma razão real para torcer por um orquestrador em vez de um monólito. Há também um fio de respeito pelo caminho de pesquisa da Sakana. Como quanto observou, David Ha tomou um caminho não convencional para a pesquisa em IA, e o trabalho anterior do laboratório (Evolutionary Model Merge, o AI Scientist, Transformer²) é consistentemente distinto.
Os céticos, por sua vez, não são reflexivos. Suas objeções se agrupam em custo, latência e o enquadramento opaco de "um único fornecedor substituindo outro único fornecedor". E um par de notas do mundo real que vale a pena saber antes de se cadastrar: o Fugu ainda não está disponível na UE/EEE, e alguns usuários expressaram desconforto com os contratos militares da Sakana. Se você está pesando isso frente aos melhores agentes de IA para produção, essas não são notas de rodapé.
Por que um modelo que orquestra modelos importa para o suporte
Esta é a parte que mais me importa, porque é o trabalho que faço. A ideia subjacente do Fugu — não aposte seu fluxo de trabalho em um único modelo, coordene vários e faça-os se verificar mutuamente — é exatamente certa para automação de alto risco como suporte ao cliente. Uma resposta errada de um bot de suporte não é um erro no leaderboard, é um reembolso emitido por engano ou um cliente furioso.
Mas há um abismo entre uma API de modelo bruto e opaca e algo que você pode colocar com segurança na frente dos clientes. O Fugu te dá orquestração; ele não te dá sua central de ajuda, seus tickets anteriores, a voz da sua marca, suas regras de escalonamento ou uma forma de testar a coisa antes de ir ao ar. Essa é a camada que realmente decide se IA para atendimento ao cliente funciona, e é por isso que eu escolheria um agente de IA para atendimento ao cliente especializado em vez de conectar manualmente uma API frontier. A questão de orquestação sobre a qual obcecamos em construir versus comprar é a mesma que o Fugu está respondendo, só que em uma camada diferente da stack.
Experimente o eesel
O eesel pega a lição sobre a qual o Fugu é construído e a aplica onde ela realmente precisa ser confiável: sua fila de suporte. Em vez de entregar uma API de modelo, é um agente de IA que se conecta ao helpdesk que você já usa (Zendesk, Freshdesk, Help Scout, Slack e mais) em minutos, se treina nos seus tickets anteriores e central de ajuda, e responde com a voz da sua marca, sem necessidade de encanamento de orquestração de modelos.

O diferencial mais importante aqui é a parte que o Fugu não pode te dar: um modo de simulação que reproduz o agente contra milhares dos seus tickets históricos antes de ele tocar em um cliente ao vivo, para que você veja a taxa de resolução e as respostas exatas antecipadamente, em vez de descobri-las em produção. Os preços são baseados em uso sem taxas por assento, para que o custo escale com o valor em vez do número de funcionários. Se você quiser ver como é um agente de IA para atendimento ao cliente quando a orquestração é invisível e as salvaguardas estão integradas, é gratuito para experimentar.
Perguntas Frequentes
O que é o Sakana Fugu em termos simples?
Como o Sakana Fugu é diferente do OpenRouter?
Quanto custa o Sakana Fugu?
O Sakana Fugu é melhor que o Claude ou GPT-5.5?
Para que o Sakana Fugu é mais indicado?
Posso usar o Sakana Fugu para suporte ao cliente?
O Sakana Fugu está disponível em todo lugar?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.








