
O que é o Groq (e por que os preços funcionam de forma diferente aqui)?
O Groq não cria modelos - eles executam modelos de outras pessoas (Llama, Qwen, Mistral, Whisper, open-weights da OpenAI) em seu próprio silício personalizado: a Language Processing Unit, ou LPU. Fundada em 2016 por ex-engenheiros do TPU do Google, eles captaram $750M com uma avaliação de $6,9 bilhões em setembro de 2025 e hoje atendem mais de 2 milhões de desenvolvedores. A equipe McLaren F1 usa o Groq para análises de corrida em tempo real - não é um caso de uso onde "geralmente rápido" é aceitável.
O modelo de preços é simples: cobrar por token, sem taxas de infraestrutura ociosa, sem picos de preços elásticos. Declaração oficial do Groq sobre isso: "Outros provedores de inferência aumentam os custos sem aviso. Alguns se escondem atrás de preços elásticos. Os preços do Groq são lineares e previsíveis, sem custos ocultos ou infraestrutura ociosa."

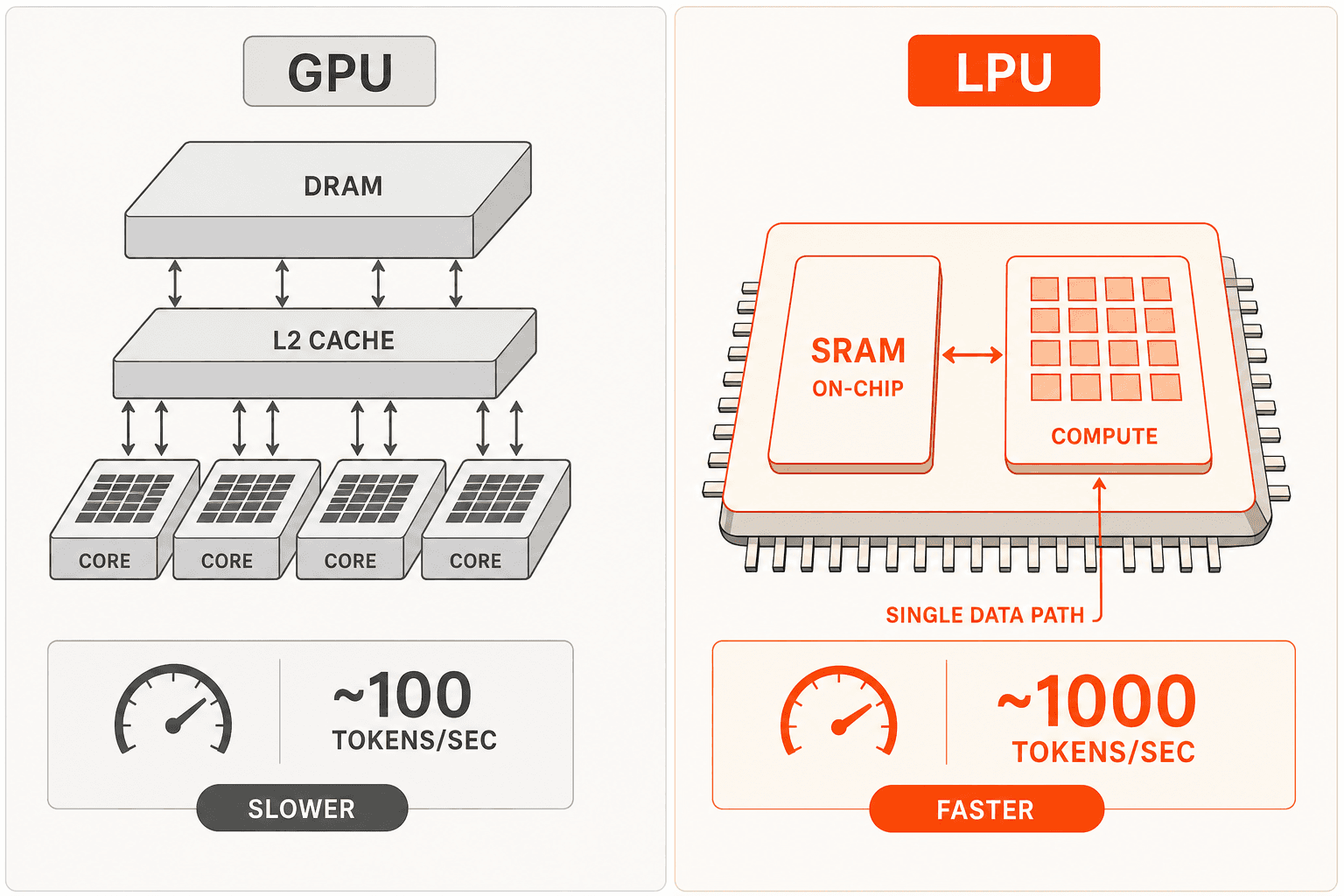
Por que a LPU muda a equação de custos
As GPUs foram criadas para treinamento: grandes hierarquias de memória DRAM/HBM externas, agendamento dinâmico, protocolos de coerência de cache. Essas são boas propriedades ao paralelizar operações matriciais em milhares de núcleos para treinamento. Elas não são adequadas para inferência, onde a execução sequencial de camadas tem baixa intensidade aritmética e as buscas de memória dominam a latência.
A arquitetura LPU adota uma abordagem diferente. A SRAM on-chip serve como armazenamento primário de pesos - não um cache, mas a memória primária. O compilador dedicado do Groq pré-agenda cada operação até os ciclos de clock individuais antes do início da execução, eliminando completamente a sobrecarga de agendamento dinâmico. O protocolo RealScale chip-a-chip permite que centenas de LPUs se comportem como um único núcleo para paralelismo tensorial. Como cada operação é agendada estaticamente, o Groq pode executar paralelismo de pipeline sobre paralelismo tensorial: a camada N+1 começa a ser processada enquanto a camada N ainda está finalizando - algo que o agendamento dinâmico de GPU não consegue fazer de forma confiável.
O resultado prático: GPT OSS 20B a 1.000 tokens por segundo. Llama 3.1 8B a 560–840 TPS. Llama 3.3 70B a 280–394 TPS. APIs de nuvem típicas baseadas em GPU rodam 50–100 TPS em modelos equivalentes. Quando o mesmo hardware atende mais requisições por segundo, os custos fixos se distribuem por mais tokens - é assim que $0,05 por 1M de tokens de entrada se torna comercialmente viável.

Nível gratuito do Groq: o que você realmente recebe
O nível gratuito não exige cartão de crédito e é governado por limites de taxa, não por uma cota mensal de tokens. Veja exatamente o que cada modelo oferece no plano gratuito:
| Modelo | RPM | TPM | Requisições/dia |
|---|---|---|---|
llama-3.1-8b-instant | 30 | 6.000 | 14.400 |
llama-3.3-70b-versatile | 30 | 12.000 | 1.000 |
meta-llama/llama-4-scout-17b-16e-instruct | 30 | 30.000 | 1.000 |
openai/gpt-oss-20b | 30 | 8.000 | 1.000 |
openai/gpt-oss-120b | 30 | 8.000 | 1.000 |
qwen/qwen3-32b | 60 | 6.000 | 1.000 |
groq/compound | 30 | 70.000 | 250 |
whisper-large-v3 | 20 | - | 2.000 req. de áudio |
whisper-large-v3-turbo | 20 | - | 2.000 req. de áudio |
(RPM = requisições por minuto, TPM = tokens por minuto. Fonte: documentação de limites de taxa do Groq)
Duas coisas pegam os desenvolvedores de surpresa. Primeiro, os limites de taxa se aplicam no nível da organização, não por chave de API. Criar cinco chaves não te dá 150 RPM - ainda são 30 RPM compartilhados em toda a sua conta. Segundo, os tokens de cache de prompt não contam para os limites de taxa, o que é um benefício significativo se você tem prompts de sistema longos que se repetem entre chamadas.
Os limites de TPM por minuto geralmente são a restrição real, não as cotas diárias de requisições. Um prompt de 2.000 tokens consome um terço do orçamento de TPM do Llama 8B em uma única chamada.
"Tenho usado a API do Groq ininterruptamente, pensando constantemente 'como ainda não atingi algum limite do nível gratuito'"
O nível gratuito do Whisper é o destaque. A Artificial Analysis confirmou o Groq como um dos provedores de Whisper Large v3 de menor custo. No plano gratuito você recebe 2.000 requisições de transcrição de áudio por dia - aproximadamente 2 horas de áudio por hora do relógio ao fazer lotes no mínimo de 10 segundos por requisição. A OpenAI cobra $0,36/hora pelo acesso ao Whisper; o nível pago do Groq cobra $0,04–$0,111/hora, então o nível gratuito é um ponto de partida generoso.
"A API gratuita para speech to text é incrível, muito generosa, altamente recomendo."
Avaliador do Trustpilot

Preços da API paga do Groq: todos os modelos
Todos os preços estão em USD por 1M de tokens (entrada / saída), salvo indicação contrária. Fonte: página de preços do Groq.
Modelos de texto/LLM
| Modelo | ID do modelo | Velocidade (TPS) | Contexto | Entrada $/1M | Saída $/1M | Status |
|---|---|---|---|---|---|---|
| Llama 3.1 8B Instant | llama-3.1-8b-instant | 560–840 | 128k | $0,05 | $0,08 | Produção |
| GPT OSS 20B | openai/gpt-oss-20b | 1.000 | 128k | $0,075 | $0,30 | Produção |
| Llama 4 Scout (17Bx16E) | meta-llama/llama-4-scout-17b-16e-instruct | 594–750 | 128k | $0,11 | $0,34 | Preview |
| GPT OSS 120B | openai/gpt-oss-120b | 500 | 128k | $0,15 | $0,60 | Produção |
| Qwen3 32B | qwen/qwen3-32b | 400–662 | 131k | $0,29 | $0,59 | Preview |
| Llama 3.3 70B Versatile | llama-3.3-70b-versatile | 280–394 | 128k | $0,59 | $0,79 | Produção |
| Kimi K2 Instruct | moonshotai/kimi-k2-instruct-0905 | - | - | $1,00 ($0,50 em cache) | $3,00 | - |
| Llama Prompt Guard 2 22M | meta-llama/llama-prompt-guard-2-22m | - | 512 | $0,03 | $0,03 | Preview |
| Llama Prompt Guard 2 86M | meta-llama/llama-prompt-guard-2-86m | - | 512 | $0,04 | $0,04 | Preview |
Alguns detalhes de modelos que valem destaque. O GPT OSS 20B - o modelo open-weight da OpenAI, não o GPT-4 - roda a 1.000 tokens por segundo a $0,075 de entrada / $0,30 de saída. Isso é simultaneamente o modelo mais rápido da plataforma e um dos mais baratos por token de saída. O Llama 4 Scout suporta entradas de visão (arquivos de até 20 MB), mas permanece em Preview - não o coloque em produção ainda. O Kimi K2 é o único modelo onde o cache de prompt está explicitamente incorporado na linha de preços: $0,50 por 1M de tokens de entrada em cache versus $1,00 sem cache.
Os modelos Prompt Guard ($0,03–$0,04 por 1M de tokens) são classificadores de segurança projetados para detectar injeção de prompt e tentativas de jailbreak - úteis se você estiver construindo IA voltada para clientes e precisar de uma camada de filtro leve antes do seu modelo principal.
Limites de taxa do plano Developer
O salto do plano gratuito para o Developer é substancial:
| Modelo | TPM Developer | RPM Developer |
|---|---|---|
llama-3.1-8b-instant | 250.000 | 1.000 |
llama-3.3-70b-versatile | 300.000 | 1.000 |
openai/gpt-oss-20b | 250.000 | 1.000 |
openai/gpt-oss-120b | 250.000 | 1.000 |
meta-llama/llama-4-scout-17b-16e-instruct | 300.000 | 1.000 |
qwen/qwen3-32b | 300.000 | 1.000 |
whisper-large-v3-turbo | 400.000 ASH | 400 |
groq/compound | 200.000 | 200 |
(Fonte: console.groq.com/docs/models)
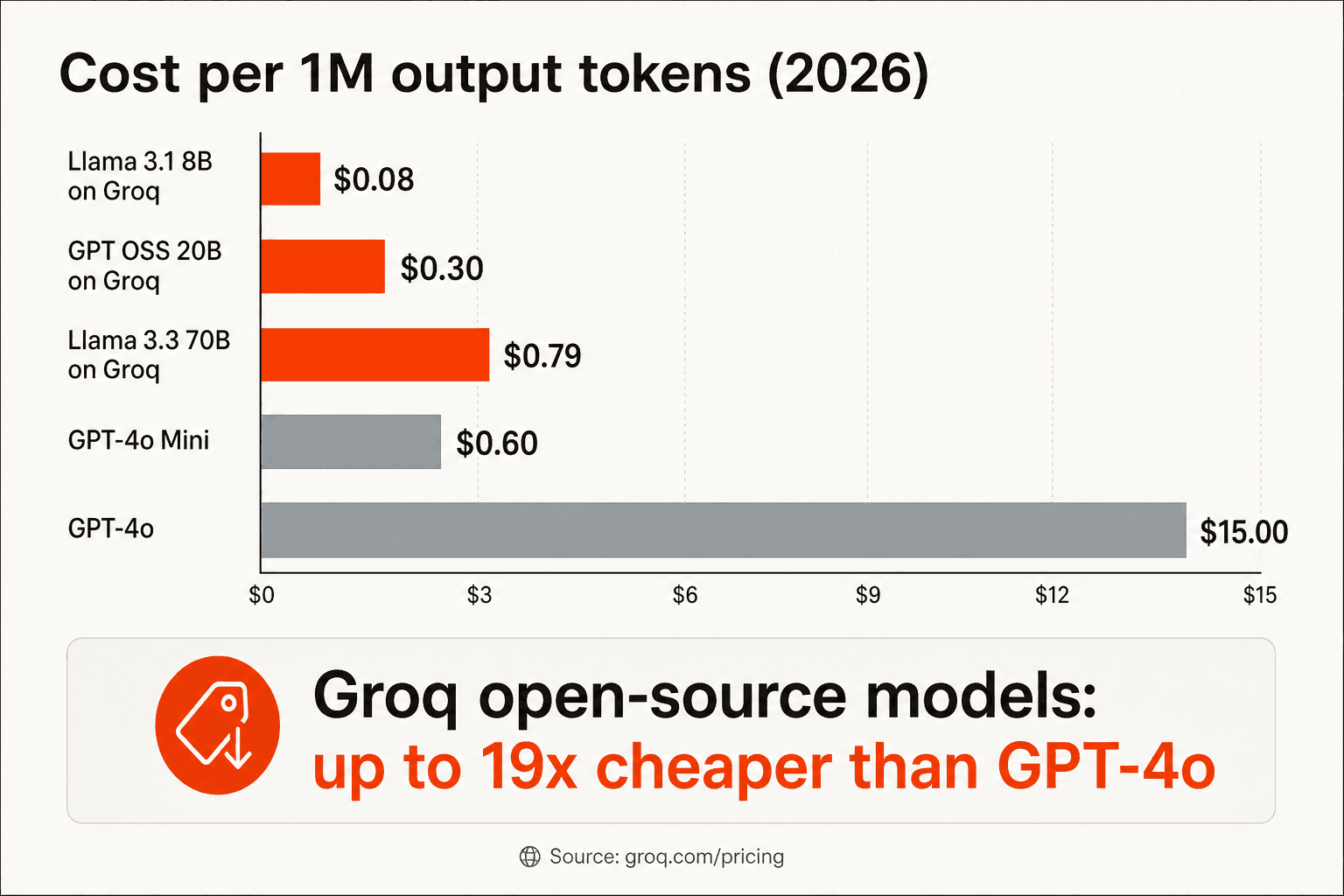
Como os preços do Groq se comparam aos da OpenAI e outros provedores
O número mais citado nas comunidades de desenvolvedores é "10–20x mais barato que a OpenAI para modelos de código aberto comparáveis." Isso é aproximadamente correto, com a ressalva necessária de que você não está comparando modelos idênticos.
"A inferência de LLM no Groq custa cerca de 10 vezes menos em comparação com os preços da OpenAI para o GPT-4o. O Groq é 10–20x mais barato, mas para um modelo um pouco menos capaz - Llama 3-70B vs GPT-4o."
A comparação mais honesta não é Groq versus os modelos proprietários da OpenAI - é Groq versus outros provedores de hospedagem de código aberto como Together AI ou Fireworks AI executando os mesmos modelos. Lá, de acordo com a revisão de produção de 8 semanas da Awesome Agents, o Groq roda 20–50% mais barato em níveis de modelo equivalentes com latência de cauda determinística que o p99 permanece dentro de 15% da mediana - uma vantagem significativa sobre cargas de trabalho em GPU onde picos de latência de cauda são comuns.
"Adeus API da OpenAI. Hoje, você pode obter a mesma inteligência subjacente - Llama-3 ou seus concorrentes de código aberto - por taxas despencando para o fundo, muitas vezes abaixo de $0,20 por milhão de tokens. Isso é uma redução de preço de 99% em dezoito meses."
O modelo mental dos praticantes que emergiu na comunidade de desenvolvedores - resumido por Jolly Gupta no LinkedIn (114 curtidas, setembro de 2025): use o Groq para cargas de trabalho de código aberto críticas para velocidade e sensíveis ao custo, use a OpenAI quando precisar das capacidades do GPT-4o ou profundidade multimodal. A maioria das stacks em produção usa os dois.
O Groq também apareceu na pesquisa da Artificial Analysis como um dos 5 principais provedores de inferência por adoção de desenvolvedores - ao lado de OpenAI, Google, Anthropic e Microsoft.
Preços de áudio: Whisper e TTS
Speech-to-text
O Groq executa ambas as variantes do Whisper Large v3 em hardware LPU, entregando transcrição a 217–228x a velocidade em tempo real. Uma hora de áudio é processada em cerca de 15 segundos.
| Modelo | Fator de velocidade | Preço | Arquivo máximo |
|---|---|---|---|
whisper-large-v3 | 217x em tempo real | $0,111 / hora | 100 MB |
whisper-large-v3-turbo | 228x em tempo real | $0,04 / hora | - |
Para a maioria das cargas de trabalho, o Turbo a $0,04/hora é a escolha clara - mais rápido e 2,8x mais barato que o modelo completo, com apenas diferenças marginais de qualidade na maioria dos áudios. O áudio é cobrado com um mínimo de 10 segundos por requisição independentemente do comprimento real, então vale o esforço de implementação para agrupar clipes curtos.
A OpenAI cobra $0,36/hora pelo Whisper; o Groq a $0,04/hora é 9x mais barato no modelo Turbo. O Levels.io observou que o Whisper + TTS no Groq era "muito barato" mesmo em 2024; os preços permaneceram estáveis desde então.
Text-to-speech (Preview)
O Groq lançou recentemente TTS por meio dos modelos Orpheus da Canopy Labs:
| Modelo | Preço | Notas |
|---|---|---|
canopylabs/orpheus-v1-english | $22,00 / 1M chars | Inglês, ~100 chars/seg |
canopylabs/orpheus-arabic-saudi | $40,00 / 1M chars | Árabe (dialeto saudita) |
Esses ainda estão em status Preview. A vantagem de velocidade da LPU também é visível aqui - o Orpheus gera a 100 caracteres por segundo no Groq, o que possibilita aplicações de voz quase em tempo real.

Sistemas de IA compostos: quando as ferramentas custam extra
Os sistemas Compound do GroqCloud - groq/compound e groq/compound-mini - são wrappers agênticos que fornecem a um modelo de linguagem busca na web e execução de código integradas. Os preços são os custos de tokens do modelo mais o uso de ferramentas:
| Ferramenta | Preço |
|---|---|
| Busca na web básica | $5 / 1.000 requisições |
| Busca na web avançada | $8 / 1.000 requisições |
| Visitar website | $1 / 1.000 requisições |
| Execução de código | $0,18 / hora |
| Automação de navegador | $0,08 / hora |
O sistema Compound roda a ~450 TPS com contexto de 131k. É um ponto de partida prático para cargas de trabalho de IA agêntica onde você quer delegar a orquestração de uso de ferramentas à plataforma em vez de construí-la você mesmo.

Dois descontos ocultos que vale conhecer
Batch API: 50% de desconto para cargas de trabalho assíncronas
A Batch API reduz pela metade o custo de qualquer modelo ao executar trabalhos de forma assíncrona. Você envia um arquivo JSONL (até 50.000 linhas, 200 MB), o processamento é concluído em 24 horas a 7 dias, e você paga 50% da taxa padrão por token. Sem impacto nos seus limites de taxa padrão.
Essa é a escolha certa para: pipelines de classificação de documentos, geração de conteúdo em massa, enriquecimento de dados noturno, moderação de conteúdo em escala - qualquer coisa onde a tolerância à latência ganha um desconto significativo. O uso de ferramentas em sistemas Compound ainda é cobrado a taxas padrão.
Cache de prompt: 50% de desconto em prefixos repetidos
O cache de prompt é automático - sem alterações de código, sem taxa extra. Quando o mesmo prefixo (um prompt de sistema longo, um documento de referência) se repete entre chamadas, o Groq o armazena em cache por até 2 horas. Acertos de cache custam 50% do preço de entrada normal.
Modelos com suporte a cache de prompt e suas taxas em cache:
| Modelo | Entrada padrão | Entrada em cache |
|---|---|---|
openai/gpt-oss-20b | $0,075 / 1M | $0,0375 / 1M |
openai/gpt-oss-120b | $0,15 / 1M | $0,075 / 1M |
moonshotai/kimi-k2-instruct-0905 | $1,00 / 1M | $0,50 / 1M |
O benefício duplo: tokens em cache custam metade e não contam para os limites de taxa. Para cargas de trabalho com prompts de sistema longos - pipelines de RAG, Q&A de documentos, agentes de suporte ao cliente com IA com grandes contextos de conhecimento - isso estende significativamente seu throughput efetivo sem fazer upgrade no nível de limite de taxa.
Limites de taxa: o que acontece quando você os atinge
Quando qualquer limite de taxa é excedido, o Groq retorna HTTP 429 com um cabeçalho retry-after mostrando quantos segundos esperar. O corpo do erro é específico:
"Limite de taxa atingido para o modelo
openai/gpt-oss-20b… nível de serviço: on_demand … Limite 200.000 · Usado 199.336 · Solicitado 1.524 · Por favor, tente novamente em 6m 11,52s."
Os cabeçalhos de resposta também incluem x-ratelimit-limit-requests, x-ratelimit-remaining-tokens e x-ratelimit-reset-requests - o suficiente para implementar backoff exponencial preciso sem tentativa e erro.
A principal consideração operacional: os limites de taxa são por organização e por modelo. Se você estiver executando vários serviços ou membros de equipe na mesma conta Groq, eles compartilham o mesmo pool de limites. Use contas de organização separadas para ambientes de produção e desenvolvimento, ou entre em contato com o Groq sobre limites mais altos para cargas de trabalho específicas via console.groq.com/settings/limits.
Preços empresariais
Não há tabela pública de preços empresariais. Para acessar o seguinte, entre em contato com groq.com/enterprise-access:
- Limites de taxa mais altos para cargas de trabalho específicas
- Implantação on-premises do GroqRack
- Modelos ajustados com LoRA
- Modelos exclusivos para empresas (Minimax M2.5, Qwen3-VL 32B com visão)
- Opções de implantação regional e residência de dados
- Documentação de conformidade SOC 2, GDPR e HIPAA
Sobre o uptime: a revisão de produção da Awesome Agents mediu 99,94% de uptime em 8 semanas com latência p99 dentro de 15% da mediana - melhor comportamento de cauda do que concorrentes baseados em GPU porque o agendamento LPU é determinístico. Garantias de SLA empresarial requerem um acordo formal.
A questão da sustentabilidade
A maioria dos guias de preços do Groq pula isso. Nós não vamos.
Em setembro de 2024, Kyle Corbitt postou no X que havia ouvido um funcionário do Groq afirmar que seus custos por token são "1–2 ordens de magnitude maiores do que o que eles cobram." A publicação atingiu 271 mil visualizações. No início de 2024, @swyx fez os cálculos e descobriu que os preços só funcionam com um tamanho de lote de ~512 - inédito em inferência normal - e caem para ~$1,84 por milhão de tokens com um lote normal de 64.
O contra-argumento: o Groq captou $750M da BlackRock, Samsung, Cisco e Disruptive AI especificamente porque a tese de volume e novos chips é crível. Seus estudos de caso de clientes mostram GPTZero 7x mais rápido e 50% menor custo, ReBlink com custo 14x menor por jogo, Recall com custo 10x menor. Os dados de mindshare do PeerSpot mostram um leve declínio ano a ano (13,7% para 9,8%) entre avaliadores de infraestrutura de IA empresarial, o que pode refletir incerteza nos negócios com a NVIDIA - vale monitorar.
Nossa opinião: não sabemos se os preços atuais são estruturalmente sustentáveis ou uma estratégia deliberada de land-and-expand antes dos chips de segunda geração. O que sabemos é que os preços têm sido estáveis ao longo de 2025–2026 e os $750M captados compram tempo. Use onde a relação preço-desempenho faz sentido; não se arquitete em uma dependência de provedor único que você não pode trocar.
Quem deve (e não deve) usar o Groq
Use o Groq quando:
- Você está construindo interfaces de voz ou chat em tempo real onde 280–1.000 TPS importa para a experiência do usuário
- Sua stack de modelos roda em Llama, Qwen, Whisper ou modelos open-weight da OpenAI
- Você precisa de transcrição barata em escala - Whisper Turbo a $0,04/hora é difícil de superar
- Você está prototipando - o nível gratuito cobre a maioria das cargas de trabalho de desenvolvimento sem cartão de crédito
- Você tem cargas de trabalho de lote assíncronas - o desconto de 50% da Batch API muda significativamente a economia
Procure alternativas quando:
- Você precisa de GPT-4o, Claude ou Gemini - não disponíveis no GroqCloud
- Você precisa de suporte multimodal robusto - o Llama 4 Scout está apenas em Preview
- Você precisa de implantação on-premises com termos de suporte padrão - o GroqRack requer negociações empresariais
- Você precisa de modelos proprietários ajustados - o fine-tuning com LoRA requer acesso empresarial
Para uma comparação mais ampla de recursos, nossa análise do Groq cobre o produto completo em profundidade. Se você ainda está avaliando provedores, alternativas ao Groq compara Together AI, Fireworks, Cerebras e outros nas mesmas dimensões de preço-desempenho.
Experimente o eesel para suporte ao cliente com IA
Se você está avaliando o Groq para suporte ao cliente ou automação de central de suporte, o eesel combina bem com ele. O eesel implanta agentes de IA autônomos diretamente dentro das suas ferramentas existentes - Zendesk, Freshdesk, Slack, e-mail - e direciona tickets de suporte para o modelo certo com base na complexidade. Consultas simples e de alto volume vão para um nível de modelo rápido e barato (exatamente para o que o Llama 8B e o GPT OSS 20B do Groq foram construídos); escalações complexas vão para um modelo de maior capacidade.
Equipes que lidam com mais de 100.000 tickets por mês usam agentes eesel que realmente resolvem problemas em vez de apenas desviá-los - sem nova interface para aprender, sem engenharia de prompt necessária. Você instrui o agente da mesma forma que integraria um novo funcionário, e ele cuida do resto.

Perguntas Frequentes
Quanto custa a API do Groq por 1M de tokens?
O Groq tem um nível gratuito?
Como os preços do Groq se comparam aos da OpenAI?
Quais são os limites de taxa do Groq no plano pago para desenvolvedores?
Os preços do Groq oferecem boa relação custo-benefício para cargas de trabalho em produção?

Article by
Rama Adi Nugraha
Rama is a software engineer at eesel AI with two years of experience writing about B2B SaaS, AI tools, and customer support technology. Based in Bali, Indonesia, he brings a developer's perspective to product comparisons — cutting through marketing copy to what the integrations and APIs actually do.








