
O que é o Qwen (e por que ele é diferente)
Qwen (通义千问) é a família de modelos de linguagem de grande porte da Alibaba Cloud - um catálogo vasto com mais de 145 IDs de modelos que abrangem texto, visão, áudio, código, tradução, geração de vídeo e embeddings, todos acessíveis sob uma única chave de API via Qwen Cloud / Alibaba Cloud Model Studio.
Três coisas o tornam incomum no mercado de LLM:
- Modelos de pesos abertos ao lado de modelos proprietários. Toda a série Qwen3 (de 0,6B a 235B-A22B) possui licença Apache 2.0 e está disponível no Hugging Face. Você pode rodar localmente, de graça, o mesmo modelo pelo qual pagaria na API.
- Arquitetura MoE domina o nível médio. Grande parte do preço competitivo do Qwen vem do design Mixture-of-Experts (MoE) - o modelo 235B-A22B ativa apenas 22B parâmetros por token, tornando seu custo de inferência semelhante ao de um modelo denso de 22B, apesar da escala total de 235B.
- Volume em uma escala que poucos provedores igualam. O Qwen3.6-Plus foi o primeiro modelo no OpenRouter a processar mais de 1T de tokens em um único dia - um sinal de como a adoção dos desenvolvedores migrou para a família Qwen.
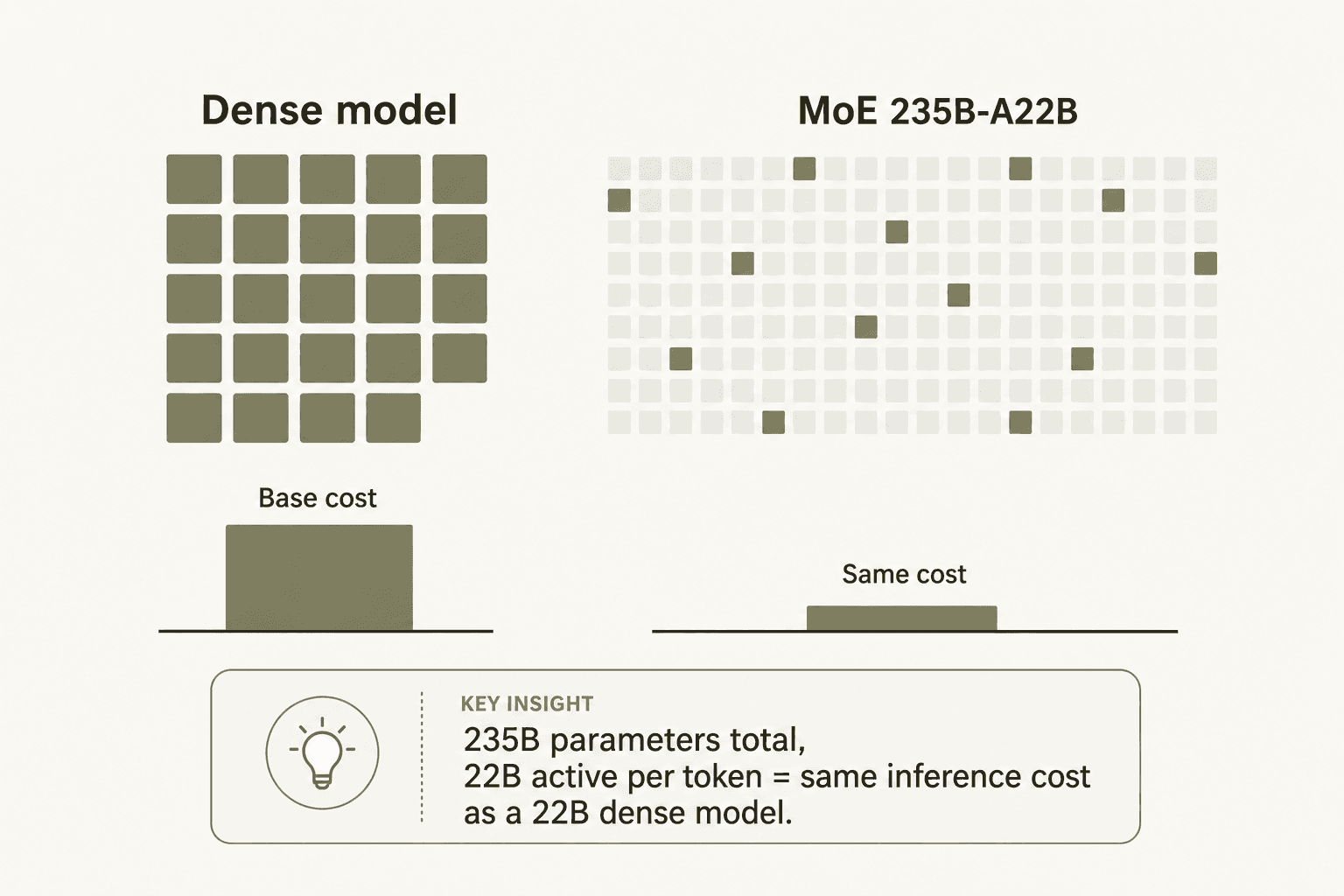
"O Design MoE: A maioria dos modelos MoE parece um remendo. A ativação esparsa do Qwen 3.5 é nativa - apenas 4,3% dos parâmetros são acionados por token. É assim que você obtém desempenho de classe de trilhões de parâmetros sem custos de inferência de trilhões de parâmetros. O preço de 0,8 RMB/milhão de tokens não é subsidiado; é conquistado estruturalmente."
Tabela completa de preços da API Qwen (2026)
Todos os preços em USD, pagamento conforme o uso (pay-as-you-go) no endpoint internacional (Alibaba Cloud Model Studio, ap-southeast-1). Preços obtidos nas páginas de detalhes dos modelos Qwen Cloud e PricePerToken.com (verificados em 3 de junho de 2026).
Modelos de geração de texto
| Modelo | Entrada $/1M | Saída $/1M | Contexto | Notas |
|---|---|---|---|---|
| Qwen3.7-Max | $1,25 | $3,75 | 1M tokens | 50% de desconto promo sobre $2,50/$7,50; apenas texto; lançado em 21/05/2026 |
| Qwen3.7-Plus | $0,32–$0,96 | $1,28–$3,84 | 1M tokens | Multimodal nativo; níveis por comprimento de contexto; lançado em 01/06/2026 |
| Qwen3-Max | $1,20 | $6,00 | 262K tokens | Otimizado para agentes; leitura de cache $0,12/1M |
| Qwen3.6-Plus | $0,50–$2,00 | $3,00–$6,00 | 1M tokens | Multimodal nativo; codificação agêntica; visual + texto |
| Qwen3.6-Flash | $0,25–$1,00 | $1,50–$4,00 | 1M tokens | Visão-linguagem otimizado para custo |
| Qwen3-235B-A22B | $0,70 | $2,80 / $8,40* | 131K tokens | Carro-chefe MoE de pesos abertos; *modo de pensamento |
| Qwen3-30B-A3B | $0,20 | $0,80 / $2,40* | 131K tokens | MoE equilibrado; *modo de pensamento |
| Qwen3-8B | $0,18 | $0,70 / $2,10* | 131K tokens | Denso pequeno; *modo de pensamento |
| Qwen-Max | $1,60 | $6,40 | 32K tokens | Alias de produção estável |
| Qwen-Plus | $0,40 | $1,20 / $4,00* | 1M tokens | Alias estável; *modo de pensamento |
| Qwen-Turbo | $0,05 | $0,20 / $0,50* | 131K tokens | Nível de texto mais barato; 5M TPM throughput; *modo de pensamento |
| Qwen3.5-0.8B | $0,01 | $0,05 | - | Piso absoluto; tarefas de microautomação |
*Saída do modo de pensamento cobrada à taxa mais alta quando enable_thinking: true
Modelos de visão-linguagem e multimodais
| Modelo | Entrada $/1M | Saída $/1M | Contexto |
|---|---|---|---|
| Qwen3-VL-Plus | $0,20 | $1,60 | 262K tokens |
Modelos de embedding
| Modelo | Preço |
|---|---|
| text-embedding-v3 / text-embedding-v4 | $0,07/1M tokens; $0,035/1M batch |
Modelos de geração de vídeo
| Modelo | Preço |
|---|---|
| Série HappyHorse-1.0 (T2V, I2V, R2V, edit) | $0,112/segundo |
| Wan2.7-T2V | $0,10/segundo |
As faixas de preço no Qwen3.7-Plus e na série Qwen3.6 refletem categorias de entrada em níveis - o custo por milhão de tokens aumenta à medida que o comprimento da entrada cresce em uma única solicitação (não uso cumulativo). A taxa de $0,32 se aplica a entradas curtas; $0,96 entra em vigor para solicitações de contexto longo no Qwen3.7-Plus.
Como o faturamento realmente funciona
Entender a tabela de preços é o primeiro passo. Entender como essas taxas se combinam em uma carga de trabalho real é onde as pessoas se surpreendem.
Modo de pensamento
Vários modelos da geração Qwen3 suportam um parâmetro opcional enable_thinking: true que aciona o raciocínio em cadeia antes da resposta final. Os tokens de pensamento são gerados internamente e depois faturados - a taxas normalmente 3 a 10 vezes superiores à saída padrão. No Qwen-Plus, por exemplo, a saída padrão custa $1,20/1M, mas a saída de pensamento custa $4,00/1M. No Qwen3-235B-A22B, a saída de pensamento salta de $2,80 para $8,40/1M.
Para a maioria das cargas de trabalho de produção - classificação, resumo, extração estruturada - o modo de pensamento é excessivo. Ative-o apenas para tarefas pesadas de raciocínio (revisão de código complexo, planejamento em várias etapas, matemática) e planeje o orçamento adequadamente.
Cache de prompt
O cache de prompt implícito é automático na maioria dos modelos Qwen: prefixos de contexto repetidos são armazenados em cache, e os acertos de cache são faturados a aproximadamente 20% da taxa de entrada padrão. Para o Qwen-Plus, isso é $0,08/1M em vez de $0,40/1M nas partes armazenadas em cache.
Também há gerenciamento de cache explícito disponível no Qwen3-Max e Qwen-Plus:
- Criação de cache: ~$0,50/1M (125% da taxa de entrada)
- Leitura de cache: ~$0,04/1M (10% da taxa de entrada)
O problema levantado consistentemente pela comunidade: o cache do Qwen funciona de forma menos confiável que o dos concorrentes. Um usuário do Reddit executou a mesma tarefa de revisão de código em quatro CLIs de IA e descobriu que o Qwen consumiu 23% de sua cota mensal de $30 em uma única tarefa - a mesma tarefa consumiu menos de 1% em planos comparáveis de $100 do Claude e $100 da OpenAI. O diagnóstico explícito: "Eles não parecem fazer cache tão bem quanto outros provedores de modelos."
Processamento em lote (Batch)
A API de lote assíncrona oferece aproximadamente 50% de desconto sobre as taxas padrão para cargas de trabalho que não precisam ser em tempo real. No Qwen3-Max, a entrada em lote cai de $1,20 para $0,60/1M; a saída em lote de $6,00 para $3,00/1M. Para pipelines de ETL, trabalhos de classificação em massa ou geração de relatórios noturnos, o modo batch é o padrão correto.
Planos de economia
A Alibaba Cloud oferece AI Savings Plans com redução de custo de até 47% via compromisso de uso. Existe também um AI Token Plan - créditos de assinatura fixa entre modelos - mas a experiência da comunidade com isso é mista (veja O que você realmente paga, abaixo).
O que você realmente paga na prática
Os preços de tabela e as faturas reais divergem. Aqui estão três exemplos práticos baseados em dados do mundo real.
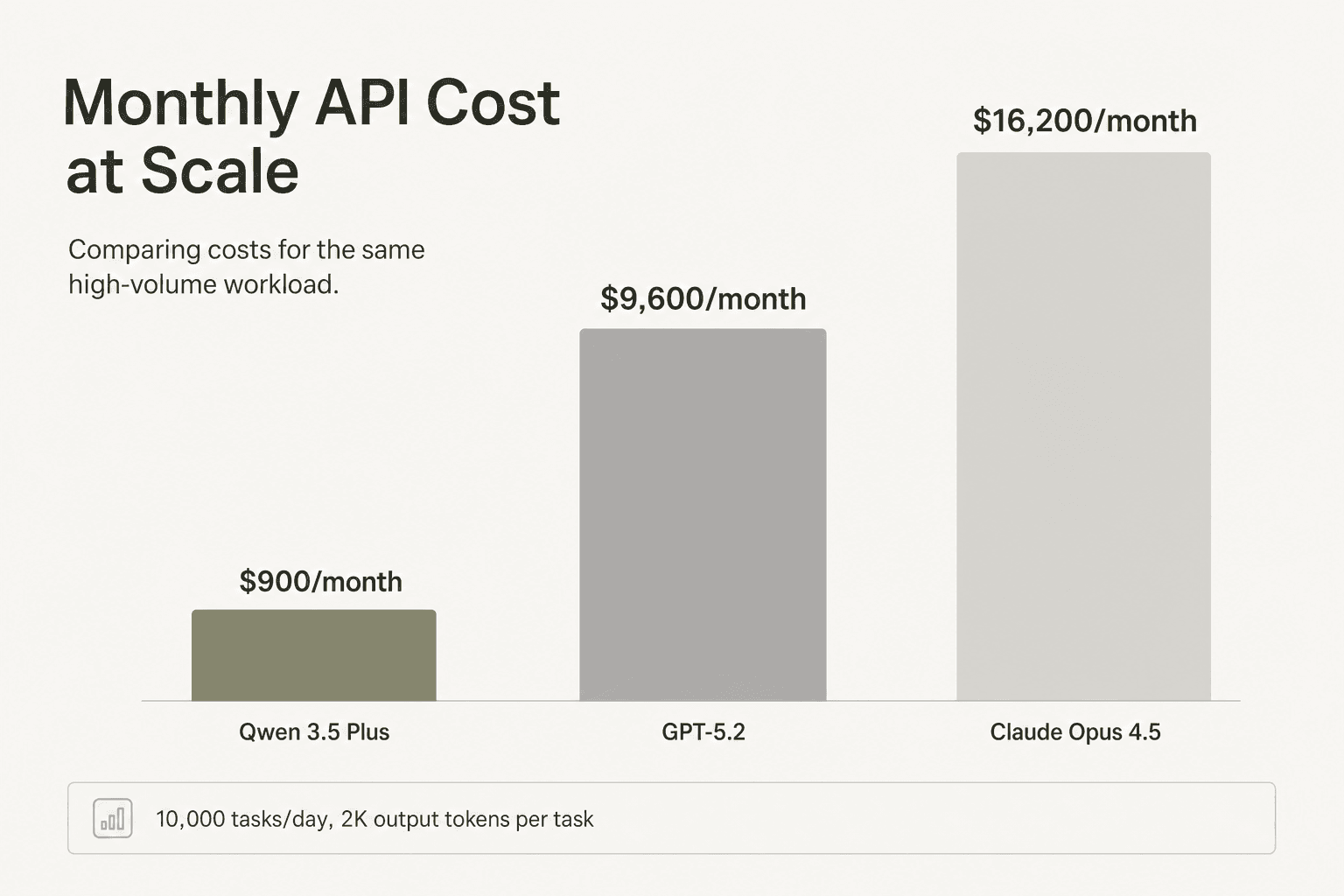
Exemplo 1: um pipeline de conteúdo com 10.000 tarefas/dia
A ChartGen AI comparou o Qwen 3.5 com o GPT-5.2 e o Claude Opus 4.5 em 20 tarefas de visualização de dados, cada uma exigindo cerca de 2K tokens de saída. A economia com 10 mil tarefas/dia:
| Modelo | Custo por tarefa | Custo diário | Custo mensal |
|---|---|---|---|
| Qwen 3.5-35B-A3B | ~$0,003 | ~$30 | ~$900 |
| GPT-5.2 | ~$0,032 | ~$320 | ~$9.600 |
| Claude Opus 4.5 | ~$0,054 | ~$540 | ~$16.200 |
O Qwen marcou 163/200 no benchmark contra 178/200 do GPT-5.2 - uma lacuna de qualidade de 9% para uma redução de custo de 10x.
A equipe da ChartGen também destacou o multiplicador multiagente:
"No pipeline da ChartGen AI, a geração de um único painel invoca o modelo 5 a 8 vezes... Nessa escala, você pode rodar 10 agentes Qwen 3.5 pelo preço de 1 chamada do GPT-5.2 - e usar votação por conjunto para exceder a precisão de qualquer modelo individual."
Steven Cen, ChartGen AI [Fonte]
Exemplo 2: o teste de infraestrutura do Intelligence Index
A Artificial Analysis submeteu o Qwen3.6 Plus ao seu benchmark completo Intelligence Index. Custo total:
- Qwen3.6 Plus: $483 (~100M tokens de saída a $0,50/$3,00)
- Claude Opus 4.6 (esforço máximo): $4.970
Essa é uma diferença de custo de 10x para uma lacuna de pontuação de inteligência de 2 pontos (o Qwen3.6 Plus marcou 51 contra 53 do Claude Opus 4.6 no índice deles). A ressalva: o Qwen gerou visivelmente mais tokens de saída por tarefa do que os pares, o que inflou os custos em comparação com um modelo menos verboso na mesma taxa por token.
Exemplo 3: o choque de preço do Token Plan
A oferta de assinatura mais recente do Qwen - o AI Token Plan - converte dólares em créditos de maneiras que confundiram muitos dos primeiros usuários. De um tópico no Reddit de maio de 2026:
"Eu assinei o plano de $30 (que oferece 25.000 créditos)... em apenas 4 horas de uso [com o Qwen 3.6 Plus], [consumi] aproximadamente 8.000 créditos (de um total de 25.000 créditos no plano de $30)."
A comparação direta do usuário qu1etus é negativa para o Token Plan especificamente:
"qwen3.7-max (usando qwen cli - plano de $30): usou 23% da minha cota mensal. gpt-5.5 xhigh (usando codex cli - plano de $100): usou <1% da cota mensal. opus 4.7 (usando claude code - plano de $100): usou <1% da cota mensal. Pelo custo, porém, estou fora. Eles não parecem fazer cache tão bem quanto outros provedores de modelos e seu modelo de precificação está quebrado."
A taxa bruta da API de pagamento conforme o uso é melhor do que a lógica do Token Plan sugere. Se você estiver comparando o Qwen com o Claude ou a OpenAI, atenha-se ao preço da API por token em vez dos níveis de planos de assinatura.
Níveis de preços do Qwen: escolhendo o modelo certo
Nem toda carga de trabalho precisa do nível Max. A decisão da arquitetura geralmente importa mais do que a geração do modelo.

Qwen-Turbo ($0,05/$0,20) - a escolha certa para classificação, roteamento, extração e qualquer carga de trabalho onde você precisa de throughput a baixo custo. Com limite de taxa de 5M de tokens por minuto, ele lida com pipelines de lote agressivos sem atingir limites. Um usuário do Reddit foi direto: "A sete centavos por milhão de tokens, parece trapaça."
Qwen3-30B-A3B ($0,20/$0,80) - a escolha equilibrada de MoE. O 30B-A3B ativa apenas 3B parâmetros na inferência, roda a ~137 tokens/segundo em uma única GPU H20 e cobre a grande maioria das tarefas de codificação e raciocínio que não precisam da capacidade do nível Max. Consenso da comunidade no r/LocalLLaMA: a variante MoE 35B-A3B roda 15x mais rápido que a densa de 27B por uma fração do custo - sempre escolha o MoE se houver um no tamanho desejado.
Qwen-Plus ($0,40/$1,20) - o alias de produção estável com 1M de contexto. Se você precisa de um ID de API previsível que não mude entre atualizações de modelos, é este. Modo de pensamento disponível a $4,00/1M de saída.
Qwen3.7-Plus ($0,32–$0,96/$1,28–$3,84) - a opção multimodal nativa com 1M de contexto e recursos de codificação agêntica. Boa opção para pipelines que misturam texto, imagem e chamada de ferramentas na mesma solicitação.
Qwen3-Max / Qwen3.7-Max ($1,20–$1,25 / $6,00–$3,75) - aproximando-se do território de preços de fronteira. A comunidade descobriu que a variante MoE Coder 480B muitas vezes faz mais sentido que o Max para codificação pesada a $1,50/$7,50, a menos que você precise especificamente da otimização de pipeline de agentes da arquitetura Max. Com o desconto de $1,25 para o Qwen3.7-Max, ele é competitivo com o preço do GPT-5 de nível médio - mas o desconto é listado como promocional.
A situação do nível gratuito em 2026
Esta é a parte que mais confunde as pessoas.
O que é gratuito: O aplicativo de chat para consumidores Qwen Studio - sem necessidade de login, sem limites de taxa comunicados, disponível para iOS, Android, macOS e web. Isso não vai acabar. A Alibaba tem fortes incentivos comerciais para manter o produto de consumo gratuito.
O que era gratuito e não é mais: O nível gratuito da API OAuth para desenvolvedores - que permitia 1.000 (depois 100) solicitações/dia via API - foi descontinuado em 15 de abril de 2026. O nível gratuito de 2.000 solicitações/dia para codificação do Qwen Code CLI também foi eliminado na mesma época. A reação da comunidade foi imediata:
"Para ser honesto, acabei de assinar o Claude. Fiz o Qwen criar arquivos .md de tudo para que o Claude pudesse continuar de onde parou."
u/ihateroomba, 3 upvotes
Um comentário analítico no Reddit explicou bem a distinção:
"É importante distinguir entre dois mundos distintos que coexistem na Alibaba: O mundo do 'Produto de Consumo' (Qwen Studio): O aplicativo que você usa no celular é um produto final. A Alibaba tem todo o interesse em mantê-lo gratuito... O mundo 'Desenvolvedor / API': É aqui que a política mudou... É uma estratégia clássica: atrair usuários com a versão gratuita e depois cobrar quando ela ganha escala."
O que ainda está disponível como teste gratuito: Novas contas do Alibaba Cloud Model Studio recebem mais de 70M de tokens gratuitos entre os modelos Qwen (1M de tokens por modelo), além de 1.650 segundos de crédito para geração de vídeo. Válido por 90 dias, apenas no endpoint de Cingapura. O endpoint dos EUA Virgínia não possui cota gratuita.
O preço base da auto-hospedagem
Há um número que as tabelas de preços da API não mostram: $0,00 por token, disponível para qualquer pessoa disposta a executar sua própria inferência.
Todos os modelos Qwen3 (de 0,6B a 235B-A22B) possuem pesos abertos Apache 2.0 e estão disponíveis no Hugging Face. @WolframRvnwlf testou a build quantizada Unsloth do Qwen3-30B-A3B em um MacBook Pro M4:
"A quantização Unsloth do 30B-A3B entregou 82,20% rodando localmente a ~45 tok/s e com zero gasto de API... Modelos 30B quantizados agora oferecem ~98% da precisão de classe de fronteira - por uma fração da latência, custo e energia."
vLLM e SGLang são os frameworks de auto-hospedagem recomendados; a documentação do Qwen3 inclui comandos completos de implantação. Para equipes que processam dados sensíveis ou operam em jurisdições onde a conformidade com nuvens de origem chinesa é um problema, a auto-hospedagem também resolve inteiramente a questão da residência dos dados.
A contrapartida: o custo do hardware é real. Um único nó de GPU H20 custa ~$3–5/hora em provedores de nuvem. Para cargas de trabalho moderadas (menos de alguns milhões de tokens/dia), a API provavelmente é mais barata do que computação dedicada. Mas em escala - ou com uma GPU que você já possui - a auto-hospedagem muitas vezes vence.
Qwen vs Claude vs GPT: a comparação honesta
A afirmação "Qwen é 9x mais barato que o Claude" é real, mas incompleta.
"A comparação de preços da API conta a história claramente. O Claude Opus 4.6 custa $5 de entrada e $25 de saída por milhão de tokens. O GPT-5.3 Codex custa $1,75 e $14. O Qwen 3.5 Plus custa $0,40 e $2,40. Isso não é uma diferença marginal. É uma mudança estrutural em quem pode pagar para construir com IA de nível de fronteira."
A nuance que a Artificial Analysis adiciona: os modelos Qwen geram mais tokens de saída por tarefa do que os pares. O Qwen3.5-27B usou 98M de tokens de saída para completar o benchmark Intelligence Index - significativamente mais alto que o MiniMax-M2.5 (56M) ou o DeepSeek V3.2 (61M). Se sua carga de trabalho gera saídas longas, a verbosidade dos tokens compensa parcialmente o desconto por token.
A análise de Rishabh Choudhary no LinkedIn sobre o Qwen3.6-Plus define a questão central:
"Ele marcou 78,8 no SWE-bench Verified... o Claude Opus 4.5 marcou 80,9. É uma diferença de 2 pontos. A diferença de preço? Não é de 2 pontos. É mais como 17x... A questão não é se os modelos chineses estão alcançando os outros. Eles claramente estão. A questão é se as lacunas de qualidade restantes importam o suficiente para justificar pagar 17x mais. Para muitos casos de uso, acho que a resposta honesta está se tornando 'não'."
As ressalvas de profissionais que rodaram o Qwen em produção também merecem ser levadas a sério. Dos comentários desse mesmo post no LinkedIn: uma latência de 11 segundos para o primeiro token no nível de visualização gratuita (um problema para loops de agentes de várias etapas onde o tempo de espera se acumula) e uma taxa relatada de 26% de alucinação em raciocínio de código em testes de produção que "exige uma camada de verificação que devolve parte da economia de custos que você está obtendo nos tokens".
Para uma comparação direta com as alternativas mais populares, veja o preço do Claude, preço do Gemini e o preço do Mistral AI.
Contexto de benchmark
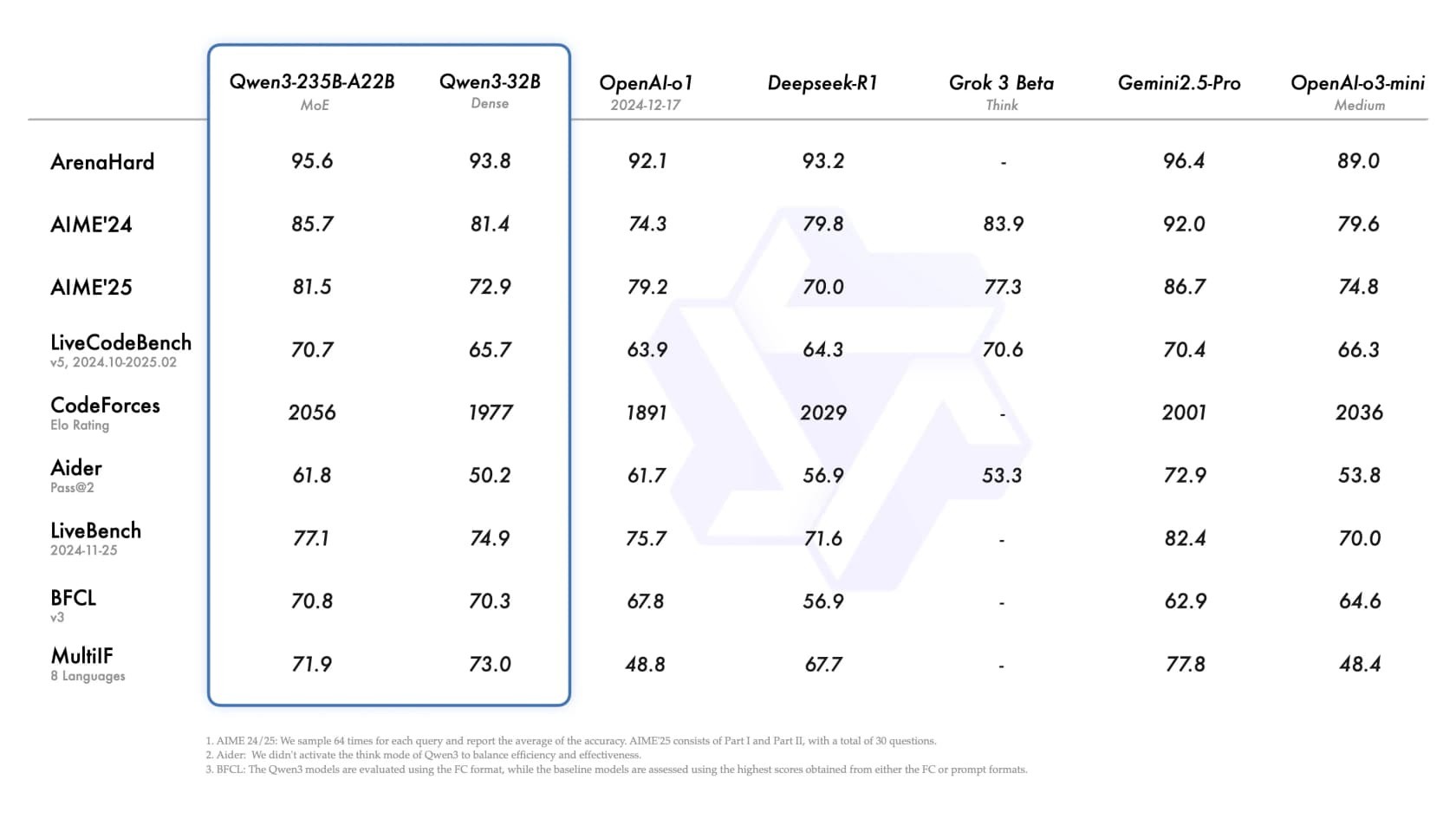
O carro-chefe Qwen3-235B-A22B MoE compete diretamente com o OpenAI o1, DeepSeek-R1 e Gemini 2.5 Pro em benchmarks públicos - ArenaHard 95,6, AIME'24 85,7, LiveCodeBench 70,7, BFCL 70,8. A $0,70/$2,80 por 1M de tokens (padrão), ele supera a maioria desses modelos no preço, mantendo a pontuação. A disponibilidade de pesos abertos significa que você também pode baixar e rodar você mesmo sem qualquer dependência de API.
O sinal de downloads de código aberto é revelador: o Qwen ocupa 7 das 10 primeiras posições nos rankings de downloads de modelos abertos do Hugging Face, de acordo com Nathan Lambert (pesquisador de ML), com o Qwen2.5-7B-Instruct atingindo 52,4M de downloads e várias variantes do Qwen3 no top cinco. Esse nível de adoção cria ferramentas comunitárias, builds quantizadas e integrações de ecossistema que tornam a auto-hospedagem cada vez mais acessível.
Acesso à API: como começar
A API internacional roda no Alibaba Cloud Model Studio. Ela é compatível com a OpenAI, o que significa que trocar o SDK da OpenAI pelo do Qwen costuma ser uma alteração de duas linhas - URL base e chave de API.
from openai import OpenAI
client = OpenAI(
base_url="https://[workspace-id].ap-southeast-1.maas.aliyuncs.com/compatible-mode/v1",
api_key="sua-chave-api-dashscope"
)
Regiões disponíveis: Sudeste Asiático (principal), Frankfurt (desde 20/03/2026) e Hong Kong (desde 17/03/2026). O endpoint de Virgínia, nos EUA, está disponível, mas não oferece cota de teste gratuito.
Os limites de taxa são 600 RPM / 1M TPM para a maioria dos modelos; o Qwen-Turbo opera com limites maiores, de 5M TPM, sendo a escolha certa para pipelines de alto volume e picos de demanda. Contas empresariais podem solicitar aumento de cota via ticket de suporte.
Quem realmente está adotando o Qwen e quem está esperando
A adoção por desenvolvedores é forte - o domínio de downloads no Hugging Face e o volume de tokens no OpenRouter tornam isso inegável. A NVIDIA endossou oficialmente o Qwen 3.5 no dia do lançamento, direcionando desenvolvedores para o caminho de construção NeMo.
A adoção empresarial é uma história diferente. Como observou um comentarista no LinkedIn:
"Para nossos clientes da Fortune 500 / corporativos, os modelos mais usados são: 1. Gemma 2. Mistral 3. GPT-OSS 4. Llama... Alguns de nossos clientes corporativos visionários estão começando a usar o Qwen, mas ainda não são a maioria."
Andrew Jardine, IA empresarial [Fonte]
Os impedimentos citados: revisões de conformidade de origem chinesa em indústrias regulamentadas (serviços financeiros, saúde, governo) e a latência nos endpoints de visualização gratuita. A série Qwen3 possui certificação ISO 27001 na API paga, mas muitas revisões de segurança corporativa exigem aprovação adicional sobre residência de dados e registro de acesso ao modelo antes que a aquisição possa prosseguir. A auto-hospedagem contorna a maior parte disso.
Para equipes fora dessas restrições de conformidade - especialmente startups, desenvolvedores de SaaS de médio porte e operadores de pipelines agênticos sensíveis a custos - a economia é indiscutível.
Experimente o eesel
Se você executa fluxos de trabalho impulsionados por IA em escala e os custos de tokens importam, vale a pena conhecer o eesel. Ele implementa agentes de IA autônomos diretamente nas ferramentas que sua equipe já usa - Zendesk, Slack, Freshdesk, e-mail, Shopify - sem exigir uma nova interface ou assinatura por usuário. Você paga por tarefa ($0,40 por ticket resolvido, $4,00 por rascunho de post de blog), e os agentes pausam automaticamente quando você atinge seu limite de gastos. O modelo de preços contorna completamente a sobrecarga de contagem de tokens. Comece com $50 de crédito gratuito, sem necessidade de cartão.

Perguntas Frequentes
Quanto custa o Qwen por milhão de tokens?
O Qwen ainda é gratuito em 2026?
Como o preço do Qwen se compara ao ChatGPT e Claude?
O que é o modo de pensamento do Qwen e como ele é cobrado?
enable_thinking: true que ativa o raciocínio em cadeia (chain-of-thought). Os tokens de saída de pensamento são cobrados a uma taxa mais alta do que a saída padrão - normalmente 3-10x. Por exemplo, o Qwen-Plus cobra $1,20/1M para saída padrão, mas $4,00/1M para saída de pensamento. Os tokens de entrada padrão são cobrados à mesma taxa, independentemente de o pensamento estar ativado ou não.








