
Resumo
AA-Briefcase é um novo benchmark da Artificial Analysis que avalia modelos de IA em trabalho do conhecimento real de várias semanas (modelos financeiros, apresentações para o conselho, especificações de produto) em vez de perguntas isoladas. Cada modelo recebe milhares de arquivos bagunçados (e-mails, threads do Slack, planilhas) e deve produzir entregáveis reais, que são pontuados por correção, qualidade analítica e apresentação.
O achado principal é revelador: mesmo o melhor modelo passa em todos os critérios da rubrica em apenas 3% das tarefas, e em 31 de 91 tarefas nenhum modelo ultrapassa 50%. O Claude Fable 5 lidera o ranking, com o open-weight GLM-5.2 rendendo muito acima de seu preço.
Aqui está a parte que a maioria das coberturas omite: uma alta pontuação no benchmark diz que um modelo é capaz em geral, não que é seguro com seus dados. Essa lacuna é a razão exata pela qual acredito que qualquer um que procure atendimento ao cliente com IA deveria testar com seu próprio trabalho histórico antes de ir ao ar, em vez de simplesmente confiar em um leaderboard.
Eu construo agentes de IA profissionalmente no eesel, então um benchmark que finalmente mede trabalho real bagunçado em vez de trivialidades é o tipo de coisa que me faz largar tudo para ler. Abaixo está o que o AA-Briefcase realmente mede, como ele avalia, quem está ganhando e a única lição que levaria dele para qualquer implantação de agente de IA.
O que o AA-Briefcase realmente mede
A maioria dos benchmarks de IA faz perguntas curtas e autocontidas: um problema de matemática, um quebra-cabeça de programação, um questionário de múltipla escolha. Isso é bom para medir raciocínio bruto, mas não se parece nada com como as pessoas realmente usam esses modelos no trabalho. O trabalho do conhecimento real é longo, ambíguo e enterrado em bagunça.
O AA-Briefcase foi construído para fechar essa lacuna. Em vez de um prompt, cada modelo é colocado em um projeto empresarial de várias semanas com muitas tarefas vinculadas e milhares de arquivos-fonte, e solicitado a produzir o tipo de entregáveis que um analista ou PM real produziria: modelos financeiros, apresentações para o conselho, maquetes de design, memorandos de estratégia. Os cenários foram desenvolvidos ao longo de meses por especialistas do setor de empresas como Google, McKinsey e Boston Consulting Group, então o trabalho se assemelha ao que essas empresas realmente fazem.
Os números dão uma ideia da escala. Há quatro cenários de projeto reservados e 91 tarefas no total, extraídas de ciência de dados, gestão de produtos e estratégia corporativa. Neles existem quase 2.000 arquivos-fonte, incluindo mais de 3.500 e-mails e 25.000 mensagens do Slack, deliberadamente fragmentados e cheios de contradições realistas. Os quatro cenários de pontuação são um projeto de Ciência de Dados, um projeto de Gestão de Produtos, uma transformação de Operações Bancárias e um projeto de Estratégia de Indústria Pesada; um quinto cenário de Due Diligence é público e não conta para as pontuações.
Esse enquadramento importa porque espelha o modo de falha de cada agente de IA que já implantei: o modelo raramente luta com a ideia, luta em encontrar o requisito oculto no arquivo 1.400 sem contradizer o e-mail que o substituiu silenciosamente.
Como o AA-Briefcase avalia um modelo
Aqui é onde o AA-Briefcase fica inteligente. Uma pontuação única esconderia a coisa mais interessante sobre a produção de IA, que é que parecer profissional e estar correto são duas habilidades completamente diferentes. Então cada tarefa é avaliada em três dimensões separadas.
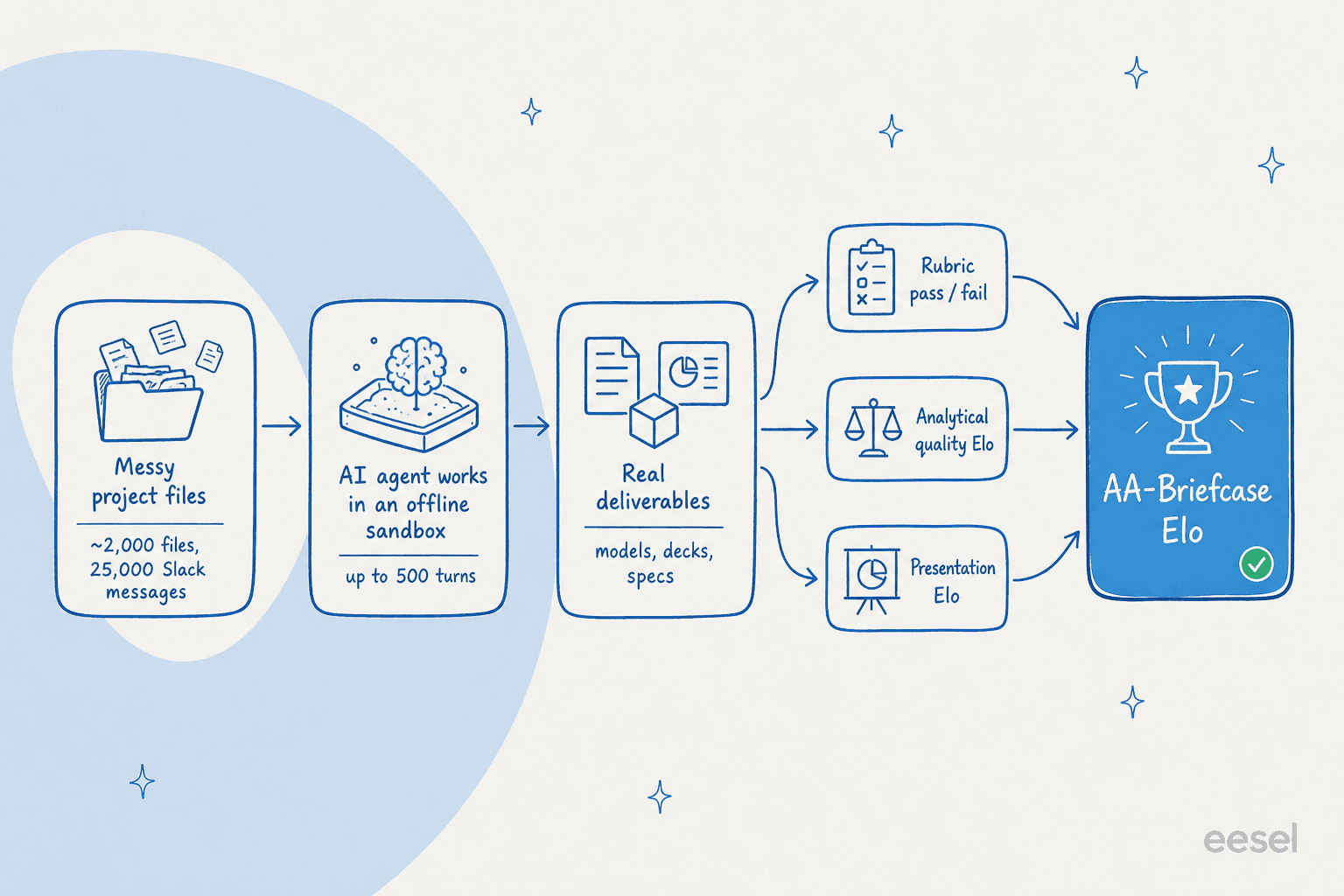
A primeira é uma rubrica binária: aprovado ou reprovado em cada verificação, sem crédito parcial. O modelo seguiu as instruções, encontrou os requisitos dispersos entre arquivos, usou as evidências corretas e chegou à conclusão correta? A segunda é qualidade analítica, julgada por comparação por pares com a entrega de outro modelo: qual entregável é mais completo e melhor embasado? A terceira é apresentação, também por pares: qual resultado está mais profissionalmente estruturado?
Esses três se combinam em um número principal único, o Elo do AA-Briefcase, que mistura Elo de qualidade analítica, Elo de apresentação e taxa de aprovação da rubrica usando agregação Elo de máxima verossimilhança. Para evitar que qualquer família de modelos se avalie favoravelmente, cada comparação é decidida por um painel de três juízes: Claude Opus 4.8, GPT-5.5 e Gemini 3.1 Pro Preview.
A infraestrutura também é aberta. Os modelos rodam no Stirrup, o harness de agente de código aberto da Artificial Analysis, dentro de um sandbox offline sem internet, por até 500 turnos por tarefa. É uma configuração genuinamente exigente e está consideravelmente mais próxima de um fluxo de trabalho agêntico real do que uma janela de chat.
O que os resultados realmente dizem
O leaderboard acima conta a história feliz (Claude Fable 5 na frente, níveis de capacidade ordenadamente empilhados). A história mais difícil está nas taxas de aprovação.
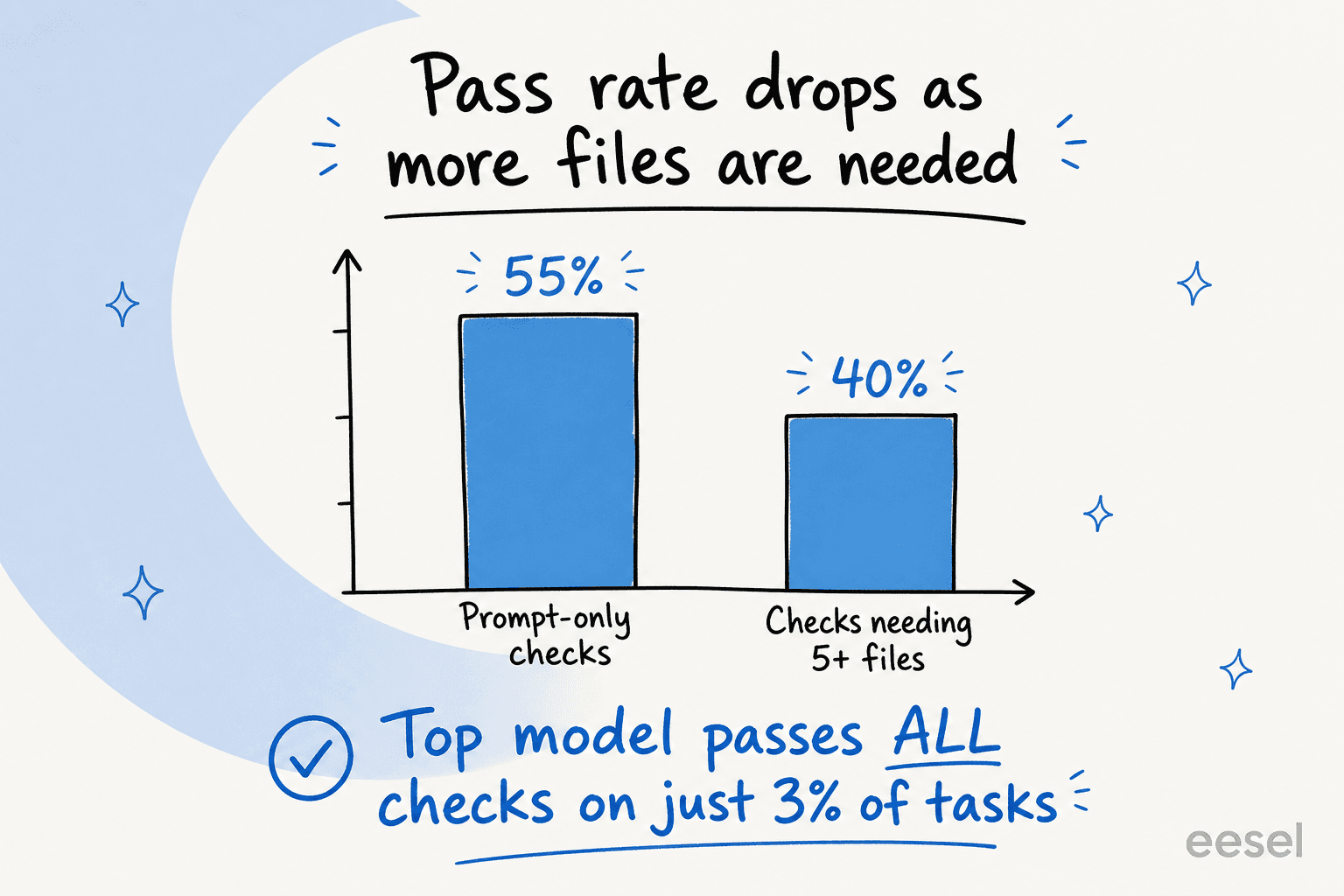
Mesmo o modelo líder satisfaz todos os critérios da rubrica em apenas 3% das tarefas, e em 31 das 91 tarefas nenhum modelo pontua acima de 50%. A dificuldade também escala com o número de arquivos necessários: modelos de alta inteligência caem de cerca de 55% em verificações apenas de prompt para aproximadamente 40% quando uma tarefa precisa de cinco ou mais. Quanto mais uma tarefa parece trabalho real, pior todos se saem.
O leaderboard tem algumas conclusões que valem a pena destacar. O GLM-5.2 é o claro líder de peso aberto e o destaque em preço/desempenho, ficando aproximadamente 90 Elo abaixo do Claude Opus 4.8 por menos de um quarto do custo. MiniMax-M3 e GLM-5.2 ambos superam suas pontuações de inteligência geral, enquanto os modelos Gemini do Google na verdade rendem menos no AA-Briefcase comparado a onde se situam nos rankings de inteligência ampla. E como a visualização de custo no widget mostra, a diferença entre o modelo mais caro e o mais barato supera 800×, o que é um lembrete útil quando se pondera o custo real de um agente de IA contra as métricas que realmente importam.
O problema de "parece certo mas está errado"
Minha descoberta favorita de toda a publicação é comportamental, e explica muito sobre por que o trabalho de IA pode parecer não confiável.
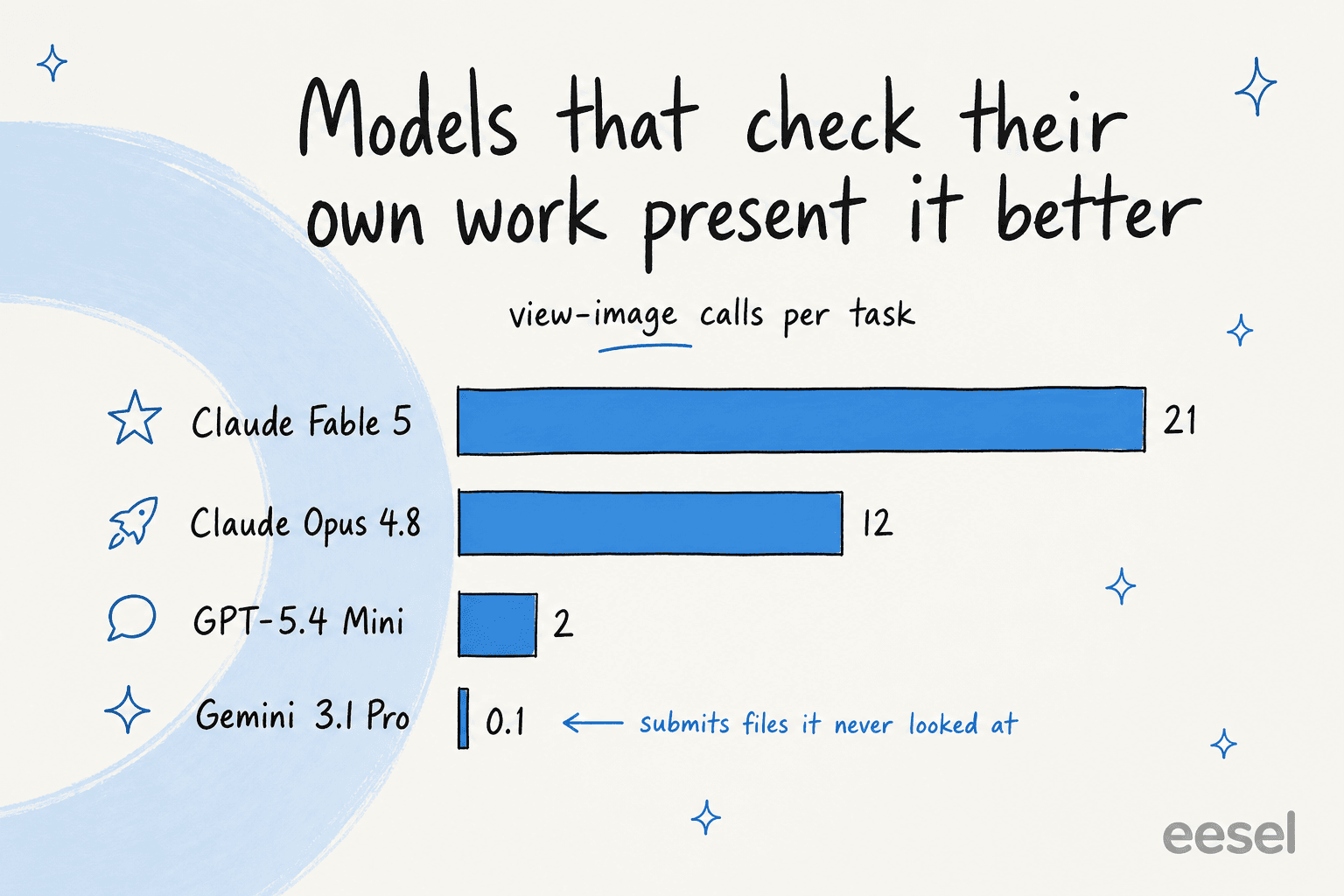
Os modelos que melhor pontuam em apresentação são os que realmente olham para seu próprio resultado renderizado. Claude Fable 5 fez cerca de 21 chamadas view-image por tarefa e Opus 4.8 cerca de 12, enquanto alguns modelos enviaram arquivos que mal tinham examinado (Gemini 3.1 Pro Preview com média de aproximadamente 0,1 chamadas view-image). Acontece que "verifique seu trabalho antes de entregá-lo" é um conselho tão bom para uma IA quanto para uma pessoa.
Há um ponto mais profundo por baixo. O AA-Briefcase separa o polimento da correção precisamente porque uma resposta confiante e bem formatada que está silenciosamente errada é mais perigosa do que uma que é obviamente incompleta. Esse é o risco exato que aparece quando um chatbot de IA responde a um cliente, e é por isso que prevenir alucinações é o ponto central no suporte, não um extra agradável.
Por que uma pontuação no leaderboard não é um plano de implantação
Então um modelo de fronteira pode fazer trabalho do conhecimento real, às vezes de forma brilhante, e ainda falhar na maioria das vezes nas tarefas mais difíceis e com mais arquivos. Se você levar uma coisa do AA-Briefcase, leve isso: uma posição no benchmark é um sinal de capacidade geral, não uma promessa sobre como um modelo se comporta nos seus dados bagunçados específicos.
Eu vi isso acontecer em primeira mão. Passamos anos colocando agentes de IA em filas de suporte ao vivo, e o que afeta as equipes não é se o modelo subjacente é inteligente o suficiente em abstrato, é se ele permanece preciso nos seus tickets específicos, nas peculiaridades do seu produto e nos seus casos extremos. Um modelo que lidera todos os leaderboards públicos ainda pode citar com confiança sua política de reembolso de forma incorreta no primeiro dia, muito antes de chegar à resolução automatizada de tickets. Isso não é uma crítica ao modelo; é a diferença entre um benchmark e a produção.
A solução é o mesmo instinto sobre o qual o AA-Briefcase é construído: avalie o trabalho contra a verdade antes de confiar nele. Para um helpdesk, isso significa executar a IA contra seus próprios tickets históricos e ver exatamente o que ela teria respondido, em vez de ler uma ficha técnica e esperar. Pense nisso como executar seu próprio AA-Briefcase privado, onde o conjunto de testes é seu histórico de suporte real.
Experimente o eesel para suporte de IA em que você pode realmente confiar
Se o AA-Briefcase te convenceu de que capacidade e confiabilidade não são a mesma coisa, esse é exatamente o problema em torno do qual o eesel AI foi construído. O eesel funciona como um novo membro da equipe de suporte que se conecta ao seu helpdesk e base de conhecimento existentes em minutos, depois permite que você simule-o em milhares de seus tickets passados antes que ele jamais fale com um cliente, para que você veja sua taxa de resolução real e respostas exatas antecipadamente em vez de adivinhar em um leaderboard.

Você mantém o controle do que é permitido responder e quando escala, e é gratuito para testar com seus próprios dados. Se você está avaliando IA para atendimento ao cliente, essa abordagem de simular primeiro é o mais próximo de trazer o rigor de "prove no trabalho real" do AA-Briefcase para sua própria fila.
Perguntas frequentes
O que é o benchmark AA-Briefcase?
Qual modelo de IA é melhor no AA-Briefcase?
Como o AA-Briefcase é pontuado?
Por que os modelos de IA pontuam tão baixo no AA-Briefcase?
Uma alta pontuação no AA-Briefcase significa que o modelo é seguro para implantar?
Como o AA-Briefcase é diferente de outros benchmarks de IA?
Posso usar o AA-Briefcase para escolher uma ferramenta de IA para o suporte ao cliente?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.








