2026年におけるZendesk Guideのファセットと検索フィルターの活用方法
Stevia Putri
最終更新 February 25, 2026
顧客がヘルプセンターにアクセスするとき、通常はすでに不満を感じています。彼らは問題を抱えており、答えを求めており、記事を掘り下げるのに費やすすべての秒が彼らの忍耐を試します。そこで、Zendesk Guide のファセットと検索フィルターが登場します。これらは単に便利な機能ではありません。迅速なセルフサービスによる解決と、キューを詰まらせる別のサポートチケットとの違いです。
このガイドでは、Zendesk Guideのファセット検索フィルターについて知っておくべきことをすべて解説します。それらがどのように機能するか、どのように設定するか、そして顧客が必要なものをより早く見つけられるようにヘルプセンターを最適化する方法について説明します。また、eesel AI のようなAIチームメイトが、記事へのリンクを返すだけでなく、質問に直接答えることで、検索設定をどのように補完できるかについても見ていきます。
Zendesk Guideのファセットと検索フィルターとは?
基本から始めましょう。フィルターとファセットはどちらも、ユーザーが検索結果を絞り込むのに役立ちますが、動作が異なります。
フィルター(Filter) は、特定の条件に基づいて結果を絞り込むために使用されます。Zendesk Guideで、ユーザーが検索してから「記事のみ」または「コミュニティ投稿のみ」を選択すると、フィルターを使用していることになります。フィルターは通常、バイナリ選択(含める/除外する)であり、結果セットをすぐに削減します。
ファセット(Facet) は、共通の属性に従って結果を分類するために使用されます。類似のアイテムをグループ化し、ユーザーが関連コンテンツをナビゲートできるようにします。Zendesk Guideでは、ファセットは、検索結果とともに表示される「カテゴリ」や「トピック」のようなフィルタリング可能なカテゴリとして表示されます。
ここに重要な違いがあります。フィルターは表示からコンテンツを削除しますが、ファセットはコンテンツを整理してナビゲートしやすくします。どちらも精度を向上させますが、ファセットは、ユーザーが探しているものが正確にわからず、関連コンテンツを探索する必要がある場合に特に役立ちます。
ヘルプセンターでは、ユーザーは最初にコンテンツタイプ(記事とコミュニティ投稿)でフィルタリングし、次にカテゴリまたはトピックでフィルタリングできます。コンテンツタイプが通常最も広い区別であるため、この階層的なアプローチは理にかなっています。公式の回答を探している人は、フォーラムのディスカッションではなく、記事を求めています。
コンテンツの構成とファセットの可用性の関係は直接的です。記事がカテゴリ化またはラベル付けされていない場合、ユーザーに表示されるフィルタリングオプションは少なくなります。これは、内部コンテンツ構造が顧客の検索エクスペリエンスに直接影響することを意味します。
ファセットを使用するネイティブ検索方法
Zendesk Guide は、4つの異なる検索方法を提供しており、それぞれに異なるファセットおよびフィルター機能があります。
インスタント検索(Instant search) は、誰かがヘルプセンターの検索ボックスに入力を開始するとすぐに開始されます。記事のタイトルに対してのみ、部分的な単語の一致を使用します。利点は速度です。結果はすぐに表示され、多くの場合、ユーザーが考えを終える前に表示されます。短所は範囲です。インスタント検索では、記事の本文、ラベル、またはコミュニティ投稿は検索されず、ファセットやフィルターは提供されません。
ネイティブヘルプセンター検索(Native help center search) は、ユーザーがEnterキーを押すとアクティブになります。これは、記事のタイトル、本文、およびラベルをスキャンする完全な単語検索です。結果は、各結果の横に投票数とコメント数が表示された専用の検索結果ページに表示されます。ここでは、ファセットが最も重要です。ユーザーは、コンテンツタイプ(ナレッジベースの記事とコミュニティ投稿)で結果をフィルタリングし、次にカテゴリまたはトピックでフィルタリングできます。
記事の提案検索(Article suggestion search) は、エンドユーザーがサポートリクエストの送信を開始するとアクティブになります。件名フィールドに入力すると、Zendeskはタイトル、コンテンツ、およびタグに基づいて関連する記事を提案します。提案では、関連性スコアを使用して結果を並べ替えます。ここでの目標は、チケットの削減です。ユーザーが提案された記事をクリックして回答を見つけた場合、チケットは作成されません。
コンテキストパネルのナレッジ(Knowledge in the context panel) は、エージェント向けです。チケットのコンテキストパネルには、チケットのコンテンツに基づいて関連する記事を自動的に提案するナレッジセクションが含まれています。エージェントは手動で検索し、応答でコンテンツを直接リンクまたは引用することもできます。
ファセットは、ユーザーが最初からやり直すことなく、広範な結果セットを絞り込むのに役立つため、これらすべての方法で精度を向上させます。その速度は、顧客満足度とチケットの削減に直接つながります。
Zendesk Guideで検索ファセットを設定する方法
ファセットを適切に機能させるには、いくつかの設定が必要です。ヘルプセンターのZendesk Guideファセット検索フィルターを設定する方法を次に示します。
前提条件: ほとんどの検索機能は、Zendesk Guideでデフォルトで利用できますが、高度なカスタマイズにはGuide ProfessionalプランまたはEnterpriseプランが必要です。セマンティック検索は2023年にすべてのお客様に展開されました。生成検索には、ProfessionalプランまたはEnterpriseプランとテーマ設定が必要です。
ステップ1:コンテンツ構造を整理します。 ファセットは、カテゴリとセクションの階層に基づいて構築されています。顧客が製品についてどのように考えているかに一致する、明確で論理的なカテゴリを作成します。過度に技術的な内部用語は避けてください。顧客が「請求」と「アカウント設定」について考えている場合は、内部部門名ではなく、これらのラベルを使用します。
ステップ2:記事に一貫したラベルを適用します。 ラベルは、追加のファセットディメンションとして機能します。関連コンテンツ全体で一貫して使用します。たとえば、払い戻しに関するすべての記事に「払い戻し」または「返品」のラベルを付けて、グループ化できるようにします。一貫性が重要です。1つの記事に「払い戻し」というラベルが付けられ、別の記事に「返品」というラベルが付けられている場合、ファセットフィルターに一緒に表示されません。
ステップ3:ファセット表示のテーマ設定を構成します。 カスタムテーマを使用している場合は、検索結果にファセットが表示される方法を調整する必要がある場合があります。デフォルトのコペンハーゲンテーマはこれを自動的に処理しますが、カスタムテーマでは、ファセットを適切に表示するために更新が必要になる場合があります。
ステップ4:さまざまなユーザータイプで検索動作をテストします。 ログアウトしたユーザー、ログインした顧客、およびエージェントとして検索します。記事の表示設定に基づいて、各ロールで異なる結果が表示される場合があります。各ユーザータイプでファセットフィルターが正しく機能していることを確認してください。
多言語ヘルプセンターの場合は、有効になっているすべてのロケールでカテゴリとラベルが一貫して翻訳されていることを確認してください。分析ダッシュボードを使用すると、ロケールでフィルタリングして、言語によって検索動作がどのように異なるかを確認できます。
高度な検索構文と演算子
基本的なファセットを超えて、Zendesk Support は、演算子とプロパティベースのキーワードを使用した高度な検索機能を提供します。これは、パワーユーザー(および管理者)が必要なものを正確に特定できる場所です。
プロパティベースのキーワードを使用すると、検索を特定のデータフィールドに制限できます。
| キーワード (Keyword) | 目的 (Purpose) | 例 (Example) |
|---|---|---|
type: | 特定のレコードタイプを検索 (Search specific record types) | type:ticket または type:article |
status: | チケットのステータスでフィルタリング (Filter by ticket status) | status:open または status:solved |
tags: | タグで検索 (Search by tags) | tags:vip または tags:refund |
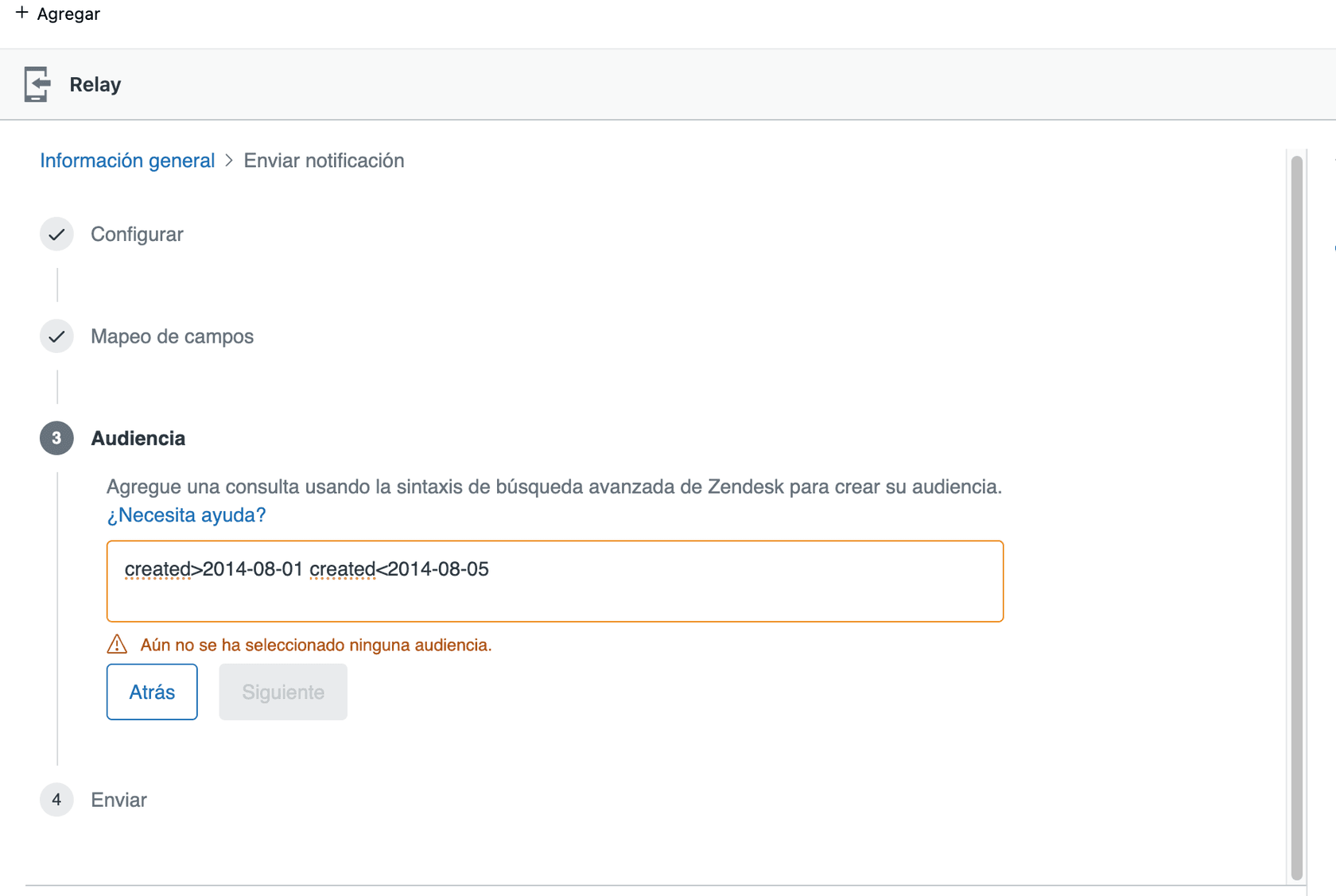
created: | 作成日でフィルタリング (Filter by creation date) | created>2026-01-01 |
assignee: | 担当者でチケットを検索 (Find tickets by assignee) | 割り当てられていない場合は assignee:none |
priority: | 優先度レベルでフィルタリング (Filter by priority level) | priority:high |
演算子は、これらのキーワードの動作を変更します。
:等しい (equals) (status:open)<より小さい (less than) (created<2026-01-01)>より大きい (greater than) (priority>normal)-除外 (excludes) (-tags:invoice)*ワイルドカード (wildcard) (subject:photo*)" "正確なフレーズ (exact phrase) ("upgrade my account")
複数の条件を組み合わせて、複雑なクエリを作成できます。たとえば、type:ticket status:open tags:vip created>7days は、過去1週間に作成されたVIPとしてタグ付けされたすべてのオープンチケットを検索します。
日付検索は相対時間もサポートしています:created>4hours または updated<2days。これは、正確な日付を指定せずに最近のアクティビティを見つけるのに役立ちます。
高度な検索が時間を節約できる一般的なシナリオを次に示します。
- 過去1週間に作成されたVIP顧客からのすべてのチケットを検索する
- 更新が必要な「非推奨」のタグが付いた記事を見つける
- 48時間以上経過した未割り当てのチケットを特定する
- アカウント固有の問題について、
customer_id:12345のようなカスタムフィールドを検索する
構文は予測可能なパターンに従います:property:value。利用可能なプロパティを学習すると、手動で見つけるのに数分かかる複雑なクエリを作成できます。
Zendesk分析で検索パフォーマンスを分析する
Zendeskには、分析セクションに組み込みの検索ダッシュボードが含まれています。ここは、検索行動について推測する段階から、ユーザーが正確に何を探しているかを知る段階に移行する場所です。
ヘッドラインメトリックは、一目で状況を伝えます。
- 合計検索数(Total searches): 検索アクティビティの量
- 結果なしの検索数(Searches with no results): 埋める必要のあるコンテンツのギャップ
- 平均クリック率(Average click-through rate): ユーザーが必要なものを見つける頻度
- 作成されたチケット数(Tickets created): 検索とサポートボリュームの相関関係
ダッシュボードを使用すると、時間、ブランド、検索チャネル、ユーザーロール、およびロケールでフィルタリングできます。あるユーザーセグメントの結果なしの割合が高い場合、別のユーザーセグメントでは許容できる可能性があるため、これは重要です。
実際の最適化の機会は、結果なしの検索にあります。ユーザーが何かを検索して結果がゼロになった場合、それはシグナルです。コンテンツが不足しているか、タイトルが顧客が実際に使用する単語と一致していません。これらの失敗した検索をマイニングすると、作成または更新する記事の優先順位付けされたリストが得られます。
また、検索ボリュームがチケットの作成と相関しているかどうかを追跡することもできます。検索が急増し、チケットも急増している場合、ヘルプセンターは人々が抱いている質問に答えていません。検索が急増してもチケットが横ばいの場合、コンテンツは役割を果たしています。
拡張検索ソリューションを検討する時期
ネイティブのZendesk検索は多くのチームでうまく機能しますが、それを使い果たしたことを示す兆候があります。
- 結果なしの割合が高い(High no-results rate): 検索の20%以上が何も返さない場合、コンテンツ戦略または検索テクノロジーの支援が必要です
- 複雑なコンテンツライブラリ(Complex content libraries): 複数のプラットフォーム(Zendesk、Confluence、SharePoint)にコンテンツがある場合、フェデレーション検索が不可欠になります
- 結果のキュレーションの必要性(Need for result curation): 特定のクエリに対して特定の記事を手動でブーストしたい場合があります
- 高度な分析要件(Advanced analytics requirements): Zendeskの組み込みダッシュボードが提供するよりも深い洞察が必要な場合
Swiftype のようなサードパーティのオプションは、これらのギャップに対処します。Swiftypeは、ヘルプセンター、フォーラム、およびFAQ全体でドラッグアンドドロップの結果ランキングとフェデレーション検索を提供します。価格は、Standardプランで月額79ドルから始まり、クロスドメイン検索やPDFインデックス作成などの追加機能については、Proで月額199ドルです。
ここで状況が面白くなります。ネイティブであろうとサードパーティであろうと、従来の検索は同じパターンに従います。ユーザーが検索し、システムがリンクを返し、ユーザーがクリックして読みます。eesel AI のようなAIチームメイトは、そのモデルを反転させます。eeselは記事へのリンクを返す代わりに、ヘルプセンターのコンテンツから学習し、質問に直接回答します。
当社の Zendesk統合 は、既存のナレッジベース、過去のチケット、および接続されたドキュメントに接続します。そこから、eeselは最前線のチケットを処理するAIエージェント、エージェントの返信を下書きするAIコパイロット、またはWebサイトのAIチャットボットとして機能できます。違いは、eeselがコンテンツを見つけるだけではないということです。会話ができるほど十分に理解しています。
Zendesk Guide検索を最適化するためのベストプラクティス
複雑さを増す前に、Zendeskが提供するものから最大限に活用していることを確認してください。
-
インスタント検索用に記事のタイトルを最適化します。 インスタント検索はタイトルのみを検索するため、最も重要なキーワードがそこに表示されていることを確認してください。「パスワードをリセットする方法」というタイトルの記事は、「パスワード」検索で表示されます。「アカウント回復手順」というタイトルの記事は表示されない場合があります。
-
コンテンツ全体で一貫したラベルを使用します。 ラベルはファセットの可用性に直接影響します。ラベル付けタクソノミーを作成し、それを守ってください。四半期ごとにラベルを見直して、一貫性を確認します。
-
カテゴリを論理的に構造化します。 内部チームのようにではなく、顧客のように考えてください。カテゴリ構造は、顧客が問題を説明する方法と一致する必要があります。
-
結果なしの検索を毎週監視します。 失敗した検索を確認するためのカレンダーリマインダーを設定します。それぞれが、必要なものを見つけられなかった顧客を表しています。
-
顧客の視点から検索動作をテストします。 顧客であるかのように、一般的な用語を定期的に検索します。何が表示され、それが役立つかどうかを確認してください。
-
コンテンツを最新の状態に保ち、古い記事を削除します。 古いコンテンツは検索結果を乱雑にし、ユーザーをイライラさせます。現在の現実を反映しなくなった記事はアーカイブまたは更新します。
eesel AIでヘルプセンターの検索を改善する
ファセットとフィルターはユーザーが記事を見つけるのに役立ちますが、ドキュメントへのリンク以上のものを必要とする顧客もいます。彼らは、誰かが答えを説明したり、詳細を明確にしたり、問題を直接処理したりする必要があります。
そこで、eesel AIが登場します。顧客が記事を見つけるのを支援するだけでなく、答えを得るのを支援します。当社のAIは、ヘルプセンターのコンテンツ、過去のチケット、および接続されたドキュメントから学習して、ビジネスを理解します。次に、AIエージェント、コパイロット、またはチャットボットを通じて質問に直接回答できます。
アプローチが異なります。従来の検索では、「答えはおそらくここにあります」と言います。eeselは「これがあなたの答えです」と言います。一般的な質問の場合、これは顧客が記事を読まなくてもすぐに解決できることを意味します。複雑な問題の場合、これは人間のエージェントにエスカレートする前にコンテキストを収集することを意味します。
Zendesk と直接統合するため、何も置き換える必要はありません。eeselは既存のヘルプセンターと並行して動作し、すでに作成したコンテンツから学習します。特定のチケットタイプを処理したり、レビュー用の返信を下書きしたりするeeselから始めて、それが証明されたら拡張できます。
ヘルプセンターの検索が最適化されているにもかかわらず、顧客がさらにサポートを必要とする場合は、eesel AIを無料で試す か、デモを予約する して、当社がどのように支援できるかをご確認ください。
よくある質問
Share this article

Article by
Stevia Putri
Stevia Putri is a marketing generalist at eesel AI, where she helps turn powerful AI tools into stories that resonate. She’s driven by curiosity, clarity, and the human side of technology.