すべてのサポートチケットには、一見しただけではわからない貴重な情報が隠されています。注文番号、製品名、アカウントIDなどです。エージェントは、問題を解決する代わりに、これらの詳細を探すために貴重な時間を費やしています。エンティティ抽出は、チケットが到着した瞬間に主要なデータポイントを自動的に特定して整理することで、これを変えます。
このガイドでは、Zendeskのエンティティ抽出の仕組みと、チーム向けの設定方法について説明します。チケットのルーティングを自動化したり、機密データをサニタイズしたり、単にエージェントが情報をより迅速に見つけられるように支援したりする場合でも、この機能はワークフローを効率化できます。
Zendeskの組み込み機能を超えてサポート自動化を強化する方法を検討している場合は、eesel AIがZendeskとどのように統合して、より広範なナレッジソースを接続し、複雑なチケットに追加のコンテキストを提供するかを確認することもできます。
Zendeskのエンティティ抽出とは?
エンティティ抽出は、顧客のメッセージ内の特定の情報を自動的に識別するAI(人工知能)を活用した機能です。製品名、注文番号、シリアルコード、または定義するカスタムフィールドなど、ビジネスが関心のあるデータポイントのチケットをスキャンするスマートハイライターと考えてください。Zendeskのドキュメントによると、この機能は、より広範なAIを活用したカスタマーエクスペリエンスプラットフォームの一部です。
これがサポートワークフローをどのように変えるかをご紹介します。顧客が「注文番号ORD-12345が破損して到着しました」と書いた場合、システムは「ORD-12345」を注文番号エンティティとして検出します。次に、対応するチケットフィールドに自動的に入力します。エージェントは、この情報を見つけるためにメッセージをスクロールする必要がなくなりました。すでにそこにあり、青色で強調表示され、すぐに使用できます。
この機能は、Zendeskのインテリジェントトリアージシステムの一部であり、より広範なAI製品内にあります。アクセスするには、基本のZendeskプランに加えてCopilotアドオンが必要です。
実際的なメリットはすぐに得られます。チケットは、手動トリアージなしで適切なチームにルーティングされます。クレジットカード番号などの機密情報は自動的にマスクできます。エージェントはデータ入力に費やす時間を減らし、実際にお客様を支援するためにより多くの時間を費やします。インテリジェントトリアージには、より包括的な自動化のためにエンティティ抽出と連携するインテント検出と感情分析も含まれています。
さらに進みたいチームのために、補完的なアプローチを提供します。Zendeskは構造化されたエンティティ抽出を適切に処理しますが、eesel AIのプラットフォームは、ヘルプセンターを超えたより広範なナレッジソース(Confluence、Googleドキュメント、Notionなど)に接続して、複雑な問い合わせに追加のコンテキストを提供します。

Zendeskでのエンティティ抽出の仕組み
技術的な基盤は簡単です。エンティティ抽出は、特定のデータパターンをZendeskですでに作成したカスタムチケットフィールドにリンクします。AIが顧客のメッセージで一致を検出すると、そのフィールドに自動的に入力します。
Zendeskは、エンティティマッチングに3つのフィールドタイプを提供しています。
ドロップダウンフィールドは、製品ラインやサービスカテゴリなどの標準化されたデータに最適です。許容される値を定義すると、システムは顧客の言及をこれらのオプションに一致させます。
複数選択フィールドは、顧客が1つのチケットで複数のアイテム(同じ問題の影響を受ける複数の製品など)を参照する可能性がある場合に役立ちます。
正規表現フィールドは、注文番号(ORD-#####)や追跡IDなど、予測可能なパターンに従うデータを処理します。これには、正規表現パターンを設定するための技術的な知識が必要です。Zendeskでのエンティティの追加の詳細については、ドキュメントを参照してください。
検出されると、エンティティ値はチケット内で青色で強調表示されます。この視覚的な手がかりにより、エージェントは重要な情報を一目で簡単に見つけることができます。強調表示は公開コメントに表示され、内部メモには視覚的な強調なしで値が表示されます。
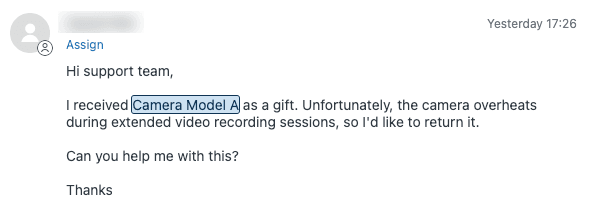
留意すべきいくつかの制約があります。エンティティ検出はスペースで区切られた単語で機能するため、「Mondo Phone3」は一致しますが、「MondoPhone3」は一致しません。エンティティは、チケットと同じ言語で作成する必要もあります。単語が同一であっても、英語のエンティティはスペイン語のチケットではトリガーされません。
スペルミス検出は、5文字より長い単語の小さなエラーをキャッチするのに役立ちます。最初の文字は一致する必要があり、システムは単語あたり最大2つのエラー(追加、欠落、誤配置、または置換された文字)を許容します。これにより、誤検知を作成せずに一般的なタイプミスをキャッチします。
Zendeskでのエンティティ抽出の設定
構成に入る前に、前提条件が整っていることを確認してください。Zendesk Suite Professional以上と、Copilotアドオン(エージェントあたり月額50ドル)が必要です。エンティティを構成するには、管理センターへのアクセスが必要です。
ステップ1:カスタムチケットフィールドを作成する
まず、エンティティデータを保存するフィールドを作成します。管理センターに移動し、オブジェクトとルール、チケット、フィールドの順に選択します。
抽出するデータのタイプに一致するフィールドを作成します。たとえば、「カメラモデルA」や「カメラモデルB」などの値を持つ「製品ライン」という名前のドロップダウンフィールド、検証パターンを持つ「注文番号」の正規表現フィールド、または「問題カテゴリ」の複数選択フィールドを作成できます。これらのフィールドは、エンティティの基盤になります。
ステップ2:インテリジェントトリアージでエンティティを作成する
フィールドの準備ができたら、管理センターに移動し、AI、インテリジェントトリアージ、エンティティの順に選択します。「エンティティを追加」をクリックして、作成プロセスを開始します。エンティティの追加に関するZendeskのガイドで詳細な手順を参照できます。
フィールドタイプ(ドロップダウン、複数選択、または正規表現)を選択し、作成したカスタムフィールドにリンクします。「エンティティを検出」チェックボックスはデフォルトで選択されています。検出をまだアクティブ化せずにエンティティを構成する場合は、チェックしたままにします。
エンティティを作成したら、「設定を管理」をクリックして詳細を構成します。エンティティの管理と編集の詳細については、エンティティの編集に関するZendeskのドキュメントを参照してください。
ステップ3:抽出ルールを構成する
抽出ルールは、エンティティがチケットフィールドに入力されるタイミングと方法を決定します。「検出された値でチケットフィールドを更新」には4つのオプションがあります。「チケットフィールドを更新しない」オプションは、エージェントが更新をクリックしてフィールドを手動で入力する必要があることを意味します。「最初のメッセージの値のみ」は、件名、最初のコメント、または会話の最初のメッセージからフィールドに入力します。「後続のメッセージの値のみ」は、最初のメッセージを除くすべてのコメントに基づいてフィールドを更新します。「すべてのメッセージの値」は、すべてのチケットコメントまたはメッセージから入力および更新します。これがデフォルト設定です。
「エージェントツール」で、「すべてのメッセージでエンティティ値を強調表示」を有効にして、エージェントが表示する青色の強調表示を表示できます。「検出設定」で、「スペルミスの値を検出」を追加すると、一般的なタイプミスに対する許容度が追加されます。
ステップ4:検出を改善するために同義語を追加する
顧客は必ずしも期待する正確な用語を使用するとは限りません。同義語は、同じ意味を持つバリエーションをキャッチするのに役立ちます。
「注文番号」エンティティの場合、「注文ID」、「取引番号」、または「購入ID」などの同義語を追加できます。エンティティ値ごとに最大10個の同義語を追加できます。同義語が表示されると、強調表示され、対応するエンティティ値が抽出されます。
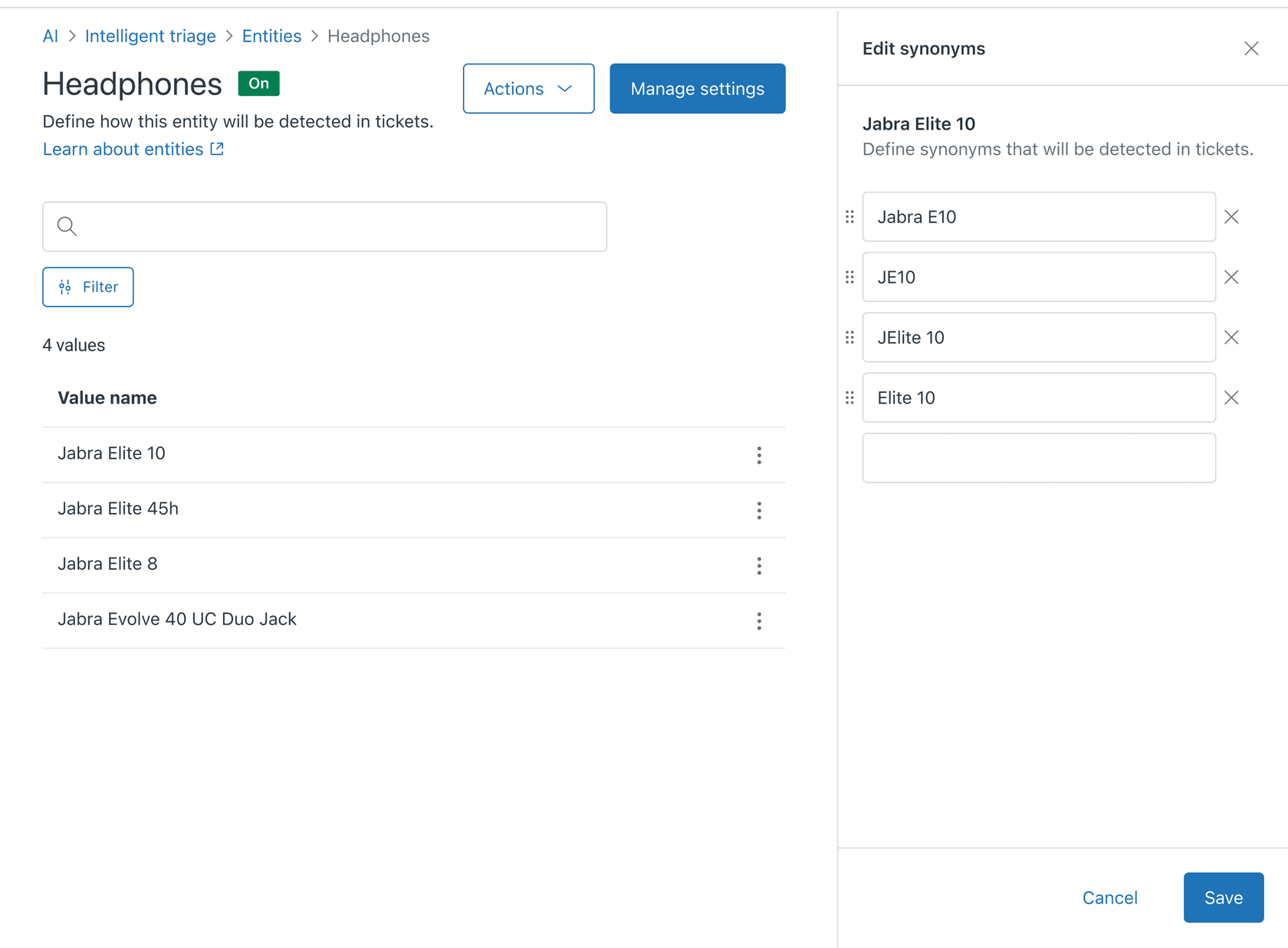
同義語を追加するには、エンティティをクリックし、値名のオプションメニューをクリックして「同義語を編集」を選択します。バリエーションを入力して保存します。同義語の構成の詳細については、エンティティの編集と管理に関するZendeskのガイドを参照してください。
ステップ5:スペルミス検出を有効にする(オプション)
スペルミス検出は、ドロップダウンフィールドおよび複数選択フィールドに関連付けられたエンティティで使用できます。最初の文字がエンティティ値と一致する場合にのみ機能し、6文字より短いパターンでは機能しません。スペルミス検出の仕組みの詳細については、Zendeskのドキュメントを参照してください。
この機能は、顧客がタイプミスする可能性のある製品名または技術用語に特に役立ちます。ただし、1文字の変更が異なる意味になる言語では、うまく機能しない可能性があることに注意してください。
エンティティ抽出の実用的なユースケース
構成が完了すると、エンティティはさまざまな自動化の可能性を秘めています。ここでは、サポートチームが実装する最も一般的なアプリケーションを紹介します。
自動チケットルーティング
最も一般的なユースケースは、検出されたエンティティに基づいてチケットを専門チームにルーティングすることです。エンティティがチケットで「カメラモデルA」を検出した場合、カメラサポートチームに自動的に割り当てるトリガーを作成できます。
これにより、手動トリアージが不要になり、顧客がすぐに適切な専門家に連絡できるようになります。複数の製品ラインまたは専門知識分野を持つチームの場合、これだけで1日に数時間のルーティング作業を節約できます。
優先順位の設定
特定のエンティティは緊急性を示します。「キャンセル」という言及は、解約しようとしている顧客を示している可能性があります。「セキュリティ侵害」エンティティは、緊急の注意が必要な重大な問題を示している可能性があります。
これらの優先度の高いエンティティを監視するトリガーを作成することにより、エージェントがチケットを見る前にチケットを自動的にエスカレーションできます。これにより、最も重要な問題に迅速に対応できます。
データサニタイズとセキュリティ
エンティティ抽出は、機密情報を自動的に検出することにより、セキュリティ標準の維持に役立ちます。クレジットカード番号や社会保障番号などのパターンに対してエンティティを設定し、それらを使用して自動的な編集またはマスキングをトリガーできます。
これにより、顧客データが保護され、コンプライアンス要件が満たされます。エージェントが機密情報を手動で見つけて処理するのではなく、システムが自動的にキャッチします。
AIエージェントの強化
ZendeskのAIエージェントを使用しているチームの場合、エンティティは重要なコンテキストを提供します。AIエージェントが注文番号エンティティを検出すると、バックエンドルックアップをトリガーして、人にエスカレーションすることなくリアルタイムの注文ステータスを提供できます。
これにより、会話が単純なQ&Aからアクティブな問題解決に移行します。AIは、一般的な応答を提供するのではなく、各チケットの特定の詳細に基づいてアクションを実行できます。
レポートと分析
エンティティは標準のチケットフィールドに入力されるため、レポートに直接フィードされます。どの製品が最も多くのサポートリクエストを生成するかを追跡したり、カテゴリ別にトレンドの問題を特定したり、製品ライン別に解決時間を測定したりできます。Zendeskのレポート機能はプランの階層によって異なり、より高度な分析は上位層のサブスクリプションで利用できます。
このデータは、リソース計画、製品の改善、およびチームのトレーニング機会の特定に役立ちます。
検出されたエンティティを使用したワークフローの作成
エンティティは、Zendeskのビジネスルールと組み合わせると強力になります。検出されたデータに基づいて効果的なワークフローを構築する方法を次に示します。
トリガーは、エンティティベースの自動化に最も一般的なツールです。トリガーを作成するときに、エンティティのタグを条件として使用できます。タグはfield_name__valueの形式に従うため、簡単に参照できます。
たとえば、トリガーには、チケット>タグにproduct_line__camera_model_aの少なくとも1つが含まれているという条件があり、チケット>グループをカメラサポートチームに設定するアクションがあります。必要に応じて、トリガー条件でカスタムフィールド値を直接使用することもできます。
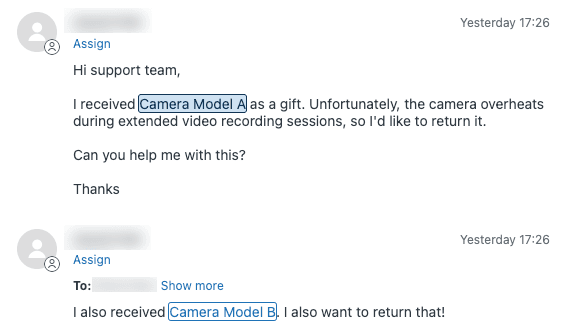
エンティティワークフローのベストプラクティスには、Zendeskのトリガーテストを使用するか、完全に展開する前に小規模なパイロットを実行して展開前にテストすることが含まれます。Zendeskは設定した順序でエンティティの一致を処理するため、順序が重要です。したがって、一般的なルールよりも具体的なルールを高く配置します。すべてを一度に構成しようとするのではなく、1つまたは2つの影響の大きいエンティティから始めることで、単純に開始します。将来のチームメンバーのために、各エンティティとトリガーが何をするかについてのメモを保持することにより、セットアップを文書化します。
制限事項と考慮事項
エンティティ抽出は強力ですが、制約がないわけではありません。これらの制約を事前に理解することで、適切な期待を設定できます。エンティティ検出の機能と制限の完全な概要については、Zendeskのエンティティ検出ドキュメントを参照してください。
言語の一致が最も重要な制限事項です。英語で作成されたエンティティは、単語が同じであっても、スペイン語のチケットでは検出されません。つまり、多言語チームは、サポートする言語ごとに個別のエンティティを作成する必要があります。
単語の分離の問題により、検出が失敗する可能性があります。システムは、スペースで区切られた個々の単語を識別します。「Mondo Phone3」は一致しますが、「MondoPhone3」は一致しません。これは主に、単語間にスペースを使用しない言語に影響します。
正規表現の設定には技術的な専門知識が必要です。ドロップダウンエンティティと複数選択エンティティは簡単ですが、正規表現パターンには正規表現の知識が必要です。技術リソースのないチームは、パターンベースのエンティティの設定で支援が必要になる場合があります。
コストも考慮事項です。Copilotアドオンは、基本のZendeskプランに加えて、エージェントあたり月額50ドルで実行されます。小規模なチームの場合、これは重要になる可能性があります。Zendeskの価格は、Suite Professional(Copilotをサポートする最小プラン)の場合、エージェントあたり月額115ドルから始まり、合計でエージェントあたり月額165ドルになります。
最後に、エンティティ抽出は、Zendeskチケット内のデータに限定されます。ConfluenceやGoogleドキュメントなどの外部ナレッジソースから情報を取得することはできません。より広範なナレッジベースを接続する必要があるチームのために、eesel AIでは100を超えるソースとの統合を提供し、Zendeskの構造化されたアプローチをより広範なコンテキストで補完します。
エンティティ抽出を最大限に活用する
実装が成功すると、いくつかの共通の特徴があります。ここでは、経験豊富な管理者が推奨することを紹介します。
影響の大きいエンティティから始めます。すべてを一度に抽出しようとしないでください。チームの時間を最も節約できる2つまたは3つのデータポイントを選択します。一般的な開始点は、ルーティングの決定を左右する製品名、注文番号、または問題カテゴリです。
一般的なルールよりも具体的なルールを使用します。Zendeskは、定義した順序でエンティティを処理します。「カメラモデルA Pro」と「カメラモデルA」の両方がエンティティとして存在する場合は、より具体的な「Pro」バージョンを最初に配置します。そうしないと、「カメラモデルA Pro」のすべての言及が「カメラモデルA」としてタグ付けされる可能性があります。
定期的なレビューにより、エンティティの精度が維持されます。顧客の言語は変化します。新製品が発売されます。エンティティを確認し、同義語を更新し、必要に応じて新しい値を追加するために、四半期ごとのリマインダーを設定します。
他のインテリジェントトリアージ機能と組み合わせます。エンティティ抽出は、インテント検出および感情分析と連携して動作します。否定的な感情+「キャンセル」エンティティ+「VIP」顧客タグを持つチケットは、すぐにエスカレーションする価値があるかもしれません。これらの機能を組み合わせて使用すると、より高度な自動化が実現します。
より広範なニーズに対応するために、補完的なツールを検討してください。Zendeskはチケット内の構造化されたエンティティ抽出に優れていますが、一部のチームはより広範なナレッジソースからコンテキストを取得する必要があります。eesel AIのプラットフォームは、ヘルプセンター、内部Wiki、ドキュメント、および過去のチケットに接続して、複雑な問い合わせに追加のコンテキストを提供します。eeselを無料で試すこともでき、既存のセットアップでどのように機能するかを確認できます。
よくある質問
Share this article

Article by
Stevia Putri
Stevia Putri is a marketing generalist at eesel AI, where she helps turn powerful AI tools into stories that resonate. She’s driven by curiosity, clarity, and the human side of technology.