Sakana Fuguとは正確には何か?
Sakana AIは、2023年に3人のGoogle出身研究者によって設立された東京のフロンティアラボです:CEO David Ha、CTO Llion Jones(Transformerの原論文"Attention Is All You Need"の8人の共著者のうちの1人)、そしてCOO Ren Itoです。2025年11月に評価額$26.5億での$1億3500万Series B資金調達を完了し、日本で最も価値あるAIスタートアップの1つになりました。
名前には意味があります。「Sakana」(魚)は魚を意味し、AIの未来が1つの巨大な脳というより、小さなスペシャリストの協調した群れに見えるというラボの賭けへのうなずきです。Fugu(フグにちなんで命名)はその考えをプロダクト化したものです。Sakanaは"One Model to Command Them All"と売り込んでいます:単一ベンダーに依存せずにフロンティアレベルの性能を実現します。
最もクリアな説明はこうです。Fugu自体はモデルですが、最終回答を単独で生成する代わりに、他の強力なモデルのプールから動的にチームを組み、それらを調整します。全体の仕組みが1つのAPIの背後にある1つのモデルとして提供されます。AIエージェント対チャットボットの解説を読んだことがあれば、Fuguはエージェントのアイデアを論理的な極端へ押し進めたものです:エージェントの「ツール」が他のフロンティアモデルなのです。
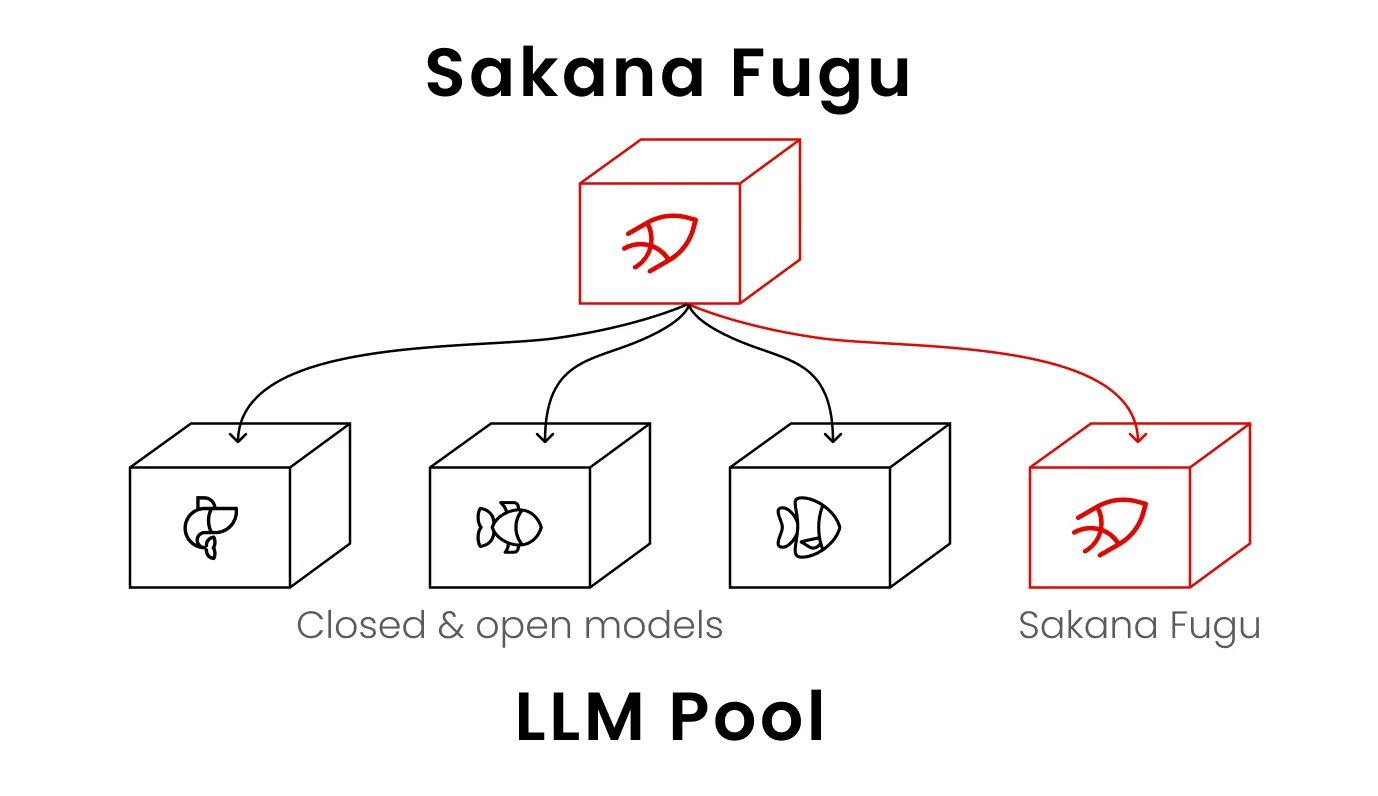
多くの人が見落とす重要な詳細:Fable 5とMythos PreviewはFuguのプールに含まれていません。公開アクセスできないためです。Fuguは実際に呼び出せるモデルのみをオーケストレーションします。SakanaがFuguはFable 5に匹敵すると言う場合、他の公開モデルの協調チームがフロンティアに並べると言っているわけで、これは一見よりも興味深い主張です。
Fuguが内部でどう機能するか
ここでFuguは「単なるルーターではない」という弁護を勝ち取ります。学習済みモデルオーケストレーションに関する2本のICLR 2026論文に基づいており、メカニズムはモデルを選んでリクエストを転送するよりはるかに複雑です。
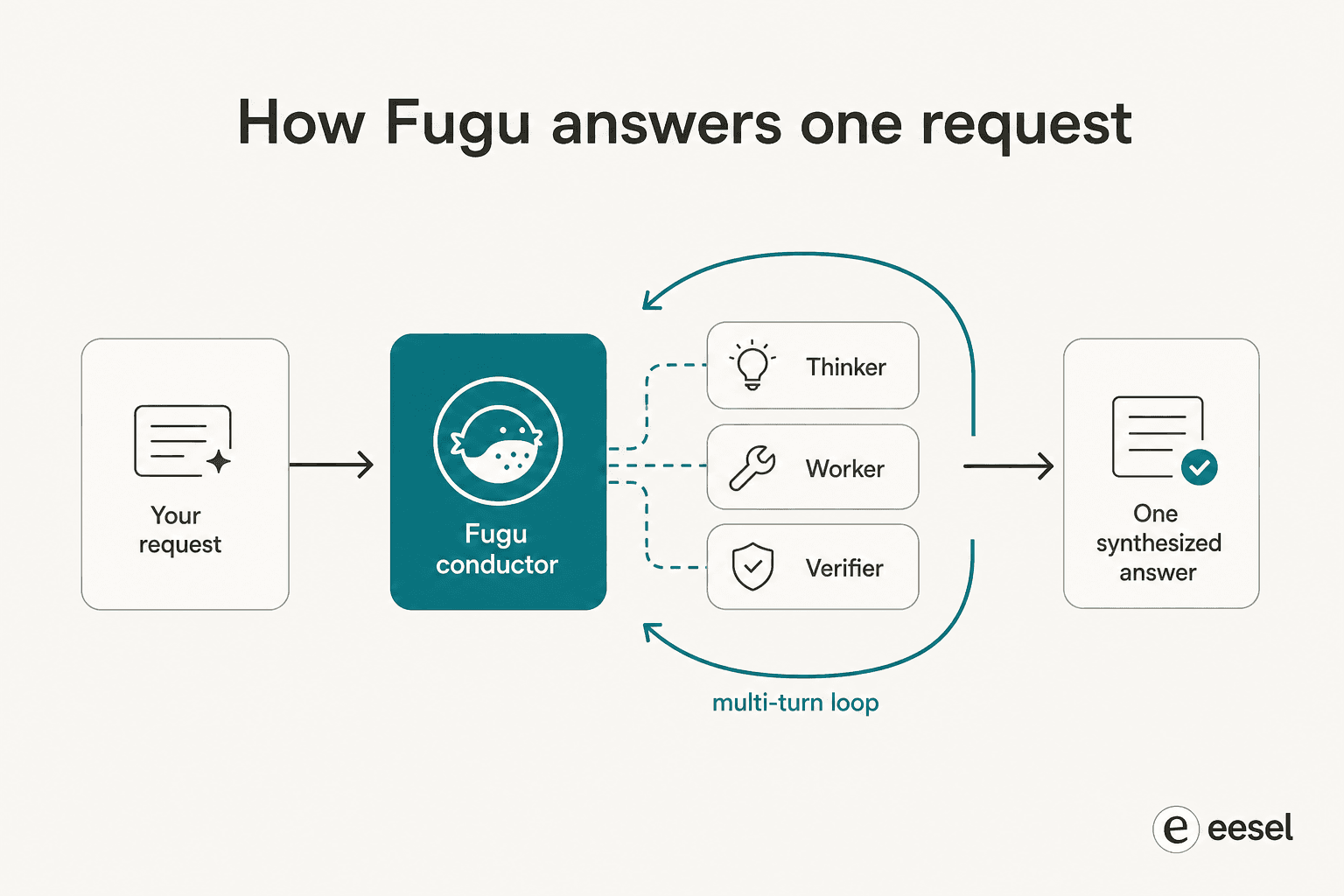
最初の論文TRINITYは、複数のターンにわたって複数のモデルをオーケストレーションする軽量な進化的コーディネーターを使用し、それぞれにThinker・Worker・Verifierの役割を割り当て、タスクの展開に合わせて再委任します。2番目のConductorは、強化学習で自然言語協調戦略を発見するよう訓練されており、基本的にはプールが各メンバーを上回るように、焦点を絞ったプロンプトの書き方とモデル間のコミュニケーション設計を学習します。
覚えておくべき2つのフレーズは学習済みとマルチターンです。Fuguは人間が設計した「まずモデルAに、次にモデルBに」というスクリプトに従いません。進化とRLを通じて非自明な協調パターンを発見し、1回のパスで終わるのではなく、ループして再確認・再ルーティングします。だから初期ユーザーは1つのタスクに数時間かかると報告しています:MLの研究問題で約14時間かけて123回の実験、または論文をほぼ4時間かけて自律的に再現するなどです。サポート自動化を構築する際に強く意識するエージェントループと非常によく似た動作で、ただしツールではなくフロンティアモデルを向いています。
今指摘すべきトレードオフ:ルーティングは設計上独自仕様かつ不透明です。どの基礎モデルが特定のクエリに回答したかは見えません。一部のチームにはそれで構いませんが、コンプライアンス要件がある場合、その「ブラックボックスの前にブラックボックス」構造は実際の考慮事項です。
FuguとFugu Ultra:どちらがどちらか
Fuguは2つのモデルとして提供され、どちらも同じOpenAI互換APIからアクセスできるため、統合を変更せずに切り替えられます。違いは調整されるエキスパートエージェントの数で、それが速度と品質のバランスを決めるレバーです。
| Fugu | Fugu Ultra | |
|---|---|---|
| 最適化対象 | バランスの取れたパフォーマンスとレイテンシ | 最高の回答品質 |
| エージェントプール | プールを調整;モデルの除外可能 | より深い固定プール;除外不可 |
| 最適な用途 | 日常的なコーディング、コードレビュー、チャットボット | 困難で高リスクなマルチステップ問題 |
| トレードオフ | 低レイテンシ、優れたデフォルト | 速度を犠牲にした高品質 |
簡単に言えば:応答性の高いデフォルトが欲しいときはFuguを、手強い問題があって良い回答のために待てるときはFugu Ultraを選びましょう。初期ユーザーはUltraをKaggleコンペ、論文再現、サイバーセキュリティ分析、特許調査に使っており、想定スイートスポットは深さであり、スループットではないことがわかります。
ベンチマーク:本当にFable 5と肩を並べているのか?
Sakanaの見出し主張は、Fuguモデルが工学・科学・推論ベンチマークで「公開アクセス可能なフロンティアモデルを上回り、Fable 5とMythos Previewと肩を並べる」というものです。数字はより狭い主張をよく裏付けています。
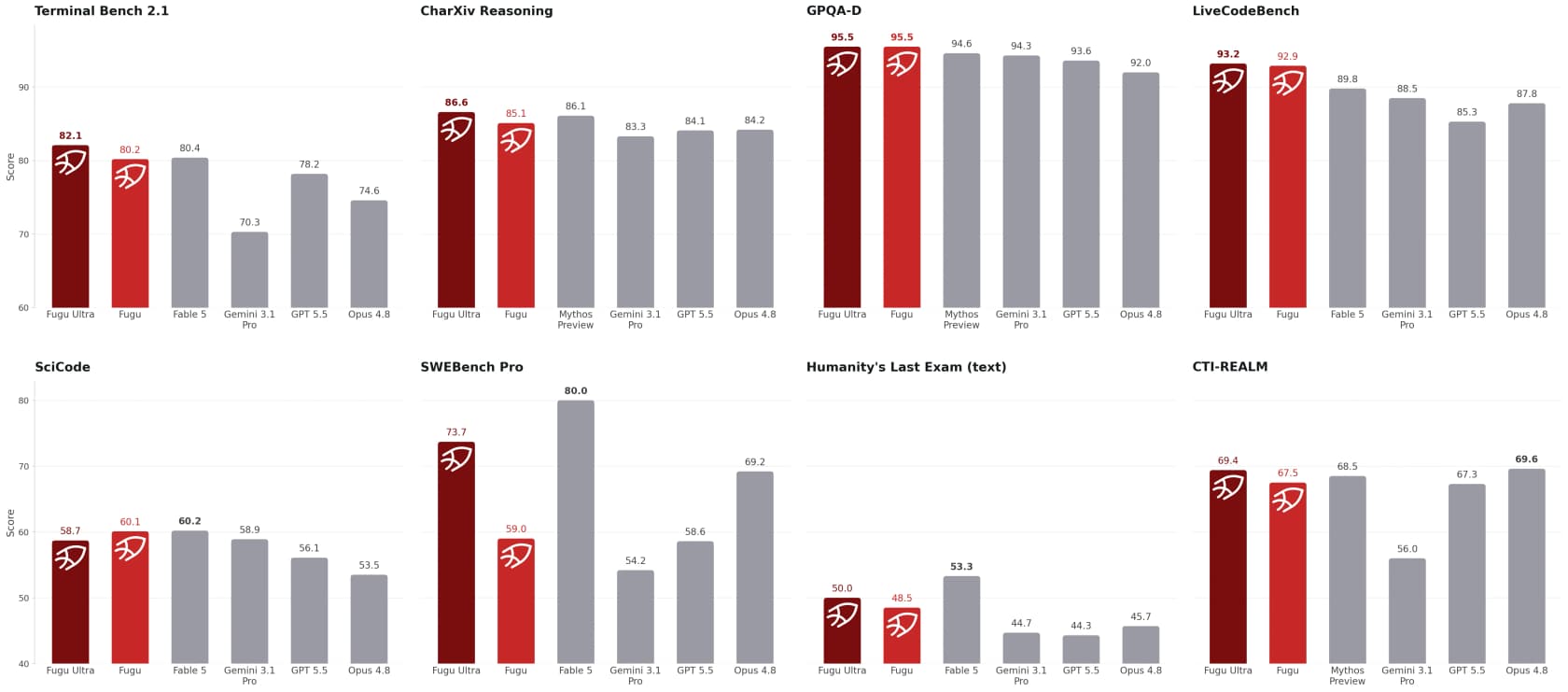
Sakanaの表から際立つものをいくつか:Fugu UltraはSWE-Bench Proで73.7(Opus 4.8の69.2、GPT-5.5の58.6に対して)、LiveCodeBenchで93.2、GPQA-Diamondで95.5を記録し、示された全ての公開ベースラインを上回っています。定性的なデモはさらに印象的です:Fuguは3つのフロンティアモデルと2100 EloのStockfishエンジンをブラインドチェスで破ったと報告されており、時系列トレードテストでは$10,000を50週間のウィンドウで$11,943に成長させ、+19.43%の平均リターンで他を上回っています。
2つの率直な注意点。まず、これらはベンダー報告のベンチマークであり、最強モデル(Fable 5、Mythos)は直接競合として比較から除外されており、正面から打ち負かされたわけではありません。次に、ベンチマークは困難な問題でのピーク性能を測定するもので、火曜日の午後2時に使って快適かどうかは測定しません。ベータユーザーのslopdetectorがHacker Newsで述べたように:
「ベータ期間中に使いました。複雑なタスクではGPT-5.5 xhighを上回ります。高価で補助が難しいため、最も難しい問題に使ってください...fugu-ultraから得た結果は印象的でした。」 - slopdetector、Hacker Newsにて
Sakana Fuguの料金(誰も言及しない落とし穴)
支払い方法は2つあり、どちらもFuguとFugu Ultraへのアクセスを含みます。
| サブスクリプション層 | 価格 | 使用量 | 対象 |
|---|---|---|---|
| Standard | $20/月 | ベースライン | 軽い日常利用 |
| Pro | $100/月 | Standard×10 | 集中した作業セッション |
| Max | $200/月 | Standard×30 | 重い長時間ワークロード |
(注:SakanaのプライシングカードはMaxをStandard×30と記載していますが、FAQの回答は20×と述べています。契約前に確認してください。)従量制トークンプランもあり、Fugu Ultraは入力$5、出力$30、キャッシュ済み入力$0.50(100万トークンあたり)の固定料金で、コンテキストが272Kトークンを超えると$10/$45/$1.00に上昇します。また、ローンチプロモーションとして2026年7月末までにサブスクライブすると2ヶ月目が無料になります。
さて落とし穴。Fuguはルーティング元プールの上限価格で課金されるため、オーケストレーションのオーバーヘッドは直接フロンティアモデルに払うことに対して正当化される必要があります。実際に使った複数のユーザーは正当化されないと感じていました。Hacker NewsのcortesiからのもっともSharpな声:
「月$200で週3時間未満の使用量、APIは非常に遅く、私のテストでの出力品質はFableにはるかに及びません。日常の作業馬として全く使えません。非常に失望しました。」 - cortesi、Hacker Newsにて
これは1人のテスターの経験であり評決ではありませんが、5時間制限がすぐになくなると報告する複数のユーザーと一致しています。AIエージェントのコスト対人間エージェントをモデル化したことがあれば、教訓は馴染み深いはずです:定価と実際の有用タスクあたりのコストは異なる数字です。
自分がやろうとしていることにFuguが適切なツールかどうかの簡単なチェック:
「余分なステップを加えたOpenRouter」という批判は公平か?
Fuguのローンチへの最も大きな反応は、Hacker News・X・Redditで独立して繰り返された「これは単にOpenRouterではないか?」というものでした。これは合理的な直感なので、真剣に取り上げましょう。
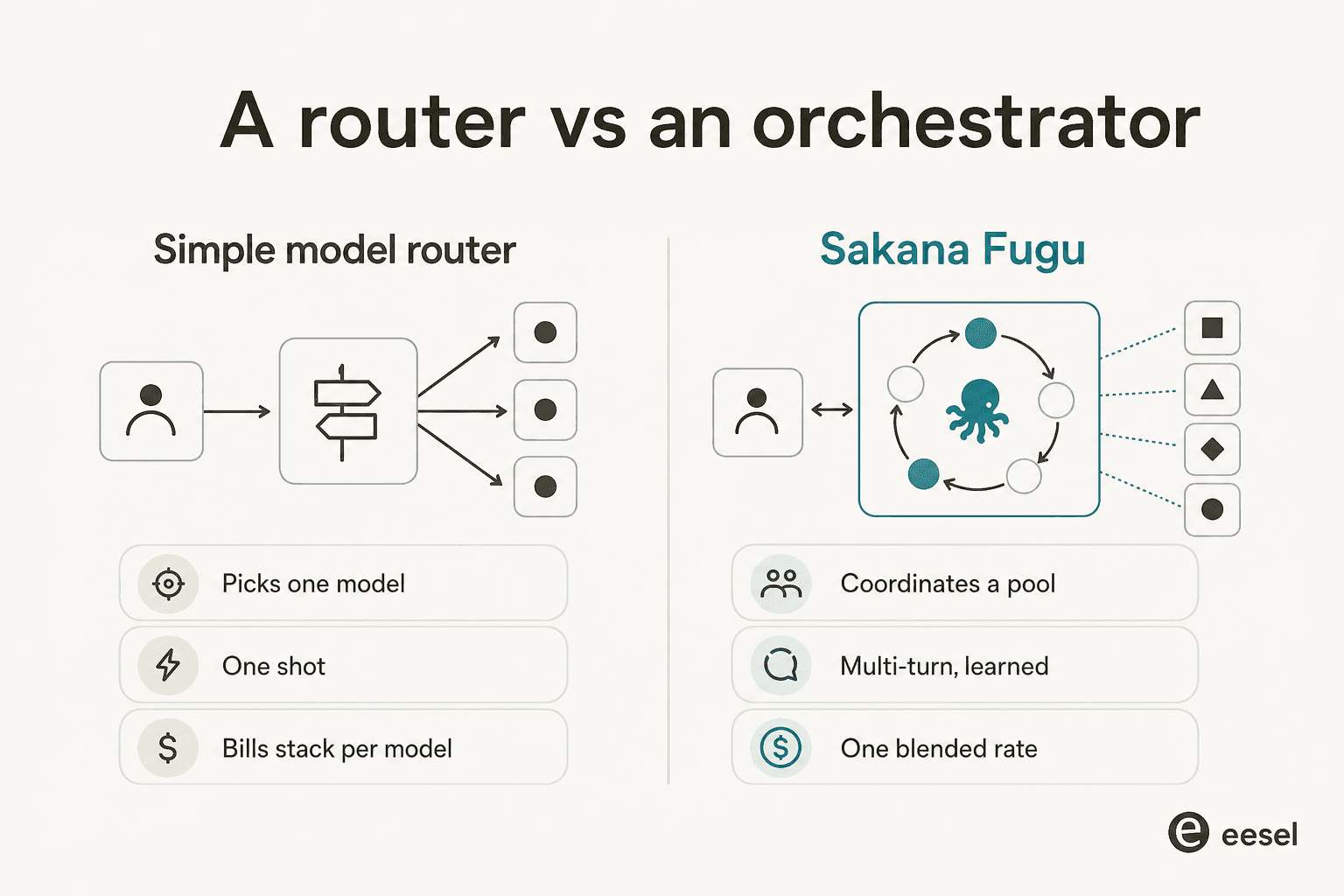
単純なルーターは1つのモデルを選んでリクエストを1回転送します。Fuguは少なくとも紙面上、ルーターがしない3つのことをします:複数のターンを実行し、モデルが互いの成果を検証し、各モデルの請求を積み上げるのではなく関与する最上位モデルに基づく単一の混合レートで課金します。アーキテクチャは本物であり、「高度なルーター」はマルチターンの自己検証ループを軽視しています。
ただし、懐疑論者はアーキテクチャではなく価値に対して正確な指摘をしています。chenzheklが率直に尋ねたように:
「でも、フロンティアモデルと同じ価格です。なぜフロンティアモデルに直接払わないのですか?」 - chenzhekl、Hacker Newsにて
これが1行で表した議論全体です。アーキテクチャはルーターを超えています;未解決の問いは、余分な調整がフロンティア価格を払うほどの価値を生み出すかどうかです。私の見解:最も難しい問題ではおそらくイエス;日常の作業ではおそらくノーです。これはAIエージェント対ルールベースチャットボットの決断と同じ計算であり、タスクが本当に難しいときだけ高度なアプローチが効果を発揮します。
Sakana Fuguについて人々が実際に考えていること
コミュニティの感情は率直に読むと、賛成派が存在するものの混合から懐疑的です。支持者は最も興味深い論拠を提示しています:モデルが互いを検証することは単純に正しい賭けだというものです。epsteingptが主張したように:
「数ヶ月間、異なるモデルが互いを検証し合うことが最善の道筋だと誰もが理解してきた...(大きなもしも)使用の仕組みがうまくいけば、これは実際には非常に良いアンチ大型モデル戦略です。彼らは投資家のためのトークン最大化ではなく、あなたの成功のためにインセンティブを持つでしょう。」 - epsteingpt、Hacker Newsにて
このインセンティブ整合性のポイントは鋭く、モノリシックよりもオーケストレーターを支持する本物の理由です。Sakanaの研究パスへの敬意のスレッドもあります。quantoが指摘したように、David HaはAI研究への非従来的なルートを取り、ラボの以前の作業(Evolutionary Model Merge、AI Scientist、Transformer²)は一貫して特徴的です。
懐疑論者は一方で反射的ではありません。彼らの異議はコスト、レイテンシ、そして不透明な「別の単一ベンダーが単一ベンダーを置き換える」フレーミングに集中しています。そして登録前に知っておく価値のある実世界のメモ:FuguはEU/EEAではまだ利用できず、一部のユーザーはSakanaの軍事契約について不安を表明しました。本番利用で最良のAIエージェントと比較検討するなら、これらは脚注ではありません。
モデルをオーケストレーションするモデルがサポートにとって重要な理由
これは私が最も気にする部分です。なぜなら、これが私の実際の仕事だからです。Fuguの基本的なアイデア、1つのモデルにワークフローを賭けず、複数を調整して互いに検証させる、はカスタマーサポートのような高リスクな自動化にとってまさに正しいアプローチです。サポートボットからの誤った回答はリーダーボードのミスではなく、誤って発行された返金や怒った顧客を意味します。
しかし、生の不透明なモデルAPIと顧客の前に安全に置けるものの間には深い溝があります。Fuguはオーケストレーションを与えてくれますが、ヘルプセンター、過去のチケット、ブランドの声、エスカレーションルール、または本番前にテストする方法は与えてくれません。それがカスタマーサービス向けAIが機能するかどうかを実際に決める層であり、フロンティアAPIを手動で配線するよりも目的特化のカスタマーサービス向けAIエージェントを選ぶ理由です。ビルド対バイで強調するオーケストレーションの問いは、Fuguが答えているのと同じ問いですが、スタックの異なる層でのことです。
eeselを試してみる
eeselはFuguが基づく教訓を取り、本当に信頼性が必要な場所、つまりサポートキューに適用します。モデルAPIを渡す代わりに、既に使用しているヘルプデスク(Zendesk・Freshdesk・Help Scout・Slackなど)に数分で接続し、過去のチケットとヘルプセンターで自己訓練し、ブランドの声で回答するAIエージェントです。モデルオーケストレーションの配管は不要です。

ここで最も重要な差別化要因は、Fuguが提供できない部分です:ライブ顧客に触れる前に、何千もの過去チケットに対してエージェントを再現するシミュレーションモード。これにより、本番で発見するのではなく、解決率と正確な返答を事前に確認できます。価格は使用量ベースでシートあたりの費用はなく、コストはヘッドカウントではなく価値とともにスケールします。オーケストレーションが不可視でガードレールが組み込まれたカスタマーサービスAIがどのようなものかを確認したい場合は、無料で試すことができます。
よくある質問
Sakana Fuguをひと言で説明すると?
Sakana FuguはOpenRouterとどう違うのか?
Sakana Fuguの料金は?
Sakana FuguはClaudeやGPT-5.5より優れているのか?
Sakana Fuguは何に最も向いているのか?
カスタマーサポートにSakana Fuguは使えるか?
Sakana Fuguはどこでも利用できるのか?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.








