正直に言いましょう。ほとんどの企業は、膨大な量の有用な情報の山の上に座っています。しかし、問題はその情報がいたるところに散らばっていることです。Slackのダイレクトメッセージ(DM)に埋もれ、ランダムなGoogleドキュメントに放置され、古いサポートチケットの中に隠され、さらにはベテランチームメンバーの頭の中に閉じ込められています。誰かが答えを必要としたとき、彼らは行き詰まってしまいます。その結果、同じ質問が何度も繰り返され、チームは当然のように不満を募らせることになります。
ナレッジベース (knowledge base) を一元化することがその解決策です。これは「信頼できる唯一の情報源(Single Source of Truth)」となり、社内チームと顧客の両方が、必要なときに必要な情報をすぐに見つけられるようにします。このガイドでは、Atlassianナレッジベースとは何か、適切にセットアップする方法、そして何よりも、その強みを活かして、誰もが現代に期待するような即時的で自動化されたサポートを提供する方法について解説します。
Atlassianナレッジベースとは何ですか?
まず初めに、「Atlassianナレッジベース」とは、主に Confluence を中心としたAtlassianの業界をリードするツールを組み合わせて構築する、強力で統合されたソリューションのことです。これは、会社のすべてのハウツーガイド、ポリシー、社内Wikiを収容する中央図書館のようなものだと考えてください。
AtlassianナレッジベースにおけるConfluenceとJira Service Managementの役割
これを機能させるには、ConfluenceとJira Service Managementという2つの主要なプレーヤーが必要です。
-
Confluence: ここは、すべてのナレッジベース記事を作成、整理、管理する場所です。共同編集機能、便利なテンプレート、そしてすべてを完璧に整理された状態に保つためのページ構造を備えたデジタルライブラリです。チームは記事を書き、変更を追跡し、すべての情報が正確であることを確認できます。
-
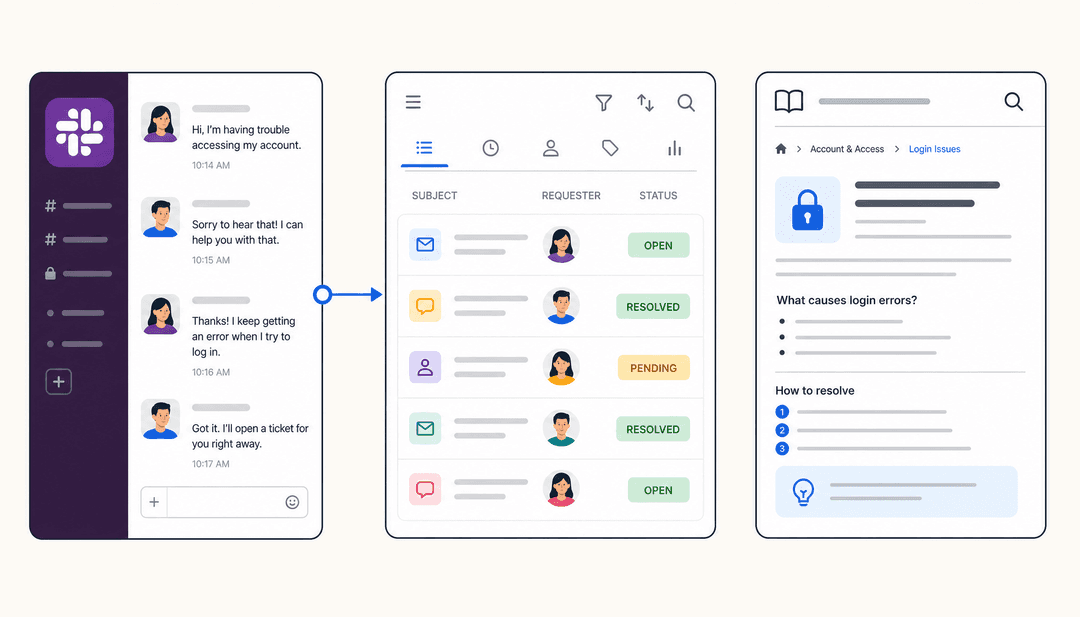
Jira Service Management (JSM): これはヘルプデスクであり、従業員や顧客が質問を持って訪れる玄関口です。ConfluenceスペースをJSMプロジェクトに接続すると、システムは非常に効率的になります。誰かがヘルプポータルに質問を入力すると、JSMは自動的にナレッジベースを検索し、関連する記事を提案します。これは、サポートチケットが作成される前に質問を解決するための実績ある方法です。
社内用 vs 社外用 Atlassianナレッジベース
Atlassianナレッジベースは、2つの異なる対象者に向けて構築でき、その違いを知っておくことは重要です。
- 社内ナレッジベース (Internal Knowledge Base): これは自チーム専用です。従業員のオンボーディングガイド、人事(HR)ポリシー、ITトラブルシューティングの手順、社内プロセスのドキュメントなどの拠点となります。目標は、従業員がより効率的に、自力で回答を見つけられるようにすることです。
- 社外ナレッジベース: これは顧客向けです。製品ガイド、よくある質問(FAQ)、セットアップ手順、チュートリアルなどで構成される公開ヘルプセンターであり、顧客が自分の問題を簡単に解決できるように設計されています。
セットアッププロセスは基本的に両方とも同じですが、権限設定に注意し、それぞれのグループに適したトーンで執筆することが重要です。
Atlassianナレッジベースのセットアップ方法:ステップバイステップガイド
開始するのは驚くほど簡単です。Atlassianは、整理され検索可能な情報のライブラリを構築するために必要なすべてを提供しています。最初のナレッジベーススペースを立ち上げて稼働させるための、簡単なウォークスルーをご紹介します。
ステップ 1: ConfluenceでAtlassianナレッジベーススペースを作成する
すべてはConfluenceから始まります。ライブラリを構築する準備ができたら、新しい「スペース」を作成する必要があります。Confluenceでは、最初から専用の 「ナレッジベース」テンプレート が用意されており、これを活用できます。
このテンプレートを選択すると、スペースに名前を付けるよう求められます(「カスタマーヘルプセンター」や「ITサポートドキュメント」のように分かりやすい名前が最適です)。次に権限を設定します。誰でも閲覧できるように公開することも、特定のユーザーだけに制限することも可能です。そこからロゴを追加したり、会社のブランディングに合わせて外観を微調整したりできます。このセットアップ全体はわずか数分で完了し、プロフェッショナルな出発点を提供してくれます。
ステップ 2: 親ページとラベルを使用してAtlassianナレッジベースのコンテンツを構造化する
論理的なレイアウトにすることで、人々が必要な情報を探しやすくなります。記事を書き始める前に、構造について少し考えてみましょう。Atlassianの柔軟性により、会社の成長に合わせて拡張できるシステムを構築できます。
プロのヒント: 整理するための優れた方法は、主要なトピックや製品ごとに「親」ページを作成することです。次に、特定のガイドやハウツー記事をその下の「子」ページとしてネスト(階層化)します。例えば、「請求(Billing)」という親ページの下に、「クレジットカードの更新方法」や「請求書の理解」といった子ページを配置します。
また、ラベルを使用する習慣をつけるべきです。ラベルはタグのようなもので、異なるセクションにまたがるコンテンツをグループ化するのに役立ちます。記事に onboarding、billing、troubleshooting といったラベルを追加することで、検索で見つけやすくなります。
ステップ 3: テンプレートを使用してAtlassianナレッジベースの記事を書く
ナレッジベースをプロフェッショナルに見せたい場合、一貫性は非常に重要です。これを実現する最も簡単な方法は、 テンプレートを使用すること です。Confluenceには、「ハウツー記事」や「トラブルシューティング記事」など、一般的な記事用のビルドインテンプレートがいくつか用意されています。
テンプレートを使用すると、すべての記事が同様の形式に従うようになり、ユーザーが情報を読み、理解するのに役立ちます。また、Confluenceが構造を担当してくれるため、チームは役立つコンテンツの執筆に集中でき、作業がスピードアップします。
ステップ 4: AtlassianナレッジベーススペースをJira Service Managementにリンクする
記事がいくつか入ったConfluenceスペースができたら、最後のステップはJira Service Managementへの接続です。JSMのプロジェクト設定に移動し、「ナレッジベース」セクションを見つけて、新しいConfluenceスペースをリンクするだけです。このステップにより、カスタマーポータルのスマート検索機能とチケット削減(Deflection)機能が有効になります。
Atlassianナレッジベースの主な機能と考慮事項
Atlassianナレッジベースは、セルフサービスサポートのための強固でエンタープライズグレードの基盤を提供します。その強みと、それをどのように拡張するかを知ることが、最大限に活用するための鍵となります。
うまく機能する点:Atlassianナレッジベースの核となる強み
Atlassianはエッセンシャルな部分をしっかりと押さえており、標準のナレッジベース設定には多くのメリットがあります。
- 検索が非常にスマート: これは大きなハイライトです。ユーザーがJSMポータルで入力を始めると、システムはリンクされたConfluenceスペースを即座にスキャンし、関連する記事を表示します。これは、よくある質問を未然に防ぎ、サポートチームの負担を軽減する素晴らしい方法です。
- バージョン履歴 と簡単なコラボレーション: コンテンツは常に最新である必要があり、Atlassianはそれを容易にします。Confluenceはページへのすべての変更を追跡するため、誰がいつ何を変更したかを簡単に確認でき、必要に応じて古いバージョンに戻すこともできます。それに加えて、共同編集エディターにより、チームが協力して作業するのがシンプルになります。
- 閲覧権限をコントロール可能: 権限を完全にコントロールできます。スペース全体に設定することも(例:このセクション全体は社内スタッフ専用にする)、特定のユーザーグループに対して1ページだけをロックするような詳細な設定も可能です。これにより、社内ナレッジと社外ナレッジの両方を1か所で管理するのに最適です。
- テンプレートとマクロによる時間の節約: 内蔵テンプレートは大きな助けになりますし、Confluenceマクロを使用すると、より動的なコンテンツを構築できます。例えば、「ラベル別のコンテンツ(Content by Label)」マクロを使用すると、特定のラベルを持つすべてのページのリストを自動的に作成でき、動的なインデックスページを作成するのに役立ちます。
Atlassianナレッジベースの拡張:成長に向けた考慮事項
コア機能は非常に強力ですが、サポート量が増えるにつれて、次のレベルの自動化に到達するために追加のツールを検討したくなるかもしれません。
- サポートワークフローのさらなる合理化: JSMは記事の提案において優れた仕事をします。これをさらに進めたいチームにとって、AIレイヤーは記事から直接回答を提供することで、顧客や担当者が手動でドキュメントをスキャンする手間を省くのに役立ちます。
- 他のプラットフォームからのナレッジの統合: 会社のナレッジはConfluenceから始まることが多いですが、規模が拡大するにつれて、 Google ドキュメント、 Notion、あるいはSlackのスレッドにもデータが存在するようになります。これらすべてのソースを1つの「脳」に集約するツールを使用することで、Atlassian中心の設定を拡張できます。
- 大量のコンテンツ更新の管理: ナレッジベースは生きた資産です。Confluenceは編集を容易にしますが、規模が大きくなるにつれて、膨大なライブラリを最新の状態に保つことは、継続的な大きな管理タスクになります。スマートなツールは、実際のサポートチケットに基づいて、ドキュメントのギャップがどこにあるかを正確に特定するのに役立ちます。
- 複雑なリアルタイムデータの要求への対応: 標準的なConfluence記事は、優れた情報源です。顧客が自分の特定の注文状況を確認できるようにするなど、より高度なユースケースの場合、Atlassianナレッジベースをライブデータベースや Shopify のようなプラットフォームと統合するAIで補完することができます。
AIでAtlassianナレッジベースを強化する方法
高まるニーズに対応するための最善の方法は、Atlassianの設定を変更することではありません。あなたはすでに素晴らしい、信頼できる基盤を構築しています。答えは、Atlassianのエコシステム内で動作するスマートなAIレイヤーを上に追加することです。これこそが eesel AI のようなツールが設計された目的であり、既存のスタックに直接プラグインして、真に 自動化されたサポート を提供します。
Wikiだけでなく、すべてのナレッジを統合する
eesel AIはConfluenceに限定されず、最初から100以上のソースに接続できます。Confluenceスペースに接続できるだけでなく、Google ドキュメント、Notion、過去のヘルプデスクチケットなどとも連携可能です。
これにより、Jiraと並行して機能する、サポートAIのための単一の統合された「脳」が作成されます。会社のあらゆる隅々から情報を引き出すことができるため、Atlassian主導のワークフローがさらに強力かつ正確になります。
手動検索から自動解決へ
記事へのリンクを提案するだけでなく、eesel AIのエージェントは顧客の質問を読み、接続されたすべてのナレッジを検索して文脈を理解し、チャットの中で 直接、会話形式で回答 を提供します。
自律的にチケットを完全に解決し、適切なタグを付け、チケットをクローズしたり、真に複雑な場合には人間の担当者に引き継いだりすることができます。これにより、単純なチケットの削減から真のチケット自動化へと移行し、チームは影響力の大きい業務に集中できるようになります。
プロのヒント: eesel AIのシミュレーションモードを使用すると、何千もの過去のチケットでAIをテストし、顧客とやり取りする前にその解決率を確認できます。まずはシンプルなトピックから自動化し、慣れてくるにつれてその責任範囲を広げていくことができます。
Atlassianナレッジベースのギャップを自動的に埋める
Atlassianナレッジベースを最新の状態に保つための最良の方法の1つは、解決済みのチケットを分析することです。担当者が新しい質問に対して素晴らしい回答を提供したことを検知すると、eesel AIはそのやり取りに基づいて新しいナレッジベース記事のドラフトを自動的に作成できます。
これにより、サポートチームは余計な労力をかけずにコンテンツ生成マシンへと変わり、実績のある現実世界の回答でConfluenceライブラリを更新し続けることができます。
| 機能 | Atlassianナレッジベース (標準) | Atlassian KB + eesel AI |
|---|---|---|
| ナレッジソース | 包括的なConfluence/Atlassianスイート | Confluence、Google ドキュメント、Notion、過去のチケットなど |
| サポートワークフロー | スマート検索と記事の提案 | 自動回答とチケット解決 |
| コンテンツ作成 | 手動での記事執筆 | チケットからの自動ドラフト生成 |
| セットアップ時間 | 内蔵テンプレートによる迅速なセットアップ | 数分でAIエージェントを稼働可能 |
| アクション | 信頼できる静的な情報の提供 | ライブデータの参照とトリアージのアクションの実行 |
Atlassianナレッジベースの基盤を構築し、それを自動化する
Atlassianナレッジベースは素晴らしい出発点です。ConfluenceとJira Service Managementを組み合わせて使用することで、情報を整理し、よくある質問を削減し、担当者がより早く回答を見つけられるようにするための、成熟した信頼できるシステムを手に入れることができます。これは、プロフェッショナルなチームにとって標準的な選択肢です。
チームが成長し、 2026年における即時24時間365日のサポート を提供することを目指すなら、このセットアップをさらに強化できます。 eesel AIのような AI自動化レイヤー を追加することで、信頼できるライブラリをプロアクティブなサポートエージェントに変えることができます。それはすべてのデータから学習し、直接的な回答を提供し、問題を自動的に解決することで、Jiraで構築したナレッジの価値を最大限に引き出します。
あなたのナレッジベースの本当の実力を確かめる準備はできていますか? わずか数分で Atlassianナレッジベースをeesel AIに接続 し、どれほどの成果を上げられるか体験してください。
よくある質問
現在、ドキュメントが全くありません。最初のAtlassianナレッジベースを構築する際、どこから始めるのが最適ですか?
まずは、影響力の大きいコンテンツに絞って小さく始めましょう。サポートチームに、頻繁に回答している上位5〜10件の質問を確認し、それらの問題に対するシンプルなハウツー記事やトラブルシューティング記事を最初に作成します。このアプローチにより、即座に価値を提供でき、勢いをつけることができます。
社内チームと社外の顧客の両方に同じAtlassianナレッジベースを使用できますか?
技術的には可能ですが、通常はターゲットごとにConfluenceスペースを分ける方が賢明です。これにより、コンテンツのトーンや技術的な深さを適切に調整でき、権限設定によって機密性の高い社内情報が顧客に公開されないようにすることができます。
Atlassianナレッジベースのコンテンツが古くなるのを防ぐための最善の方法は何ですか?
重要なのは、明確な所有権とレビュープロセスを確立することです。コンテンツのカテゴリごとに担当者を割り当て、定期的なサイクル(例:四半期ごと)で記事のレビューと更新を行うようにします。eesel AIのようなツールを使用すると、新しいサポートチケットに基づいてナレッジの不足を自動的に特定することもできます。
Atlassianナレッジベースを作成するには、ConfluenceとJSMの別々のライセンスが必要ですか?
はい、通常はConfluenceとJira Service Managementの両方の有効なサブスクリプションが必要です。これらは密接に統合してナレッジベース機能を提供する別個の製品であり、Confluenceはコンテンツのリポジトリ(保存場所)として、JSMはヘルプポータルとして機能します。
標準の検索機能がすでに優れている場合、AtlassianナレッジベースにAIツールを追加する必要が本当にあるのでしょうか?
標準の検索は記事へのリンクを提案するだけなので、担当者や顧客は特定の回答を見つけるために手動で作業する必要があります。AIレイヤーは、会話形式で直接的な回答を提供し、自律的にチケットを完全に解決することも可能です。また、Confluenceにあるものだけでなく、会社全体のあらゆるナレッジから学習します。