
まとめ
AA-BriefcaseはArtificial Analysisによる新しいベンチマークで、AIモデルを単発の質問ではなく実際の数週間のナレッジワーク(財務モデル、取締役会向けプレゼン、製品仕様書)で評価します。各モデルには数千の乱雑なファイル(メール、Slackスレッド、スプレッドシート)が与えられ、実際の成果物を制作する必要があり、それが正確性、分析品質、プレゼンテーションで採点されます。
主要な発見は謙虚にさせるものです。最高のモデルでも、全てのルーブリックチェックをパスするのはタスクの3%にすぎず、91タスク中31タスクではどのモデルも50%を超えません。Claude Fable 5がリーダーボードをリードし、オープンウェイトのGLM-5.2がそのコストをはるかに超える性能を発揮しています。
多くの記事が触れない点がこれです:ベンチマークの高スコアはモデルが一般的に優秀であることを示しますが、あなたのデータで安全であることを意味しません。このギャップが、AIカスタマーサービスを検討している方に対して、リーダーボードを信頼するだけでなく、実際の過去のデータでテストすることを推奨する理由です。
私はeeselでAIエージェントを専門に構築しています。些末な知識ではなく、乱雑な実際の仕事をついに測定するベンチマークは、すべてを置いて読まずにいられないものです。以下では、AA-Briefcaseが実際に何を測定し、どう評価し、誰がリードしているか、そしてAIエージェントの展開に際して学ぶべき一つの教訓を説明します。
AA-Briefcaseが実際に測定するもの
ほとんどのAIベンチマークは短く独立した質問をします:数学の問題、コーディングパズル、選択式クイズ。これは純粋な推論能力を測るには適していますが、実際の職場でのモデル活用とは大きく異なります。実際のナレッジワークは長く、曖昧で、混乱した状況に埋め込まれています。
AA-Briefcaseはそのギャップを埋めるために作られました。プロンプト一つの代わりに、各モデルは多くの連携したタスクと数千のソースファイルを含む数週間のビジネスプロジェクトに投入され、実際のアナリストやPMが作るような成果物(財務モデル、取締役会向けプレゼン、デザインモックアップ、戦略メモ)の作成を求められます。シナリオは、Google、McKinsey、Boston Consulting Groupなどの企業の業界専門家によって数ヶ月かけて開発されたため、実際の業務に近い内容になっています。
規模感を示す数字があります。4つの非公開プロジェクトシナリオと合計91タスクがあり、データサイエンス、プロダクトマネジメント、企業戦略から抽出されています。その中には約2,000のソースファイルがあり、3,500件以上のメールと25,000件のSlackメッセージが意図的に断片化され、現実的な矛盾に満ちています。4つの採点シナリオは、データサイエンスプロジェクト、プロダクトマネジメントプロジェクト、銀行業務変革、重工業戦略構築です。5番目のデューデリジェンスシナリオは公開されており、スコアにはカウントされません。
この枠組みが重要な理由は、私がこれまでリリースしてきた全てのAIエージェントの失敗モードを反映しているからです。モデルが苦労するのはアイデアではなく、1,400番目のファイルに隠れた要件を見つけ、それを静かに上書きしたメールと矛盾しないようにすることです。
AA-Briefcaseがモデルを評価する方法
ここでAA-Briefcaseが巧みになります。一つのスコアでは、AI出力で最も興味深いことが隠れてしまいます。プロフェッショナルに見えることと正確であることは、全く異なる二つのスキルです。そのため、各タスクは3つの独立した次元で評価されます。
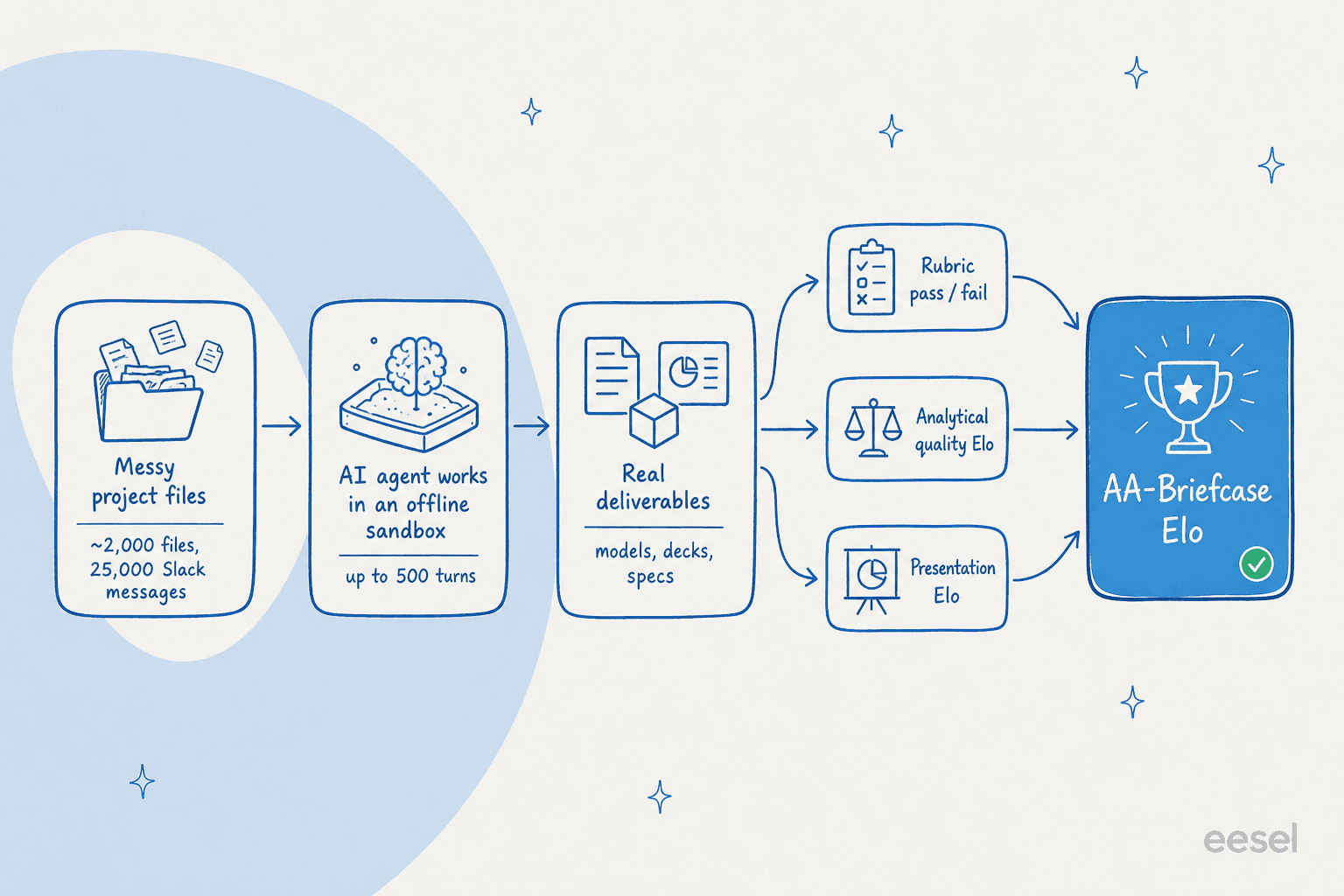
第一はバイナリルーブリック:各チェックで合格か不合格か、部分点なし。モデルは指示に従ったか、ファイル全体に散らばった要件を見つけ出したか、正しいエビデンスを使用したか、正しい結論に達したか?第二は分析品質で、他のモデルの提出物とのペアワイズ比較で判断されます。どちらの成果物がより徹底的でより裏付けられているか?第三はプレゼンテーションで、これもペアワイズです:どちらの出力がよりプロフェッショナルに仕上がっているか?
これら三つが一つのメインスコアであるAA-Briefcase Eloに統合されます。分析品質Elo、プレゼンテーションElo、ルーブリック合格率を最大尤度Elo集約で組み合わせます。同一ファミリーのモデルが自分に有利な評価をしないよう、各比較は3モデルの審査員パネル(Claude Opus 4.8、GPT-5.5、Gemini 3.1 Pro Preview)が決定します。
インフラも公開されています。モデルはArtificial AnalysisのオープンソースエージェントハーネスStirrup上で、インターネットのないオフラインサンドボックス内で、タスクあたり最大500ターンで動作します。本格的な設定であり、チャットウィンドウよりも実際のエージェンティックワークフローにはるかに近いです。
結果が実際に示すもの
上部のリーダーボードは喜ばしい話(Claude Fable 5が首位、能力の階層がきれいに積み重なっている)を伝えています。より難しい話は合格率にあります。
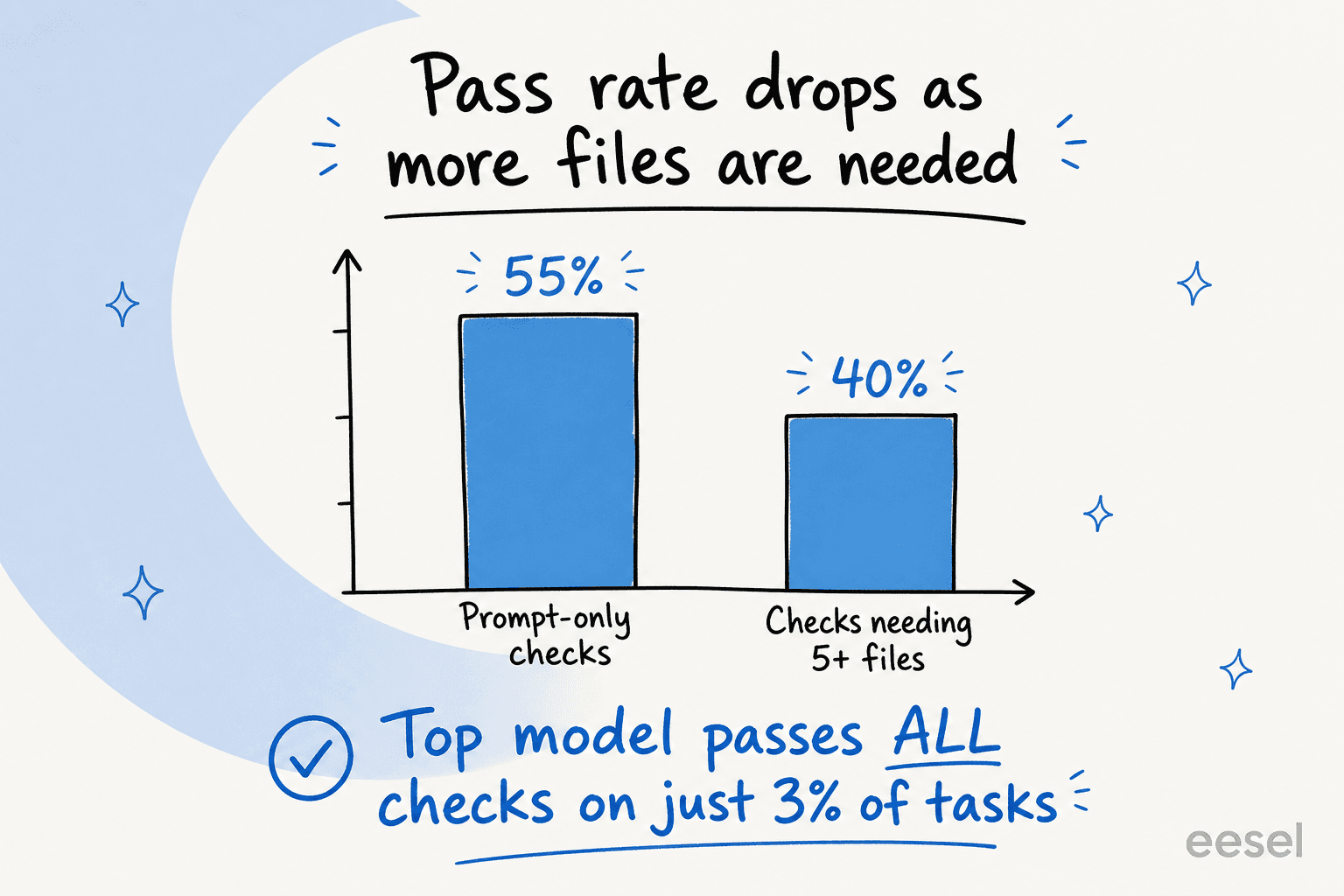
リードモデルでさえ、全てのルーブリック基準を満たすのはタスクの3%のみであり、91タスク中31タスクではどのモデルも50%を超えません。難易度は必要なファイル数とともに上昇します。高知能モデルはプロンプトのみのチェックで約55%から、タスクに5つ以上必要になると約40%まで落ちます。タスクが実際の仕事に似れば似るほど、全員の成績が悪くなります。
リーダーボードからいくつかの重要な示唆が得られます。GLM-5.2は明確なオープンウェイトのリーダーであり、価格対性能の際立った存在で、Claude Opus 4.8より約90Elo低いにもかかわらず、コストは4分の1以下です。MiniMax-M3とGLM-5.2はいずれも一般的な知能スコアを上回りますが、GoogleのGeminiモデルは広範な知能ランキングでの位置に比べてAA-Briefcaseでは実際に低いパフォーマンスを示しています。ウィジェットのコスト表示が示すように、最も高いモデルと最も安いモデルの差は800×以上であり、AIエージェントの実際のコストと本当に重要な指標を比較検討する際に有益な注意点です。
「正しく見えるが間違っている」という問題
リリース全体で私のお気に入りの発見は行動に関するもので、AIの作業が信頼できないと感じられる理由の多くを説明しています。
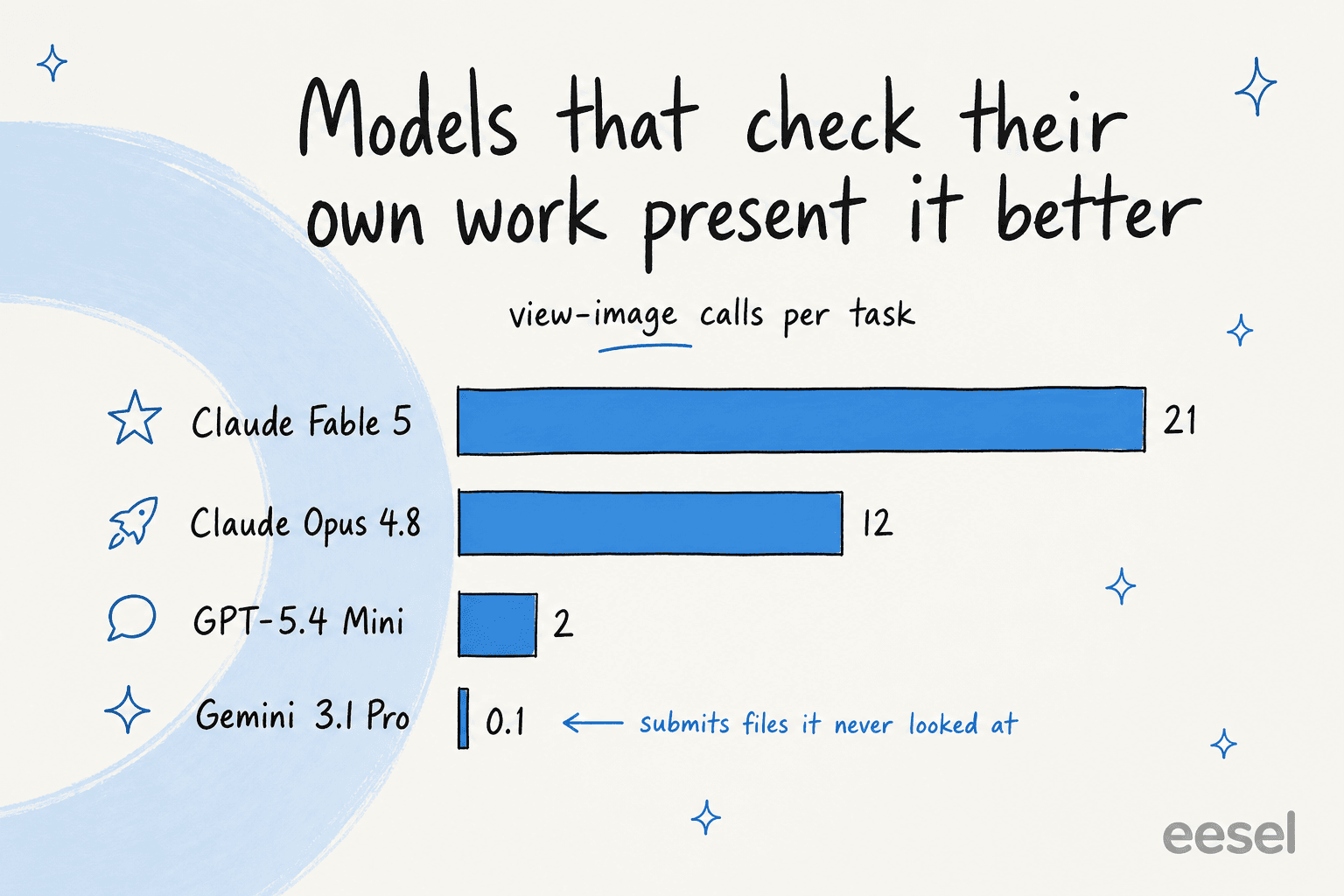
プレゼンテーションで最高得点を取るモデルは、自分のレンダリングされた出力を実際に確認しているものです。Claude Fable 5はタスクあたり約21回のview-image呼び出しを行い、Opus 4.8は約12回でしたが、一部のモデルはほとんど見ていないファイルを提出しました(Gemini 3.1 Pro Previewは平均約0.1回のview-image呼び出し)。「提出前に自分の仕事を確認する」というアドバイスは、人間と同様にAIにとっても良いアドバイスであることがわかります。
その下にはより深い点があります。AA-Briefcaseが磨きと正確性を分けるのは、まさに静かに間違っている自信満々でよく整形された回答は、明らかに不完全なものより危険だからです。これはAIチャットボットが顧客に答える時に現れるリスクそのものであり、サポートにおいてハルシネーションを防ぐことが付加的な機能ではなく核心である理由です。
リーダーボードのスコアがデプロイ計画でない理由
つまり、フロンティアモデルは実際のナレッジワークを時に見事にこなせますが、最も難しいファイル量の多いタスクではほとんどの場合失敗します。AA-Briefcaseから一つのことを学ぶとすれば、これです:ベンチマークの順位は一般的な能力シグナルであり、モデルがあなたの乱雑なデータでどう振る舞うかの約束ではありません。
これを直接経験してきました。私たちは何年もかけてAIエージェントをライブサポートキューに投入してきました。チームを困らせるのは、基盤となるモデルが抽象的に十分賢いかどうかではなく、そのモデルが特定のチケット、製品の特性、エッジケースで正確であり続けるかどうかです。全ての公開リーダーボードをリードするモデルでも、自動チケット解決に達するはるか前の初日に、自信を持って返金ポリシーを誤って伝えることがあります。これはモデルへの批判ではなく、ベンチマークと本番環境の違いです。
解決策はAA-Briefcaseが基盤とする直感と同じです:信頼する前に根拠に基づいて作業を評価する。ヘルプデスクにとって、それは自社の過去のチケットに対してAIを実行し、仕様書を読んで希望を持つのではなく、何と答えたかを正確に確認することを意味します。テストセットが実際のサポート履歴である、自社プライベートAA-Briefcaseを実行するようなものだと考えてください。
本当に信頼できるAIサポートのためにeeselを試す
AA-Briefcaseが能力と信頼性は同じではないと納得させてくれたなら、それはまさにeesel AIが解決するために作られた問題です。eeselは既存のヘルプデスクとナレッジベースに数分で接続する新しいサポートチームメンバーのように機能し、顧客と話す前に数千の過去チケットでシミュレーションを行えるため、リーダーボードから推測するのではなく、実際の解決率と正確な回答を事前に確認できます。

何に答えることを許可するか、いつエスカレーションするかをコントロールでき、自社のデータで無料で試せます。カスタマーサービス向けAIを評価しているなら、このシミュレーション優先アプローチは、AA-Briefcaseの「実際の仕事で証明する」という厳格さを自社のキューに持ち込む最も近い方法です。
よくある質問
AA-Briefcaseベンチマークとは何ですか?
AA-BriefcaseでどのAIモデルが最も優れていますか?
AA-Briefcaseのスコアはどのように算出されますか?
なぜAIモデルはAA-Briefcaseで低スコアになるのですか?
AA-Briefcaseの高スコアはモデルが安全にデプロイできることを意味しますか?
AA-Briefcaseは他のAIベンチマークとどう違いますか?
AA-Briefcaseをカスタマーサポート向けAIツール選びに使えますか?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.








