
L'IA fait fureur dans le domaine du support client en ce moment, avec des promesses de réponses instantanées qui libèrent votre équipe. Mais que vous envisagiez un simple chatbot ou un agent entièrement autonome, son succès repose sur une seule chose : la qualité de ses données d'entraînement.
C'est là que de nombreuses équipes se retrouvent en difficulté. Il existe un mythe courant selon lequel il faudrait trouver (ou créer) des ensembles de données externes massifs pour lancer une IA. Cette voie est souvent compliquée, coûteuse et peut mener à des outils d'IA biaisés qui ne fonctionnent tout simplement pas comme annoncé.
Clarifions tout cela. Nous allons expliquer ce que sont réellement les données d'entraînement pour l'IA, passer en revue les pièges courants liés à leur sourcing et vous montrer une approche beaucoup plus pratique pour votre équipe de support, une approche qui utilise les connaissances que vous possédez déjà.
Qu'est-ce que les données d'entraînement pour l'IA ?
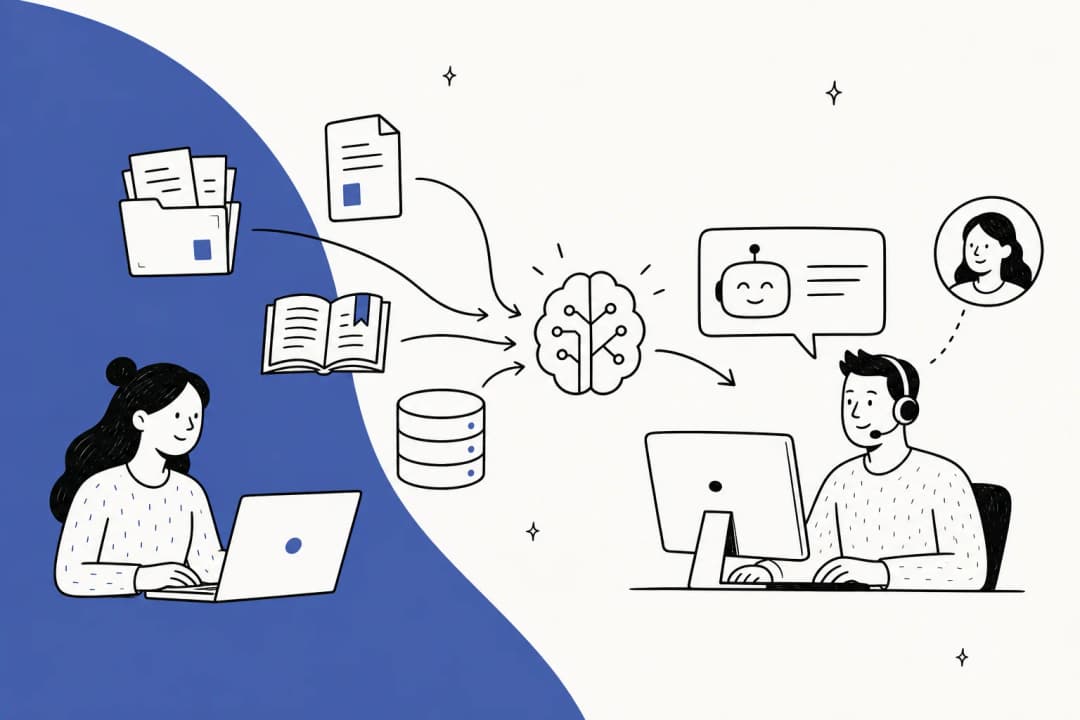
Pour faire simple, les données d'entraînement pour l'IA sont les informations que vous fournissez à un modèle d'apprentissage automatique pour lui apprendre à faire son travail. Considérez-les comme la collection de manuels, de plans de cours et d'exemples pratiques pour une IA qui débute. Pour une IA de support, cela signifie une tonne d'exemples de vraies questions de clients associées aux bonnes réponses. Plus l'IA voit d'exemples pertinents et de haute qualité, mieux elle parvient à reconnaître les schémas et à donner des réponses solides par elle-même.
Une bonne façon de voir les choses est de comparer cela à l'intégration d'un nouvel agent de support dans l'équipe. Vous ne lui jetteriez pas un tas d'articles aléatoires trouvés sur Internet en lui souhaitant bonne chance. Vous lui donneriez accès à votre centre d'aide, vous lui feriez observer des agents expérimentés et vous partageriez vos manuels internes. La même logique s'applique à votre IA.
Bien faire les choses est essentiel. Des données d'entraînement de qualité et pertinentes mènent à des résolutions précises, ce qui se traduit par des clients plus satisfaits et des coûts réduits. D'un autre côté, fournir à votre IA des données génériques ou de mauvaise qualité est la recette du désastre. Vous vous retrouvez avec des conversations frustrantes et hors de propos qui rendent les clients fous et créent encore plus de travail pour vos agents humains.
L'ancienne méthode de sourcing des données d'entraînement pour l'IA (et ses problèmes)
De nombreuses équipes se heurtent à un mur parce qu'elles pensent devoir "trouver" ou "créer" des données à partir de zéro. Cette approche traditionnelle est truffée de problèmes qui peuvent stopper net un projet d'IA.
Utiliser des ensembles de données publics et open-source
Cela signifie prendre des ensembles de données publiquement disponibles sur des sites comme Kaggle ou des archives universitaires pour entraîner un modèle. Le problème flagrant ici est que ces données sont complètement génériques. Elles ne savent rien de votre entreprise, de vos produits ou du jargon spécifique que vos clients utilisent. Une IA entraînée de cette manière sonnera comme un robot et sera déconcertée par toute question un tant soit peu spécifique à votre entreprise, la rendant assez inutile dans le monde réel.
Le web scraping et l'achat d'ensembles de données
Certaines entreprises se tournent vers des outils automatisés pour extraire des informations sur le web ou achètent d'énormes ensembles de données auprès de fournisseurs tiers. Toute cette approche est un champ de mines éthique et légal. Comme l'ont rapporté des médias tels que Scientific American, vous pourriez facilement finir par entraîner votre IA sur du matériel protégé par des droits d'auteur ou des données utilisateur privées. Cela peut entraîner de sérieux problèmes juridiques et nuire à la réputation de votre marque. En plus de cela, vous n'avez aucun contrôle réel sur la qualité ou les biais déjà présents dans ces ensembles de données.
Créer manuellement des données d'entraînement
C'est là que vous payez une équipe de personnes pour rédiger manuellement des milliers de paires de questions-réponses à utiliser comme matériel d'entraînement. Le problème est que ce processus est incroyablement lent, coûteux et un véritable cauchemar à faire évoluer. Il est presque impossible pour une équipe d'anticiper chaque problème qu'un client pourrait rencontrer. Et dès que vos produits ou politiques changent, tout cet ensemble de données est obsolète, et vous devez recommencer ce processus coûteux.
Trois grands défis liés aux données d'entraînement pour l'IA que vous ne pouvez pas ignorer
Au-delà des maux de tête logistiques, ces méthodes traditionnelles de collecte de données d'entraînement pour l'IA créent des problèmes fondamentaux qui peuvent complètement saper l'efficacité et l'équité de votre IA.
Le problème de la qualité et de la pertinence
Plus de données ne signifie pas toujours mieux. Un modèle d'IA pour une marque de e-commerce échouera lamentablement s'il est entraîné sur un ensemble de données générique pour le support informatique. L'information doit être directement liée à ce que vos clients demandent réellement. Fournir à une IA des données non pertinentes est pire que simplement inutile ; cela enseigne au modèle les mauvaises choses et conduit à des réponses confiantes mais complètement fausses qui peuvent briser la confiance des clients.
Une meilleure méthode : Les données les plus pertinentes que vous puissiez trouver sont votre propre historique de conversations clients réussies. Les plateformes modernes comme eesel AI sont conçues pour puiser directement dans cette source. Elles peuvent analyser vos anciens tickets de support pour apprendre automatiquement sur vos problèmes clients spécifiques, la voix de votre marque, et à quoi ressemble une bonne réponse.
Le piège des biais cachés
Les modèles d'IA peuvent facilement capter et même amplifier les biais présents dans leurs données d'entraînement, un fait souligné par des recherches d'institutions comme Penn State. Si un ensemble de données surreprésente une catégorie démographique, l'IA pourrait avoir de mauvaises performances ou être injuste pour d'autres. Ce n'est pas seulement un problème technique ; c'est un risque énorme pour votre marque. Une IA biaisée peut créer des expériences négatives et aliénantes pour des groupes entiers de vos clients.
Une meilleure méthode : Utiliser vos propres interactions clients diversifiées est la meilleure défense contre cela. Votre IA apprend de votre base d'utilisateurs réelle, et non d'un ensemble de données public biaisé qui ne reflète pas votre public.
Le besoin constant de mises à jour
Votre entreprise est en constante évolution. Les produits sont mis à jour, les politiques sont révisées et de nouvelles promotions sont lancées. Un ensemble de données créé ou extrait il y a six mois est déjà obsolète. Mettre à jour et ré-entraîner manuellement un modèle d'IA est un effort et une dépense continus énormes, ce qui rend incroyablement difficile pour votre IA de suivre le rythme de votre entreprise.
Une meilleure approche : utilisez les connaissances que vous possédez déjà
La bonne nouvelle, c'est que la meilleure source de données d'entraînement pour l'IA n'est pas quelque chose que vous devez aller chercher, ce sont les connaissances que vous avez déjà constituées. Elles sont de haute qualité, parfaitement pertinentes, sécurisées et toujours à jour.
Entraînez votre IA sur les anciens tickets de support
Votre service d'assistance est une mine d'or de données d'entraînement. Toutes ces conversations passées contiennent les questions exactes que vos clients posent et les réponses réussies que vos meilleurs agents ont fournies. En analysant ces données, une IA peut apprendre automatiquement la voix de votre marque, les étapes de dépannage courantes et ce à quoi ressemble une excellente résolution, sans aucune saisie manuelle de données. Des plateformes comme eesel AI peuvent se connecter à votre service d'assistance en un seul clic et commencer à apprendre de ces conversations immédiatement.

Unifiez les connaissances de votre centre d'aide et de vos wikis internes
Votre documentation officielle, comme les articles du centre d'aide, les FAQ et les wikis internes, est votre unique source de vérité. L'intégration de ces éléments garantit que votre IA donne des réponses cohérentes, précises et parfaitement conformes aux directives de votre entreprise. Au lieu d'un projet désordonné de type "tout jeter et recommencer", une plateforme comme eesel AI rassemble de manière transparente toutes ces sources, se connectant aux connaissances d'outils comme Confluence ou Google Docs en quelques minutes seulement.

De l'apprentissage réactif à la création proactive de connaissances
Cette approche met également en place une puissante boucle de rétroaction. L'IA n'utilise pas seulement vos connaissances existantes ; elle vous aide à les améliorer. En analysant les questions entrantes, le système peut repérer des lacunes dans votre documentation où les clients se retrouvent fréquemment bloqués. Les plateformes avancées comme eesel AI vous fournissent des rapports qui mettent en évidence ces lacunes et peuvent même aider à transformer des résolutions de tickets réussies en brouillons d'articles pour votre centre d'aide, rendant ainsi l'ensemble de votre base de connaissances plus intelligente au fil du temps.

Le coût des données d'entraînement pour l'IA : de l'acquisition des données à la tarification des plateformes
La voie traditionnelle pour obtenir des données d'entraînement pour l'IA s'accompagne de coûts élevés et imprévisibles. Vous devez prévoir des frais pour les annotateurs de données, des paiements aux fournisseurs et des tonnes d'heures d'ingénierie consacrées uniquement au nettoyage et au traitement des données.
En revanche, les plateformes d'IA modernes offrent un coût beaucoup plus clair et prévisible. Au lieu de payer pour le processus désordonné d'obtention des données, vous payez un abonnement forfaitaire pour un service qui gère tout pour vous.
| Forfait | Mensuel (facturé mensuellement) | Effectif /mois Annuel | Bots | Interactions IA/mois | Fonctionnalités clés |
|---|---|---|---|---|---|
| Équipe | 299 $ | 239 $ | Jusqu'à 3 | Jusqu'à 1 000 | Entraînement sur site web/docs ; Copilot pour centre d'aide ; Slack ; rapports. |
| Entreprise | 799 $ | 639 $ | Illimité | Jusqu'à 3 000 | Tout du forfait Équipe + entraînement sur les anciens tickets ; MS Teams ; Actions IA (tri/appels API) ; simulation en masse ; résidence des données en UE. |
| Personnalisé | Contacter le service commercial | Personnalisé | Illimité | Illimité | Actions avancées ; orchestration multi-agents ; intégrations personnalisées ; conservation des données personnalisée ; sécurité / contrôles avancés. |
Vos meilleures données d'entraînement pour l'IA sont déjà les vôtres
L'ancienne méthode de sourcing de données d'entraînement pour l'IA est dépassée. Elle est trop lente, trop coûteuse et tout simplement trop risquée pour que la plupart des équipes de support puissent la gérer efficacement.
La véritable clé d'une automatisation réussie du support est d'utiliser les données de haute qualité et parfaitement pertinentes que vous possédez déjà, qui se trouvent dans votre service d'assistance, vos documents et vos wikis internes. C'est cette information qui contient la voix unique de votre marque et les solutions éprouvées dont vos clients ont besoin.
Avec la bonne plateforme, vous n'avez pas besoin d'une équipe de data scientists pour construire une IA de support de premier ordre. Vous avez juste besoin d'un moyen de débloquer les connaissances expertes que votre équipe a déjà créées.
Prêt à ne plus vous soucier des données d'entraînement pour l'IA et à commencer à automatiser votre support ? eesel AI se connecte à vos outils existants en quelques minutes pour entraîner un puissant agent IA sur vos propres connaissances. Essayez-le gratuitement dès aujourd'hui.
Questions fréquemment posées
Que sont exactement les données d'entraînement pour l'IA, et pourquoi sont-elles si cruciales pour une automatisation efficace du support client ?
Les données d'entraînement pour l'IA sont les informations fournies à un modèle d'IA pour lui apprendre à répondre. Pour le support, il s'agit de questions de clients associées à des réponses. Leur qualité détermine directement la précision et l'utilité avec lesquelles votre IA peut résoudre les problèmes des clients.
Mon équipe envisage d'utiliser des ensembles de données publics ; quels sont les risques associés à ce type de données d'entraînement pour l'IA ?
Les ensembles de données publics sont génériques et ne comprendront pas les spécificités de votre entreprise, ce qui rendra l'IA inutile. Ils manquent souvent de pertinence, contiennent des biais et ne peuvent pas répondre aux besoins uniques de vos clients, rendant l'IA inefficace dans des scénarios réels.
Quels sont les principaux défis ou pièges si nous utilisons des données d'entraînement pour l'IA de mauvaise qualité ou non pertinentes pour notre IA de support ?
Des données d'entraînement pour l'IA de mauvaise qualité peuvent apprendre de mauvaises choses à votre IA, ce qui conduit à des réponses assurées mais incorrectes. Cela nuit à la confiance des clients, crée des expériences frustrantes et génère finalement plus de travail pour vos agents humains, annulant les avantages de l'automatisation.
Comment pouvons-nous empêcher les biais de s'infiltrer dans nos données d'entraînement pour l'IA lors de la création d'un bot de support ?
La meilleure façon d'atténuer les biais est d'entraîner votre IA sur vos propres interactions clients diversifiées. Cela garantit que l'IA apprend de votre base d'utilisateurs réelle, plutôt que d'ensembles de données publics potentiellement biaisés qui pourraient ne pas refléter votre public ou conduire à des résultats équitables pour tous les clients.
La création manuelle de toutes nos données d'entraînement pour l'IA est-elle une solution évolutive pour une équipe de support en croissance ?
La création manuelle de données d'entraînement pour l'IA est extrêmement chronophage, coûteuse et difficile à faire évoluer. Il est difficile d'anticiper tous les problèmes des clients, et les données deviennent rapidement obsolètes à mesure que vos produits ou politiques changent, nécessitant des mises à jour constantes et coûteuses.
À quelle fréquence nos données d'entraînement pour l'IA doivent-elles être mises à jour pour que notre agent de support IA reste actuel et efficace ?
Vos données d'entraînement pour l'IA nécessitent des mises à jour constantes pour refléter les changements de produits, de politiques et de promotions. Les plateformes modernes résolvent ce problème en apprenant continuellement des nouveaux tickets de support et en unifiant les sources de connaissances comme les centres d'aide, garantissant que votre IA reste à jour sans refonte manuelle.





Comment l'exploitation de nos conversations clients existantes peut-elle améliorer la qualité de nos données d'entraînement pour l'IA ?
Vos anciens tickets de support fournissent des exemples très pertinents de vraies questions de clients et de réponses réussies, avec la voix de votre marque. L'entraînement sur ces données garantit que votre IA apprend de vos utilisateurs réels et du contexte spécifique de votre entreprise, ce qui conduit à des résolutions plus précises.