So verhindern Sie doppelte Tickets mit Idempotenzschlüsseln in der Zendesk-API
Stevia Putri
Zuletzt bearbeitet March 2, 2026
Netzwerkfehler kommen vor. Ihre API-Anfrage läuft ab, sodass Ihr Client sie wiederholt. Ohne entsprechende Schutzmaßnahmen erstellt dieser Wiederholungsversuch ein zweites Ticket, ein drittes Ticket, und plötzlich hat Ihr Kunde drei identische Supportanfragen im System. Idempotenzschlüssel lösen dieses Problem, indem sie sicherstellen, dass wiederholte Anfragen mit demselben Schlüssel dasselbe Ergebnis liefern, ohne Duplikate zu erstellen.
Wenn Sie Integrationen mit der Zendesk API erstellen, ist das Verständnis von Idempotenzschlüsseln nicht optional. Es ist unerlässlich für produktionsreife Systeme, die echte Kundendaten verarbeiten.
Was sind Idempotenzschlüssel und warum sind sie wichtig?
Ein Idempotenzschlüssel ist eine eindeutige Kennung, die Clients in API-Anfragen einfügen. Wenn Ihr Server eine Anfrage empfängt, prüft er, ob er diesen Schlüssel bereits gesehen hat. Wenn der Schlüssel neu ist, wird die Anfrage normal verarbeitet und das Ergebnis gespeichert. Wenn der Schlüssel vorhanden ist, wird das gespeicherte Ergebnis zurückgegeben, ohne den Vorgang erneut auszuführen.
Das Konzept stammt aus der Mathematik, wo eine idempotente Operation das gleiche Ergebnis liefert, egal ob sie einmal oder mehrmals ausgeführt wird. In API-Begriffen sollte das Senden eines Tickets mit demselben Idempotenzschlüssel fünfmal genau ein Ticket erstellen und jedes Mal dieselbe Antwort zurückgeben.
Hier ist, warum dies speziell für Zendesk wichtig ist. Die Ticketerstellung ist ein Schreibvorgang mit Nebenwirkungen. Jedes Ticket löst Benachrichtigungen, Routing-Regeln und potenziell SLA-Timer aus. Das Erstellen doppelter Tickets verstopft nicht nur Ihr System. Es verschwendet die Zeit der Agenten, verwirrt Kunden, die mehrere Bestätigungen erhalten, und verzerrt Ihre Metriken.
Reale Szenarien, in denen Idempotenz Sie rettet:
- Payment Webhooks Ihr Zahlungsabwickler sendet einen Webhook, um ein Ticket für fehlgeschlagene Transaktionen zu erstellen. Der Webhook wiederholt den Vorgang bei einem Timeout. Ohne Idempotenz erstellt jeder Wiederholungsversuch ein neues Ticket.
- Bulk-Importe Sie migrieren Tickets von einem alten System. Das Importskript stößt auf einen Netzwerkfehler und startet neu. Ohne Idempotenz erhalten Sie doppelte Datensätze.
- Mobile Apps Ein Benutzer tippt aufgrund von Verzögerungen zweimal auf "Senden". Ohne Idempotenz erstellt er zwei Tickets.
Das manuelle Erstellen einer zuverlässigen Wiederholungslogik ist komplex. Sie müssen verfolgen, welche Anfragen erfolgreich waren, Teilausfälle behandeln und den Zustand über verteilte Systeme hinweg abstimmen. Idempotenzschlüssel verlagern diese Komplexität auf die API-Schicht, wo sie hingehört.
Wenn Sie die Ticketerstellung automatisieren möchten, ohne diese Edge Cases selbst zu behandeln, verwaltet unser KI-Agent die Idempotenz automatisch als Teil seiner Zendesk-Integration.
Wie die Idempotenzschlüssel-Implementierung von Zendesk funktioniert
Zendesk implementiert Idempotenz über einen einfachen HTTP-Header. Um ihn zu verwenden, fügen Sie einen Idempotency-Key-Header mit einem eindeutigen Wert in Ihre Anfrage ein:
Idempotency-Key: {unique_key}
Der Wert kann eine beliebige Zeichenkette mit bis zu 255 Zeichen sein. Zendesk empfiehlt die Verwendung von UUIDs oder anderen Identifikatoren mit hoher Entropie.
Wenn Sie eine Anfrage mit einem Idempotenzschlüssel stellen, enthält die Antwort von Zendesk einen x-idempotency-lookup-Header:
x-idempotency-lookup: missDies ist das erste Mal, dass dieser Schlüssel gesehen wurde. Die Anfrage wird normal verarbeitet.x-idempotency-lookup: hitDieser Schlüssel wurde bereits verwendet. Zendesk gibt die zwischengespeicherte Antwort von der ursprünglichen Anfrage zurück.
Hier ist der entscheidende Punkt. Zendesk speichert Idempotenzschlüssel für 2 Stunden. Nach diesem Zeitraum wird eine Anfrage mit demselben Schlüssel als neu behandelt. Das bedeutet, dass Ihre Wiederholungslogik das Ablaufzeitfenster berücksichtigen muss. Wenn Sie eine Anfrage von gestern wiederholen, erstellen Sie ein Duplikat.
Zendesk validiert auch, dass Anfragen mit demselben Idempotenzschlüssel identische Parameter haben. Wenn Sie denselben Schlüssel mit einem anderen Betreff oder einer anderen Beschreibung senden, erhalten Sie einen 400-Fehler:
{
"error": "IdempotentRequestError",
"description": "Request parameters don't match the given idempotency key"
}
Dies verhindert den versehentlichen Missbrauch von Schlüsseln über verschiedene Operationen hinweg. Es bedeutet auch, dass Sie für jede einzelne Operation einen neuen Schlüssel generieren müssen und Schlüssel nicht über verschiedene Tickets hinweg wiederverwenden dürfen.
Wichtige Einschränkung: Der Idempotenzschlüssel wird nicht als Teil des Tickets gespeichert. Wenn Sie ein Ticket später abrufen, sehen Sie nicht, welcher Schlüssel verwendet wurde, um es zu erstellen. Wenn Sie diese Korrelation verfolgen müssen, speichern Sie sie in Ihrem eigenen System.
Nicht alle Zendesk-API-Endpunkte unterstützen Idempotenz. Der primäre Anwendungsfall ist die Ticketerstellung (POST /api/v2/tickets.json). Überprüfen Sie die offizielle Dokumentation für den spezifischen Endpunkt, den Sie verwenden.
Implementieren von Idempotenzschlüsseln in Ihrem Code
Lassen Sie uns eine praktische Implementierung durchgehen. Wir verwenden Python mit der Requests-Bibliothek, aber das Muster gilt für jede Sprache.
Schritt 1: Generieren Sie eindeutige Idempotenzschlüssel
Generieren Sie Ihren Idempotenzschlüssel, bevor Sie die erste Anfrage stellen, nicht während der Wiederholungsversuche. Der Schlüssel sollte pro logischer Operation eindeutig sein.
import uuid
idempotency_key = str(uuid.uuid4())
request_context = {
'idempotency_key': idempotency_key,
'payload': ticket_data,
'attempt': 0
}
Verwenden Sie UUIDv4 oder eine andere zufällige Zeichenkette mit mindestens 128 Bit Entropie. Vermeiden Sie vorhersehbare Muster wie Zeitstempel, fortlaufende IDs oder Hashes der Payload allein. Diese können kollidieren oder erraten werden.
Schritt 2: Fügen Sie den Header zu Ihren API-Anfragen hinzu
Fügen Sie den Idempotenzschlüssel in Ihren Anfrageheadern zusammen mit Ihrer Authentifizierung hinzu.
Python-Beispiel:
import requests
import os
subdomain = os.getenv('ZENDESK_SUBDOMAIN')
email = os.getenv('ZENDESK_EMAIL')
api_token = os.getenv('ZENDESK_API_TOKEN')
url = f'https://{subdomain}.zendesk.com/api/v2/tickets.json'
auth = (f'{email}/token', api_token)
headers = {
'Content-Type': 'application/json',
'Idempotency-Key': idempotency_key
}
data = {
'ticket': {
'subject': 'Payment failed notification',
'comment': {'body': 'Customer payment method declined'},
'requester': {'email': 'customer@example.com'}
}
}
response = requests.post(url, json=data, auth=auth, headers=headers)
cURL-Beispiel:
curl https://yourcompany.zendesk.com/api/v2/tickets.json \
-d '{"ticket": {"subject": "Test ticket", "comment": {"body": "This is a test"}}}' \
-H "Content-Type: application/json" \
-H "Idempotency-Key: 550e8400-e29b-41d4-a716-446655440000" \
-u your@email.com/token:your_api_token \
-X POST
JavaScript/Node.js-Beispiel:
const response = await fetch('https://company.zendesk.com/api/v2/tickets.json', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': 'Basic ' + Buffer.from(`${email}/token:${token}`).toString('base64'),
'Idempotency-Key': idempotencyKey
},
body: JSON.stringify(ticketData)
});
Schritt 3: Behandeln Sie Antworten und Wiederholungsversuche
Ihre Wiederholungslogik sollte den Antwortstatus und die Header überprüfen, um festzustellen, ob ein Wiederholungsversuch durchgeführt werden soll.
import time
def create_ticket_with_retry(ticket_data, max_retries=3):
idempotency_key = str(uuid.uuid4())
for attempt in range(max_retries + 1):
headers = {
'Content-Type': 'application/json',
'Idempotency-Key': idempotency_key
}
response = requests.post(
url,
json=ticket_data,
auth=auth,
headers=headers
)
# Check if this was a cached response
lookup_status = response.headers.get('x-idempotency-lookup')
if lookup_status == 'hit':
print(f"Request was cached (attempt {attempt + 1})")
# Success case
if response.status_code == 201:
return response.json()
# Idempotency mismatch - don't retry, this is a logic error
if response.status_code == 400 and 'IdempotentRequestError' in response.text:
raise ValueError(f"Idempotency key mismatch: {response.json()['description']}")
# Rate limited - wait and retry
if response.status_code == 429:
retry_after = int(response.headers.get('Retry-After', 60))
time.sleep(retry_after)
continue
# Server errors - retry with exponential backoff
if response.status_code in [500, 502, 503, 504]:
if attempt < max_retries:
backoff = (2 ** attempt) + (hash(idempotency_key) % 1000 / 1000)
time.sleep(backoff)
continue
# Client errors (4xx) - don't retry
response.raise_for_status()
raise Exception("Max retries exceeded")
Wichtige Punkte für Ihre Wiederholungslogik:
- Verwenden Sie denselben Idempotenzschlüssel für alle Wiederholungsversuche derselben logischen Operation
- Wiederholen Sie keine 400-Fehler mit
IdempotentRequestError- dies deutet auf einen Logikfehler in Ihrem Code hin - Beachten Sie Ratenbegrenzungen (429) mit dem
Retry-After-Header - Verwenden Sie exponentiellen Backoff für Serverfehler, um die API nicht zu überlasten
Weitere Informationen zur Struktur der Zendesk-Ticket-API finden Sie in unserem Leitfaden zum Erstellen von Zendesk-Tickets mit der API.
Best Practices für Produktionsimplementierungen
Sobald Sie die Grundlagen zum Laufen gebracht haben, sollten Sie diese produktionsreifen Praktiken berücksichtigen.
Schlüsselspeicherstrategien. Für Systeme mit hohem Volumen sollten Sie Idempotenzschlüssel in Ihrer eigenen Datenbank oder Ihrem Cache verfolgen. Dies ermöglicht Ihnen:
- Erkennen, ob ein Schlüssel bald abläuft (das 2-Stunden-Fenster von Zendesk)
- Überprüfen, welche Operationen erfolgreich waren oder fehlgeschlagen sind
- Implementieren Sie eine benutzerdefinierte Deduplizierungslogik, die über Zendesk hinausgeht
Redis ist eine beliebte Wahl dafür. Legen Sie eine TTL fest, die etwas kürzer ist als das 2-Stunden-Fenster von Zendesk, um Edge Cases zu vermeiden:
import redis
redis_client = redis.Redis(host='localhost', port=6379)
redis_client.setex(f"zendesk:idempotency:{key}", 5400, response_data)
Behandeln Sie gleichzeitige Anfragen. Wenn zwei Anfragen mit demselben Idempotenzschlüssel gleichzeitig eintreffen, verarbeitet Zendesk eine und gibt das zwischengespeicherte Ergebnis für die andere zurück. Ihr Client kann jedoch Race Conditions sehen. Implementieren Sie die Anfragededuplizierung auf Ihrer Anwendungsschicht, wenn dies ein Problem darstellt.
Request Fingerprinting. Um Fehler abzufangen, bei denen Sie versehentlich einen Schlüssel mit unterschiedlichen Parametern wiederverwenden, hashen Sie die Request-Payload und speichern Sie sie mit dem Idempotenzschlüssel. Überprüfen Sie vor dem Senden, ob der Hash übereinstimmt:
import hashlib
import json
def get_request_fingerprint(payload):
return hashlib.sha256(json.dumps(payload, sort_keys=True).encode()).hexdigest()
fingerprint = get_request_fingerprint(ticket_data)
store_key_with_fingerprint(idempotency_key, fingerprint)
if get_fingerprint_for_key(idempotency_key) != fingerprint:
raise ValueError("Payload changed for existing idempotency key")
Protokollierung und Überwachung. Verfolgen Sie die Verwendung von Idempotenzschlüsseln in Ihren Protokollen:
- Protokollieren Sie den Schlüssel und den
x-idempotency-lookup-Status für jede Anfrage - Warnen Sie bei hohen Raten von
hit-Antworten (kann auf übermäßige Wiederholungsversuche hindeuten) - Überwachen Sie auf
IdempotentRequestError(deutet auf Fehler hin)
Testen Sie Ihre Implementierung. Schreiben Sie Tests, die Ihre Idempotenzlogik überprüfen:
def test_duplicate_request_returns_same_ticket():
key = str(uuid.uuid4())
# First request
response1 = create_ticket(ticket_data, idempotency_key=key)
ticket_id = response1['ticket']['id']
# Second request with same key
response2 = create_ticket(ticket_data, idempotency_key=key)
assert response2['ticket']['id'] == ticket_id
assert response2.headers['x-idempotency-lookup'] == 'hit'
Häufige Fehler und wie Sie sie vermeiden können
Selbst erfahrene Entwickler machen diese Fehler bei der Implementierung von Idempotenz.
Verwenden von vorhersehbaren Schlüsselmustern. Zeitstempel, fortlaufende IDs oder einfache Hashes der Payload können kollidieren oder erraten werden. Verwenden Sie immer kryptografisch zufällige Werte wie UUIDv4.
Generieren neuer Schlüssel bei Wiederholungsversuchen. Der ganze Sinn ist es, denselben Schlüssel für Wiederholungsversuche zu verwenden. Wenn Sie bei jedem Versuch eine neue UUID generieren, erstellen Sie Duplikate, anstatt sie zu verhindern.
Ignorieren des 2-Stunden-Ablaufs. Wenn Ihre Wiederholungslogik mehr als 2 Stunden umfasst (vielleicht aufgrund längerer Ausfälle), funktioniert Ihr Idempotenzschlüssel nicht mehr. Implementieren Sie für lang laufende Prozesse Ihre eigene Deduplizierungsschicht.
Nichtbehandlung von Parameternichtübereinstimmungsfehlern. Wenn Sie einen IdempotentRequestError erhalten, ist dies normalerweise ein Fehler in Ihrem Code. Sie verwenden einen Schlüssel mit unterschiedlichen Daten wieder. Protokollieren Sie diese aggressiv und beheben Sie die Ursache.
Fehlerhafte Zwischenspeicherung von Fehlerantworten. Einige Implementierungen speichern alle Antworten zwischen, einschließlich 5xx-Fehler. Dies bedeutet, dass ein vorübergehender Serverfehler "hängen bleibt" und alle Wiederholungsversuche denselben Fehler zurückgeben. Speichern Sie nur erfolgreiche Antworten (2xx-Statuscodes) zwischen.
Race Conditions in gleichzeitigen Umgebungen. Ohne ordnungsgemäße Sperrung können zwei Threads beide auf das Vorhandensein eines Schlüssels prüfen, beide sehen, dass er fehlt, und beide Anfragen senden. Verwenden Sie atomare Operationen oder verteilte Sperren, wenn Sie hohe Volumina verarbeiten.
Automatisieren der Ticketerstellung ohne die Komplexität
Das Erstellen und Warten von API-Integrationen kostet Zeit. Sie müssen Authentifizierung, Fehlerwiederholungslogik, Ratenbegrenzung, Idempotenz und laufende Wartung bei Änderungen der APIs behandeln.
Wenn Ihr Ziel darin besteht, die Ticketerstellung zu automatisieren, anstatt eine benutzerdefinierte Integration zu erstellen, sollten Sie überlegen, ob Sie tatsächlich Code schreiben müssen. Tools wie eesel AI können die Ticketerstellung und -beantwortung ohne Entwicklungsaufwand übernehmen.
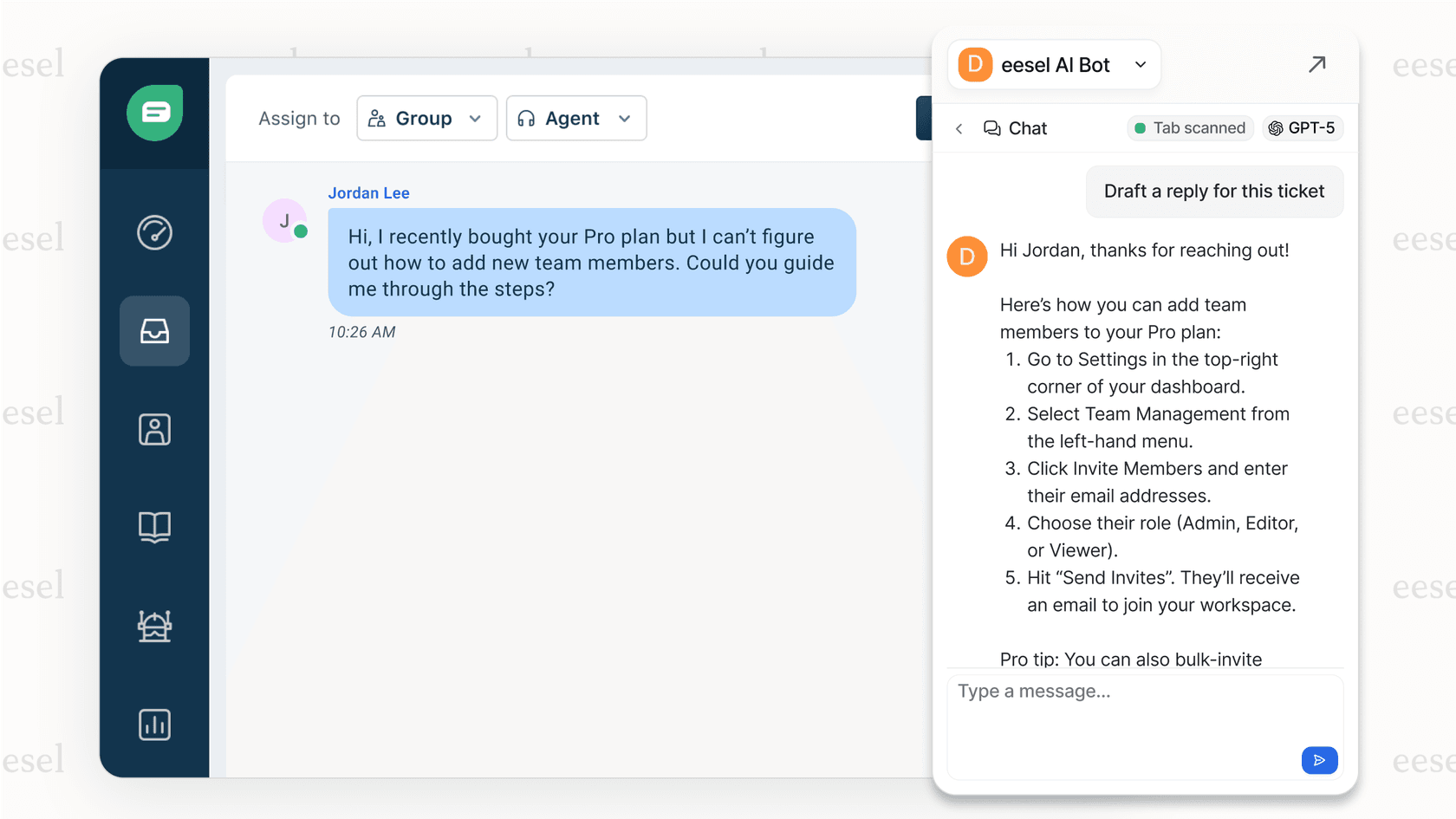
Hier ist der Unterschied. Mit dem API-Ansatz schreiben Sie Skripte, um Tickets zu erstellen, auf die Menschen antworten werden. Mit einem KI-Agenten trainieren Sie ein System, um Ihr Geschäft zu verstehen und den gesamten Ticketlebenszyklus zu verwalten, von der Erstellung bis zur Lösung. Sie verbinden es mit Ihrem Zendesk-Konto und es lernt aus Ihren vergangenen Tickets, Hilfeartikel und Makros.
Das progressive Rollout-Modell bedeutet, dass Sie damit beginnen, dass die KI Antwortentwürfe zur Überprüfung erstellt, und dann auf die vollständige Automatisierung ausweiten, sobald sie sich bewährt hat. Für Teams, die das Ticketvolumen reduzieren und nicht nur die Erstellung automatisieren möchten, liefert dies oft schnellere Ergebnisse als die benutzerdefinierte API-Entwicklung.
Unser AI Copilot kann Ihnen auch helfen, indem er Antwortentwürfe erstellt, die Ihre Agenten vor dem Senden überprüfen, sodass Sie KI-Unterstützung erhalten, ohne die Komplexität der selbstständigen Erstellung einer idempotenten Wiederholungslogik.
Häufig gestellte Fragen
Share this article

Article by
Stevia Putri
Stevia Putri is a marketing generalist at eesel AI, where she helps turn powerful AI tools into stories that resonate. She’s driven by curiosity, clarity, and the human side of technology.