Die Welt der KI bewegt sich in einem schwindelerregenden Tempo. Kaum haben Sie Ihr Team mit einem Modell vertraut gemacht, erscheint etwas wie Claude Opus 4.5 und verspricht, die Spielregeln erneut zu ändern.
Es ist leicht, sich im Hype und den Benchmark-Ergebnissen zu verlieren. Was bedeuten diese Updates wirklich für den täglichen Workflow Ihres Teams? Ist dies nur ein weiterer kleiner Schritt nach vorne oder ein echter Sprung, der Ihre Arbeitsweise verändern könnte?
Dieser Testbericht zu Claude Opus 4.5 untersucht die Programmierfähigkeiten, die Kapazitäten für autonome Agenten, die Einschränkungen und die neue Preisstruktur sowie die Auswirkungen für Unternehmen, insbesondere im Kundensupport.
Was ist Claude Opus 4.5?
Was genau ist Claude Opus 4.5? Es ist das neueste Spitzenmodell der großen Sprachmodelle (Large Language Models, LLMs) von Anthropic, das im November 2025 veröffentlicht wurde. Anthropic stellt mehrere Behauptungen auf und bezeichnet es als das „weltweit beste Modell für Programmierung, Agenten, Computernutzung und Unternehmens-Workflows“.
Dies ist kein bloßes kleines Update. Das Unternehmen betont das verbesserte logische Denken (Reasoning) und die Fähigkeit, mit verwirrenden oder unklaren Informationen umzugehen. Zudem ist es effizienter und kostengünstiger als die Vorgängerversion, was für Unternehmen von Vorteil ist, die High-End-KI kosteneffektiv einsetzen möchten.
Es ist so positioniert, dass es mit bedeutenden Modellen wie Googles Gemini 3 Pro und OpenAIs GPT-5.1 konkurriert. Man kann es sich als einen Allrounder vorstellen, der besonders geschickt darin ist, komplexe, spezialisierte Aufgaben zu bewältigen.
Wichtigste Funktionen und Fähigkeiten
Lassen Sie uns ins Detail der neuen Funktionen gehen und klären, was sie für Sie bedeuten, basierend auf offiziellen Informationen und Nutzerberichten.
Ein führendes Modell für Programmierung und Entwicklung
Opus 4.5 hat die Aufmerksamkeit von Entwicklern auf sich gezogen.
Es erreichte 80,9 % beim SWE-bench Verified Benchmark, einem anspruchsvollen Test, bei dem reale GitHub-Probleme behoben werden müssen. Dies ist eine beachtliche Leistung und ein Beleg für seine fortschrittlichen Coding-Fähigkeiten.
Bemerkenswerterweise schnitt es besser ab als jeder menschliche Bewerber bei Anthropic's eigener, strapaziöser Engineering-Prüfung. Dies legt nahe, dass es unter Druck schwierige technische Entscheidungen treffen kann, ganz ähnlich wie ein Senior-Entwickler.
Seine Fähigkeiten gehen über die reine Code-Generierung hinaus. Der aktualisierte „Plan Mode“ in Claude Code ermöglicht es dem Modell, Fragen zu stellen, um Ihre Wünsche zu präzisieren, und anschließend eine editierbare „plan.md“-Datei zu erstellen. Dies hilft sicherzustellen, dass Sie von Anfang an das richtige Ergebnis erhalten.
Ich denke, Claude ist besser, wenn es um eigentliche Engineering-Arbeit geht, und besonders wenn man die fortgeschritteneren Funktionen nutzt; Claude Code ist einfach besser als das Gemini CLI
Das Aufkommen autonomer KI-Agenten
Einige KI-Modelle haben Schwierigkeiten mit unstrukturierten, realen Geschäftsdaten. Ein Test aus Nate's Newsletter zeigte beispielsweise, dass Opus 4.5 ein getipptes Versandmanifest mit einer unstrukturierten, handgeschriebenen Strichliste abgleichen konnte. Dies ist eine Aufgabe, die ein starkes Verständnis für unstrukturierte Informationen erfordert.
Opus 4.5 schneidet auch gut bei Aufgaben ab, die länger dauern und bei denen es Dinge gründlich durchdenken muss. Es kann ein Team von Unter-Agenten beaufsichtigen und nutzt eine Technik namens Kontext-Kompaktierung (Context Compaction), um bei komplizierten Workflows auf Kurs zu bleiben, sodass Sie nicht ständig nachhaken müssen. Dies war ein Kernpunkt in der offiziellen Ankündigung.
Es hat alle grundlegenden Dokumente für mein nächstes Nebenprojekt in so kurzer Zeit und in so hoher Qualität zusammengestellt, dass es sich anfühlt, als hätte man das weltbeste Team aus Praktikanten und Doktoranden, die alle darum wetteifern, Ihr Top-Performer zu sein.
Die Fähigkeit, über längere Zeiträume eigenständig zu arbeiten, lässt es weniger wie ein einfaches Werkzeug und mehr wie ein zuverlässiges Teammitglied wirken, dem Sie zutrauen können, einen Prozess von Anfang bis Ende zu steuern.
Signifikante Verbesserungen bei Kosten und Effizienz
Die API verfügt nun über einen „Effort“-Parameter, was eine bemerkenswerte Funktion ist. Sie ermöglicht es Entwicklern, Geschwindigkeit, Kosten und Leistung auszubalancieren. Sie können je nach Schwierigkeitsgrad der Aufgabe zwischen niedrigem, mittlerem oder hohem Aufwand wählen.
Der Unterschied in der Effizienz ist erheblich. Bei einer mittleren Aufwandseinstellung erbringt Opus 4.5 die gleiche Leistung wie das leistungsstarke Sonnet 4.5 Modell, verbraucht aber 76 % weniger Output-Token, um die Aufgabe zu erledigen.
Diese Art von Effizienz öffnet mehr Unternehmen die Tür zur Nutzung fortschrittlicher KI. Komplexe Workflows, die zuvor für den regulären Gebrauch zu teuer waren, sind plötzlich deutlich zugänglicher.
Performance-Analyse: Stärken und Schwächen
Hier ist ein Blick darauf, wie es in der realen Welt abschneidet, basierend auf Berichten Dritter.
Stärke: Ein kollaboratives Tool für Entwickler
Entwickler scheinen Opus 4.5 weniger als Tool, sondern eher als Teamkollegen zu betrachten. Ein technischer Bericht auf Medium wies darauf hin, dass es eher „chirurgische, gezielte Änderungen“ vornimmt, anstatt nur große Codeblöcke umzuschreiben, was auf ein nuanciertes Verständnis von bestehendem Code hindeutet.
Sein riesiges Kontextfenster bedeutet, dass es ganze Code-Basen aufnehmen und sich an die offizielle Dokumentation halten kann. Wenn Sie ein Entwickler sind, der mit neuen SDKs oder maßgeschneiderter Hardware arbeitet, ist dies ein erheblicher Vorteil. Wie ein Nutzer erklärte: „Ich akzeptiere buchstäblich niemals Code von irgendeinem Modell, wenn es nicht zuerst die Dokumentation gelesen hat.“ Opus 4.5 ist genau dafür konzipiert.
Stärke: Umgang mit unstrukturierten Geschäftsdaten
Das meiste Wissen in Unternehmen ist nicht in einer perfekt organisierten Datenbank gespeichert. Es ist überall verteilt – in Support-Tickets, internen Wikis und endlosen Slack-Konversationen. Die „Christmas Tree Challenge“ zeigte, dass Opus 4.5 hervorragend darin ist, diese Art von ungeordneten Informationen zu sortieren.
Genau das ermöglicht es einem KI-Teamkollegen wie eesel AI, den spezifischen Tonfall und die Regeln Ihres Unternehmens zu erfassen. Sie müssen ihn nicht manuell einrichten oder eine komplizierte Konfiguration durchlaufen. Er lernt einfach aus Ihren vorhandenen Helpdesk-Daten, alten Tickets und Wissensdatenbanken. Auf diese Weise kann er sofort damit beginnen, Probleme korrekt und in der Stimme Ihrer Marke zu lösen.
Stärke: Hohe Sicherheit und Zuverlässigkeit
Sicherheit ist ein großes Thema für jedes Unternehmen, das KI einsetzt, insbesondere wenn es um Prompt-Injection-Angriffe geht. In einem Test für genau dieses Problem erwies sich Opus 4.5 als das sicherste Modell.
Tests von Vellum.ai ergaben, dass diese Art von Angriffen bei Opus 4.5 nur in 4,7 % der Fälle erfolgreich war. Das ist eine deutlich niedrigere Quote als bei Gemini 3 Pro (12,5 %) und GPT-5.1 (21,9 %), was es als sicherere Option für Anwendungen positioniert, die kundenorientiert sind oder sensible Informationen verarbeiten.
Schwäche: Gemischtes Feedback zu abstraktem logischem Denken
Trotz all seiner Stärken ist das Feedback der Community nicht durchweg positiv. Einige Entwickler auf Reddit berichten, dass es „so viele Fehlalarme (False Positives)“ produziert. Sie bevorzugen tatsächlich Konkurrenten wie GPT-5.1 Codex und sagen, es sei „viel eher bereit für den produktiven Einsatz“ und verfolge einen „sorgfältigeren und systematischeren Ansatz“.
Mein Problem mit Opus ist, dass seinem Programmieransatz solides wissenschaftliches und mathematisches Denken fehlt.
Es glänzt beim Befolgen eines Programmierplans, erbringt aber möglicherweise weniger effektive Leistungen bei hochgradig abstraktem Denken auf PhD-Niveau. Beim GPQA Diamond Benchmark beispielsweise erreichte Opus 4.5 einen Wert von 82,4 %, während der Hauptrivale GPT-5.1 Codex Max 89,4 % erzielte.
Fazit ist, dass Opus 4.5 offenbar ein Spezialist ist. Es ist wahrscheinlich das beste verfügbare Modell für die Durchführung komplexer Programmier- und agentenähnlicher Aufgaben, aber es ist nicht das Beste bei jeder Art von abstraktem Problem, das man ihm vorsetzen kann.
Preise und Verfügbarkeit
Lassen Sie uns die Details zu Preisen und Zugänglichkeit prüfen.
Ein zugänglicherer Preispunkt
Der offizielle API-Preis liegt bei 5 $ pro Million Input-Token und 25 $ pro Million Output-Token.
Dies stellt eine erhebliche Reduzierung gegenüber dem alten Opus 4.1 Modell dar, das zuvor 15 $ für den Input kostete. Diese neue Preisgestaltung bedeutet, dass Unternehmen es im Alltag einsetzen können, anstatt es nur für Spezialprojekte aufzusparen.
Preisvergleich mit anderen Modellen
Obwohl Claude Opus 4.5 deutlich günstiger ist als die letzte Version, wird es im Vergleich zu seinen Rivalen immer noch als Premium-Modell eingestuft. Aber da es so effizient mit Token umgeht, könnten die tatsächlichen Kosten für die Nutzung niedriger sein, als man beim bloßen Blick auf die Preisliste vermuten würde.
Hier ist ein kurzer Blick darauf, wie die Standard-Preise (Pay-as-you-go) im Vergleich abschneiden.
| Modell | Input-Kosten (pro 1 Mio. Token) | Output-Kosten (pro 1 Mio. Token) |
|---|---|---|
| Claude Opus 4.5 | $5.00 | $25.00 |
| Claude Sonnet 4.5 | $3.00 | $15.00 |
| OpenAI GPT-5.1 | $1.25 | $10.00 |
| Google Gemini 3 Pro | $2.00 | $12.00 |
Preisdaten stammen von den offiziellen Seiten von Anthropic, OpenAI und Google, Stand Ende 2025.
So greifen Sie auf Claude Opus 4.5 zu
Sie können das Modell über die offizielle Claude API, die Claude Web- und Desktop-Apps sowie auf großen Cloud-Plattformen wie AWS Bedrock und Google Cloud Vertex AI beziehen.
Wenn Sie es als Einzelperson oder als Teil eines Teams nutzen, ist Opus 4.5 in den Plänen Max, Team und Enterprise verfügbar. Den Nutzerberichten nach scheint es, dass Pro-Nutzer möglicherweise die „zusätzliche Nutzung“ aktiviert haben müssen oder auf einen höheren Plan upgraden müssen, um es überall nutzen zu können.
Ich glaube, Sie haben die zusätzliche Nutzung aktiviert. Ich bete für Ihr Bankkonto.
Auswirkungen für Unternehmen
Was bedeutet das nun alles für Ihr Unternehmen?
Die größte Veränderung bei Modellen wie Opus 4.5 besteht darin, dass wir uns weg von der KI als einfachem „Assistenten“, der nur Informationen abruft, hin zu einem „KI-Teamkollegen“ bewegen, der tatsächlich eigenständig Dinge erledigen kann.
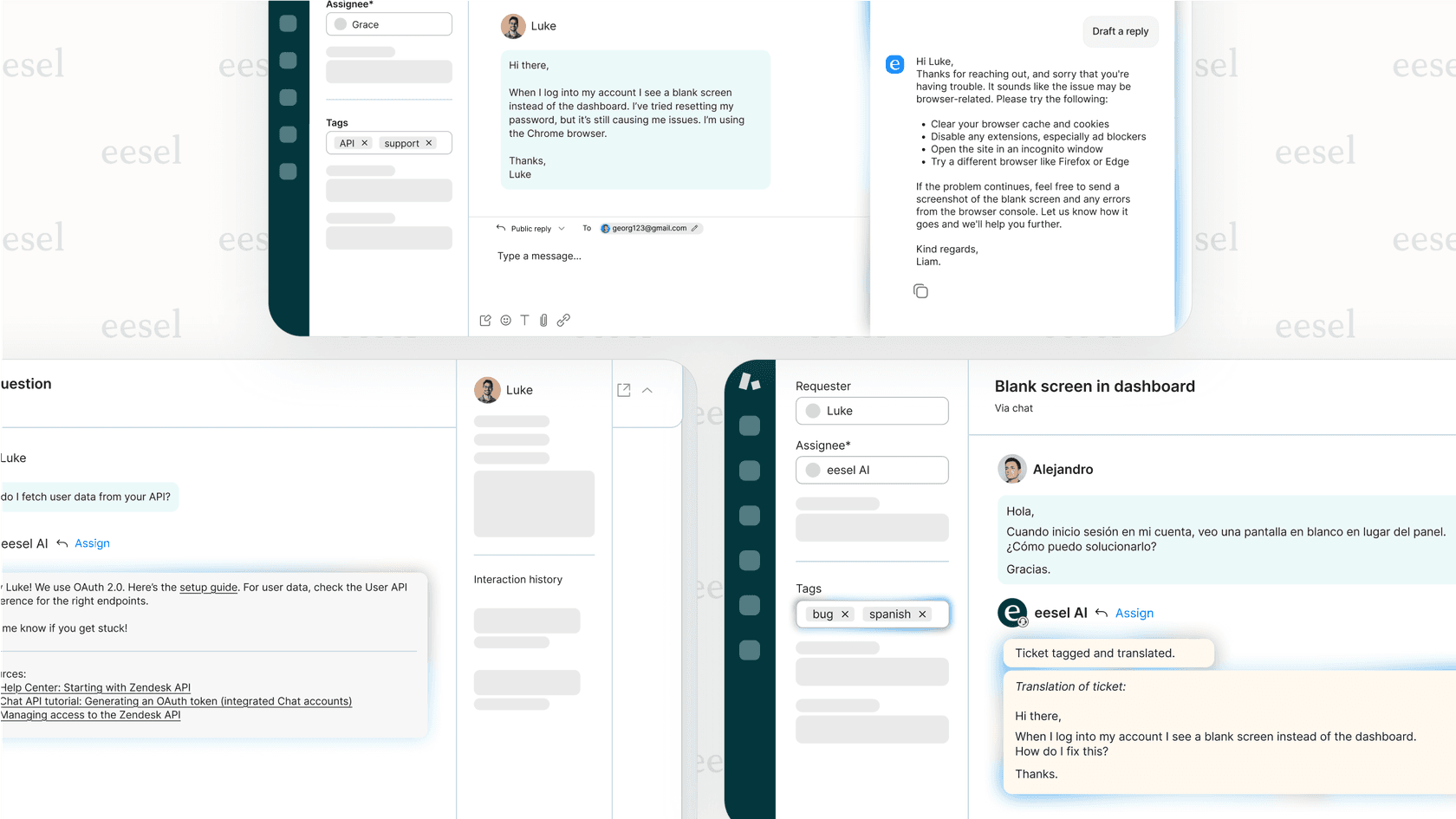
Betrachten Sie es am Beispiel des Kundensupports. Eine ältere KI findet vielleicht nur einen Hilfeartikel und sendet einen Link. Eine KI, die Opus 4.5 nutzt, kann das Problem des Kunden verstehen, seine Bestellung in Shopify finden, die Rückgabebedingungen in einem Google Doc prüfen, die Rücksendung mit einem internen Tool bearbeiten und das Ticket dann in Zendesk schließen. Sie erledigt den gesamten Vorgang.
Dies ist die Idee hinter dem AI Agent von eesel. Anstatt einen starren, regelbasierten Bot zu bauen, „stellen Sie quasi einen KI-Teamkollegen ein“. Er lernt aus den Tools und Daten, die Sie bereits verwenden, um Kundenprobleme selbstständig zu lösen, und zieht nur dann einen menschlichen Mitarbeiter hinzu, wenn eine persönliche Note wirklich erforderlich ist.

Um eine Live-Demonstration davon zu sehen, wie Claude Opus 4.5 eine reale Engineering-Aufgabe bewältigt, schauen Sie sich das Video unten an. Es bietet einen tiefen Einblick in die Fähigkeiten des Modells, wenn es bei einer praktischen Coding-Herausforderung auf die Probe gestellt wird.
Der Aufstieg des KI-Teamkollegen
Claude Opus 4.5 stellt eine bedeutende Entwicklung dar. Seine exzellenten Programmierfähigkeiten, die Kapazität für lange, automatisierte Aufgaben und der zugängliche Preis machen es zu einer soliden Basis für eine neue Welle von KI-Tools.
Mehr als alles andere signalisiert dies eine Abkehr von einfachen Chatbots hin zu echten KI-Partnern, denen man komplizierte Geschäftsabläufe von Anfang bis Ende anvertrauen kann.
In der Zukunft geht es nicht darum, Ihr Team zu ersetzen; es geht darum, es durch fähige KI-Teamkollegen zu ergänzen. Um zu sehen, wie diese neue Art von KI Ihre Kundenservice-Mannschaft unterstützen kann, testen Sie eesel AI kostenlos.
Häufig gestellte Fragen (FAQs)
Was ist die wichtigste Erkenntnis für Entwickler?
Die wichtigste Erkenntnis ist, dass Opus 4.5 eher wie ein Partner beim Programmieren als wie ein einfaches Werkzeug agiert. Es ist hervorragend darin, gesamte Code-Basen zu verstehen, präzise Änderungen vorzunehmen und Dokumentationen zu folgen, was es für komplexe, reale Entwicklungsaufgaben nützlich macht.
Ist Claude Opus 4.5 für alle Arten von Aufgaben geeignet?
Nicht ganz. Während es ein Spitzenreiter für die Programmierung und autonome, mehrstufige Aufgaben ist, kann es bei hochabstrakten logischen Schlussfolgerungen auf PhD-Niveau im Vergleich zu einigen Wettbewerbern wie GPT-5.1 Codex Max zurückbleiben. Es ist eher ein Spezialist als ein Allround-Modell.
Wie schneidet die Preisgestaltung von Claude Opus 4.5 im Vergleich zu älteren Modellen ab?
Die Preisgestaltung ist eine deutliche Verbesserung. Mit 5 $ für den Input und 25 $ für den Output pro Million Token ist es wesentlich günstiger als das vorherige Opus 4.1 Modell. Dieser Preisnachlass macht es für Unternehmen zugänglicher, es im täglichen Betrieb einzusetzen.
Was ist die bedeutendste Geschäftsanwendung, die erwähnt wird?
Die Fähigkeit des Modells, als „KI-Teamkollege“ zu fungieren, insbesondere im Kundensupport, wird hervorgehoben. Es kann komplexe End-to-End-Workflows bearbeiten, wie z. B. die Abwicklung einer Rücksendung durch Interaktion mit mehreren Apps (Shopify, Zendesk usw.), was über einfache Chatbot-Antworten hinausgeht.
Wie sicher ist Claude Opus 4.5?
Es gilt als eines der sichersten Modelle der Branche. Tests zeigen, dass es hochgradig resistent gegen Prompt-Injection-Angriffe ist, mit einer Erfolgsquote von nur 4,7 % für Angreifer. Dies macht es zu einer zuverlässigen Wahl für Anwendungen mit Kundenkontakt, bei denen Sicherheit Priorität hat.
Ist Claude Opus 4.5 besser als GPT-5.1?
Das hängt von der Aufgabe ab. Opus 4.5 ist bei spezifischen Programmier-Benchmarks (wie SWE-bench) und agentenbasierten Workflows überlegen. Allerdings erzielt GPT-5.1 Codex Max höhere Werte bei Benchmarks für abstraktes logisches Denken, sodass das „bessere“ Modell vom jeweiligen Anwendungsfall abhängt.