Let’s be honest, modern AI applications are getting ridiculously hungry for fresh data. Things like RAG pipelines, which give AI real-time context, or autonomous agents need a constant stream of information that wasn't part of their original training set. But getting that data reliably from the wild, messy web is a massive headache.
This is where tools like Firecrawl and Apify step in. They both promise to tame the web, turning unstructured chaos into clean, usable data for your AI projects. But they come at the problem from completely different directions. Firecrawl is the lean, API-first tool designed to be fast and simple. Apify, on the other hand, is a sprawling, feature-packed ecosystem built for just about any scraping task you can imagine.
This guide will break them both down, comparing how they’re built, what they can do, how much they cost, and the hidden costs you might not be thinking about. By the end, you’ll have a clear idea of which tool is right for your project, and maybe realize that for some jobs, you don't need a scraper at all.
What is web scraping for AI?
Web scraping is really just a technical term for automatically grabbing data from websites. For AI, it’s become a lifeline. It’s how you feed a large language model (LLM) up-to-the-minute info, whether that’s breaking news, competitor pricing, or your own product documentation. Without it, your AI is basically stuck in the past, completely clueless about anything that's happened since its last training run.
Two of the biggest players helping developers build these data pipelines are Firecrawl and Apify.
What is Firecrawl?
Firecrawl is a tool made by developers, for developers. It’s API-driven and designed to do one thing incredibly well: turn any website into clean, LLM-ready formats like Markdown or JSON. Its main hook is simplicity and speed. It uses a "zero-selector" approach, which often means you can just tell it what data you want in plain English instead of writing fragile code that targets specific bits of HTML.
What is Apify?
Apify isn't just one tool; it's a full-blown web scraping and automation platform. Its centerpiece is the Apify Store, a marketplace with over 6,000 pre-built scrapers (which they call "Actors") that can handle a huge variety of websites right out of the box. Apify is all about giving you options and scale, serving everyone from folks who want a no-code tool to developers building seriously custom scraping workflows.
Firecrawl vs Apify: Core architecture and approach
The real difference in the Firecrawl vs Apify matchup isn't just a list of features, it's their entire philosophy. Firecrawl bets on being a simple, focused utility, while Apify goes all-in on being a flexible, do-everything platform.
Firecrawl's AI-native design
Firecrawl is built to be a straightforward tool for developers. You work with it through a single, clean API. You give it a URL, and its system figures out the smartest way to grab the content. If it’s a simple page, it does a quick fetch. If the page needs JavaScript to load, it automatically spins up a headless browser. The point is, you don't have to think about it. The goal is to hide all the messy parts of scraping so you can get back to building your actual application.
Apify's actor-based ecosystem
Apify is built around "Actors," which are basically small, containerized programs that run on their cloud. An Actor could be a scraper for a specific website, a script to clean up data, or a complex automation that chains multiple steps together. This modular setup is incredibly powerful. You can find an Actor to pull product data from Amazon, connect it to another one that formats the data, and a third that sends it to your database, all without writing much, if any, code.
The catch with scraping
No matter how clever the tool is, any approach that relies on scraping has the same fundamental weakness: it's brittle. Websites change their code and layout all the time, without warning. When they do, scrapers that were built for the old structure break. A developer then has to drop everything they're doing to go and fix it. This cycle of breaking and fixing can turn a simple data feed into a surprisingly high-maintenance chore.
Feature comparison: Firecrawl vs Apify
Let's get into the weeds and see how the two platforms really stack up.
| Feature | Firecrawl | Apify |
|---|---|---|
| Extraction Method | "Zero-selector" using natural language or a JSON schema. | Code-based selectors (CSS/XPath) inside custom Actors. |
| Ease of Use | Very easy for developers with a simple API. | Steeper learning curve for custom builds; easy for non-devs using pre-built Actors. |
| Flexibility | Focused on its core job, so less configurable. | Extremely flexible with SDKs (Python/JS) and custom code. |
| Pre-built Solutions | Limited to what its core API can do. | Over 6,000 pre-built Actors in the Apify Store. |
| AI Integrations | Official loaders for LangChain & LlamaIndex. | Official loaders for LangChain & LlamaIndex, plus other data connectors. |
| Scalability | Scales based on concurrent browser limits in your plan. | Elastic scaling; can run thousands of Actors at once. |
Data extraction and maintenance
Firecrawl’s natural language extraction is fantastic for getting started quickly. Telling it to "grab the product title and price" is a whole lot faster than digging through a website's HTML to write a specific CSS selector. The trade-off is that you have less fine-grained control, which can be an issue on websites with weird or unique structures.
Apify's code-based approach is the exact opposite. It takes more upfront work from a developer to write the selectors and logic, but it gives you total control. This is a must-have for dealing with complex login forms, tricky pagination, or sites that actively try to block scrapers.
Use cases and anti-blocking
With its focus on speed and low latency, Firecrawl really shines in real-time AI agent workflows. If you're building a chatbot that needs to look up live information to answer a user's question on the fly, Firecrawl's sub-second response times are a huge plus.
Apify is the clear winner for large-scale data gathering across many different websites. If your job is to track prices across 50 e-commerce sites, you’ll probably find ready-to-use, maintained Actors for most of them in the Apify Store. This can save you hundreds of hours of development. Apify also has top-notch proxy management and anti-detection tech, making it a solid choice for enterprise-level scraping.
It's also worth pointing out that for a lot of internal business tasks, like customer support, scraping your own public help articles is often the least effective way to get information. A tool that connects directly to your internal knowledge, like past tickets or private Confluence pages, will always give your AI better, more context-aware answers.
Firecrawl vs Apify: Pricing breakdown and total cost of ownership
Comparing prices isn't as simple as looking at the sticker price. The way these platforms charge for usage can drastically change your final bill, and that's before you even think about the hidden costs.
Firecrawl's predictable pricing
Firecrawl has a simple, transparent credit system, which makes budgeting pretty straightforward. For most scrapes, one page costs one credit.
-
Free: 500 one-time credits
-
Hobby: $16/month for 3,000 credits
-
Standard: $83/month for 100,000 credits
-
Growth: $333/month for 500,000 credits
The big win here is predictability. You know exactly what you're getting and what you'll pay, with no nasty surprises at the end of the month.
Apify's hybrid model
Apify's pricing is a mix of a monthly subscription and pay-as-you-go billing. You pay a monthly fee that gets you a certain amount of platform credit, which is then spent to run Actors. The cost of running an Actor is measured in "Compute Units" (CUs), which are based on how much memory and CPU time it uses.
-
Free: $5 of platform credit per month
-
Starter: $39/month
-
Scale: $199/month
-
Business: $999/month
This model is way more flexible, but also much harder to predict. A well-written scraper might cost almost nothing to run, but a clunky one hitting a complex, JavaScript-heavy site could chew through your credits faster than you'd believe.
The hidden costs of scraping
The true "total cost of ownership" for any scraping solution goes way beyond the monthly bill. The biggest expense, by far, is developer time. You need a developer to build the scrapers, but more importantly, you need their time for ongoing maintenance. When a website you rely on pushes an update and your scraper breaks (and trust me, it will), you're paying a developer's salary to fix it. A cheap scraping tool can quickly become a very expensive and unpredictable drain on your resources.
When a website you rely on pushes an update and your scraper breaks (and trust me, it will), you're paying a developer's salary to fix it.
A smarter approach for support teams: Direct knowledge integration
For critical use cases like AI-powered customer support, the fragility of scraping isn't just a minor issue; it's a real liability. You can't have your support bot breaking every time you tweak your help center.
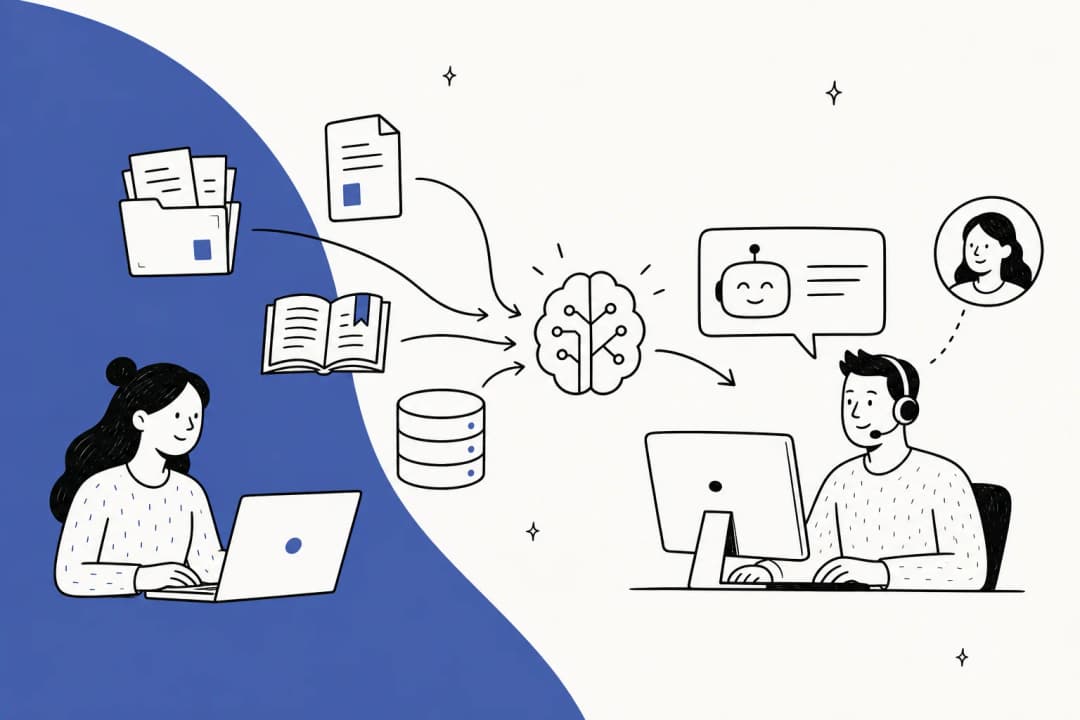
This is where a tool like eesel AI offers a completely different and, frankly, better way. Instead of scraping, eesel AI connects directly to where your knowledge actually lives through stable, one-click integrations.
Unify your knowledge in one click
Forget trying to scrape your public help docs. eesel AI plugs straight into the tools your team uses every single day. With integrations for platforms like Zendesk, Google Docs, Slack, and over 100 others, it pulls information from the source of truth, not a fragile copy of it.

Go live in minutes, not months
Building a reliable scraping pipeline can take a developer weeks or even months. With eesel AI's self-serve platform, you can connect your help desk, train your AI on your actual knowledge, and have a bot running in just a few minutes. There's no code needed and no sitting through boring sales calls just to see how it works.

Reliable and maintenance-free
Because eesel AI uses direct API connections, it doesn't break when you change the font on your website. Your AI always has a solid link to your most current information, whether it's in internal wikis, product specs, or even resolved support tickets. This completely gets rid of the maintenance nightmare that comes with scraping-based solutions.

Firecrawl vs Apify: The final verdict
So, when it comes down to Firecrawl vs Apify, what's the verdict?
-
Choose Firecrawl if your main goal is speed, simplicity, and a great developer experience for real-time AI tasks. It's the perfect tool for quickly giving your application web-browsing powers.
-
Choose Apify if you need massive scale, flexibility, and a huge library of pre-built tools for large, multi-site scraping projects. Its marketplace of Actors can save you an unbelievable amount of development time.
While they’re both great for pulling data from the public web, they both share the maintenance burden that comes with scraping. For teams trying to build a reliable AI for customer support, a direct integration platform that sidesteps the fragility of scraping is a much smarter choice.
Ready to power your support with AI that just works, without the constant upkeep? Try eesel AI for free and connect your knowledge sources in minutes.
Frequently asked questions
Which tool, Firecrawl vs Apify, is better suited for real-time AI applications requiring low latency?
Firecrawl is generally better for real-time AI applications due to its focus on speed, simplicity, and low latency, making it ideal for quick lookups by AI agents.
When considering Firecrawl vs Apify, what are the primary differences in their data extraction methods?
Firecrawl uses a "zero-selector" approach, often allowing natural language to specify data. Apify relies on code-based selectors (CSS/XPath) within custom Actors, offering more fine-grained control.
How do the pricing models for Firecrawl vs Apify compare in terms of predictability and total cost of ownership?
Firecrawl offers predictable credit-based pricing. Apify has a hybrid model with monthly subscriptions and pay-as-you-go "Compute Units," which can be less predictable, and both incur significant hidden costs in developer maintenance time.
For projects that require large-scale data collection from numerous different websites, which solution, Firecrawl vs Apify, is generally recommended?
Apify is the clear winner for large-scale, multi-site data gathering due to its extensive marketplace of over 6,000 pre-built Actors and robust anti-blocking and proxy management features.
Can I expect similar levels of pre-built solutions or marketplace support when comparing Firecrawl vs Apify?
No, Apify has a substantial advantage here with its Apify Store, offering over 6,000 pre-built "Actors" for various scraping tasks. Firecrawl has limited pre-built solutions, focusing on its core API.