Claude Opus 4.7 Review: The New Standard for AI Reasoning in 2026
Stevia Putri
Last edited April 21, 2026
The AI world moves fast, but the release of Claude Opus 4.7 on April 16, 2026, feels like a fundamental shift in direction. While the last two years have been a race for speed and lower latency, Anthropic’s latest flagship model takes a different path. It isn’t necessarily built to be the fastest.it’s built to be the most rigorous.
In this review, we’ll dive into what makes Opus 4.7 a "reasoning leap," why it has sparked a heated debate about model regression, and how businesses are already using it to handle complex, autonomous tasks that previous models simply couldn’t touch.
What’s New in Opus 4.7?
Claude Opus 4.7 isn’t a complete architectural overhaul, but rather a focused upgrade designed for "long-horizon agentic reliability." If Opus 4.6 was about getting the right answer quickly, 4.7 is about proving the answer is right before it even talks to you.

Software Engineering Excellence
The headline improvement is in coding. Opus 4.7 achieved a staggering 87.6% on SWE-bench Verified, up from 80.8% in Opus 4.6. Even more impressive is its performance on SWE-bench Pro (+10.9 points), suggesting its gains are concentrated on the hardest, most unique software engineering problems rather than just common patterns.
Self-Verification and Rigor
Perhaps the most "human-like" feature of 4.7 is its ability to verify its own outputs. In practice, when you give Opus 4.7 a complex task, it doesn't just execute and report. It proactively writes tests, runs sanity checks, and inspects its own work. This "Verify before Report" loop significantly cuts error rates in long-running agentic work.
Enhanced Vision Capabilities
Opus 4.7 now supports images up to 2,576 pixels on the long edge (~3.75 megapixels). This is a 3.3x increase in resolution over prior models. For businesses, this means the AI can now "read" dense screenshots, complex architectural diagrams, and pixel-perfect UI elements that were previously too blurry for reliable extraction.
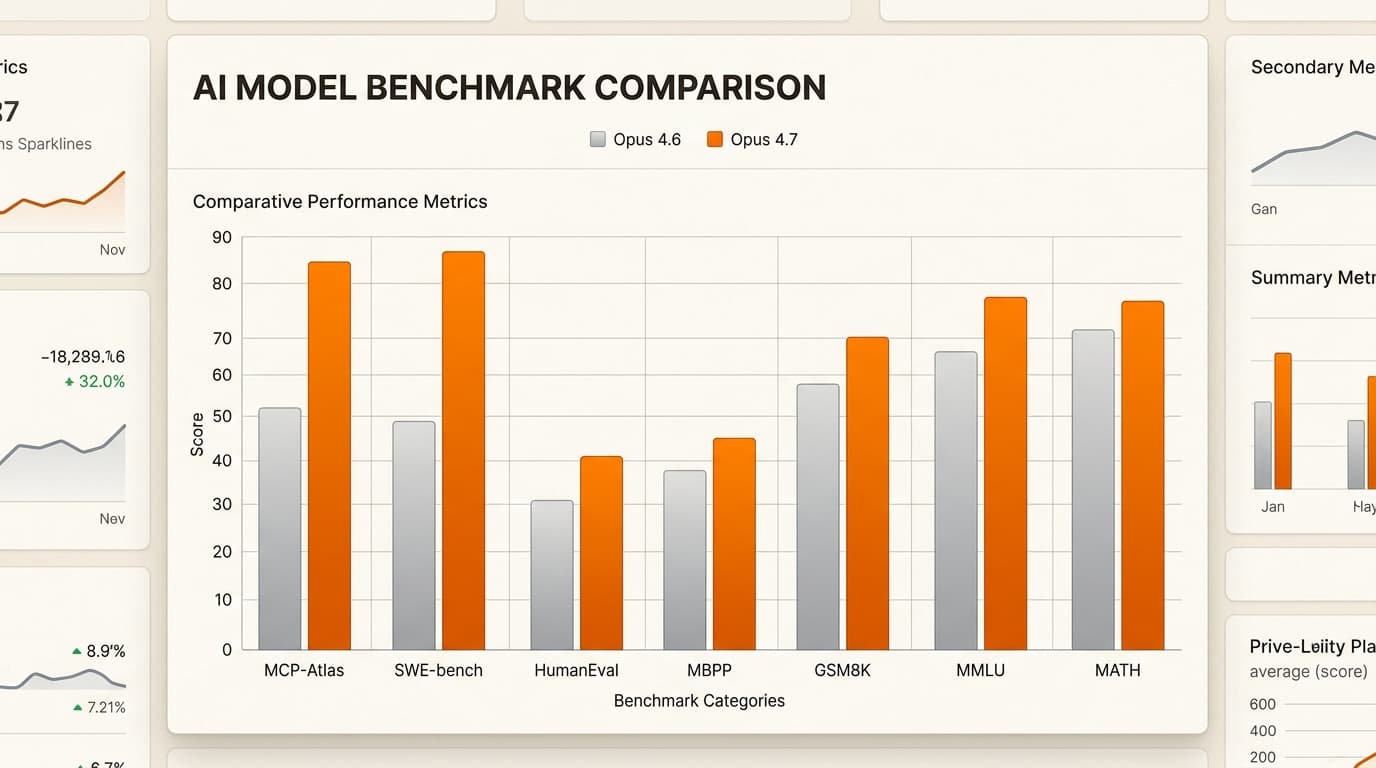
The "Thinking" Model: Performance Benchmarks
Anthropic has positioned 4.7 as the thinking person’s AI. It isn't just predicting the next token; it is "reasoning" through steps. This is reflected in its benchmark performance across the board.
| Benchmark | Claude Opus 4.7 | Claude Opus 4.6 | Delta |
|---|---|---|---|
| SWE-bench Verified | 87.6% | 80.8% | +6.8 |
| GPQA Diamond | 94.2% | 91.3% | +2.9 |
| MCP-Atlas (Tools) | 77.3% | 62.7% | +14.6 |
| Finance Agent (SOTA) | 64.4% | 60.7% | +3.7 |
The jump on MCP-Atlas (+14.6 points) is particularly notable for anyone building autonomous agents. It shows that 4.7 is significantly better at using tools.like searching a database or interacting with an API.without getting lost in the process.
Addressing the Controversy: Is it a Regression?
Despite the glowing benchmarks, the release hasn't been without controversy. On platforms like Reddit, a vocal segment of users has labeled Opus 4.7 a "regression."
The main complaint? Speed.
Because Opus 4.7 "thinks" more.especially at the new xhigh and max effort levels.it can feel significantly slower than 4.6. Some users describe it as "overthinking" simple tasks. There is also a perception that the model has lost some of its "creative soul" in non-technical writing, becoming more literal and dry.
The Project Glasswing Factor
Part of this shift is intentional. Opus 4.7 is the first broadly released model to include the Project Glasswing safeguard stack. Anthropic explicitly experimented with reducing offensive cybersecurity capabilities during training. These safeguards automatically detect and block requests that indicate high-risk cyber uses. While this makes the model safer for enterprises, it adds a layer of "literalness" that can feel like a constraint to power users.
Practical Business Use Cases
For most businesses, the "regression" debate is a distraction from the model’s true value: its reliability. At eesel AI, we see Opus 4.7 as the perfect engine for AI teammates.
Complex Support Workflows
Imagine a customer support request that requires:
- Checking a user's subscription status in Stripe.
- Cross-referencing it with a refund policy in a Confluence wiki.
- Updating a ticket in Zendesk.
- Sending a Slack notification to the finance team.
Earlier models might miss a step or hallucinate a detail. Opus 4.7’s "self-verification" ensures that each step is checked against the last. It’s the difference between a bot that guesses and an AI teammate that knows.
Document & Slide Generation
With its improved vision and creative taste, 4.7 is also significantly better at producing high-quality interfaces, slides, and professional docs. It can "see" your existing brand assets with 3.3x more clarity and ensure that the generated content follows your Claude AI programming tools and design standards perfectly.
Getting Started & Pricing
The good news is that Claude Opus 4.7 is a drop-in replacement on the API, and the price remains unchanged:
- Input: $5 per 1 million tokens
- Output: $25 per 1 million tokens
However, there is a catch. Opus 4.7 uses an updated tokenizer. The same text can map to 1.0–1.35x more tokens than it did in 4.6. This means that while the price per token is the same, your cost per task might rise slightly.
Tips for Prompting 4.7
- Be Literal: Since 4.7 follows instructions more precisely, avoid "vague vibes." Be explicit about what you want.
- Use the xhigh Level: This new effort level sits between high and max, giving you the best balance of reasoning and latency.
- Set Task Budgets: Use the new beta task budgets to cap your token spend on long-running autonomous jobs.
The Verdict: Accurate over Fast
Claude Opus 4.7 is a specialized tool. If you need a quick chat about what to have for dinner, it’s probably overkill (and too slow). But if you are building autonomous AI teammates to handle critical business operations, software engineering, or complex data extraction, it is the new gold standard.
It chooses accuracy over speed, and rigor over "vibes." For the future of autonomous work, that’s exactly the trade-off we need.
Frequently Asked Questions
Share this article

Article by
Stevia Putri
Stevia Putri is a marketing generalist at eesel AI, where she helps turn powerful AI tools into stories that resonate. She’s driven by curiosity, clarity, and the human side of technology.