Escritor de artigos para base de conhecimento com IA: como usar de verdade (2026)
Kurnia Kharisma Agung Samiadjie
Katelin Teen
Última edição June 23, 2026

Resumo
Um escritor de artigos para base de conhecimento com IA rascunha artigos de central de ajuda e base de conhecimento a partir de fontes que você já possui, como tickets resolvidos, documentos dispersos e as respostas que seus agentes enviam todos os dias, em vez de escrever do zero. O valor não está na velocidade, mas em transformar o que sua equipe já sabe em artigos que seus clientes conseguem realmente encontrar.
O erro que a maioria das equipes comete: apontam uma IA para uma página de marketing ou para a própria wiki interna e publicam o que sai. O resultado lê bem e não ajuda ninguém, porque foi escrito para o leitor errado. As boas ferramentas fundamentam cada rascunho no seu conteúdo real, escrevem para a pessoa que realmente faz a pergunta e sinalizam as lacunas onde você não tem nenhum artigo.
Trabalho com conteúdo e SEO na eesel AI, e passamos anos observando a IA responder tickets de suporte reais a partir de bases de conhecimento reais. Então isso não é uma comparação de ferramentas. É o que um escritor de artigos para base de conhecimento com IA faz, como os que valem a pena realmente funcionam e um fluxo de trabalho para obter artigos que cumpram seu papel, além de onde o eesel se encaixa se você quer que a escrita e as respostas funcionem a partir da mesma fonte.
O que um escritor de artigos para base de conhecimento com IA realmente faz
Tire o marketing de cena e o trabalho é simples: pegar o conhecimento preso em tickets, chats e documentos incompletos, e transformá-lo em um artigo limpo e estruturado que um cliente possa ler e se ajudar sozinho.
Esse é um trabalho diferente do de um escritor de IA genérico ou de um gerador de conteúdo com IA voltado para posts de blog. Um post de blog pode ser superficialmente verdadeiro e ainda cumprir seu papel. Um artigo de base de conhecimento que é superficialmente verdadeiro gera um ticket, ou pior, uma ação errada do cliente. Então a prioridade é precisão primeiro, polimento depois.
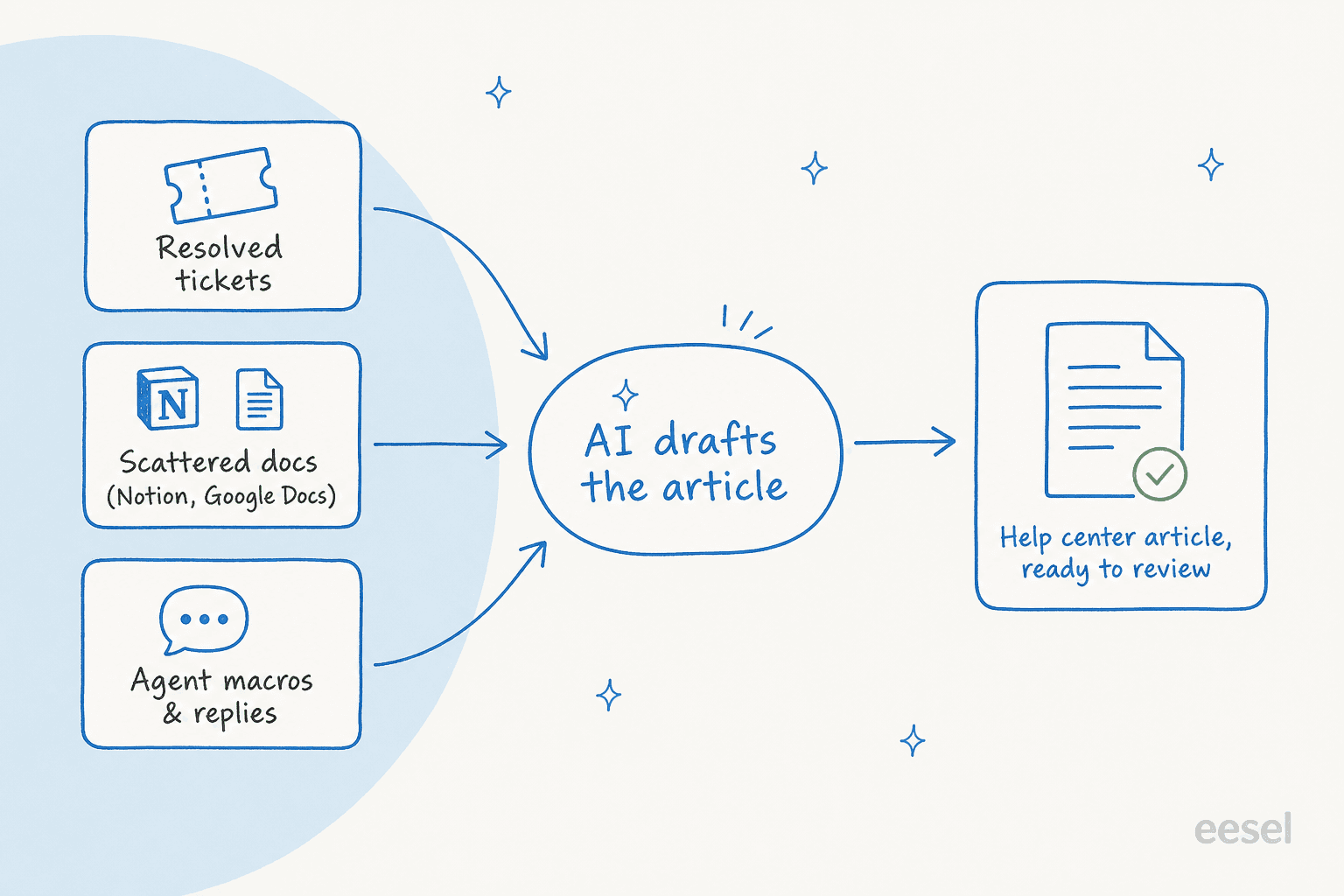
Na prática, um bom escritor faz três coisas:
- Puxa das suas fontes, não da imaginação. Tickets resolvidos, sua central de ajuda existente, documentos internos no Notion ou Google Docs, macros de agentes, notas de lançamento. O artigo é uma reestruturação do que você já sabe, com a IA cuidando da estrutura.
- Escreve com a sua voz e formato. Listas de passos para tutoriais, respostas curtas para FAQs, os títulos e o tom que seus artigos existentes usam. É aqui que o treinamento de voz da marca importa, para que um novo artigo não pareça escrito por outra empresa.
- Diz o que escrever a seguir. Os melhores analisam o que os clientes pesquisam e o que perguntam nos tickets, e então identificam os tópicos onde você ainda não tem nenhum artigo.
Esse último ponto é o que as equipes ignoram, e é geralmente onde o tempo é realmente economizado.
O erro que desperdiça silenciosamente todo o esforço
Este é o fracasso que vi afundar mais projetos de base de conhecimento do que qualquer limitação de modelo: os artigos são escritos para o leitor errado.
Já participei de reuniões com um gerente de suporte de um serviço de rastreamento de ônibus que recebia algumas centenas de tickets no Zendesk por mês, cuja base de conhecimento inteira foi escrita para administradores, enquanto cada ticket vinha de passageiros. Os documentos eram tecnicamente precisos e completamente inúteis para as pessoas que escreviam. Uma IA apontada para esses documentos apenas produz mais artigos para administradores, mais rápido. Você automatizou a coisa errada.
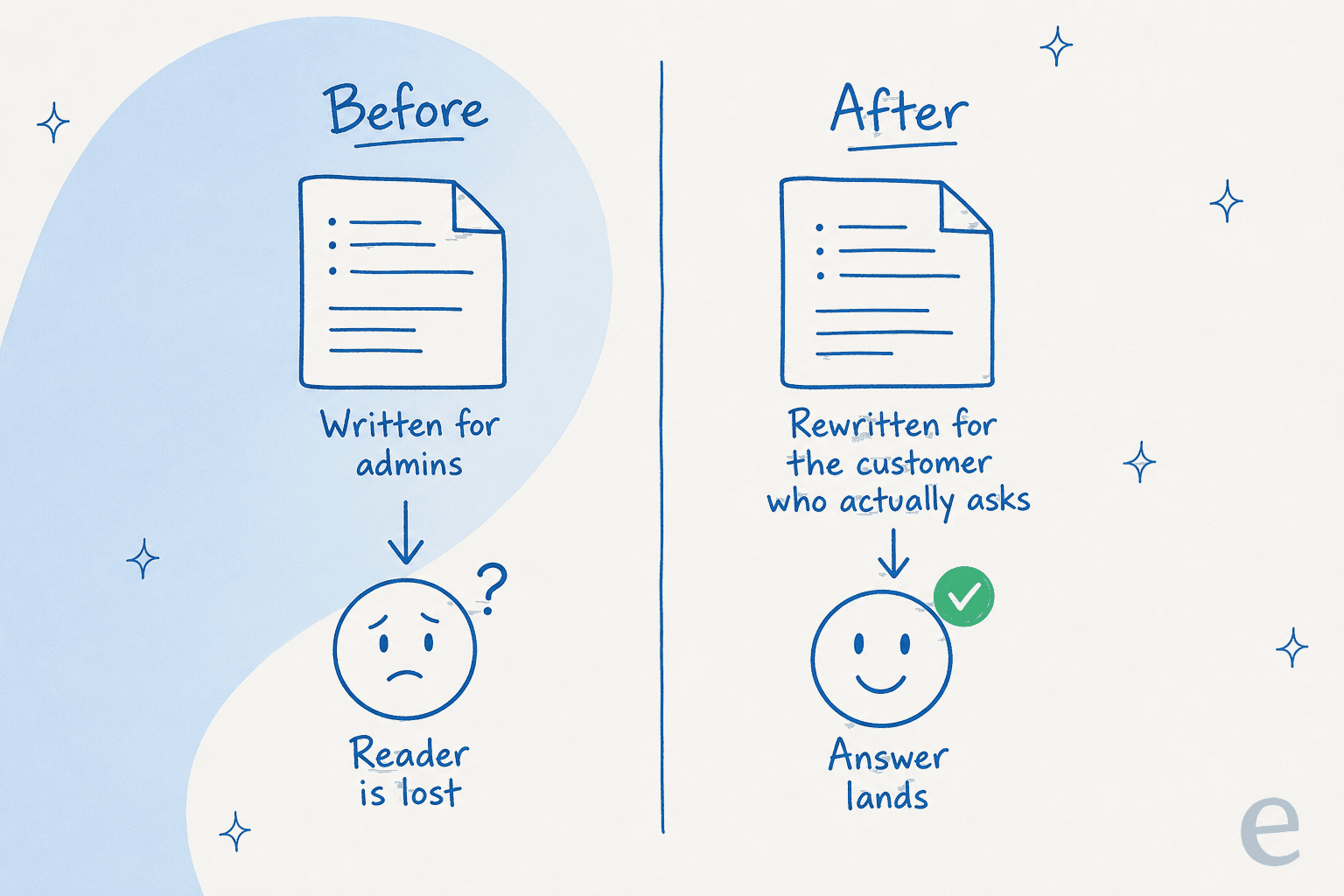
É exatamente por isso que alimentar a IA com seus tickets resolvidos supera alimentá-la com seus documentos existentes. Os tickets carregam a pergunta nas próprias palavras do cliente, a formulação que eles realmente usam, o que os deixou confusos. Um artigo gerado a partir dessa fonte responde à pergunta real. Um artigo gerado a partir de uma especificação interna responde a uma pergunta que ninguém fez.
Portanto, antes de julgar qualquer ferramenta, verifique de onde ela está lendo. Um escritor que só ingere seus documentos atuais reproduzirá fielmente tudo o que está errado neles. O objetivo de um escritor de artigos para base de conhecimento com IA é fechar a lacuna entre o que você documentou e o que as pessoas estão realmente perguntando, não multiplicar seus documentos existentes.
Como os bons realmente funcionam
Com as fontes certas, o mecanismo que separa uma ferramenta útil de um brinquedo é o fundamentação: a IA escreve apenas a partir do conteúdo recuperado, ou recorre aos dados de treinamento quando não encontra uma resposta?
Este é o mesmo problema que torna um chatbot de base de conhecimento com IA confiável ou perigoso, e vale a pena entender porque o lado da escrita tem o risco idêntico. Quando a recuperação não retorna nada e o modelo responde mesmo assim, você obtém ficção confiante. Vimos bots de clientes pagantes inventar afirmações sobre produtos e enviá-las a pessoas reais, simplesmente porque a base de conhecimento não tinha nenhuma entrada correspondente e o modelo preencheu o silêncio. Um escritor com a mesma falha rascunhará alegremente um tutorial para uma funcionalidade que não existe.
Portanto, as perguntas que importam para qualquer assistente de documentação com IA:
- Ele cita o documento de origem por trás de cada seção, para que um revisor possa verificá-lo?
- Ele recusa, ou sinaliza, quando não tem uma fonte fundamentada em vez de adivinhar?
- Ele consegue treinar na sua base de conhecimento e nos seus tickets anteriores juntos, não só em um ou outro?
Se você só levar uma coisa desta seção: uma ferramenta que admite "não tenho uma fonte para isso" vale mais do que uma que sempre tem uma resposta. A confiante é a que causa problemas.
Construir você mesmo ou comprar?
Uma pergunta justa, especialmente se você tem engenheiros: por que não conectar a API da OpenAI ou do Claude aos seus documentos e criar o seu próprio? Karel da GENERAL BYTES, que conecta o eesel AI ao Confluence e ao Telegram, colocou o dilema de forma direta:
"Poderíamos tentar escrever nossa própria aplicação LLM, mas não queríamos investir nosso tempo nisso. Queríamos algo que não precisássemos manter."
Karel, GENERAL BYTES (estudo de caso)
Essa é a matemática honesta. O primeiro rascunho de um pipeline de recuperação mais escrita é uma tarefa de fim de semana. Mantê-lo preciso à medida que seus documentos mudam, seu produto avança e os casos extremos se acumulam é um trabalho permanente. Para a maioria das equipes, a manutenção é o custo, não a construção.
Um fluxo de trabalho que produz artigos que valem a pena manter
Ferramentas à parte, este é o ciclo que eu realmente usaria. Funciona tanto com uma ferramenta específica quanto combinando ajuda de IA para escrever manualmente.
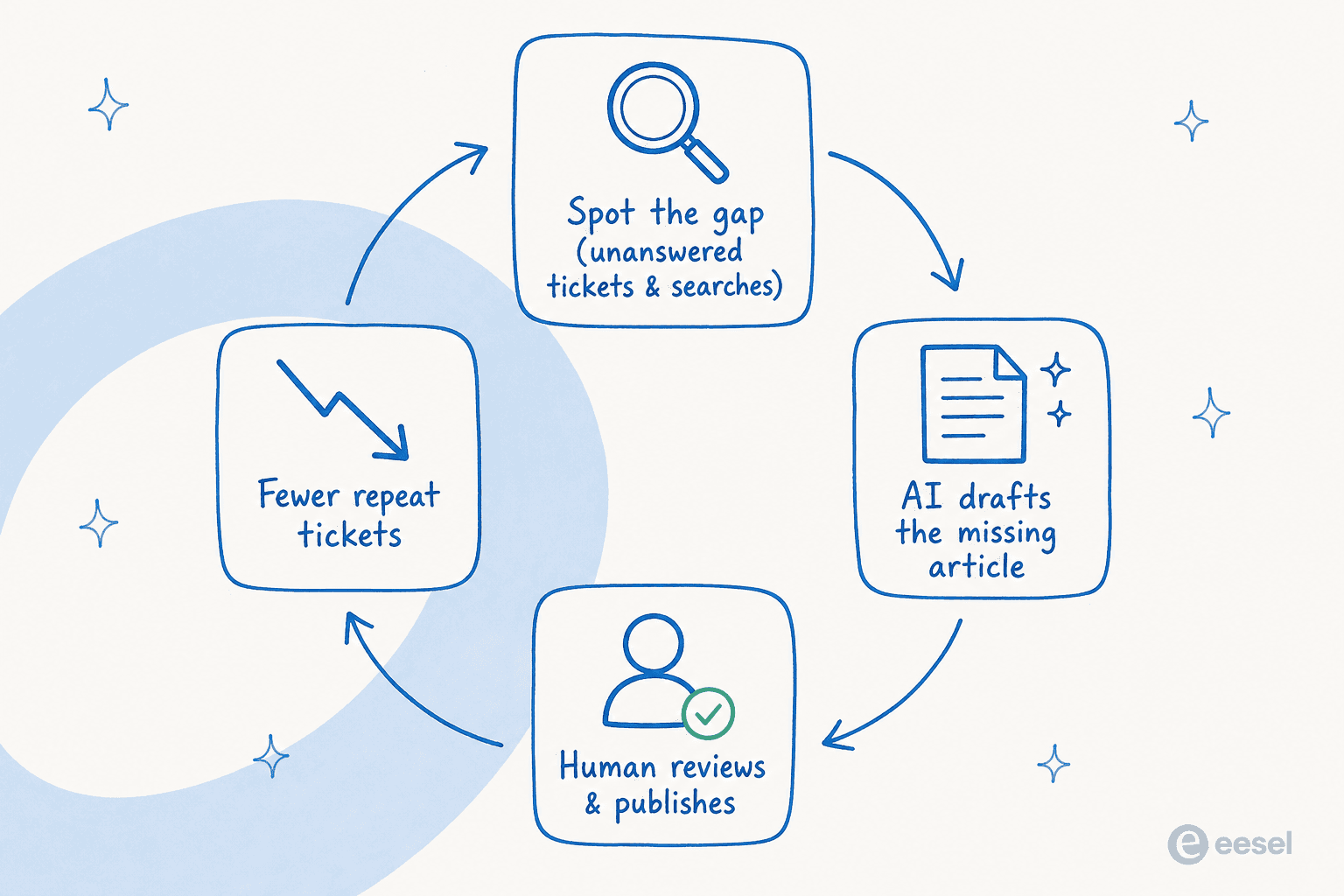
- Encontre a lacuna antes de escrever. Não comece por um calendário de conteúdo, comece pela demanda. Puxe os tickets que continuam chegando e as consultas de busca que atingem uma lacuna na central de ajuda. Esses são os tópicos dos seus artigos, ordenados por quanto sofrimento estão causando.
- Rascunhe a partir do ticket resolvido, não da especificação. Alimente a IA com a conversa real onde um agente resolveu o problema. A resposta que seu agente já escreveu é 80% do artigo, na linguagem do cliente.
- Mantenha um humano na posição de revisão. A IA rascunha, uma pessoa aprova. Isso não é formalidade, é onde você pega o número errado ou o passo que mudou no último lançamento. O revisor deve verificar fatos, não reescrever prosa.
- Publique na fonte que seu suporte já lê. Um artigo só desvia tickets se seus agentes e seu bot conseguem vê-lo. Esse é o argumento para manter a escrita e as respostas em uma única plataforma.
- Atualize de acordo com uma programação. Use IA para sinalizar conteúdo desatualizado na central de ajuda para que você corrija o artigo obsoleto antes que um cliente o encontre. Essa é a diferença entre uma base de conhecimento e um cemitério.
Execute esse ciclo e a contagem de artigos deixa de ser a métrica. A diminuição de tickets repetidos passa a ser.
Qual abordagem se encaixa na sua equipe?
A maioria das equipes se enquadra em um dos três cenários dependendo do volume e de onde o conhecimento já vive. Uma verificação rápida:
Onde vive o seu conhecimento agora?
Onde as coisas dão errado
Alguns problemas que vale nomear, porque são previsíveis:
- Conteúdo desatualizado sem dono. A IA torna a escrita barata, o que significa que é fácil publicar 200 artigos e não atualizar nenhum. Uma base de conhecimento maior e desatualizada é pior do que uma pequena e atual. Isso é realmente um problema de gestão de base de conhecimento, e é o que morde silenciosamente.
- Desvio de audiência. Abordamos acima, mas recorre: a cada poucos meses, verifique se os novos artigos ainda correspondem a como os clientes formulam as coisas, não como sua equipe de produto faz.
- O wiki que vira um pântano. Documentos internos e artigos voltados para clientes são trabalhos diferentes. Se você também está gerenciando uma base de conhecimento interna, mantenha as duas claramente separadas, ou sua IA vai misturar jargão interno em artigos públicos.
- Visão de túnel de fonte única. Um escritor que só lê documentos perde tickets; um que só lê tickets perde suas notas de lançamento. Uma forte gestão de conhecimento com IA para equipes de suporte puxa de tudo ao mesmo tempo.
Nenhum desses é um problema de modelo. São problemas de processo, e uma ferramenta que incorpora o ciclo em como funciona te salva da maioria deles.
Experimente o eesel para a escrita e as respostas
Se você quer que a escrita de artigos e as respostas a tickets funcionem a partir do mesmo mecanismo, essa é a aposta que o eesel AI faz. Ele se conecta ao seu help desk e seus documentos, seja Zendesk, HubSpot, Confluence ou Jira, aprende com seus tickets anteriores e rascunha respostas e artigos fundamentados nesse conteúdo em vez de adivinhar.
O ponto que amarra todo este post: porque o mesmo mecanismo que rascunha artigos também responde tickets, as lacunas surgem naturalmente. Quando a IA não consegue responder algo com confiança, esse é o seu próximo artigo, já identificado. Um cliente gerencia uma base de conhecimento genuinamente grande com o eesel AI fazendo exatamente isso, e outra equipe nos disse que seus agentes pararam completamente de vasculhar o Notion e o Google Docs porque a IA faz a recuperação por eles.
Você pode conectá-lo à sua pilha existente, apontá-lo para seus tickets e documentos e assistir enquanto ele rascunha com base no seu histórico real antes de se comprometer. É gratuito para experimentar e funciona como um colega de equipe que já leu sua central de ajuda. Se você ainda está comparando opções, nosso resumo de ferramentas de base de conhecimento com IA e software de gestão de conhecimento apresenta o campo, e nossa análise dos benefícios de uma base de conhecimento com IA abrange o porquê.






