How to paginate through Zendesk tickets: A complete developer guide
Stevia Putri
Last edited March 2, 2026
If you're building integrations with Zendesk, you'll quickly discover that the API doesn't hand over your entire ticket database in one go. Instead, it serves data in bite-sized chunks through a mechanism called pagination. This is by design. Pagination keeps the API responsive and prevents timeouts when you're dealing with thousands (or millions) of support tickets.
But here's where it gets interesting. Zendesk offers two different ways to paginate through your data: cursor pagination and offset pagination. One is fast, modern, and virtually unlimited. The other is limited to 10,000 records and carries some baggage from older API designs. Since August 2023, Zendesk has been pushing developers toward cursor pagination by enforcing strict limits on the offset method.
In this guide, we'll walk through both pagination approaches with working code examples. You'll learn when to use each method, how to handle edge cases, and what pitfalls to avoid. And if you're thinking there must be an easier way to automate Zendesk workflows without writing pagination logic yourself, we'll cover that too.
Understanding Zendesk API pagination
Before we dive into code, let's clarify why pagination exists and how it works at a high level.
The Zendesk API breaks large result sets into smaller pages for performance reasons. Requesting 100,000 tickets in a single API call would timeout or crash most systems. Instead, you request page 1, process those results, then request page 2, and so on until you've retrieved everything.
Different endpoints have different default page sizes:
- Tickets and users: 100 items per page
- Help Center articles: 30 items per page
- Search results: 100 items per page maximum
You can usually adjust the page size within limits, but you can't exceed the maximum for any given endpoint.
All API requests count against your rate limit. Zendesk allows a certain number of requests per minute depending on your plan, and pagination can eat into that quota quickly if you're retrieving large datasets. The good news is that cursor pagination is more efficient than offset pagination, so switching methods can actually reduce your API usage.
One critical change to know about: starting August 15, 2023, offset-based pagination requests beyond the first 10,000 records (100 pages) return a 400 Bad Request error. If you need more than 10,000 records, cursor pagination is now your only option. Learn more about this change in the Zendesk offset pagination announcement.
Cursor pagination: the recommended method
Cursor pagination is Zendesk's preferred approach for most list endpoints. It uses a pointer (the cursor) that tracks your position in the dataset rather than counting records from the beginning each time. This makes it significantly faster for large datasets because the API doesn't need to count and skip records to find your page.
How cursor pagination works
To enable cursor pagination, add a page[size] parameter to your request. This tells Zendesk you want to use cursor mode and specifies how many items to return per page (up to 100 for most endpoints).
The response includes two key objects:
- meta: Contains
has_more(boolean),after_cursor, andbefore_cursor - links: Contains
nextandprevURLs for the adjacent pages
Here's what a typical response looks like:
{
"tickets": [
{ "id": 1, "subject": "Sample ticket" },
{ "id": 2, "subject": "Another ticket" }
],
"meta": {
"has_more": true,
"after_cursor": "eyJvIjoibmljZV9pZCIsInYiOiJhV2tCQUFBQUFBQUEifQ==",
"before_cursor": "eyJvIjoibmljZV9pZCIsInYiOiJhUzRCQUFBQUFBQUEifQ=="
},
"links": {
"next": "https://example.zendesk.com/api/v2/tickets.json?page[size]=100&page[after]=eyJvIjoibmljZV9pZCIsInYiOiJhV2tCQUFBQUFBQUEifQ==",
"prev": "https://example.zendesk.com/api/v2/tickets.json?page[size]=100&page[before]=eyJvIjoibmljZV9pZCIsInYiOiJhUzRCQUFBQUFBQUEifQ=="
}
}
You keep paginating until meta.has_more is false. At that point, you've retrieved all records.
Python example with cursor pagination
Here's a complete working example using Python and the requests library:
import requests
import time
ZENDESK_SUBDOMAIN = 'your-subdomain'
ZENDESK_EMAIL = 'your-email@example.com'
ZENDESK_API_TOKEN = 'your-api-token'
BASE_URL = f'https://{ZENDESK_SUBDOMAIN}.zendesk.com/api/v2/tickets.json'
auth = (f'{ZENDESK_EMAIL}/token', ZENDESK_API_TOKEN)
def fetch_all_tickets():
tickets = []
url = BASE_URL
params = {'page[size]': 100} # Use cursor pagination with 100 items per page
while url:
response = requests.get(url, auth=auth, params=params)
# Handle rate limiting
if response.status_code == 429:
retry_after = int(response.headers.get('Retry-After', 60))
print(f'Rate limited. Waiting {retry_after} seconds...')
time.sleep(retry_after)
continue
response.raise_for_status()
data = response.json()
# Process tickets from this page
for ticket in data['tickets']:
tickets.append(ticket)
print(f"Fetched ticket {ticket['id']}: {ticket['subject']}")
# Check if there are more pages
if data['meta']['has_more']:
url = data['links']['next']
params = None # Next URL already includes all parameters
else:
url = None
return tickets
if __name__ == '__main__':
all_tickets = fetch_all_tickets()
print(f'\nTotal tickets fetched: {len(all_tickets)}')
Key things to notice in this example:
- We start with
page[size]=100to enable cursor pagination - We check for rate limiting (HTTP 429) and respect the Retry-After header
- After the first request, we use the
links.nextURL directly for subsequent pages - The loop continues until
has_moreis false
Node.js example with cursor pagination
Here's the same logic in Node.js using axios:
const axios = require('axios');
const ZENDESK_SUBDOMAIN = 'your-subdomain';
const ZENDESK_EMAIL = 'your-email@example.com';
const ZENDESK_API_TOKEN = 'your-api-token';
const BASE_URL = `https://${ZENDESK_SUBDOMAIN}.zendesk.com/api/v2/tickets.json`;
const auth = Buffer.from(`${ZENDESK_EMAIL}/token:${ZENDESK_API_TOKEN}`).toString('base64');
async function fetchAllTickets() {
const tickets = [];
let url = BASE_URL;
let params = { 'page[size]': 100 };
try {
do {
const response = await axios.get(url, {
headers: { Authorization: `Basic ${auth}` },
params: params
});
const data = response.data;
// Process tickets from this page
for (const ticket of data.tickets) {
tickets.push(ticket);
console.log(`Fetched ticket ${ticket.id}: ${ticket.subject}`);
}
// Prepare for next page
if (data.meta.has_more) {
url = data.links.next;
params = null; // Next URL includes all parameters
} else {
url = null;
}
} while (url);
console.log(`\nTotal tickets fetched: ${tickets.length}`);
return tickets;
} catch (error) {
if (error.response && error.response.status === 429) {
const retryAfter = error.response.headers['retry-after'] || 60;
console.log(`Rate limited. Retry after ${retryAfter} seconds`);
} else {
console.error('Error fetching tickets:', error.message);
}
throw error;
}
}
fetchAllTickets();
Offset pagination: the legacy method
Offset pagination is the older approach that Zendesk still supports but no longer recommends. It works by specifying a page number and the API calculates which records to return based on that offset from the beginning of the dataset.
How offset pagination works
With offset pagination, you use the page parameter to request a specific page number, and optionally per_page to set the number of items per page (up to 100).
The response includes:
- next_page: URL for the next page, or null if you're on the last page
- previous_page: URL for the previous page, or null if you're on the first page
- count: Total number of records in the dataset
Here's a typical response:
{
"tickets": [
{ "id": 1, "subject": "Sample ticket" },
{ "id": 2, "subject": "Another ticket" }
],
"count": 15420,
"next_page": "https://example.zendesk.com/api/v2/tickets.json?page=2",
"previous_page": null
}
Python example with offset pagination
Here's how to paginate using the offset method:
import requests
import time
ZENDESK_SUBDOMAIN = 'your-subdomain'
ZENDESK_EMAIL = 'your-email@example.com'
ZENDESK_API_TOKEN = 'your-api-token'
BASE_URL = f'https://{ZENDESK_SUBDOMAIN}.zendesk.com/api/v2/tickets.json'
auth = (f'{ZENDESK_EMAIL}/token', ZENDESK_API_TOKEN)
def fetch_tickets_offset():
tickets = []
url = BASE_URL
while url:
response = requests.get(url, auth=auth)
if response.status_code == 429:
retry_after = int(response.headers.get('Retry-After', 60))
time.sleep(retry_after)
continue
if response.status_code == 400:
# You've hit the 10,000 record limit
print('Error: Cannot paginate beyond 10,000 records with offset pagination')
break
response.raise_for_status()
data = response.json()
for ticket in data['tickets']:
tickets.append(ticket)
# Move to next page
url = data['next_page']
return tickets
Limitations to be aware of
Offset pagination has several drawbacks that explain why Zendesk is phasing it out:
-
The 10,000 record hard limit: You cannot retrieve more than 10,000 records using offset pagination. Attempting to request page 101 or beyond returns a 400 error.
-
Performance degradation: As you request deeper pages (page 50, page 90), the API takes longer to respond because it must count and skip all preceding records.
-
Data inconsistency: If records are added or removed while you're paginating, you may see duplicates or miss records. This happens because the offset is calculated fresh for each request based on the current dataset state.
-
No total count with cursor pagination: One advantage of offset pagination is that it returns a
countof total records. Cursor pagination doesn't provide this, so you'll need a separate API call if you need the total.
Cursor vs offset: which should you use?
The choice is straightforward for most use cases:
| Feature | Cursor Pagination | Offset Pagination |
|---|---|---|
| Record limit | Unlimited | 10,000 maximum |
| Performance | Consistent (fast even at deep pages) | Degrades as page number increases |
| Total count available | No | Yes (count property) |
| Jump to arbitrary page | Not possible | Possible |
| Data consistency during pagination | Better | Prone to duplicates/missed records |
| Zendesk recommendation | Recommended | Legacy support only |
Use cursor pagination when:
- You need more than 10,000 records
- Performance matters (especially for large datasets)
- You're processing data sequentially without needing to jump around
Use offset pagination when:
- You need the total record count
- You're building a UI that lets users jump to specific pages
- You're working with a small dataset (under 10,000 records) and simplicity matters
If you're currently using offset pagination and hitting the 10,000 record limit, migrating to cursor pagination is straightforward. The main changes are:
- Replace
pageparameter withpage[size] - Check
meta.has_moreinstead of whethernext_pageis null - Use
links.nextfor the next page URL instead ofnext_page
Common pagination pitfalls and solutions
Even with working code, you'll encounter edge cases in production. Here's how to handle the most common issues.
Handling rate limits
Zendesk returns HTTP 429 when you exceed your rate limit. The response includes a Retry-After header telling you how many seconds to wait. Always implement exponential backoff rather than hammering the API:
import time
def make_request_with_backoff(url, auth, max_retries=5):
for attempt in range(max_retries):
response = requests.get(url, auth=auth)
if response.status_code == 429:
retry_after = int(response.headers.get('Retry-After', 60))
# Exponential backoff: wait longer with each retry
wait_time = retry_after * (2 ** attempt)
time.sleep(wait_time)
continue
return response
raise Exception('Max retries exceeded')
Dealing with empty pages
Occasionally you may encounter an empty page where has_more was true but the next request returns no records. This can happen when the final record from the previous page was the last record in the entire dataset. Save the previous after_cursor value for future use in this case.
Cursor expiration
For the Export Search Results endpoint, cursors expire after one hour. If your processing takes longer than that, you'll need to restart the export or process data more quickly.
Search API limitations
The Search API has its own pagination quirks:
- Maximum 1,000 results per query total
- Maximum 100 results per page
- Uses offset pagination only
- Requesting page 11 (at 100 results per page) returns a 422 error
If you need more than 1,000 search results, use the Export Search Results endpoint instead, which supports cursor pagination and returns up to 1,000 records per page. See the Zendesk Search API documentation for more details.
Automating Zendesk workflows without the API
Building custom API integrations with proper pagination, error handling, and rate limiting takes significant development effort. You need to write the code, maintain it as Zendesk updates their API, and handle all the edge cases we've discussed.
For many teams, there's a simpler path. eesel AI connects directly to your Zendesk account and handles all the data retrieval automatically. Instead of writing pagination logic, you configure what you want to accomplish through a visual interface.
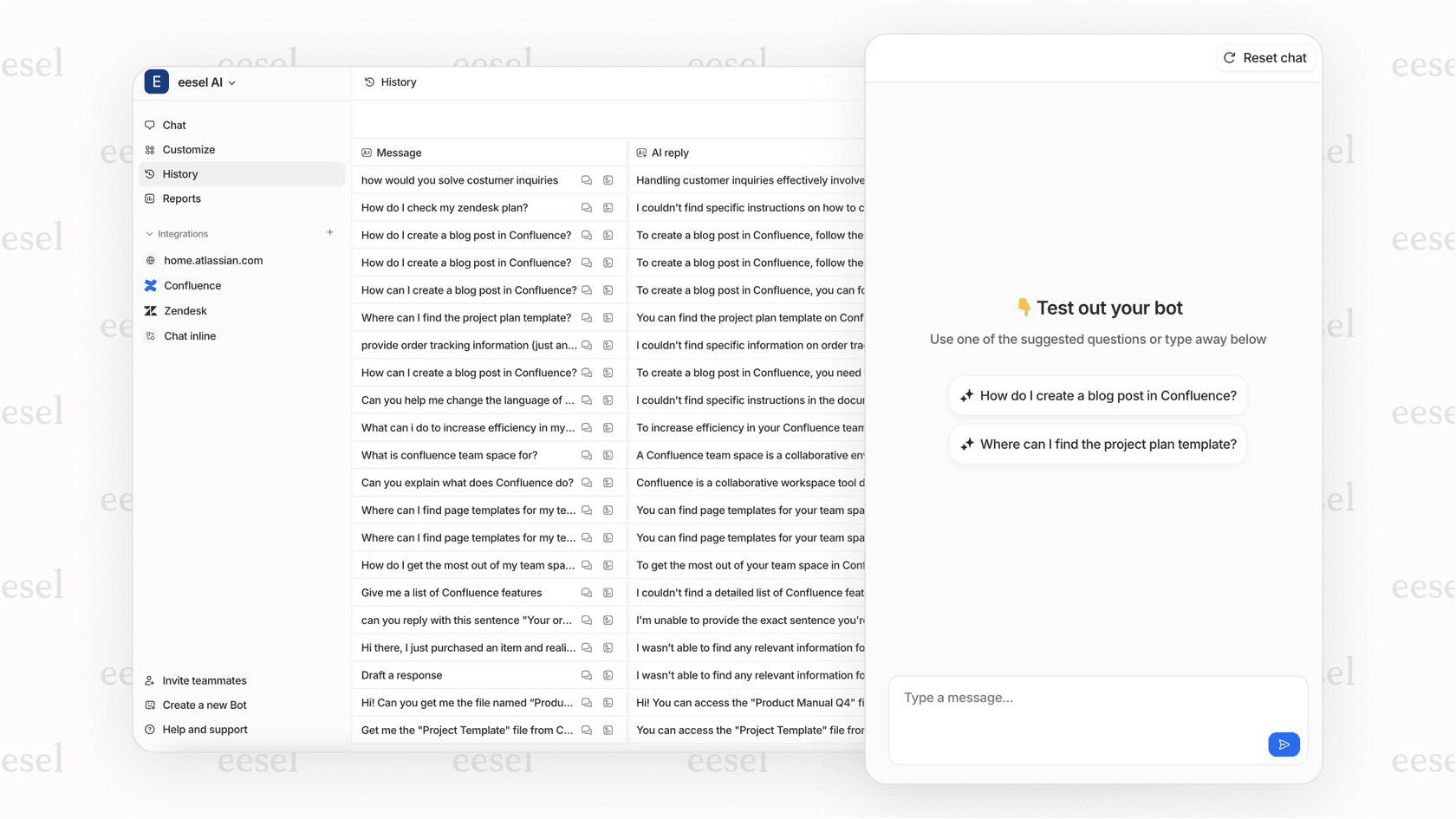
Here's how it works:
- Connect eesel AI to your Zendesk account in minutes
- The AI learns from your past tickets, help center articles, and macros
- You define automation rules in plain English (no code required)
- eesel AI handles all the API calls, pagination, and data processing
You can automate ticket routing, draft responses for your agents, tag and prioritize incoming tickets, and generate reports. All without writing a single line of pagination code.
For teams that need custom integrations, the Zendesk API remains the right choice. But if your goal is to automate workflows and improve efficiency, tools like eesel AI can get you there faster.
Start automating your Zendesk workflows today
Pagination is a fundamental concept when working with the Zendesk API. Cursor pagination offers better performance and no record limits, making it the clear choice for most modern integrations. Offset pagination still has its place for smaller datasets and when you need total record counts, but the 10,000 record limit means it's not suitable for large-scale data retrieval.
The code examples in this guide should give you a solid foundation for implementing pagination in your own projects. Remember to handle rate limits gracefully, watch for edge cases like empty pages, and choose the pagination method that fits your specific use case.
If you'd rather skip the API development entirely and start automating your Zendesk workflows today, try eesel AI. It handles the technical complexity so you can focus on delivering better customer support.
Frequently Asked Questions
Share this article

Article by
Stevia Putri
Stevia Putri is a marketing generalist at eesel AI, where she helps turn powerful AI tools into stories that resonate. She’s driven by curiosity, clarity, and the human side of technology.