Was es wirklich bedeutet, den Kundensupport zu automatisieren
Der Begriff deckt viel ab. Für Käufer in 2026 bedeutet „Kundensupport automatisieren" in der Regel eines von drei Dingen – und der Unterschied zwischen ihnen ist wichtiger, als die meisten Beiträge zugeben.
Die erste Interpretation ist die regelbasierte: Makros, Trigger, automatische Antworten, Round-Robin-Weiterleitung. Das ist es, was die meisten Helpdesks seit einem Jahrzehnt liefern. Es funktioniert, ist aber spröde – jedes neue Anliegen braucht eine neue Regel, und Regelbibliotheken wuchern zu Tausenden überlappender Bedingungen aus, die niemand im Team mehr versteht. Die zweite ist die Chatbot-Interpretation: ein Entscheidungsbaum auf der Website, der häufige Fragen abfängt, bevor sie zu Tickets werden. Diese haben durchaus ihre Berechtigung, aber ein Entscheidungsbaum-Bot ist eine Self-Service-FAQ mit zusätzlichen Schritten.
Die dritte – und die, um die es in diesem Leitfaden hauptsächlich geht – ist agentische Automatisierung: Software, die jedes eingehende Ticket liest, entscheidet, was zu tun ist, und entweder einen Antwortentwurf zur menschlichen Genehmigung erstellt, die Aktion selbst ausführt oder eskaliert. Moderne Systeme verwenden große Sprachmodelle (GPT-4, Claude, Gemini) als Denk-Backbone anstelle älterer Intent-Klassifizierungs-Pipelines allein, was bedeutet, dass sie Paraphrasen, Mehrdeutigkeiten und mehrstufige Fragen verstehen können, die schlüsselwortbasierte Systeme überfordern würden (ClarityArc, 2026).
Wenn wir in diesem Beitrag von „Kundensupport automatisieren" sprechen, meinen wir die dritte Interpretation – aber die praktische Wahrheit ist, dass die meisten Produktionseinsätze ein Stack aus allen dreien sind, wobei die Regeln das Deterministische übernehmen und das LLM das Urteilsvermögen.
Warum Teams das jetzt angehen
Drei Zahlen erzählen die ganze Geschichte.
Erstens: Kosten. Ein menschlich bearbeitetes Support-Ticket kostet die Branche im Durchschnitt 8 bis 12 US-Dollar, im B2B-SaaS 25 bis 35 US-Dollar (SaaS Capital 2024 B2B Support Spending Report, via theStacc); McKinseys Stichprobendurchschnitt liegt bei 7,40 US-Dollar (McKinsey AI in Customer Service 2026). Ein KI-bearbeitetes Ticket kostet 0,20 bis 0,40 US-Dollar für einfache FAQ-Deflection, 0,80 bis 1,50 US-Dollar für kontobewusste Agenten, mit einem McKinsey-Stichprobendurchschnitt von 0,62 US-Dollar (Gartner, 2025). Das ist die Lücke, die jeden CFO im Support zu einer Anbieterdemo greifen lässt.
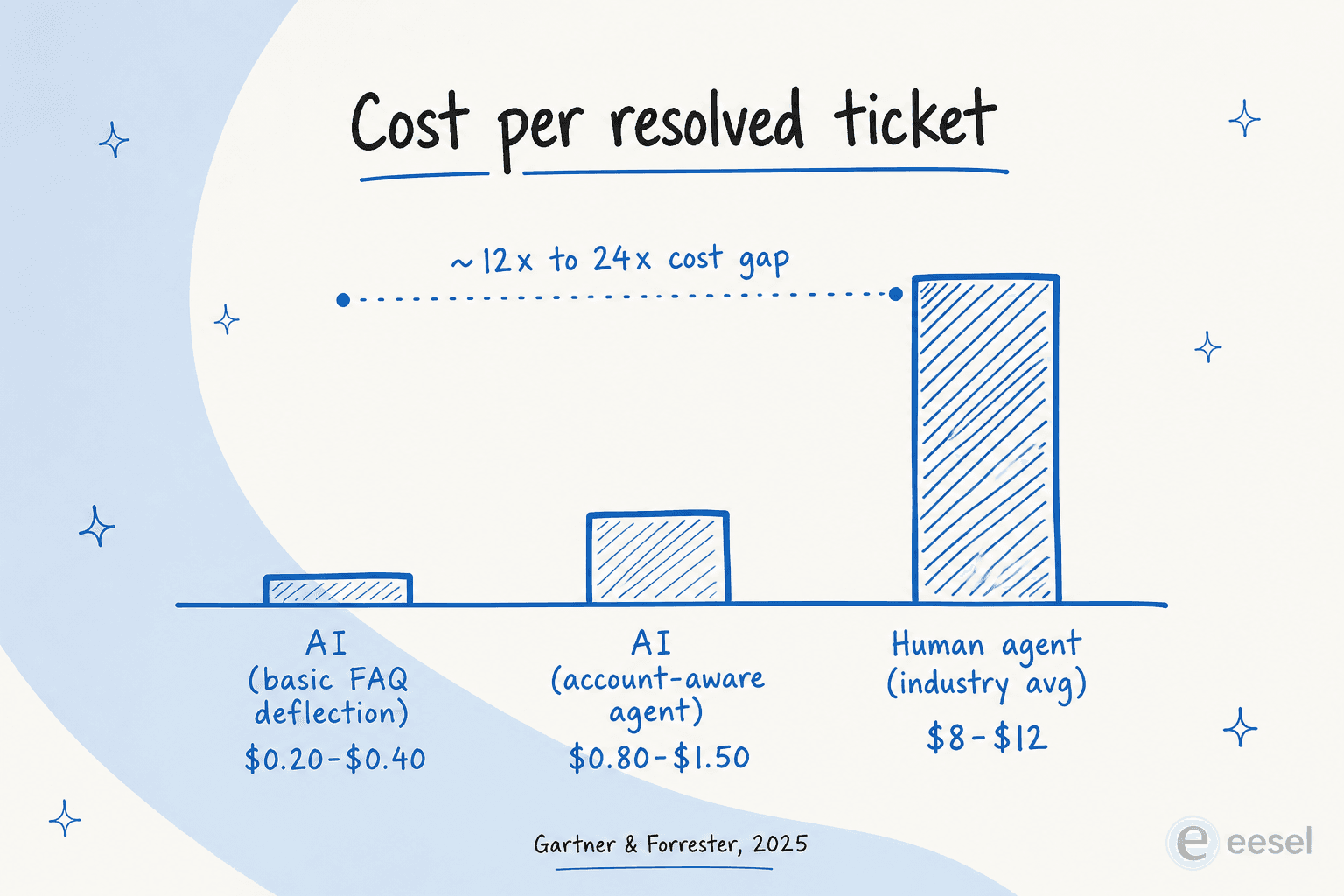
Zweitens: Ergebnisse. Unternehmen, die 2025 KI im Kundendienst eingesetzt haben, senkten die Support-Kosten im Durchschnitt um 30 %, wobei das obere Quartil 53 % Reduzierungen meldete (IBM, 2025, via theStacc). Die Amortisationszeit beträgt 6 bis 9 Monate (Deloitte, 2025), und der durchschnittliche ROI liegt bei 3,50 US-Dollar pro 1 US-Dollar Investition, mit einem durchschnittlichen ROI von 41 % im ersten Jahr (Lorikeet CX benchmarks). Die Gartner-Prognose für die gesamten globalen Einsparungen durch KI-Kundendienst beläuft sich auf 80 Milliarden US-Dollar bis 2027 (Gartner, 2024).
Drittens – und das ist das interessantere menschliche Signal – wird das Volumenproblem nicht besser. Teams ertrinken in sich wiederholenden Tickets, und die Menschen, die uns darüber schreiben, klingen genau so:
Als schnell wachsendes Startup mit einem kleinen Team übersteigt die Anzahl unserer Kunden bei Weitem die unserer Mitarbeiter. Es ist entscheidend, dass wir robuste Self-Service-Lösungen sowie Tools haben, um die Effizienz unserer kundenorientierten Teams zu steigern.
- Jon Miron, Director of Support & Operations, Yellowdig
Die Kostenmathematik sorgt dafür, dass das Budget genehmigt wird. Die Volumenrealität ist es, die das Projekt tatsächlich zum Laufen bringt.
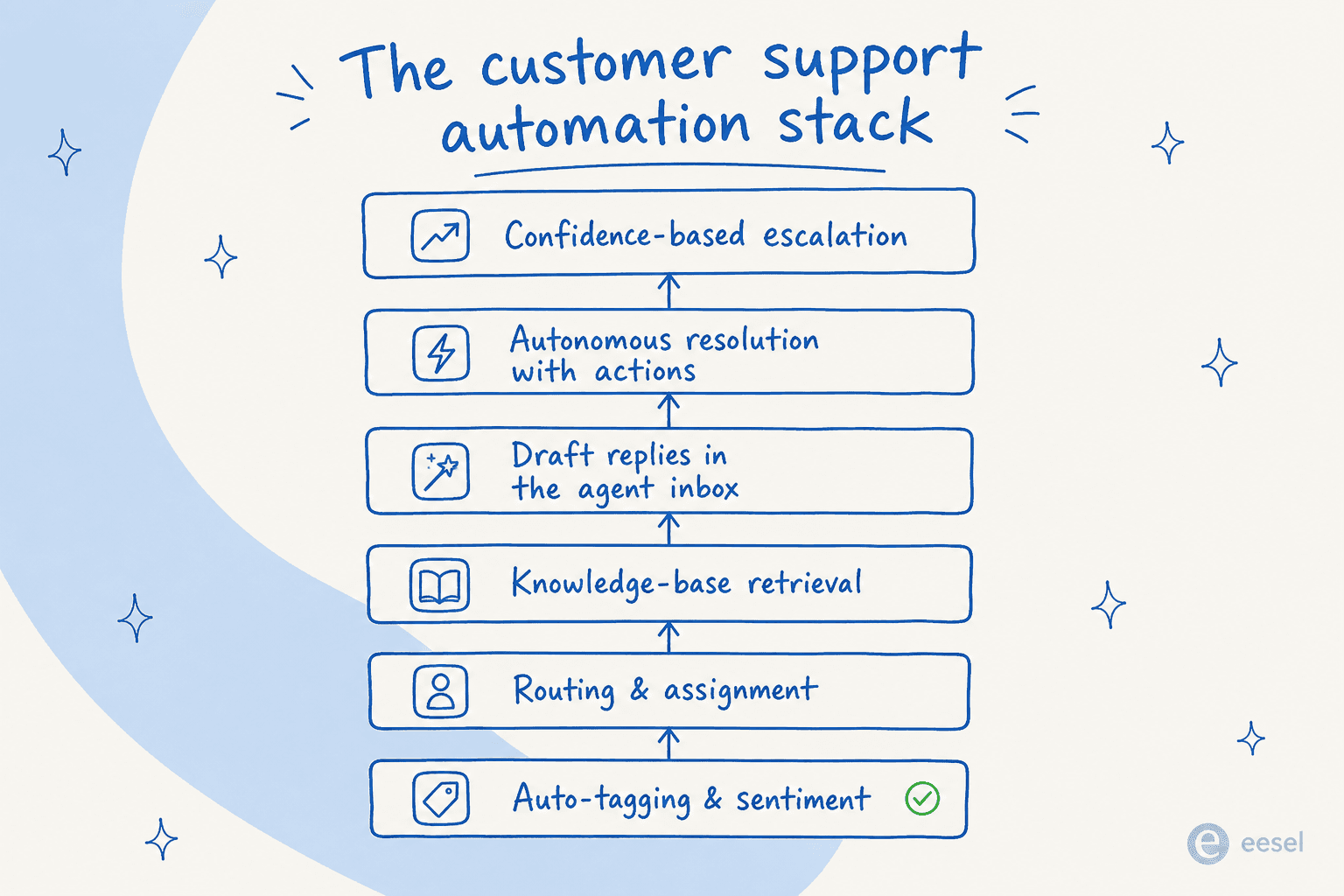
Die sechs Ebenen des Kundensupport-Automatisierungs-Stacks
Wenn Käufer sich „Support automatisieren" vorstellen, neigen sie dazu, die dramatischste Version zu sehen – eine KI, die Tickets liest und ohne menschliche Beteiligung antwortet. Das ist die Spitze des Stacks. Alles darunter leistet echte Arbeit, und bei den meisten Teams liegen dort die sichersten und schnellsten Erfolge.
Ebene 1 – Auto-Tagging und Stimmungsanalyse
Das kleinste, risikoärmste Element. Das System liest jedes eingehende Ticket, klassifiziert es (Anliegen, Priorität, Stimmung, Produktbereich) und schreibt diese Tags in den Helpdesk, bevor ein Mensch es öffnet. Die nachgelagerten Vorteile sind sofort spürbar: Weiterleitungsregeln werden präziser, Berichte werden aussagekräftiger, und das Team hört auf, Tickets manuell neu zu taggen. Praktische Anleitungen: Mit Ticket-Tags arbeiten und KI-Ticket-Klassifizierung.
Ebene 2 – Weiterleitung und Zuweisung
Sobald Tags vorhanden sind, folgt die Weiterleitung. Die KI weist jedes Ticket der richtigen Warteschlange, dem richtigen Agenten oder der richtigen Skill-Gruppe basierend auf Anliegen, Sprache, Kundenstufe oder SLA zu. Richtig umgesetzt, beseitigt dies das Muster des „Tickets, das im Team herumreicht" und Stunden zur Erstantwortzeit hinzufügt, ohne etwas zu lösen. Der Zendesk-Leitfaden zur Ticket-Weiterleitung ist hier das Standardwerk, und dieselbe Logik lässt sich sauber auf Freshdesk und Jira Service Management übertragen.
Ebene 3 – Wissensdatenbank-Abruf
Das ist die Ebene, die die meisten Beiträge überspringen, und die eigentlich bestimmt, ob der Rest des Stacks funktioniert. KI-Ticket-Deflection ist im Kern ein Wissensabrufsystem mit einer konversationellen Oberfläche – seine Qualitätsobergrenze ist die Qualität der Wissensdatenbank, aus der es abruft. Pylons Analyse ergab, dass gut strukturierte Dokumentation die echte Lösungsrate um 15 bis 25 % steigert, und EBI.ai berichtete von 96 % Erfolgsraten bei themenrelevanten Anfragen, wenn die Dokumentation gründlich war (SupportBench).
Wenn Ihre Wissensdatenbank lückenhaft ist, bereinigen Sie sie, bevor Sie alles andere einschalten. Ein Retrieval-augmentiertes LLM, das auf schlechten Dokumenten trainiert wurde, wird selbstbewusst falsche Antworten erfinden – und ein Kunde, der eine falsche, selbstbewusste Antwort erhalten hat, wandert schneller ab als einer, der „Lass mich das mit dem Team klären" bekommen hat.
Ebene 4 – Antwortentwürfe im Agent-Posteingang
Die „Copilot"-Ebene. Die KI liest das Ticket, ruft die relevanten Dokumente ab und schreibt eine vollständige Antwortvorschlag als interne Notiz (oder als Entwurf im Antwortfenster), den ein menschlicher Agent überprüfen, bearbeiten und senden kann. Dies ist der Ausgangspunkt mit dem höchsten Hebel für die meisten Teams: Agenten arbeiten schneller, der Mensch ist noch für Ton und Richtigkeit verantwortlich, und das Team baut Vertrauen in die Genauigkeit des Modells auf, bevor irgendetwas autonom läuft.
Das klassische Vorgehen ist, die KI als „Ersthelfer" einzustellen – die auf eingehende Tickets reagiert, einen Antwortvorschlag hinterlässt und manchmal eine Dokumentensuche über PDFs und Wissensdatenbank-Artikel durchführt, bevor sie einen Entwurf erstellt:
Wir nutzen es als Ersthelfer für unsere Helpdesk-Tickets in Jira. Es verhält sich im Wesentlichen genau wie ein Agent.
- Jason Loyola, Head of IT, InDebted Fallstudie
Dieses Team nutzt die Antwortentwurfs-Ebene, um die Deflection von 15 % auf 55 % bei einem internen IT-Desk auf Jira Service Management zu steigern. Dasselbe Muster funktioniert bei kundenseitigen Desks: Antwortentwürfe in Zendesk, Gorgias-Automatisierungen und Freshdesk-Automatisierung unterstützen dieses Muster nativ oder über einen Anbieter darüber.
Ebene 5 – Autonome Lösung mit Aktionen
Die dramatische Ebene. Die KI liest das Ticket, entscheidet über eine Aktion, führt sie aus (Rückerstattung, Abonnementänderung, Adressänderung, Bestellstatusabfrage) und schreibt dem Kunden zurück – ohne menschliche Beteiligung. Hier kommen die auffälligen Zahlen her: Klarnas KI übernimmt zwei Drittel des gesamten Kundendienstes – das Äquivalent von 700 Vollzeitmitarbeitern (SaaStr). Bilt Rewards bearbeitet 70 % von 60.000 monatlichen Tickets autonom (SaaStr citing Decagon). Grammarlys Einsatz erreichte 87 % Deflection innerhalb von 10 Tagen mit einem CSAT von 4,2/5 (Forethought Fallstudie).
Der Haken ist, dass diese Ebene nur funktioniert, wenn die vorherigen vier solide sind. Zu versuchen, direkt zur autonomen Lösung zu springen, ohne die Wissensdatenbank-Bereinigung und die Antwortentwurfs-Phase zuerst zu durchlaufen, führt zu dem Fehlermuster, das im nächsten Abschnitt beschrieben wird.
Ebene 6 – Konfidenzbasierte Eskalation
Das Sicherheitsnetz – und wohl die wichtigste Ebene überhaupt. Die KI generiert eine Kandidatenantwort, bewertet ihr eigenes Vertrauen (anhand von Abrufabdeckung, historischem Erfolg beim Anliegen und Unsicherheitssignalen in der generierten Antwort) und sendet nur dann autonom, wenn der Score einen Schwellenwert überschreitet. Darunter eskaliert sie mit vollem Kontext an einen Menschen.
Der Konfidenz-Schwellenwert ist eine der kritischsten Designentscheidungen in jedem Deflections-System – und muss durch Tests kalibriert werden, nicht angenommen (ClarityArc, 2026). Vertrauen Sie auch nicht rohen LLM-Konfidenzbewertungen: Sie messen Token-Wahrscheinlichkeit, nicht faktische Genauigkeit. Ein Modell kann sich zu 95 % „sicher" über eine halluzinierte Antwort sein (DEV Community). Kombinieren Sie Konfidenzbewertungen mit Wissensdatenbank-Abdeckungssignalen und Themenbereichsregeln.
Die Deflections-Falle – und warum „Lösung" die bessere Kennzahl ist
Hier gehen die meisten Teams falsch vor, und es ist das eine, dem wir am stärksten widersprechen würden, wenn ein Freund uns nach seinem Rollout-Plan fragt.
Die Deflektionsrate ist die häufigste Kennzahl für die Support-Automatisierung – und eine verfluchte. Für Deflection zu optimieren bedeutet, für weniger Tickets zu optimieren, nicht für bessere Ergebnisse. Die KPI verbessert sich; die Kundenerfahrung verschlechtert sich. Zwei Fehlermuster, beide gut dokumentiert:
Fehlermuster eins – der Bot als Türsteher. Die Deflektionsrate erreicht 75 %, das Dashboard leuchtet grün, die besten Kunden wandern still ab. Aus der Analyse von Corebee.ai von 50+ Support-Team-Diskussionen:
Ein SaaS-Gründer beschrieb dies genau so: "Das Optimieren auf Ticket-Deflection mit KI hätte fast unsere Churn-Rate ruiniert. Hören Sie auf, Bots als Türsteher zu nutzen." Ihre Deflektionsrate erreichte 75 %. Ihre Kunden mit hohem LTV wanderten ab, weil sie sich daran gehindert fühlten, einen Menschen zu erreichen.
Fehlermuster zwei – die selbstbewusst falsche Antwort. Der Bot antwortet, wenn er es nicht hätte tun sollen. Der Kunde vertraut ihm. Die einfache Frage wird zu einer Vertrauenskrise. Corebee fand dieses Muster in sieben separaten Diskussions-Threads, und die Grundursache ist konsistent: Bots, die auf Deflektionsrate optimiert sind, werden versuchen, Anfragen zu beantworten, die sie eskalieren sollten.
Die Lösung ist zweigleisig. Erstens: Ändern Sie die Kennzahl. Optimieren Sie für Lösungsrate – den Anteil der Tickets, die die KI geschlossen hat, bei denen der Kunde sich nicht innerhalb von 48 Stunden erneut gemeldet hat, den CSAT nicht gesenkt hat und nicht an einen Manager eskaliert hat. Gartner stellte fest, dass KI insgesamt mehr als 45 % der Kundenanfragen ablenkt, aber nur etwa 14 % eine vollständige Self-Service-Lösung erreichen (Gartner via Fini Labs) – diese 31-Punkte-Qualitätslücke ist genau die Falsch-Deflections-Falle.
Zweitens: Bauen Sie konfidenzbasiertes Routing von Anfang an ein. Die klarste Formulierung davon, die wir haben, stammt von einem CX-Lead bei einer DTC-Supplements-Marke mit ~7.000 Gorgias-Tickets/Monat:
Die KI wird nie in der Lage sein, 100 % der Fragen zu beantworten. Ich brauche eine KI, die nur die Tickets bearbeitet, bei denen sie zuversichtlich ist, und alle anderen in Ruhe lässt.
- anonymisiert als CX-Lead bei einer DTC-Supplements-Marke auf Gorgias + Shopify (~7K Tickets/Monat), aus eesel-Kundeninterviews
Dieser Satz ist die ganze These. Streben Sie nicht nach einer KI, die jedes Ticket beantwortet; streben Sie nach einer, die weiß, welche sie nicht anfassen sollte.
Wie echte Teams es einsetzen
Die unten genannten Anwendungsfälle sind dort, wo wir bei echten eesel-Kunden den meisten ROI sehen – aber die Muster lassen sich auf jeden modernen Support-Automatisierungsanbieter übertragen.
Erstlinienbetreung mit sauberem Übergabe-Prozess. Die KI bearbeitet Frontline-Fragen, wenn Menschen nicht verfügbar sind, und tritt zurück, sobald das Problem Urteilsvermögen erfordert. Aus einem freigegebenen Kundenzitat:
eesel fungiert als unsere Erstlinienunterstützung, bis ein menschlicher Kontakt erforderlich ist – es beantwortet schnelle Fragen, wenn das Team nicht verfügbar ist, und lässt uns die Probleme lösen, die nur wir lösen können.
- Kellen Brown, Textla (freigegebene G2-Bewertung, eesel auf G2)
Triage mit internen Notizentwürfen. Der Agent wird bei jedem eingehenden Ticket ausgeführt, klassifiziert es, führt Dokumentensuchen über die Wissensdatenbank (und Produkt-PDFs, falls erforderlich) durch und hinterlässt einen vollständigen Antwortvorschlag als interne Notiz. Der Mensch überprüft und sendet entweder oder schreibt neu. Wir haben gesehen, dass dies bei rumänischen Zahlungsgateway-Fragen, bei technischen EtherCAT-Problemen bei Industrieautomatisierungs-Anbietern und bei der Spam-Erkennung (der Agent gleicht eingehende „Vertriebspitch-Tickets" mit vergangenen Beispielen ab und entwirft eine höfliche Ablehnung) funktioniert. Das Muster ist dasselbe; die Eingaben variieren erheblich.
Taggen, weiterleiten und warmhalten. Über Entwürfe hinaus taggt die KI automatisch, füllt benutzerdefinierte Felder aus und leitet an die richtige Warteschlange weiter. Einige Teams nutzen dieselbe Automatisierungsschicht, um eskalierte Tickets mit Beruhigungsnachrichten „warm" zu halten, während das Team auf Drittanbieter-Auszahlungspartner wartet – keine Wissensdatenbank erforderlich, nur Anweisungen. (Aus einem anonymisierten Fintech-Kundeninterview, ~7.000 eskalierte Tickets/Monat.)
Stammeswissen sichern, bevor es geht. Dies ist der Anwendungsfall, den wir am häufigsten von älteren Support-Organisationen hören: erfahrene Agenten mit tiefem Produktwissen gehen, und das Team möchte ihre Antworten „in der KI", bevor sie gehen. Ein französisches B2B-IT-Dienstleistungsunternehmen, das öffentlichen ERP-Troubleshooting-Support (~3.000 Tickets/Monat auf Freshdesk) leistet, formulierte es genau so – der Job der KI war nicht, die erfahrenen Agenten zu ersetzen, sondern ihre Antworten verfügbar zu halten, nachdem sie gegangen sind.
Der Punkt ist, dass „Kundensupport automatisieren" nicht unbedingt autonome Lösung bedeuten muss, um ein Erfolg zu sein. Die Ebenen 1 bis 4 (Tagging, Weiterleitung, Wissensdatenbank-Abruf, Antwortentwürfe) generieren in der Regel mehr Gesamt-ROI als Ebene 5 jemals tut, und sie sind in Wochen statt Quartalen einsatzbereit.
Ein praktischer 5-Schritte-Rollout
Die meisten gescheiterten Support-Automatisierungsprojekte, von denen wir hören, haben einen Schritt hier übersprungen. Die Reihenfolge ist wichtig.
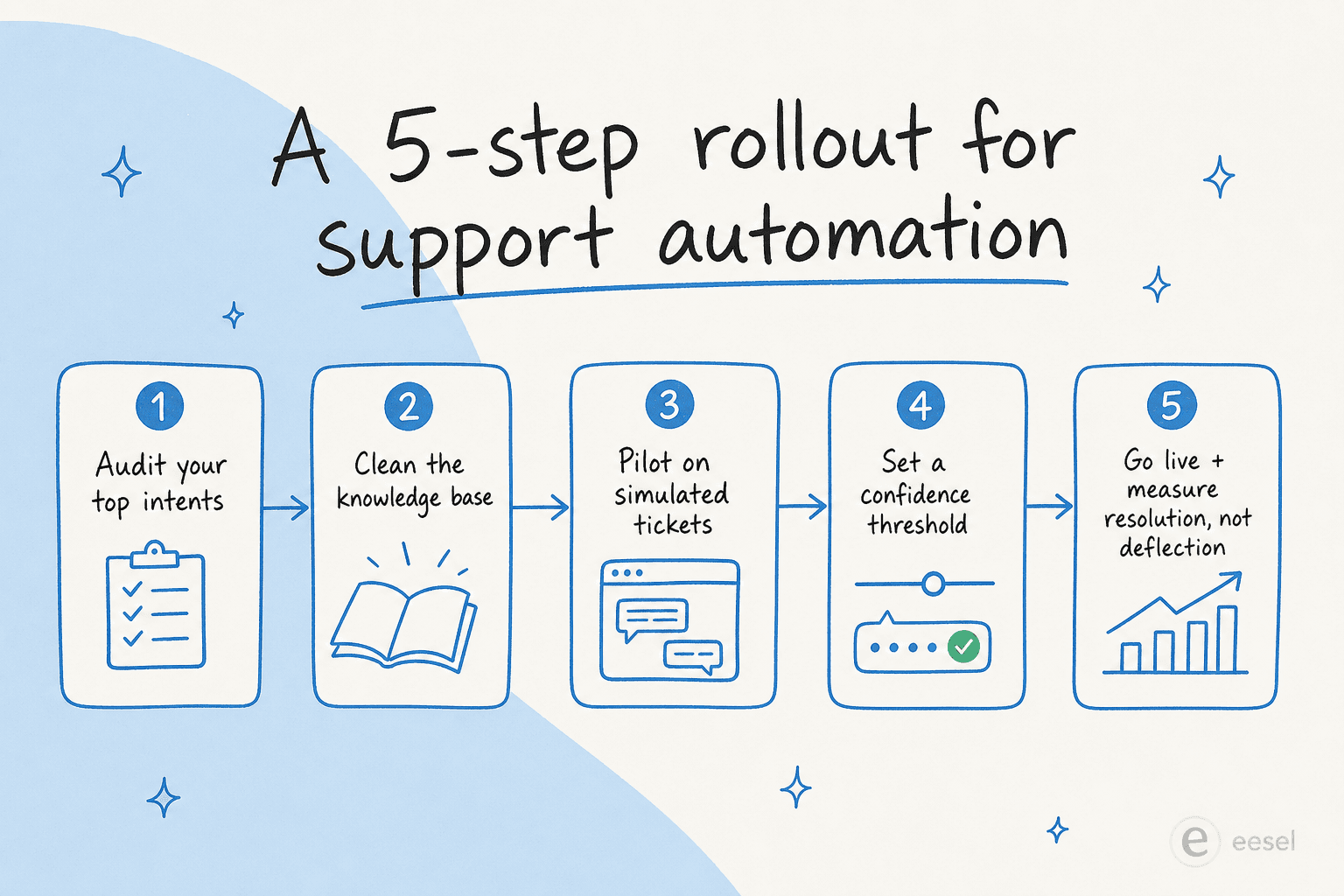
Schritt 1 – Ihre häufigsten Anliegen prüfen
Ziehen Sie die Tickets der letzten 30 Tage und sortieren Sie sie nach Anliegen. Sie suchen nach den 10 häufigsten Kategorien, die 70 bis 80 % des Gesamtvolumens ausmachen. Das sind die Ziele – Automatisierung zahlt sich am schnellsten bei häufigen, wenig komplexen Anliegen aus. Stimmungsgeladene oder streitähnliche Anliegen überschreiten selten 25 % Deflection selbst bei den besten Implementierungen (ClarityArc 2026), also lassen Sie diese aus dem anfänglichen Umfang heraus.
Konkreter Rahmen: Wenn Passwort-Zurücksetzungen, Abrechnungsfragen und Bestellstatus 60 % Ihres Volumens ausmachen, sind diese drei Kategorien Ihre erste Phase. Versuchen Sie nicht, in v1 „alles zu machen".
Schritt 2 – Die Wissensdatenbank bereinigen
Finden Sie für jedes der häufigsten Anliegen den Artikel, der es beantworten sollte. Wenn er nicht existiert, schreiben Sie ihn. Wenn er existiert, aber veraltet oder im falschen Ton ist, überarbeiten Sie ihn. Das ist der unspektakuläre Schritt, der bestimmt, ob der Rest des Rollouts funktioniert. Der Leitfaden zum KI-Wissensdatenbank-Chatbot geht tiefer darauf ein, wie „gut" aussieht – kurze Antworten oben, strukturierte Überschriften, Beispiele, kein Hedging.
Eine nützliche Probe: Lesen Sie den Artikel und fragen Sie: „Wenn ein neuer Mitarbeiter nur das liest, könnte er die Frage richtig beantworten?" Wenn nicht, kann die KI es auch nicht.
Schritt 3 – Testen Sie mit simulierten Tickets, nicht mit echten Kunden
Bevor ein Kunde die Ausgabe der KI sieht, führen Sie sie gegen die letzten 90 Tage echter Tickets in einem Simulationsmodus aus. Vergleichen Sie die Entwürfe der KI mit dem, was der menschliche Agent tatsächlich gesendet hat. Wo weichen sie ab? Wo hätte die KI eskaliert? Wo hat die KI eine selbstbewusste Antwort geschrieben, die sich als falsch herausstellte? Dies ist der einzige ehrliche Weg, Erwartungen mit dem Team vor dem Go-Live zu setzen, und hier finden Sie die Fehlermodi, die in keiner Anbieterdemo zu sehen sind.
Achten Sie auf Teams, deren Anbieter diese Simulationsfunktion nativ anbietet – es ist ein klarer Filter zwischen Anbietern, die in der Produktion eingesetzt haben, und solchen, die es nicht haben.
Schritt 4 – Einen Konfidenz-Schwellenwert (und eine Verbotsliste) festlegen
Bevor Sie für echte Kunden einschalten, sind zwei Entscheidungen zu treffen:
- Der Konfidenz-Schwellenwert für autonome Antworten. Die meisten Teams beginnen konservativ (hoher Schwellenwert, geringes Volumen autonomer Antworten, hohe Genauigkeit) und lockern im Laufe der Zeit. Permissiv zu beginnen und zu verschärfen ist viel schwieriger, weil das Vertrauen des Teams am ersten Tag beschädigt wird.
- Die Verbotsliste. Ticket-Typen, die die KI niemals autonom lösen wird – Dinge wie Stornierungen, Rückerstattungen über einem bestimmten Betrag, alles als „Rechtsstreit" oder „Abrechnungsstreit" getaggte, alles von einem VIP-Kundensegment. Aus einem echten Kundenzitat: „Es gibt bestimmte Tickets, bei denen ich nicht möchte, dass sie durch KI laufen."
Schritt 5 – Live gehen, Lösung messen (nicht Deflection)
Schalten Sie es für einen Kanal, einen Anliegen-Cluster ein. Beobachten Sie Lösungsrate, CSAT-Delta, Wiederkontaktrate innerhalb von 48 Stunden und Eskalationsgenauigkeit. Beobachten Sie nicht nur die Deflektionsrate – sie wird Ihnen sagen, dass der Bot großartig ist, während die Kundenerfahrung darunter zusammenbricht.
Ein nützlicher KPI-Mix für die Führungsebene:
| Kennzahl | Was sie Ihnen sagt |
|---|---|
| Lösungsrate | % der Tickets, die ohne Wiederkontakt innerhalb von 48 Stunden geschlossen wurden |
| CSAT-Delta vs. Nur-Mensch-Baseline | Ob die KI-Tickets sanfter landen als menschliche |
| Eskalationsgenauigkeit | % der eskalierten Tickets, die tatsächlich die richtige Entscheidung waren |
| Erstantwortzeit (Median) | Der Rückgang hier ist in der Regel der größte sichtbare Erfolg |
| Kosten pro Lösung | Der wirtschaftliche ROI-Hebel |
Dieser Mix belohnt „beantwortet weniger Tickets, beantwortet sie aber richtig" gegenüber „beantwortet alles schlecht". Führen Sie ihn monatlich aus; verschärfen Sie den Schwellenwert basierend auf dem, was er zeigt.
Die Fallstricke, für die es sich lohnt, Budget einzuplanen
Sechs Fehlermuster, die es sich lohnt, vor dem Start zu durchdenken – alle in Produktionseinsätzen dokumentiert:
- Die selbstbewusst falsche Antwort. LLM-Konfidenzbewertungen messen Token-Wahrscheinlichkeit, nicht faktische Genauigkeit (DEV Community). Kombinieren Sie Konfidenz mit Wissensdatenbank-Abdeckungssignalen.
- Wiederkontakt, der als Deflection getarnt ist. Kunden melden sich über andere Kanäle (Telefon, E-Mail, Social Media) wieder. Das Plattform-Dashboard zeigt 80 % Deflection; die echte Deflection, angepasst für 48-Stunden-Wiederkontakt, liegt näher bei 55–65 % (ClarityArc 2026).
- Den KPI optimieren, nicht das Ergebnis. Machen Sie Deflection zur KPI und das Team wird es schwieriger machen, Tickets zu öffnen – der Bot geht in Schleifen, die Kontakt-Schaltfläche wird vergraben, der CSAT sinkt. Wechseln Sie zur Lösungsrate.
- Die 47-%-Flat-Cost-Falle. Unternehmen, die Workflows nicht rund um KI neugestaltet haben: 47 % berichteten von gleichbleibenden oder steigenden Kosten (theStacc 2026). KI als Anbau ohne Prozessüberarbeitung fügt nur Lizenzkosten zur bestehenden Lohnkasse hinzu.
- KI-Bias hin zu Antwortversuchen. Eine Studie mit 100.050 Interaktionen stellte fest, dass KI-Bots 37 % häufiger Probleme von der Lösung wegbewegen als Menschen, wenn sie für Deflection konfiguriert sind (Studie zitiert von Corebee). Verbieten Sie Anliegen, die die KI nicht anfassen sollte.
- Den Piloten überspringen. „Wir schalten es einfach ein und stimmen es live ab" ist die Art, wie Anbieter in Woche zwei Kunden verlieren.
Worauf Sie bei einem Anbieter achten sollten
Nach Dutzenden dieser Rollouts beobachtet sind die Funktionen, die wirklich wichtig sind (und über die die meisten Anbieter nicht genug sprechen):
- Native Integration mit dem bestehenden Helpdesk. Nicht migrieren. Die KI sollte innerhalb von Zendesk, Freshdesk, Gorgias oder wo auch immer das Team bereits arbeitet sitzen. Ein Austausch des Gesamtsystems verdoppelt das Projektrisiko ohne Mehrwert.
- Simulationsmodus gegen vergangene Tickets. Siehe oben. Das ist der klarste Anbieterfilter.
- Konfidenzbasiertes Routing als Erstklassige Funktion, nicht als Anbau. Granular: pro Anliegen, pro Ticket-Typ, pro Kundensegment.
- Ticket-Typ-Ausschlusslisten. „Es gibt bestimmte Tickets, bei denen ich nicht möchte, dass sie durch KI laufen" – das ist ein echtes Kundenzitat, und die richtige Antwort ist ein UI-Steuerelement, keine Slack-Nachricht an den CSM des Anbieters.
- Nutzungsbasierte Preisgestaltung, nicht Pro-Seat. Pro-Seat-Preisgestaltung bestraft Sie dafür, Menschen zum Support-Team hinzuzufügen – was genau das ist, was Sie tun möchten, wenn das Ticket-Volumen in absoluten Zahlen steigt (was es tendenziell tut, selbst wenn der KI-Anteil steigt). eesel's Preisgestaltung beträgt 0,40 US-Dollar pro Ticket ohne Seat-Gebühren als konkretes Beispiel.
- Mehrsprachige Verarbeitung ohne Prompt-Pflege. Wenn Ihr Kundenstamm mehr als eine Sprache umfasst, ist das wichtiger, als die Demo erkennen lässt.
- Eine ehrliche Messung der Lösung, nicht nur der Deflection, im Dashboard dargestellt. Bonus, wenn es Ihnen die Tickets zeigt, bei denen die KI falsch lag, nicht nur die, bei denen sie richtig lag.
Für einen direkten Vergleich der tatsächlichen Optionen decken unser Rundblick Beste KI für die Kundensupport-Automatisierung und Top KI-Tools zur Automatisierung des Kundensupports das Feld ab; Beste KI für Shopify-Kundensupport und Bester KI-Chatbot für den Kundenservice zoomen auf spezifische Nischen ein.
Was gute Rollouts tatsächlich erreichen
Ein realistisches Bild davon, wo die Zahlen in der Regel landen, aus echten Produktionsdaten statt aus Anbieter-Verkaufspräsentationen:
| Ergebnis | In der Produktion gesehene Bandbreite | Quelle |
|---|---|---|
| Tier-1-Deflection (Median) | 41 % | ClarityArc 2026 |
| Tier-1-Deflection (oberes Quartil) | 58,7 % | ClarityArc 2026 |
| Beste agentische Deflection | 70–92 % bei Routine-Anliegen | Forrester Wave 2025 |
| Kostensenkung (Durchschnitt erstes Jahr) | 30 % | IBM 2025 |
| Kostensenkung (oberes Quartil) | 53 % | IBM 2025 |
| Verbesserung der Erstantwortzeit | 37 % schneller | G2 AI in Customer Service |
| Verbesserung der Lösungszeit | 52 % schneller | G2 AI in Customer Service |
| Durchsatz KI-verstärkter Agenten | 13,8 % mehr Anfragen/Stunde | G2 AI in Customer Service |
| Amortisationszeit | 6–9 Monate | Deloitte 2025 |
| Durchschnittlicher ROI | 3,50 US-Dollar pro 1 US-Dollar investiert | Lorikeet CX |
Einige echte Produktionsbeispiele, um diese Bandbreiten mit benannten Teams zu verankern: Klarnas KI übernimmt zwei Drittel des Kundendienstes (entspricht 700 Vollzeitmitarbeitern); Bilt Rewards bearbeitet 70 % von 60.000 monatlichen Tickets autonom; Grammarly erreichte 87 % Deflection innerhalb von 10 Tagen mit einem CSAT von 4,2/5 und einer weiteren Steigerung von 5–10 % durch Systemintegrationen; Forma (13.800 Nutzer auf Forethought Solve) steigerte die Deflection von 30 % auf 39 % zwischen Oktober 2024 und März 2025 durch kontinuierliche Optimierung; Einzelhandelsteams auf Freshworks Freddy lösen 53 % der eingehenden Anfragen mit KI, laut Freshworks Customer Benchmark Report 2025. SaaStrs Rundblick ist die klarste Einzelquelle für diese Zahlen.
Auf unserer eigenen Seite haben wir bis zu 80 % Zeitersparnis bei schnellen Antworten und Onboarding aus Global Pays Confluence-gestütztem Einsatz gesehen (siehe Confluence KI-Anwendungsfälle), und Gridwises CX-Lead berichtete: „73 % unserer Tier-1-Anfragen... erzielen schnell Ergebnisse während unseres 7-tägigen Tests." Beides sind freigegebene Kundentestimonials.
eesel ausprobieren
eesel ist die Support-Automatisierungsschicht, zu der wir greifen würden, wenn Sie bereits auf Zendesk, Freshdesk, Gorgias, Jira Service Management oder Slack sind – und Sie nicht migrieren möchten, um die Automatisierung zum Laufen zu bringen. Der Agent liest jedes eingehende Ticket, führt Dokumentensuchen über Ihre Wissensdatenbank und historische Tickets durch, entwirft die Antwort (oder sendet sie autonom, wenn er zuversichtlich ist) und eskaliert den Rest mit vollem Kontext. Konfidenz-Routing, Ticket-Typ-Ausschluss, Simulationsmodus gegen vergangene Tickets und Pro-Anliegen-Leitplanken sind alle erstklassige Funktionen, keine Roadmap-Punkte.

Die Preisgestaltung beträgt 0,40 US-Dollar pro gelöstem Ticket, keine Seat-Gebühren, keine Plattformgebühr bei Self-Service und ein 50-US-Dollar-Testguthaben bei der Anmeldung. Das vollständige Details finden Sie auf der Preisseite, und der Rundblick Beste KI für die Kundensupport-Automatisierung stellt ihn im direkten Vergleich mit dem Rest des Feldes. eesel ausprobieren – wenn das oben Gesagte wie der Rollout klingt, den Sie zu planen versucht haben.
Häufig gestellte Fragen
Was bedeutet es eigentlich, den Kundensupport zu automatisieren?
Den Kundensupport zu automatisieren bedeutet, Teile des Support-Workflows – Tagging, Weiterleitung, Wissensdatenbank-Abruf, Antwortentwürfe, autonome Lösungen, Eskalation – an Software zu übergeben, die bei jedem eingehenden Ticket ausgeführt wird. Es ist kein einzelner Schalter; es ist ein Stack von Aufgaben, von denen jede unabhängig automatisiert werden kann. Die richtige Mischung hängt vom Ticketvolumen, der Reife der Wissensdatenbank und dem Risiko ab, das das Team bei autonomen Antworten tragen möchte.
Was kostet es, den Kundensupport zu automatisieren?
Die Kosten pro Ticket sind die entscheidende Kennzahl. Menschlich bearbeitete Tickets kosten im Durchschnitt 8 bis 12 US-Dollar und bis zu 25 bis 35 US-Dollar für B2B-SaaS, während KI-bearbeitete Tickets zwischen 0,20 und 1,50 US-Dollar landen, je nachdem, ob der Agent nur Dokumente liest oder auch Kontodaten abruft (Gartner & Forrester via theStacc, 2026). Die Plattformpreise variieren stark – nutzungsbasierte Agenten wie eesel für 0,40 US-Dollar pro Ticket befinden sich an einem Ende, Pro-Seat-Unternehmensverträge am anderen. Das vollständige Bild findet sich in unserer Kostenanalyse.
Was ist eine realistische Deflektionsrate bei der Automatisierung des Kundensupports?
Der Branchenmedian liegt bei ~41 % Tier-1-Deflection, mit einem oberen Quartil von etwa 58,7 % (ClarityArc, 2026). Agentische Systeme mit Backend-Integrationen erreichen 70 bis 92 % bei Routineanliegen. Aber Deflection ist nicht dasselbe wie Lösung – Gartner stellte fest, dass nur etwa 14 % der abgelenkten Anfragen eine echte Self-Service-Lösung erreichen, eine Qualitätslücke von 31 Prozentpunkten. Optimieren Sie für Lösung, nicht für Deflection.
Wird KI menschliche Support-Mitarbeiter ersetzen?
Nein, und Teams, die es so formulieren, verlieren Kunden. Klarnas KI-Assistent übernimmt das Äquivalent von 700 Vollzeitmitarbeitern, aber Menschen behalten die schwierigen Fälle. Die Daten zeigen auch, dass durch KI verstärkte Mitarbeiter 13,8 % mehr Anfragen pro Stunde bearbeiten. Das richtige Modell ist KI für das Volumen, Menschen für das Urteilsvermögen – nicht das eine oder das andere.
Wo soll ich anfangen, wenn meine Wissensdatenbank ein Chaos ist?
Fangen Sie dort an. Pylons Analyse ergab, dass gut strukturierte Dokumentation die echte Lösungsrate um 15 bis 25 % steigert, und ClarityArc formuliert es direkt: „Ein Ticket-Deflection-Agent ist ein Wissensabrufsystem mit einer konversationellen Oberfläche." Prüfen Sie Ihre 10 häufigsten Ticket-Anliegen, schreiben oder überarbeiten Sie die Dokumentation, die sie beantwortet, und schalten Sie den Agenten erst dann ein. Ein KI-Wissensdatenbank-Chatbot, der auf einer dünnen Wissensdatenbank aufbaut, wird halluzinieren; bei einer gründlichen berichtet EBI.ai von 96 % Erfolg bei themenrelevanten Anfragen.
Was ist der schnellste Weg, den Kundensupport auf Zendesk, Freshdesk oder Gorgias zu automatisieren?
Setzen Sie die Automatisierungsschicht auf Ihrem bestehenden Helpdesk auf, anstatt ihn auszutauschen. Die meisten Teams beginnen mit Antwortentwürfen im Agent-Posteingang (geringes Risiko, hohe Einsparungen), schalten dann automatisches Tagging und Weiterleitung ein und steigen dann auf autonome Lösungen für die zuversichtlichsten Anliegen um. Praktische Anleitungen je Plattform: Zendesk-Tickets automatisieren, Freshdesk automatisieren und das Gorgias-Playbook für E-Commerce-Teams.

Article by
Rama Adi Nugraha
Rama is a software engineer at eesel AI with two years of experience writing about B2B SaaS, AI tools, and customer support technology. Based in Bali, Indonesia, he brings a developer's perspective to product comparisons — cutting through marketing copy to what the integrations and APIs actually do.