Claude Opus 4.7 im Test: Der neue Standard für KI-Logik im Jahr 2026
Stevia Putri
Zuletzt bearbeitet April 21, 2026
Die Welt der KI entwickelt sich schnell, aber die Veröffentlichung von Claude Opus 4.7 am 16. April 2026 fühlt sich wie ein grundlegender Richtungswechsel an. Während die letzten zwei Jahre ein Wettlauf um Geschwindigkeit und geringere Latenz waren, schlägt das neueste Flaggschiff-Modell von Anthropic einen anderen Weg ein. Es wurde nicht unbedingt gebaut, um das schnellste zu sein – es wurde gebaut, um das gründlichste zu sein.
In diesem Testbericht gehen wir darauf ein, was Opus 4.7 zu einem „Logik-Sprung“ macht, warum es eine hitzige Debatte über Modell-Regression ausgelöst hat und wie Unternehmen es bereits nutzen, um komplexe, autonome Aufgaben zu bewältigen, die mit früheren Modellen schlicht nicht möglich waren.
Was ist neu in Opus 4.7?
Claude Opus 4.7 ist keine komplette architektonische Überarbeitung, sondern ein gezieltes Upgrade für „langfristige agentische Zuverlässigkeit“. Wenn es bei Opus 4.6 darum ging, schnell die richtige Antwort zu erhalten, geht es bei 4.7 darum, zu beweisen, dass die Antwort korrekt ist, noch bevor sie Ihnen mitgeteilt wird.

Exzellenz in der Softwareentwicklung
Die wichtigste Verbesserung liegt im Bereich Programmierung. Opus 4.7 erreichte beeindruckende 87,6 % im SWE-bench Verified, ein Anstieg von 80,8 % bei Opus 4.6. Noch beeindruckender ist die Leistung bei SWE-bench Pro (+10,9 Punkte), was darauf hindeutet, dass sich die Zuwächse auf die schwierigsten und einzigartigsten Software-Engineering-Probleme konzentrieren und nicht nur auf gängige Muster.
Selbstüberprüfung und Gründlichkeit
Das vielleicht „menschlichste“ Merkmal von 4.7 ist die Fähigkeit, die eigenen Ausgaben zu verifizieren. In der Praxis bedeutet das: Wenn Sie Opus 4.7 eine komplexe Aufgabe geben, führt es diese nicht einfach nur aus und berichtet darüber. Es schreibt proaktiv Tests, führt Plausibilitätsprüfungen durch und überprüft seine eigene Arbeit. Diese „Verify before Report“-Schleife reduziert die Fehlerraten bei lang laufenden agentischen Aufgaben erheblich.
Verbesserte Vision-Fähigkeiten
Opus 4.7 unterstützt jetzt Bilder mit bis zu 2.576 Pixeln an der langen Kante (ca. 3,75 Megapixel). Dies entspricht einer 3,3-fachen Steigerung der Auflösung gegenüber früheren Modellen. Für Unternehmen bedeutet dies, dass die KI nun dichte Screenshots, komplexe Architekturdiagramme und pixelgenaue UI-Elemente „lesen“ kann, die zuvor für eine zuverlässige Extraktion zu unscharf waren.
Das „denkende“ Modell: Leistungs-Benchmarks
Anthropic hat 4.7 als die KI für den denkenden Menschen positioniert. Sie sagt nicht nur das nächste Token voraus; sie „logisiert“ sich durch die Schritte. Dies spiegelt sich in der Benchmark-Leistung auf ganzer Linie wider.
| Benchmark | Claude Opus 4.7 | Claude Opus 4.6 | Delta |
|---|---|---|---|
| SWE-bench Verified | 87,6 % | 80,8 % | +6,8 |
| GPQA Diamond | 94,2 % | 91,3 % | +2,9 |
| MCP-Atlas (Tools) | 77,3 % | 62,7 % | +14,6 |
| Finance Agent (SOTA) | 64,4 % | 60,7 % | +3,7 |
Der Sprung bei MCP-Atlas (+14,6 Punkte) ist besonders bemerkenswert für alle, die autonome Agenten entwickeln. Er zeigt, dass 4.7 deutlich besser darin ist, Werkzeuge zu nutzen – wie das Durchsuchen einer Datenbank oder die Interaktion mit einer API –, ohne sich im Prozess zu verlieren.
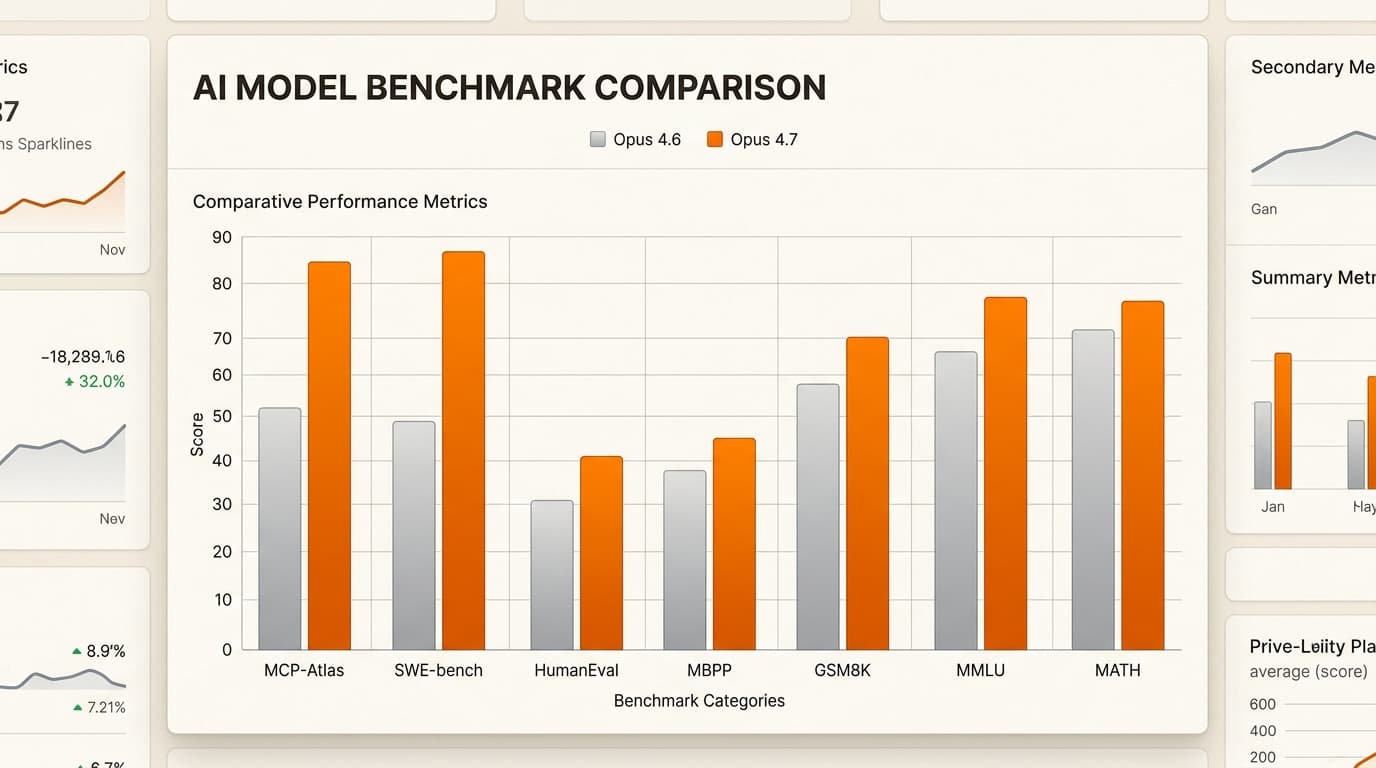
Die Kontroverse: Handelt es sich um eine Regression?
Trotz der glänzenden Benchmarks war die Veröffentlichung nicht frei von Kontroversen. Auf Plattformen wie Reddit hat ein lautstarker Teil der Nutzer Opus 4.7 als „Regression“ bezeichnet.
Die Hauptbeschwerde? Geschwindigkeit.
Da Opus 4.7 mehr „nachdenkt“ – insbesondere auf den neuen Anstrengungsstufen xhigh und max –, kann es sich deutlich langsamer anfühlen als 4.6. Einige Nutzer beschreiben es als „Überdenken“ einfacher Aufgaben. Es gibt auch die Wahrnehmung, dass das Modell bei nicht-technischen Texten etwas von seiner „kreativen Seele“ verloren hat und wörtlicher und trockener geworden ist.
Der Faktor Project Glasswing
Ein Teil dieser Verschiebung ist beabsichtigt. Opus 4.7 ist das erste breit veröffentlichte Modell, das den Project Glasswing-Schutzstapel enthält. Anthropic hat während des Trainings explizit damit experimentiert, offensive Cybersicherheitsfähigkeiten zu reduzieren. Diese Schutzmaßnahmen erkennen und blockieren automatisch Anfragen, die auf risikoreiche Cyber-Anwendungen hindeuten. Während dies das Modell für Unternehmen sicherer macht, fügt es eine Ebene der „Wörtlichkeit“ hinzu, die sich für Power-User wie eine Einschränkung anfühlen kann.
Praktische geschäftliche Anwendungsfälle
Für die meisten Unternehmen ist die „Regressions“-Debatte eine Ablenkung vom wahren Wert des Modells: seiner Zuverlässigkeit. Bei eesel AI sehen wir Opus 4.7 als die perfekte Engine für KI-Teamkollegen.
Komplexe Support-Workflows
Stellen Sie sich eine Kundensupport-Anfrage vor, die Folgendes erfordert:
- Überprüfung des Abonnementstatus eines Benutzers in Stripe.
- Abgleich mit einer Rückerstattungsrichtlinie in einem Confluence-Wiki.
- Aktualisierung eines Tickets in Zendesk.
- Senden einer Slack-Benachrichtigung an das Finanzteam.
Frühere Modelle könnten einen Schritt verpassen oder ein Detail halluzinieren. Die „Selbstüberprüfung“ von Opus 4.7 stellt sicher, dass jeder Schritt gegen den vorherigen geprüft wird. Es ist der Unterschied zwischen einem Bot, der rät, und einem KI-Teamkollegen, der weiß.
Dokumenten- und Foliengenerierung
Mit seiner verbesserten Vision und seinem kreativen Gespür ist 4.7 auch deutlich besser darin, hochwertige Interfaces, Folien und professionelle Dokumente zu erstellen. Es kann Ihre bestehenden Marken-Assets mit 3,3-facher Klarheit „sehen“ und sicherstellen, dass die generierten Inhalte perfekt Ihren Claude KI-Programmiertools und Designstandards folgen.
Erste Schritte & Preise
Die gute Nachricht ist, dass Claude Opus 4.7 ein direkter Ersatz in der API ist und der Preis unverändert bleibt:
- Eingabe: 5 $ pro 1 Million Token
- Ausgabe: 25 $ pro 1 Million Token
Es gibt jedoch einen Haken. Opus 4.7 verwendet einen aktualisierten Tokenizer. Derselbe Text kann auf 1,0–1,35x mehr Token abgebildet werden als in 4.6. Das bedeutet, dass zwar der Preis pro Token gleich ist, Ihre Kosten pro Aufgabe jedoch leicht steigen könnten.
Tipps für das Prompting von 4.7
- Seien Sie wörtlich: Da 4.7 Anweisungen präziser befolgt, vermeiden Sie „vage Schwingungen“. Seien Sie explizit bei dem, was Sie wollen.
- Nutzen Sie die xhigh-Stufe: Diese neue Anstrengungsstufe liegt zwischen „high“ und „max“ und bietet Ihnen das beste Gleichgewicht zwischen Logik und Latenz.
- Legen Sie Aufgabenbudgets fest: Nutzen Sie die neuen Beta-Aufgabenbudgets, um Ihre Token-Ausgaben bei lang laufenden autonomen Jobs zu begrenzen.
Das Urteil: Genauigkeit vor Geschwindigkeit
Claude Opus 4.7 ist ein spezialisiertes Werkzeug. Wenn Sie ein kurzes Gespräch darüber führen möchten, was es zum Abendessen geben soll, ist es wahrscheinlich übertrieben (und zu langsam). Aber wenn Sie autonome KI-Teamkollegen aufbauen, um kritische Geschäftsabläufe, Softwareentwicklung oder komplexe Datenextraktion zu bewältigen, ist es der neue Goldstandard.
Es wählt Genauigkeit vor Geschwindigkeit und Gründlichkeit vor „Schwingungen“. Für die Zukunft der autonomen Arbeit ist das genau der Kompromiss, den wir brauchen.
Häufig gestellte Fragen
Share this article

Article by
Stevia Putri
Stevia Putri is a marketing generalist at eesel AI, where she helps turn powerful AI tools into stories that resonate. She’s driven by curiosity, clarity, and the human side of technology.

