Claude Opus 4.7: The Rise of the Senior Engineer Model
Stevia Putri
Last edited April 20, 2026
The surprise release of Claude Opus 4.7 isn't just another benchmark bump. While we've grown accustomed to models getting slightly better at math or coding with every iteration, this update marks a distinct shift in how these systems behave. It's the move from a passive assistant that follows orders to a collaborator that thinks, plans, and occasionally pushes back.
Anthropic is positioning Claude Opus 4.7 as a model built for senior-level engineering work, and the early feedback from the developer community suggests they've hit the mark. It's less about the raw scores and more about the "epistemic discipline" the model displays, the ability to know what it doesn't know and verify its own work before presenting it to you.

Let's break down why this release matters for your workflow and how it changes the landscape for AI agents in 2026.
The behavioral shift: Why Claude Opus 4.7 feels like a senior engineer
The most interesting thing about the Claude Opus 4.7 launch wasn't the charts. It was the testimonials from companies like Replit, Hex, and Cognition. They describe a model being shaped toward a new persona: a senior engineer rather than a helpful assistant.
This shift manifests in three key behaviors:
- Planning and verification: Instead of jumping straight into code, the model plans its approach and catch its own logical faults before execution.
- Willingness to disagree: It brings a more opinionated perspective. If you propose a suboptimal architecture, Opus 4.7 is more likely to push back and suggest a better alternative rather than simply agreeing with you.
- Persistence through failure: In agentic loops, it keeps executing through tool failures that would have stopped previous models cold.
A CEO at Replit recently shared: "Personally, I love how it pushes back during technical discussions to help me make better decisions. It really feels like a better coworker."
At eesel AI, we see this as a pivotal moment for content and support automation. When you hire an AI teammate to handle complex research or drafting, you don't just want a fast writer, you want a teammate who understands the nuances of your brand and can self-correct their output.
High-resolution vision: 3x more detail for complex tasks
Vision has always been a bottleneck for AI agents tasked with navigating complex UIs or reading dense technical documents. Claude Opus 4.7 effectively removes that bottleneck with a massive jump in resolution support.
The model now supports images up to 2576 pixels on the long edge (~3.75 megapixels), which is more than three times the fidelity of prior Claude models. For developers building "computer use" agents, this is the difference between a blurry screenshot and a pixel-perfect map of the interface.
Here's how that vision jump plays out in practice:
- 1:1 pixel coordinates: The model's coordinates now map directly to actual pixels. This means no more scale-factor math or guessing where a button is on a high-res display.
- Technical diagram analysis: It can read chemical structures, architectural blueprints, and complex engineering diagrams with much higher accuracy.
- Data extraction: It can transcribe data from dense dashboards and figures that were previously unreadable.
A CTO at XBOW noted: "Our single biggest Opus pain point effectively disappeared, and that unlocks its use for a whole class of work where we couldn't use it before."
API power moves: xhigh effort and task budgets
For those building on the Claude Platform, Opus 4.7 introduces new controls that allow you to tune the tradeoff between intelligence and cost.
The new xhigh effort level
The effort parameter has been expanded with a new xhigh ("extra high") tier. It sits between high and max, providing a deeper reasoning capability that is now the default for Claude Code.
Start with the xhigh effort level for:
- Complex refactoring tasks
- Finding deep-seated bugs in large codebases
- Long-horizon agentic loops where quality is paramount
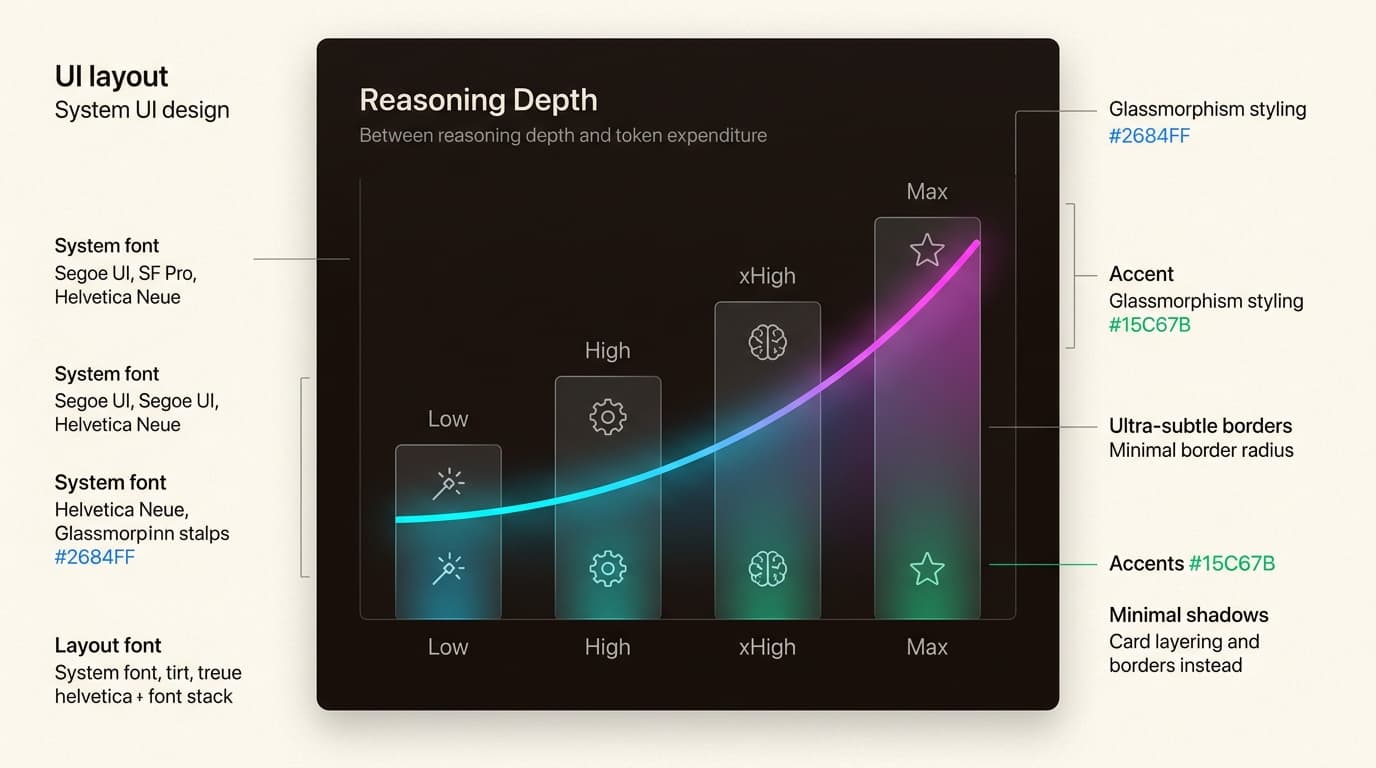
Task budgets (beta)
Anthropic is also introducing task budgets in public beta. This gives the model a target token allowance for a full agentic loop. Unlike max_tokens, which is a hard cap the model isn't aware of, Claude can see a running countdown of its task budget and use it to prioritize work.
If the budget is running low, the model will try to finish the task gracefully rather than cutting off mid-sentence. It’s a tool for scoping work to a specific token allowance, though you'll need to experiment with the minimum 20k token limit to find the sweet spot for your use case.
The pricing paradox: Same rates, new tokenizer
On paper, the pricing for Claude Opus 4.7 remains unchanged from Opus 4.6: $5 per million input tokens and $25 per million output tokens. However, there is a hidden variable you need to plan for: the updated tokenizer.
The new tokenizer improves how the model processes text, but it also means the same input can map to more tokens (roughly 1.0x to 1.35x more depending on your content type). This effectively results in a modest cost increase for the same volume of raw text.
To manage this, you should lean on:
- Prompt caching: Save up to 90% on input costs for repetitive context.
- Batch processing: Get 50% savings for tasks that aren't time-sensitive.
- Effort tuning: Use
highinstead ofxhighfor simpler tasks to keep token usage in check.
This is particularly relevant when comparing Claude with other models like GPT-4 and Gemini. While the per-token price might look identical, the "real-world" cost per task is now more dependent on how much the model "thinks" at higher effort levels.
Migration guide: Moving from Claude Opus 4.6 to 4.7
Upgrading to Claude Opus 4.7 is designed to be a direct upgrade, but you'll want to adjust your implementation to get the best results.
| Change | Recommendation |
|---|---|
| Headroom | Increase your max_tokens limit to account for the 1.0x-1.35x tokenizer shift. |
| Scaffolding | Remove prompts like "double-check your work" or "plan carefully." Opus 4.7 does this natively. |
| Effort | Switch to xhigh for your most difficult coding and agentic tasks. |
| Budgets | Implement task budgets for autonomous agents to prevent indefinite loops. |
If you're already using AI teammates to automate complex coding workflows, you'll likely see an immediate lift in reliability. The model passes through tool failures that previously required manual intervention, making the "teammate" experience feel much more seamless.
For security professionals, there is also the new Cyber Verification Program. It allows verified users to bypass the real-time cyber safeguards for legitimate research, such as penetration testing and vulnerability research.
Conclusion
Claude Opus 4.7 is a preview of where we’re heading: away from chatbots and toward autonomous teammates. By optimizing for sustained reasoning and "senior" behaviors like pushing back on bad ideas, Anthropic has built a model that can be trusted with more responsibility.
Whether you're building a dashboard, debugging a race condition, or automating your support queue, the shift in behavior matters far more than the benchmarks. It’s finally time to stop babysitting your agents and start collaborating with them.
Frequently Asked Questions
Share this article

Article by
Stevia Putri
Stevia Putri is a marketing generalist at eesel AI, where she helps turn powerful AI tools into stories that resonate. She’s driven by curiosity, clarity, and the human side of technology.