Resumo
A Together AI cobra de você de quatro maneiras diferentes, dependendo de qual produto você escolher: por milhão de tokens no serverless (US$ 0,03 a US$ 4,50 dependendo do modelo), por hora-GPU em endpoints dedicados (US$ 6,49/h para uma H100), por hora-GPU em clusters alugados (US$ 5,49/h H100 sob demanda até US$ 3,99/h reservado) e por milhão de tokens de dados de treinamento em fine-tuning, com uma conta de hospedagem separada por hora depois. Não há um plano gratuito anunciado, e a taxa por token raramente é o que faz a conta explodir - hospedagem de fine-tuning, endpoints dedicados, tentativas e tempo de engenharia fazem. Em um modelo legado como o Llama 3.3 70B, a Together está na média de preço (a Groq é mais barata, a Replicate é muito mais cara); em modelos mais novos, o provedor mais barato muda de semana para semana. Se você está passando seus fins de semana conectando inferência, recuperação, tentativas e uma interface para entregar uma IA para o cliente, a questão maior é se você deveria estar comprando tokens ou se uma plataforma por tarefa como a eesel simplesmente entregaria o resultado por US$ 0,40 por ticket.
Pelo que a Together AI realmente cobra você
A maioria dos posts sobre preços tenta encaixar a Together AI em uma história de níveis Build / Scale / Enterprise. A página de preços simplesmente não funciona assim. Não há níveis nomeados. Não há taxa por assento. Não há mínimo mensal no autoatendimento. O que existe são quatro medidores paralelos, cada um medindo uma unidade diferente de consumo, e qualquer carga de trabalho pode cair em um, dois ou nos quatro, dependendo de como você faz a implantação.
Os quatro pilares:
- Inferência serverless - você chama um endpoint
/v1/chat/completionscompatível com OpenAI, recebe uma resposta e paga por milhão de tokens de entrada e saída. A mesma superfície cobre chat, visão, imagem, áudio, vídeo, transcrição, embeddings e moderação, cada um com sua própria taxa por modelo (Together AI pricing). - Inferência dedicada - a Together provisiona uma instância de GPU de locatário único para você, você a mantém ativa 24/7 e paga por hora-GPU. O medidor dedicado ignora totalmente o volume de tokens; você está pagando por um assento reservado, não pelas viagens.
- Clusters de GPU - você aluga o hardware bruto da NVIDIA (de 8 a mais de 4.000 GPUs, conectadas por InfiniBand) sob demanda ou reservado por até seis meses. Isso é para equipes que treinam seus próprios modelos ou executam seus próprios mecanismos de inferência.
- Fine-tuning - o treinamento é cobrado por token de dados de treinamento, escalonado pelo tamanho do modelo e método (LoRA, Full FT, DPO). Em seguida, o modelo resultante vai para um endpoint dedicado, que tem seu próprio medidor por hora.
Isso importa porque escolher o medidor certo é onde vive a economia. Uma startup fazendo 5 milhões de tokens por dia no Llama 3.3 70B não tem o que fazer em um endpoint dedicado; uma carga de trabalho de produção em estado estacionário fazendo 500 milhões de tokens por dia no mesmo modelo geralmente tem. O CEO da Together AI, Vipul Ved Prakash, define a plataforma como a "AI Acceleration Cloud" situada entre os dois (LinkedIn), e a estrutura de preços reflete isso: serverless para começar, dedicado quando você pode prever a carga, clusters quando você está treinando.

Preços de inferência serverless
Serverless é a porta de entrada e é o medidor em que a maioria das equipes viverá. A tabela de modelos de chat em together.ai/pricing lista as taxas por milhão de tokens para cada modelo suportado, divididas em entrada, saída e (em alguns modelos) uma taxa de entrada em cache que é significativamente mais barata que a base.
Uma amostra representativa da aba de chat, extraída literalmente (Together AI pricing):
| Modelo | Entrada $/M | Saída $/M | Entrada em cache $/M |
|---|---|---|---|
| GLM-5.1 | $1,40 | $4,40 | - |
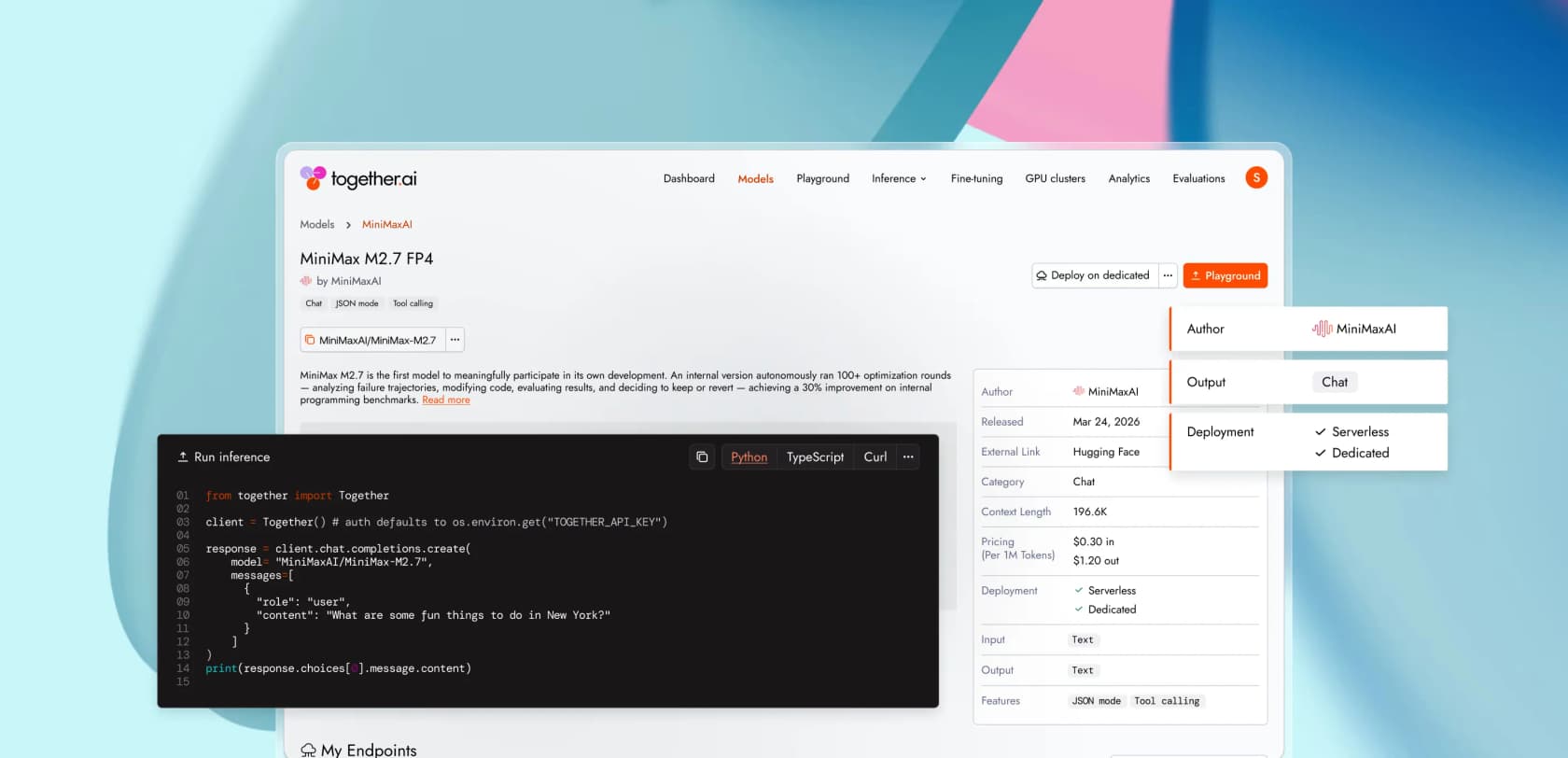
| MiniMax M2.7 | $0,30 | $1,20 | $0,06 |
| Kimi K2.6 | $1,20 | $4,50 | $0,20 |
| DeepSeek V4 Pro | $2,10 | $4,40 | $0,20 |
| DeepSeek V4 Flash | - (sem preço na página) | - | - |
| Qwen3.6-Plus | $0,50 | $3,00 | - |
| Qwen3.7-Max | $1,25 | $3,75 | $0,13 |
| gpt-oss-120B | $0,15 | $0,60 | - |
| gpt-oss-20B | $0,05 | $0,20 | - |
| Llama 3.3 70B | $1,04 | $1,04 | - |
| Qwen3 235B A22B FP8 Throughput | $0,20 | $0,60 | - |
| LFM2 24B A2B | $0,03 | $0,12 | - |
| Cogito v2.1 671B | $1,25 | $1,25 | - |
Três coisas que valem a pena destacar nessa tabela.
Primeiro, o preço de entrada em cache é a alavanca de que ninguém fala. O custo de entrada do DeepSeek V4 Pro cai de US$ 2,10/M para US$ 0,20/M quando o prefixo do prompt está em cache - um desconto de 10,5×. O Kimi K2.6 cai 6×. O MiniMax M2.7 cai 5×. Se sua carga de trabalho reutiliza um prompt de sistema longo ou tem contextos de usuário repetidos (a maioria dos loops de agentes, a maioria dos pipelines RAG), a taxa em cache é a taxa real. O número sem cache na tabela é o pior cenário.
Segundo, a onda de modelos em que você está importa mais do que o provedor. O gpt-oss-20B e o LFM2 24B existem na mesma página de preços que o DeepSeek V4 Pro e o GLM-5.1. A lacuna de 100× entre US$ 0,03/M (entrada LFM2) e US$ 4,50/M (saída Kimi K2.6) é muito maior do que a lacuna entre a Together e seus concorrentes para o mesmo modelo. "Together é barata" não é uma afirmação útil; "este modelo específico é barato na Together" geralmente é.
Terceiro, visão, imagem, áudio e vídeo possuem medidores separados por modelo - modelos de imagem cobram por megapixel ou por imagem (FLUX.2 [pro] custa US$ 0,03/imagem; Google Imagen 4.0 Ultra custa US$ 0,06/MP), modelos de vídeo cobram por vídeo finalizado (Sora 2 custa US$ 0,80; Google Veo 3.0 com áudio custa US$ 3,20) e áudio é dividido entre por minuto (Whisper Large v3 a US$ 0,0015) e por 1 milhão de caracteres (Cartesia Sonic-3 a US$ 65) (Together AI pricing). Se você está construindo um app multimodal, está tocando em vários medidores ao mesmo tempo e sua "fatura da Together" é a soma, não uma única taxa.
A porta de entrada serverless também inclui uma Batch API: processe até 30 bilhões de tokens por modelo de forma assíncrona com custo até 50% menor do que o serverless síncrono (Batch Inference API updates 2025). Para cargas de trabalho que não precisam de latência em tempo real - geração de dados sintéticos, classificação offline, enriquecimento de logs - o batch é o caminho legítimo mais barato na plataforma.
A Together promove o nível serverless pela velocidade tanto quanto pelo preço. Da página do produto de inferência, as comparações publicadas mostram "até 2,75x mais rápido" no Qwen3 235B 2507, "mais de 65% mais rápido" no Kimi K2 0905 e "2x mais rápido" no gpt-oss-20B em comparação com o próximo provedor mais rápido em cada benchmark. Mais tokens por segundo por GPU é, em última análise, o que permite à Together cobrar menos e ainda manter a margem - é o mesmo hardware, apenas fazendo mais trabalho por segundo.
Nossos pesquisadores e engenheiros estão comprometidos em acelerar a inferência de IA para ser tão rápida quanto as leis da física permitirem.
Ce Zhang, CTO, via Ryan Pollock no LinkedIn
Preços de inferência dedicada
Assim que sua carga de trabalho supera o serverless compartilhado - ou, mais frequentemente, assim que a latência imprevisível da infraestrutura compartilhada se torna um problema para o produto - os endpoints dedicados da Together AI permitem provisionar uma instância de GPU de locatário único e pagar por hora (Together AI pricing):
| Hardware | Preço por hora |
|---|---|
| 1× H100 80 GB | US$ 6,49 |
| 1× H200 140 GB | Entre em contato |
| 1× HGX B200 180 GB | US$ 11,95 |
A matemática é brutal em uma direção. Uma H100 deixada rodando 24 horas por dia, 30 dias por mês, custa US$ 4.672,80/mês por GPU. Uma B200 no mesmo período custa US$ 8.604. O volume de tokens é irrelevante - mesmo com zero solicitações, o medidor continua contando.
Também é brutal na outra direção, no bom sentido. Com um volume de solicitações alto o suficiente, o custo efetivo por token em um endpoint dedicado cai abaixo da taxa serverless. O ponto de equilíbrio depende do modelo, mas como regra geral para um modelo da classe 70B no serverless a US$ 1,04/M de tokens em ambos os sentidos, você começa a economizar no dedicado em algum ponto acima de ~5 bilhões de tokens/mês de tráfego constante e previsível. Abaixo disso, o serverless quase sempre vence no custo; acima disso, o dedicado vence e você também ganha latência consistente.
A equipe de pesquisa da Salesforce é um dos pontos de referência publicados para este nível:
Ficamos profundamente impressionados com a Together. Eles entregaram uma redução de 2x na latência e cortaram nossos custos em aproximadamente um terço.
Caiming Xiong, VP, Salesforce AI Research, página de inferência da Together AI
Se você está considerando o dedicado, a pergunta que você realmente precisa responder não é "a H100 de US$ 6,49/h da Together é mais barata que a X?" - é "eu tenho uma carga de trabalho estável o suficiente para que pagar por uma GPU o tempo todo seja mais barato do que pagar por tokens que ocorrem principalmente durante o horário comercial?" Para muitas equipes, a resposta honesta é não.
Preços de clusters de GPU - sob demanda vs reservados
Abaixo dos endpoints dedicados está o nível mais bruto da pilha: clusters de GPU alugados que você mesmo opera (gpu-clusters). É aqui que acabam as equipes que treinam seus próprios modelos, executam mecanismos de inferência personalizados ou escalam além do que os endpoints dedicados oferecem.
Preços de cluster sob demanda (autoatendimento, pague pelo que usar, encerre a qualquer momento, até 256 GPUs) (Together AI pricing):
| Hardware | Preço por GPU por hora |
|---|---|
| NVIDIA HGX H100 | US$ 5,49 |
| NVIDIA HGX H200 | US$ 6,79 |
| NVIDIA HGX B200 | US$ 9,95 |
Preços de cluster reservado diminuem com a duração, com um compromisso máximo publicado de 180 dias; qualquer coisa além disso encaminha para um formulário de solicitação de cluster de GPU para preços empresariais personalizados (Together AI pricing):
| Hardware | 7-30 dias | 31-90 dias | 91-180 dias | 181+ dias |
|---|---|---|---|---|
| NVIDIA HGX H100 | US$ 4,99 | US$ 4,49 | US$ 3,99 | Entre em contato |
| NVIDIA HGX H200 | US$ 5,95 | US$ 4,99 | US$ 4,55 | Entre em contato |
| NVIDIA HGX B200 | US$ 9,65 | US$ 9,35 | US$ 9,09 | Entre em contato |
| NVIDIA GB200 NVL72 | Entre em contato | Entre em contato | Entre em contato | Entre em contato |
| NVIDIA GB300 NVL72 | Entre em contato | Entre em contato | Entre em contato | Entre em contato |
Três coisas tornam o nível de cluster interessante em comparação com um aluguel de GPU de hiperescala.
Primeiro, desempenho bare-metal com interconexão InfiniBand em tudo. O argumento da Together é que "nossa interconexão InfiniBand mantém a sincronização de gradientes rápida e a sobrecarga de comunicação baixa - assim seus treinamentos terminam mais rápido, não apenas maiores" (Together AI gpu-clusters). Isso importa porque um treinamento 30% mais rápido no mesmo hardware é, na prática, um desconto de 30% na mesma taxa horária.
Segundo, a Together Kernel Collection vem com o cluster. A TKC (construída pelo Cientista-Chefe Tri Dao, criador do FlashAttention) é a mesma camada de otimização que alimenta a inferência serverless da Together e está disponível também em clusters. O benchmark publicado: "Treinar um modelo de arquitetura Llama de 70B parâmetros (BF16) com um TorchTitan otimizado + Together Kernel Collection (TKC) atingiu 15.264 tokens/segundo/GPU na NVIDIA HGX B200, acima dos 8.080 tokens/segundo na NVIDIA HGX H100 - um salto de 90% na velocidade de treinamento" (Together AI gpu-clusters).
Terceiro, o armazenamento não é um detalhe. Os clusters vêm com sistemas de arquivos paralelos Weka ou VAST anexados a US$ 0,16/GiB/mês com zero taxas de saída (Together AI pricing). Qualquer pessoa que já tenha desistido de um hiperescala por causa das taxas de saída do S3 reconhecerá por que isso importa.
A Together AI oferece o desempenho e a confiabilidade de que precisamos para geração de imagens e vídeos de alta qualidade em tempo real e em escala.
Victor Perez, Cofundador, Krea, Together AI gpu-clusters
Preços de fine-tuning - e o custo de hospedagem que ninguém te avisa
O fine-tuning na Together é cobrado por token de dados de treinamento, não por época e não por hora-GPU (Together AI fine-tuning docs). A matemática é explícita na página de preços: "O preço é baseado na soma dos tokens processados no conjunto de dados de treinamento do fine-tuning (tamanho do conjunto de dados de treinamento × número de épocas) mais quaisquer tokens no conjunto de dados de avaliação opcional (tamanho do conjunto de dados de validação × número de avaliações)" (Together AI pricing).
A tabela de preços padrão escala pelo tamanho do modelo base e pelo método de ajuste (Together AI pricing):
| Tamanho do modelo base | SFT - LoRA | SFT - Full | DPO - LoRA | DPO - Full |
|---|---|---|---|---|
| Até 16B | US$ 0,48 / M | US$ 0,54 / M | US$ 1,20 / M | US$ 1,35 / M |
| 17B–69B | US$ 1,50 / M | US$ 1,65 / M | US$ 3,75 / M | US$ 4,12 / M |
| 70B–100B | US$ 2,90 / M | US$ 3,20 / M | US$ 7,25 / M | US$ 8,00 / M |
Além de 100B parâmetros, a Together precifica o fine-tuning por modelo em um nível "especializado", muitas vezes com uma carga mínima por job (Together AI pricing):
| Modelo | SFT (LoRA) | DPO (LoRA) | Mínimo |
|---|---|---|---|
| Família DeepSeek-R1 / V3 / V3.1 | US$ 10,00 / M | US$ 25,00 / M | US$ 20,00 |
| GLM-4.6 / 4.7 | US$ 9,00 / M | US$ 22,50 / M | US$ 27,00 |
| GLM-5 / GLM-5.1 | US$ 40,00 / M | US$ 100,00 / M | US$ 60,00 |
| gpt-oss-120B | US$ 5,00 / M | US$ 12,50 / M | US$ 6,00 |
| Kimi K2 (Thinking / Instruct / Base) | US$ 15,00 / M | US$ 37,50 / M | US$ 60,00 |
| Llama 4 Maverick / Maverick Instruct | US$ 8,00 / M | US$ 20,00 / M | US$ 16,00 |
| Llama 4 Scout | US$ 3,00 / M | US$ 7,50 / M | US$ 6,00 |
| Qwen3-Coder-480B-A35B-Instruct | US$ 9,00 / M | US$ 22,50 / M | US$ 18,00 |
| Qwen3-235B-A22B / Instruct-2507 | US$ 6,00 / M | US$ 15,00 / M | Sem mín. |
| Qwen3.5-122B-A10B | US$ 6,00 / M | US$ 15,00 / M | US$ 10,00 |
| Qwen3.5-397B-A17B | US$ 8,00 / M | US$ 20,00 / M | US$ 22,00 |
A tabela acima é a que a maioria das pessoas cita. O número que elas esquecem é que, uma vez treinado o modelo, hospedá-lo é uma cobrança separada e contínua.
Dos docs: "Assim que o treinamento termina, a inferência roda em um endpoint dedicado" (Together AI docs). Esse endpoint dedicado é medido nas mesmas taxas do nível de inferência dedicada - US$ 6,49/h para uma H100 ou US$ 11,95/h para uma B200 (Together AI pricing). Um LoRA em uma base de 16B pode ser treinado por menos de um dólar por milhão de tokens de treinamento, mas manter o modelo resultante ativo em uma única H100 o tempo todo custa aproximadamente US$ 4.700/mês por GPU, independentemente de ele atender a uma solicitação naquele mês.
Esta é a maior armadilha de preços da plataforma. Equipes calculam rotineiramente que "o fine-tuning nos custará US$ 30 para a execução" - o que está correto - e então descobrem que a fatura de hospedagem é duas ordens de grandeza maior. Planeje o ciclo de vida, não apenas a etapa de treinamento.
Alguns outros detalhes sobre o fine-tuning que são fáceis de perder:
- Nenhum nível gratuito anunciado. Cada execução de treinamento cobra por token desde o primeiro token.
- LoRA é o padrão, o fine-tuning completo é opcional. As diferenças na página de preços entre LoRA e Full são pequenas (cerca de US$ 0,30/M no nível 70B), então a escolha geralmente é sobre qualidade, não custo.
- DPO custa cerca de 2,5× o SFT em todos os níveis de tamanho. Se você está alinhando um modelo às preferências, planeje o orçamento de acordo.
- BYOM (bring your own model) permite que você carregue uma base fora do catálogo. O preço para o treinamento BYOM se enquadra em qualquer categoria de tamanho padrão em que o modelo se encaixe; a hospedagem tem as mesmas taxas dedicadas.
Sandbox, interpretador de código e armazenamento gerenciado
Dois medidores menores valem a pena notar porque pegam muitos construtores de agentes de surpresa.
O Code Sandbox permite criar sandboxes isoladas de VM para agentes de IA executarem código. É precificado por vCPU virtual e por GiB de memória, por hora (Together AI pricing):
| Recurso | Preço por hora |
|---|---|
| Por vCPU | US$ 0,0446 |
| Por GiB RAM | US$ 0,0149 |
Uma sandbox modesta de 4 vCPUs e 8 GiB mantida ativa por um dia de trabalho (8 horas) custa cerca de US$ 2,39 - um valor pequeno individualmente, mas para uma frota de agentes que está criando dezenas delas em paralelo, os totais podem se acumular rapidamente.
O Code Interpreter é o primo mais leve: uma sandbox de sessão única para executar código gerado por LLM sem sobrecarga de pool ativo, custando US$ 0,03 por sessão de 60 minutos (Together AI pricing). Esse é o padrão sensato para a maioria dos fluxos de uso de ferramentas de agentes.
Armazenamento Gerenciado é o sistema de arquivos paralelo que fica ao lado dos clusters. Custa US$ 0,16 por GiB por mês com zero taxas de saída (Together AI pricing). Um conjunto de trabalho de 10 TB custa cerca de US$ 1.638/mês - comparável a um sistema de arquivos de alto desempenho de hiperescala, mas sem a conta de largura de banda na saída.
O que é, e o que não é, gratuito
Esta parte é curta, porque não há muito.
- Nenhum nível gratuito anunciado na página de preços pública. A página não apresenta um valor de crédito de inscrição, um período de teste gratuito ou uma permissão mensal de tarefas gratuitas.
- A Batch API é o único mecanismo de desconto em linha: até 50% de desconto na maioria dos modelos de chat para cargas de trabalho assíncronas (Batch Inference API updates 2025).
- Descontos por volume / uso comprometido existem, mas não são publicados - a página direciona você para Entre em contato para preços empresariais.
- Entrada em cache é o mais próximo de um almoço grátis: desconto de 5-10× nos tokens de entrada para modelos de chat selecionados quando os prefixos são reutilizados.
Profissionais mencionaram historicamente um crédito inicial:
Um crédito grátis de US$ 25 vai longe quando até os modelos mais caros custam US$ 0,9/milhão de tokens.
Chris Samiullah, engenheiro de ML, LinkedIn
Esse número não está publicado atualmente na página de preços como uma política fixa. Se você está planejando um orçamento, trate o crédito como "pergunte ao seu gerente de conta" em vez de "garantido".
Como o preço da Together AI se compara ao da Fireworks, Groq, Replicate e o resto
A resposta honesta é que se a Together é a mais barata depende inteiramente do modelo que você está executando, da taxa de transferência de que precisa e se você está no serverless ou dedicado. Aqui está uma comparação lado a lado para os modelos compartilhados mais comuns, com taxas extraídas da página de preços ao vivo de cada provedor em 05/06/2026:
| Provedor | Llama 3.3 70B entr / saíd $/M | DeepSeek R1 entr / saíd $/M | Mixtral 8x22B entr / saíd $/M | Créditos grátis | Modelo de preço |
|---|---|---|---|---|---|
| Together AI | $1,04 / $1,04 | DeepSeek V4 Pro: $2,10 / $4,40 (cache $0,20 entr) | Fora da linha atual | Nenhum anunciado; Batch 50% desc | Serverless por token, dedicado por hora-GPU |
| Fireworks AI | $0,90 / $0,90 (balde >16B) | DeepSeek V4 Pro: $1,74 / $3,48 | $1,20 / $1,20 (MoE 56-176B) | US$ 1 de crédito grátis | Serverless por token, sob demanda por segundo-GPU |
| Groq | $0,59 / $0,79 | Fora da linha | Fora da linha | Inscrição no console gratuita | Serverless por token |
| Replicate | Por segundo de hardware | $3,75 / $10,00 | Por segundo de hardware | Nenhum anunciado | Por segundo de hardware + por token para selecionados |
| Anyscale | Implantação própria em H100 a $9,29/h | Igual | Igual | US$ 100 de crédito | Por hora-GPU (Anyscale Compute Units) |
| Modal | Autodeploy em H100 equiv. ~$3,95/h | Igual | Igual | $30/mês Starter, $100/mês Team | Computação por segundo |
| Hugging Face | Provedores de Inferência pass-through | Pass-through | Pass-through | PRO $9/mês + ZeroGPU grátis | Endpoints por hora + tokens pass-through |
| OpenRouter | $0,10 / $0,32 | $0,50 / $2,15 (R1 0528) | $2,00 / $6,00 | Variantes gratuitas com limite | Marketplace por token |
Alguns padrões surgem dessa tabela.
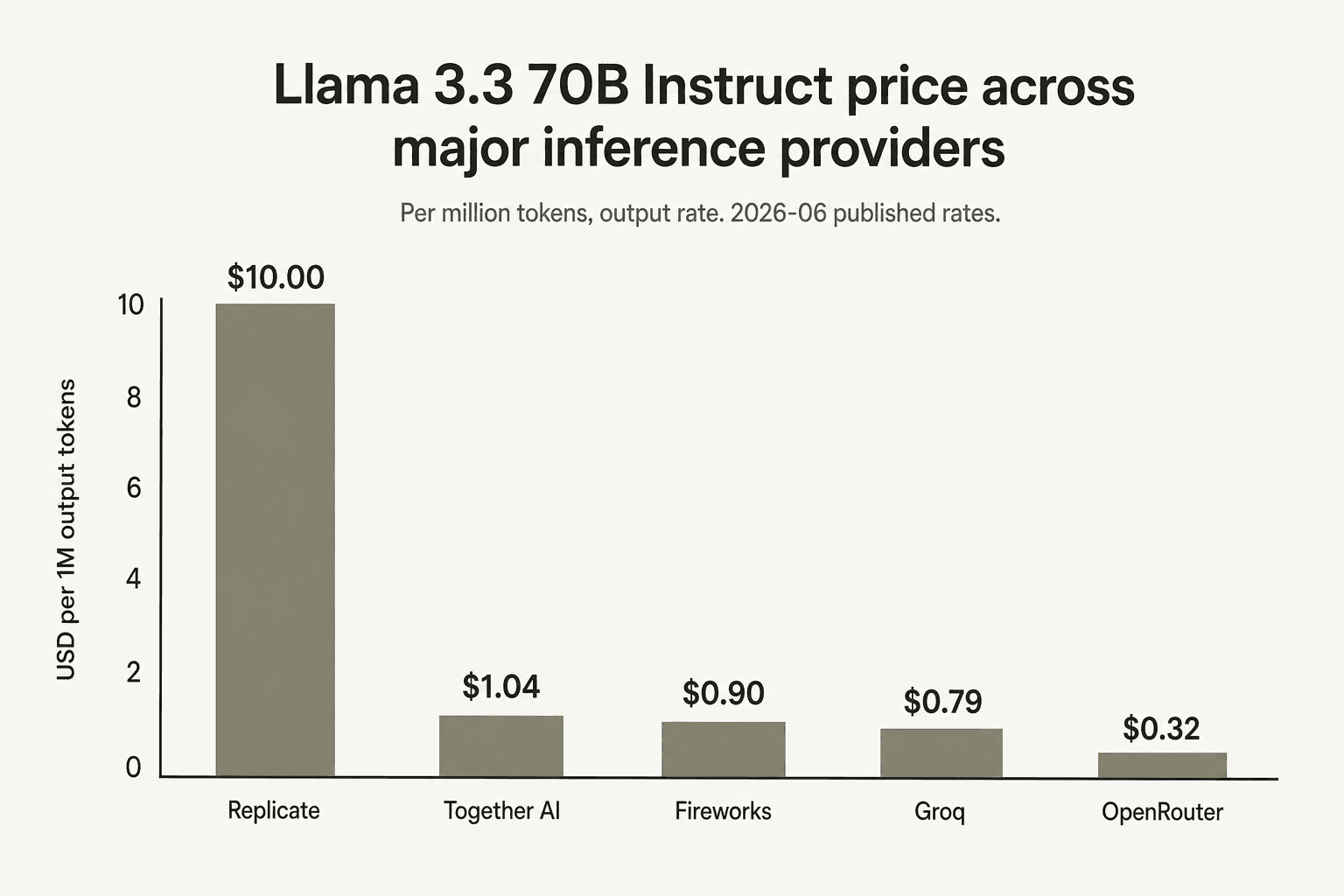
No Llama 3.3 70B especificamente, a Together AI está no meio termo. A Groq é o provedor primário mais barato no popular modelo legado (US$ 0,59/US$ 0,79), a Fireworks vem em seguida (US$ 0,90 fixo), a Together em terceiro (US$ 1,04/US$ 1,04), a Replicate nem o lista por token e a OpenRouter - que é um marketplace que roteia para o provedor subjacente mais barato - supera todos a US$ 0,10/US$ 0,32. Se sua carga de trabalho é "muita inferência de Llama 3.3 70B", a Groq e o marketplace da OpenRouter merecem uma olhada séria.
Nos modelos de nova geração - Kimi K2.6, GLM-5.1, DeepSeek V4, Qwen3.6-Plus - a Together é competitiva, mas nem sempre a mais barata. A Fireworks tende a listar seus novos Kimi e DeepSeek individualmente com taxas de entrada em cache que igualam ou superam as da Together. A diferença geralmente fica entre 10-30%, não a lacuna de 5-10× que às vezes se vê em textos de marketing.
Para hospedagem de GPU dedicada, o cenário é mais amplo. A Modal supera quase todos na computação por segundo (H100 ≈ equiv. a US$ 3,95/h a US$ 0,001097/seg). A Hugging Face Endpoints publica US$ 4,50/h para uma H100. A Together está em US$ 6,49/h para inferência dedicada, US$ 5,49/h para um cluster sob demanda e US$ 3,99/h para um cluster reservado de 91-180 dias. Produtos diferentes, contas diferentes - e seu custo real depende se você pode absorver a complexidade operacional de executar sua própria implantação de vLLM na Modal versus deixar a Together hospedar um modelo por você.
Para embeddings, a Together está entre as mais baratas a US$ 0,02/M de tokens (Multilingual e5 large instruct) (Together AI pricing). A conta corporativa da Together anunciou historicamente "custo até 4x menor que a OpenAI" em embeddings (@togethercompute no X), e as taxas atuais estão nessa faixa.
Para cargas de trabalho em lote (batch), o desconto de 50% da Batch API da Together é o principal atrativo. A Fireworks iguala o desconto de 50%; a Groq também. Replicate, Modal e Anyscale não têm um nível de desconto assíncrono comparável.
Para análises mais profundas por provedor, nossos detalhamentos de preços da Fireworks AI, preços da Baseten e preços da SambaNova Cloud estão ao lado deste. A versão curta: escolha o provedor mais barato para o modelo específico que você está entregando, não o provedor mais barato em abstrato.
Três exemplos práticos do que as equipes realmente pagam
Matemática de tokens é barata; a fatura no final do mês é o que importa. Aqui estão três cenários com os números reais.
Exemplo 1 - Uma equipe de SaaS rodando um assistente de chat no produto com Llama 3.3 70B
Tráfego: 5.000 conversas/dia, média de 1.500 tokens de entrada (prompt do sistema + contexto recuperado) e 400 tokens de saída por conversa. Cerca de 21 dias úteis por mês.
Cálculo serverless na Together a US$ 1,04/M entrada + US$ 1,04/M saída:
- Entrada: 5.000 × 1.500 × 21 = 157,5M tokens × US$ 1,04 = US$ 163,80/mês
- Saída: 5.000 × 400 × 21 = 42M tokens × US$ 1,04 = US$ 43,68/mês
- Total: ~US$ 207/mês na linha de inferência
Se a mesma equipe escolher a Groq a US$ 0,59 entrada / US$ 0,79 saída:
- 157,5M × US$ 0,59 + 42M × US$ 0,79 = US$ 92,92 + US$ 33,18 = ~US$ 126/mês
Se eles usarem OpenRouter a US$ 0,10 entrada / US$ 0,32 saída:
- 157,5M × US$ 0,10 + 42M × US$ 0,32 = US$ 15,75 + US$ 13,44 = ~US$ 29/mês
Conclusão: neste volume, o custo puro de inferência é pequeno o suficiente para que a escolha provavelmente se resuma à latência, confiabilidade regional, resposta do suporte - não à taxa de inferência.
Exemplo 2 - Uma startup focada em IA rodando um loop de agente Kimi K2.6 em escala
Tráfego: 200M tokens de entrada/dia, 50M tokens de saída/dia, com cerca de 80% da entrada passível de cache (prompt de sistema longo + definições de ferramentas reutilizadas). 30 dias por mês.
Cálculo Together com preços em cache incluídos:
- Entrada (em cache): 200M × 0,80 × 30 × US$ 0,20/M = US$ 960/mês
- Entrada (sem cache): 200M × 0,20 × 30 × US$ 1,20/M = US$ 1.440/mês
- Saída: 50M × 30 × US$ 4,50/M = US$ 6.750/mês
- Total: ~US$ 9.150/mês
Sem o desconto de entrada em cache, a parte de entrada sozinha seria de US$ 7.200, então a alavanca de cache vale aproximadamente US$ 5.800/mês neste cenário. A maioria das equipes subestima o tamanho do desconto de entrada em cache, porque a maioria das comparações de preços cita a taxa sem cache.
Exemplo 3 - Uma equipe fazendo fine-tuning do Llama 4 Scout e hospedando-o 24/7
Treinamento: 500M tokens de dados de treinamento no Llama 4 Scout. No nível especializado, isso custa US$ 3,00/M LoRA SFT com um mínimo de US$ 6.
- Custo de treinamento: 500 × US$ 3,00 = US$ 1.500 (único)
Hospedagem: 1× endpoint dedicado H100 mantido ativo para produção.
- US$ 6,49/h × 24 h × 30 dias = US$ 4.672,80/mês, todo mês
Fatura total do primeiro mês: US$ 1.500 + US$ 4.672,80 ≈ US$ 6.173. Estado estacionário a partir do segundo mês em diante: US$ 4.673.
O custo do treinamento parece ser o destaque. O custo de hospedagem é a fatura recorrente real. Se você puder hospedar o modelo ajustado em capacidade dedicada existente, ou se seu tráfego justificar o serverless no modelo base + engenharia de prompt direcionada em vez de um fine-tuning completo, você pode eliminar totalmente a linha de US$ 4.673. Planeje o ciclo de vida.

Onde os preços da Together pegaram equipes desprevenidas
O fio condutor mais consistente nas avaliações negativas no G2 e Trustpilot não é sobre as taxas principais - é sobre a mecânica de cobrança. Três reclamações específicas aparecem repetidamente.
Cobranças de autorização não reembolsadas. Vários revisores no Trustpilot descrevem a adição de um cartão de crédito, o recebimento de uma cobrança de autorização de US$ 1 que deveria ser estornada e, em seguida, o não recebimento do dólar de volta:
Quando você adiciona um cartão de crédito, dizia explicitamente: "Haverá uma cobrança imediata de US$ 1 para autorização, que será creditada de volta". Adicionei meu cartão, fui cobrado em US$ 1, mas nunca recebi de volta.
Revisor do Trustpilot, Together AI no Trustpilot
Cobranças em intervalos rápidos e acompanhamento fraco de reembolsos. Outro tópico sobre padrão de cobrança:
Eles estavam cobrando o cartão de crédito em intervalos de segundos com valores estranhos - tive que bloquear o cartão em emergência. Suporte inacessível.
Revisor do Trustpilot, Together AI no Trustpilot
Após 2 semanas, eles ainda não reembolsaram o saldo restante na minha conta pré-paga, nem reembolsaram o valor para a resolução de problemas da chave de API desativada.
Revisor do G2, Together AI no G2
Essas não são experiências típicas do cliente médio - a maioria dos revisores do G2 é positiva - mas são consistentes o suficiente para que o grupo negativo seja inequivocamente sobre cobrança e resposta do suporte, não lacunas de recursos. Se você é uma equipe pequena sem um gerente de conta, configure um cartão corporativo separado com um limite rígido e não carregue grandes saldos de crédito antecipadamente.
Surpresa na hospedagem do fine-tune. Já cobrimos isso, mas vale a pena repetir: o custo de manter um modelo ajustado vivo é frequentemente de 50× a 200× o custo de treiná-lo para qualquer volume mensal razoável. Isso pega muitas equipes. O medidor de endpoint dedicado não para quando o modelo está ocioso.
Tempo de engenharia é o maior custo invisível. Extraído de uma crítica recorrente de profissionais que surgiu em tópicos do LinkedIn e X sobre os preços da Together AI:
Usar a Together AI não é exatamente uma experiência plug-and-play. Exige uma boa quantidade de tempo do desenvolvedor para integrar sua API, construir um aplicativo em torno dela e, em seguida, manter esse sistema ao longo do tempo. Esses custos de engenharia podem se acumular rápido e muitas vezes acabam sendo muito mais altos do que o uso da API em si.
Crítica recorrente de profissionais surgida via discussões no LinkedIn / X sobre os preços da Together AI
Isso não é um ataque à Together especificamente; aplica-se a todas as plataformas de inferência de API bruta. Se o tempo da sua equipe de engenharia não é de graça, a planilha que compara o Llama 3.3 70B de US$ 1,04/M da Together com o Llama 3.3 70B de US$ 0,59/M da Groq também deve incluir as semanas de engenharia necessárias para lidar com autenticação, retry/backoff, observabilidade, validação de saída estruturada, versionamento de prompt, pipelines de avaliação e escala de sobreaviso. Para muitas equipes, esses itens de engenharia anulam completamente o item de inferência.
Quando a Together AI é a escolha certa - e quando não é
Onde os preços da Together brilham ativamente:
- Você está executando modelos de código aberto ajustados com tráfego de produção estável e previsível. Endpoints dedicados a US$ 6,49/h ou clusters reservados a US$ 3,99/h por H100 são competitivos com aluguéis de GPU de hiperescala e uma fração do preço de APIs proprietárias de fronteira em bandas de qualidade equivalentes.
- Você precisa de clusters de GPU com InfiniBand sem montar seu próprio data center. A faixa de 8 a mais de 4.000 GPUs da Together e a presença em mais de 25 cidades, além da vantagem de desempenho da Together Kernel Collection, são genuinamente competitivas com qualquer coisa fora dos maiores hiperescalas (gpu-clusters).
- Você está construindo experiências multimodais e quer uma única API. O nível serverless cobre chat, visão, imagem, áudio, vídeo, transcrição, embeddings e moderação, para que você não precise costurar seis contas de provedores diferentes.
- Você está executando grandes cargas de trabalho assíncronas / batch. O desconto de 50% na Batch API sobre taxas serverless já competitivas é difícil de superar para sumarização offline, geração de dados sintéticos, enriquecimento de logs e classificação em escala.
Onde o preço da Together é a ferramenta errada:
- Você só precisa do endpoint Llama 3.3 70B mais barato que o dinheiro pode comprar. A Groq é mais rápida e mais barata nesse modelo específico. A OpenRouter é ainda mais barata. A Together está na média em modelos legados.
- Você é uma equipe pequena que quer um agente de IA gerenciado para uma superfície específica - tickets de suporte, chat de vendas, ajuda interna - e não quer montar inferência + recuperação + uso de ferramentas + UI + avaliação por conta própria. É aqui que uma plataforma por resultado faz mais sentido; mais sobre isso a seguir.
- Você quer preços previsíveis e limitados. O pagamento pelo que usar em vários medidores é difícil de prever com antecedência. Sem um limite de gastos, um loop de agente descontrolado pode custar dinheiro real antes que alguém perceba.
- Você precisa de um SLA publicado sobre o tempo de resposta do suporte primário. Várias avaliações negativas sinalizam a capacidade de resposta do suporte em relação a disputas de cobrança, o que é algo a ser negociado antecipadamente em um contrato empresarial.
Para análises de alternativas mais profundas, veja nosso resumo de alternativas à Together AI, a avaliação da Together AI e o guia mais amplo sobre o que é a Together AI.
Experimente a eesel quando preferir comprar resultados do que tokens
Um post sobre preços na Together AI é quase sempre um post sobre preços nas matérias-primas de um produto de IA - tokens, horas-GPU, latência de inferência, tokens de treinamento de fine-tuning. Esses são os primitivos certos se você estiver construindo uma empresa de modelos de base ou um mecanismo de inferência personalizado. Eles são os primitivos errados se o que você realmente quer é um agente de IA funcionando dentro de suas ferramentas existentes.

A eesel toma a forma oposta: preços por tarefa para um colega de equipe de IA totalmente gerenciado que roda dentro dos helpdesks, aplicativos de chat e caixas de entrada que você já usa (Zendesk, Freshdesk, integração com Intercom, Slack, Gmail, Shopify e mais de 100 outros). Um ticket de suporte custa US$ 0,40. Uma pergunta no dashboard é gratuita. Uma geração de blog de formato longo custa US$ 4. Inferência, recuperação, iteração de prompt, tentativas, avaliação e observabilidade estão todas dentro desse número - você não as vê na fatura e não precisa construí-las você mesmo.
Contrate colegas de equipe de IA. Colegas totalmente autônomos e incrivelmente capazes, vivendo em seus aplicativos existentes e prontos para começar em minutos.
Uma comparação prática para a equipe de SaaS do Exemplo 1 acima - 5.000 conversas/dia, assistente de chat no produto. Na Together, a linha de inferência é de aproximadamente US$ 207/mês mais o tempo de engenharia para montar recuperação, lógica de tentativa, validação de saída, versionamento de prompt e análises. Na eesel, essas mesmas 5.000 conversas × 21 dias = 105.000 tarefas/mês a US$ 0,40 cada = US$ 42.000/mês para o mesmo resultado - muito mais caro no papel, mas inclui um produto funcional de ponta a ponta e um SLA em resoluções. A resposta certa depende se o tempo da sua equipe é melhor gasto construindo infraestrutura ou construindo produto.
Para a maioria das equipes onde o suporte de IA, o chat de IA ou o conteúdo de IA é o resultado em vez da tecnologia central, o modelo por tarefa vence. O teste gratuito de US$ 50 de crédito da eesel permite que você experimente uma carga de trabalho real - um agente de helpdesk, um redator de blog, um agente de e-commerce - sem necessidade de cartão, e o desconto de compromisso anual é de 25% se você ultrapassar US$ 300/mês de gastos. Sem taxa por assento, sem taxa de plataforma no autoatendimento, sem mínimo mensal.
Se você já está na Together AI e está satisfeito com o que ela oferece, você deve continuar lá. Se você está na Together AI porque não conseguiu encontrar uma alternativa de nível superior - essa é exatamente a lacuna para a qual a eesel foi construída.
Perguntas Frequentes
Quanto custa usar a Together AI em 2026?
A Together AI tem um plano gratuito ou crédito inicial?
Como funciona o preço de fine-tuning da Together AI?
A Together AI é mais barata que Fireworks AI, Groq ou Replicate?
Quais custos ocultos devo observar na Together AI?

Article by
Rama Adi Nugraha
Rama is a software engineer at eesel AI with two years of experience writing about B2B SaaS, AI tools, and customer support technology. Based in Bali, Indonesia, he brings a developer's perspective to product comparisons — cutting through marketing copy to what the integrations and APIs actually do.