Cómo manejar las interrupciones de Zendesk SaaS: Una guía completa para 2026
Stevia Putri
Última edición March 3, 2026
Cuando su mesa de ayuda se cae, cada minuto cuenta. Si su equipo depende de Zendesk para gestionar las conversaciones con los clientes, una interrupción no solo pausa sus operaciones de soporte. Crea una cascada de clientes frustrados, agentes inactivos y una posible pérdida de ingresos.
Esta es la realidad: Zendesk presta servicio a más de 100.000 empresas, desde Uber hasta Khan Academy. Cuando su infraestructura tiene problemas, millones de interacciones con los clientes penden de un hilo. Y aunque la fiabilidad de Zendesk es generalmente sólida (han construido una plataforma robusta), las interrupciones ocurren. La pregunta no es si se enfrentará a una, sino si está preparado cuando ocurra.
Esta guía cubre todo lo que necesita saber sobre cómo manejar las interrupciones de Zendesk SaaS. Veremos cómo funciona su infraestructura, cómo monitorizar los problemas antes de que afecten a sus clientes y cómo crear un manual de respuesta que mantenga sus operaciones de soporte en funcionamiento incluso cuando su herramienta principal esté inactiva.
Comprender la infraestructura de Zendesk y los patrones de interrupción
Zendesk se ejecuta en una arquitectura "pod" distribuida. Piense en los pods como clústeres de centros de datos separados que gestionan diferentes grupos de cuentas de clientes. Cuando se registra en Zendesk, su cuenta se asigna a un pod específico (como Pod 18, Pod 25 o Pod 29).
Esta arquitectura tiene implicaciones en la forma en que se desarrollan las interrupciones:
- Los problemas específicos del pod afectan solo a los clientes de ese pod en particular. Es posible que no pueda acceder a los tickets mientras que su competidor en un pod diferente no tiene ningún problema.
- Los problemas globales afectan a todos los pods simultáneamente. Estos son menos comunes pero más graves.
- Las interrupciones específicas del servicio podrían dejar fuera de servicio solo el Web Widget o el Agent Workspace mientras que el resto de la plataforma permanece en línea.
Si observamos los datos de incidentes recientes de las notificaciones de servicio de Zendesk, surgen varios patrones. En los últimos meses, los problemas más comunes han sido los errores 5XX relacionados con la CDN (Content Delivery Network - Red de Entrega de Contenido) (que afectan a varios servicios), los problemas del compositor del Agent Workspace (donde la interfaz se establece por defecto en notas internas en lugar de respuestas públicas) y los problemas de funcionalidad del Web Widget.
Los tiempos de resolución varían significativamente. Los incidentes menores suelen resolverse en 1-3 horas. Los problemas moderados pueden tardar entre 4 y 12 horas. Las interrupciones prolongadas son raras, pero pueden durar varios días (como el problema del panel de control de uso de la API de diciembre de 2025 que persistió durante casi dos semanas).
¿La conclusión clave? No asuma que una interrupción que le afecta es global. Compruebe el estado de su pod específicamente. Y no asuma que una interrupción global significa que todas las funciones de Zendesk están inhabilitadas. La plataforma es lo suficientemente modular como para que las interrupciones parciales sean comunes.
Cómo monitorizar el estado de Zendesk de forma proactiva
Confiar únicamente en Zendesk para que le diga cuándo Zendesk está inactivo crea un conflicto de intereses. Necesita fuentes de verificación independientes.
Comience con la página de estado oficial de Zendesk. Suscríbase a las alertas por correo electrónico o SMS para su pod específico. La página de estado desglosa el estado por producto (Support, Chat, Voice, etc.) e incluye los horarios de mantenimiento para que pueda planificar en torno al tiempo de inactividad planificado.
Pero aquí está la trampa: las páginas de estado oficiales a veces se retrasan con respecto a los problemas reportados por los usuarios. Las empresas tienden a verificar los problemas antes de publicarlos, lo que crea un retraso. Ahí es donde las herramientas de monitorización de terceros se vuelven valiosas.
Downdetector agrega informes de usuarios de crowdsourcing. Cuando los usuarios no pueden acceder a Zendesk, lo informan aquí. Esto a menudo saca a la luz los problemas entre 15 y 30 minutos antes del reconocimiento oficial. El sitio categoriza los problemas por tipo (App, Login, Website) para que pueda ver rápidamente si otros están experimentando los mismos síntomas.
StatusGator adopta un enfoque diferente. Monitorizan la página de estado oficial de Zendesk junto con los informes de los usuarios y las comprobaciones automatizadas de la API. Su mapa de interrupciones muestra la distribución geográfica de los problemas. Según sus datos, Zendesk experimentó 79 incidentes en los últimos 12 meses, siendo Support el componente más afectado.
Para los equipos técnicos, considere la posibilidad de monitorizar directamente los puntos finales de la API de Zendesk. Una simple comprobación HTTP cada pocos minutos puede alertarle de problemas de conectividad antes de que lleguen a sus agentes. Herramientas como Uptime.com proporcionan esta monitorización automatizada con datos históricos del tiempo de respuesta.
¿La mejor práctica? Utilice múltiples fuentes. Suscríbase a la página de estado oficial para obtener actualizaciones autorizadas, consulte Downdetector para obtener señales de alerta temprana y utilice StatusGator para el análisis de tendencias y la evaluación del impacto geográfico.
Construyendo su manual de respuesta a interrupciones de Zendesk
Cuando Zendesk se cae, el caos sigue a menos que tenga un plan. Aquí tiene un marco para construir ese plan.
Verificación inmediata (primeros 5 minutos)
No asuma lo peor. Compruebe varias fuentes para confirmar si se trata de una interrupción generalizada o de un problema local:
- Compruebe la página de estado de Zendesk para su pod
- Compruebe Downdetector para ver los informes de los usuarios
- Intente acceder a Zendesk desde una red diferente (punto de acceso móvil) para descartar su ISP (Internet Service Provider - Proveedor de Servicios de Internet)
- Pida a un colega en una ubicación diferente que pruebe el acceso
Si es solo usted, solucione los problemas localmente. Si es generalizado, active su respuesta a la interrupción.
Comunicación interna (minutos 5-15)
Alerta a su equipo a través de su plataforma de chat interna (Slack, Microsoft Teams, etc.). Designe un único "coordinador de interrupciones" que sea el propietario de la comunicación. Esto evita mensajes contradictorios y garantiza actualizaciones consistentes.
Su alerta interna debe incluir:
- Confirmación de que Zendesk está experimentando una interrupción
- Impacto esperado (no se pueden crear tickets, no se puede acceder a datos históricos, etc.)
- Flujos de trabajo alternativos que se están activando
- Cronograma para la próxima actualización (incluso si esa actualización es "todavía estamos esperando")
Comunicación con el cliente (minutos 15-30)
El silencio frustra a los clientes más que las malas noticias. La comunicación proactiva demuestra que está al tanto de la situación.
Publique un aviso en su:
- Página de estado (si tiene una)
- Banner del sitio web
- Canales de redes sociales
- Respuesta automática de correo electrónico (si es apropiado)
El mensaje debe ser honesto pero tranquilizador: "Estamos experimentando dificultades técnicas con nuestra plataforma de soporte. Nuestro equipo está monitorizando la situación y trabajando en formas alternativas de ayudarle. Para asuntos urgentes, por favor [método de contacto alternativo]".
Procedimientos de escalamiento
Defina los umbrales para cuándo escalar:
- 15 minutos: Activar flujos de trabajo alternativos
- 1 hora: Notificar a los equipos de liderazgo y de éxito del cliente
- 4 horas: Considere la posibilidad de ofrecer créditos de servicio o gestos de buena voluntad a los clientes afectados
- Más de 8 horas: Modo de respuesta a incidentes completo con sala de guerra dedicada
Documentación
Registre todo durante una interrupción. Anote las horas de inicio, los síntomas, las quejas de los clientes recibidas, las acciones tomadas y el tiempo de resolución. Estos datos se vuelven valiosos para los análisis post-mortem y para construir el caso de negocio para las inversiones en redundancia.
Mantener la atención al cliente durante las interrupciones de Zendesk
Cuando su mesa de ayuda principal está inactiva, necesita alternativas. La clave es tener estas alternativas preconfiguradas y probadas antes de necesitarlas.
Canales de comunicación alternativos
- Correo electrónico: Mantenga una dirección de correo electrónico de respaldo (soporte@empresa.com) que no pase por Zendesk. Los agentes pueden monitorizar esto directamente en Gmail u Outlook durante las interrupciones.
- Teléfono: Si tiene soporte de voz, asegúrese de que pueda operar independientemente de Zendesk. Muchos sistemas telefónicos pueden enrutar las llamadas a las líneas directas de los agentes cuando falla la integración de la mesa de ayuda.
- Redes sociales: Twitter/X y Facebook pueden servir como canales de soporte temporales. Los clientes a menudo los revisan primero cuando no pueden comunicarse con usted a través de los canales normales.
- Widgets de chat en otras plataformas: Si utiliza el chatbot de IA de eesel AI, puede seguir funcionando en su sitio web incluso cuando Zendesk está inactivo, capturando las consultas para su posterior seguimiento.
Opciones de autoservicio
Una base de conocimientos bien mantenida puede desviar una parte importante de las consultas incluso cuando su sistema de tickets está inactivo. Asegúrese de que los artículos de su centro de ayuda sigan siendo accesibles durante las interrupciones. Considere la posibilidad de crear una página sencilla de "Preguntas frecuentes sobre la interrupción de Zendesk" que explique la situación y proporcione métodos de contacto alternativos.
Respaldo impulsado por IA
Las herramientas modernas de soporte de IA pueden proporcionar continuidad durante las interrupciones. Un agente de IA entrenado en su base de conocimientos puede responder a las preguntas más comunes incluso cuando su sistema de tickets principal no está disponible. Nuestro Agente de IA se integra con múltiples plataformas simultáneamente, por lo que si Zendesk se cae, puede seguir operando a través de canales alternativos.
La clave es configurar estas copias de seguridad antes de necesitarlas. Una interrupción es el momento equivocado para configurar nuevas herramientas.
Calcular el verdadero coste del tiempo de inactividad de las herramientas de soporte
Las interrupciones no son solo un inconveniente. Son caras. Comprender el coste ayuda a justificar las inversiones en redundancia.
Aquí tiene un marco sencillo para calcular el impacto de la interrupción:
Costes directos:
- Tiempo de inactividad del agente: (Número de agentes afectados) × (Coste por hora) × (Duración de la interrupción)
- Pérdida de resolución de tickets: (Promedio de tickets por hora) × (Horas de interrupción) × (Valor promedio del ticket)
- Horas extras para el trabajo de recuperación: (Tickets atrasados) × (Tiempo para resolver) × (Tasa de horas extras)
Costes indirectos:
- Sanciones del SLA (Service Level Agreement - Acuerdo de Nivel de Servicio): Compruebe sus contratos para ver las cláusulas de incumplimiento
- Abandono de clientes: (Clientes afectados) × (Probabilidad de abandono) × (Valor de vida del cliente)
- Daño a la reputación: Más difícil de cuantificar pero real, especialmente si las interrupciones se vuelven frecuentes
Ejemplo de cálculo para un equipo de tamaño medio:
- 50 agentes a 40 $/hora = 2.000 $/hora de coste laboral
- Interrupción de 4 horas = 8.000 $ de coste laboral directo
- Capacidad perdida: 200 tickets a 25 $ de valor = 5.000 $
- Impacto total inmediato: 13.000 $
Eso no incluye las horas extras para limpiar el atraso, las posibles sanciones del SLA o el daño a la satisfacción del cliente. Una sola interrupción importante puede costar fácilmente entre 20.000 y 50.000 dólares si se tienen en cuenta todos los factores.
Estas matemáticas cambian la forma en que piensa acerca de los sistemas de respaldo. Gastar 500 $/mes en redundancia parece barato cuando una interrupción de 4 horas cuesta más de 13.000 $.
Construyendo una pila de soporte resistente con eesel AI
Aquí está la incómoda verdad: confiar en una sola plataforma SaaS para las operaciones comerciales críticas crea puntos únicos de fallo. Cuando esa plataforma tiene una interrupción, está a su merced.
¿La solución? Un enfoque multiplataforma que no ponga todos los huevos en la misma cesta.
En eesel AI, hemos construido nuestra plataforma teniendo en cuenta la resistencia. Nuestro Agente de IA no solo vive en una mesa de ayuda. Se integra con Zendesk, Freshdesk, Intercom, Gorgias y más de 100 herramientas simultáneamente. Esto significa:
- Si Zendesk se cae, su agente de IA puede seguir operando a través de canales alternativos
- Puede ejecutar la IA en múltiples plataformas en paralelo, creando redundancia
- Los datos de los clientes y el historial de conversaciones no quedan atrapados en el ecosistema de un solo proveedor

Nuestro enfoque es diferente de las herramientas tradicionales de IA. En lugar de configurar flujos de trabajo complejos, contrata a eesel AI como a un nuevo miembro del equipo. Aprende su negocio a partir de sus datos existentes (tickets pasados, artículos del centro de ayuda, macros) y comienza con la supervisión antes de subir de nivel a la operación autónoma.
Así es como los equipos construyen la resistencia con eesel AI:
Comience con AI Copilot durante las operaciones normales. Redacta respuestas para que sus agentes las revisen, aprendiendo su tono y sus políticas. Esto sigue funcionando incluso durante las interrupciones parciales porque puede redactar respuestas que los agentes envían a través de canales alternativos.
Progrese a AI Agent para las consultas rutinarias. Cuando Zendesk está inactivo, la IA puede manejar las preguntas comunes a través del widget de chat de su sitio web, correo electrónico o Slack, dándole tiempo para resolver el problema de la plataforma principal.
Utilice AI Triage para mantener la higiene de los tickets automatizada. Incluso durante el servicio degradado, puede etiquetar, enrutar y priorizar los tickets para que su equipo no se enfrente a un desastre completo cuando se restaure el servicio completo.
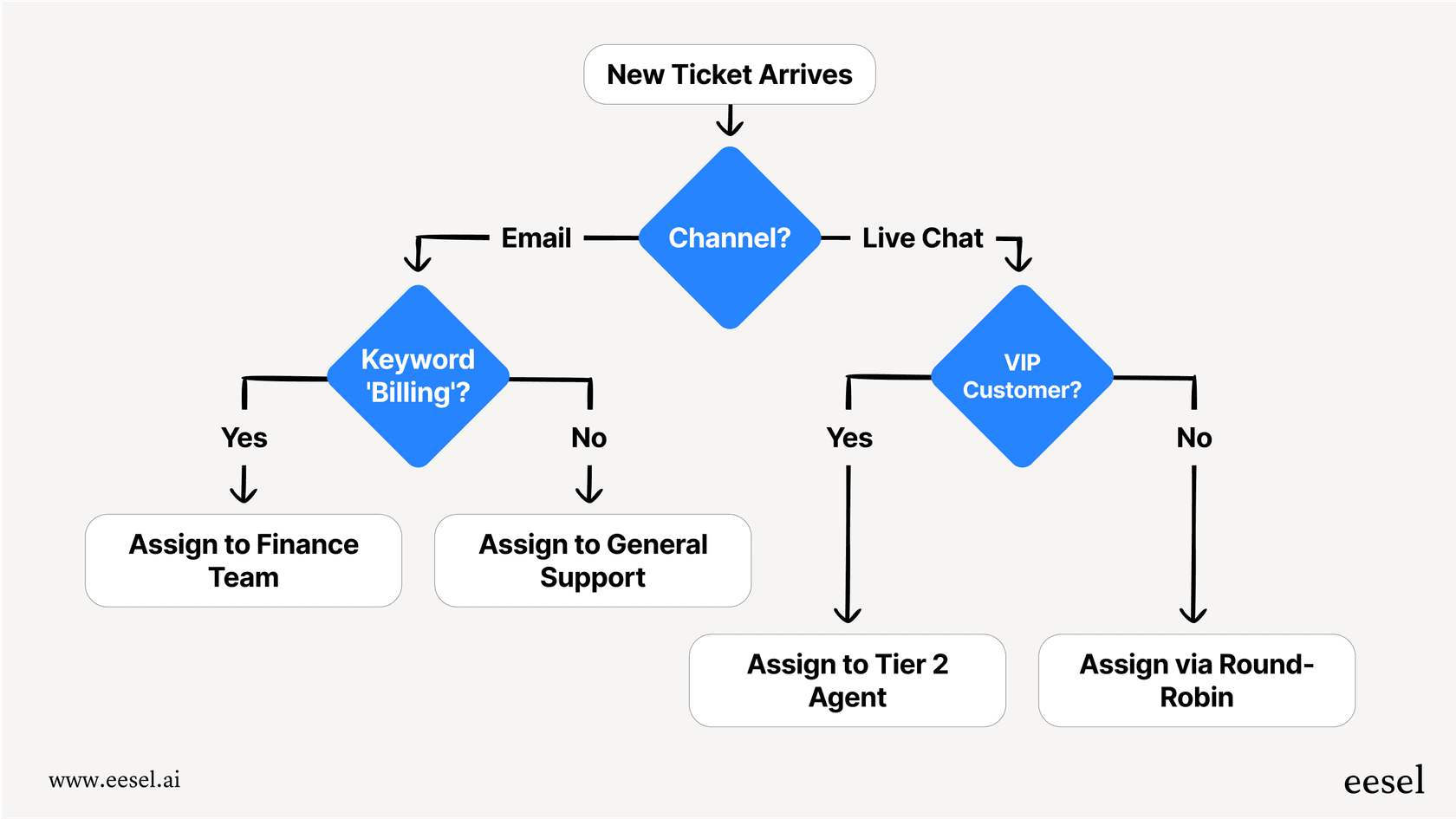
El período de recuperación de las herramientas de soporte de IA suele ser inferior a dos meses. Cuando se tiene en cuenta la resistencia a las interrupciones junto con las ganancias de eficiencia normales, la inversión se vuelve aún más convincente.
Si actualmente depende por completo de Zendesk para la atención al cliente, considere esto: ¿qué le sucede a su experiencia del cliente durante la próxima interrupción? Hablemos de cómo construir una operación de soporte más resistente.
Preguntas Frecuentes
Share this article

Article by
Stevia Putri
Stevia Putri is a marketing generalist at eesel AI, where she helps turn powerful AI tools into stories that resonate. She’s driven by curiosity, clarity, and the human side of technology.
