ServiceNow KI-Genauigkeit: Was die Zahlen im Jahr 2026 wirklich bedeuten
Stevia Putri
Zuletzt bearbeitet March 15, 2026
Wenn Sie KI für Ihr IT-Service-Management evaluieren, ist die Genauigkeit nicht nur eine nette Metrik. Es ist der Unterschied zwischen einer KI, die Ihren Ticket-Backlog tatsächlich reduziert, und einer, die durch schlechte Empfehlungen und frustrierte Benutzer mehr Arbeit verursacht.
ServiceNow hat stark in KI-Funktionen investiert, von Now Assist über KI-Agenten bis hin zu Predictive Intelligence (vorausschauende Intelligenz). Aber welche Art von Genauigkeit können Sie realistisch erwarten? Und welche Faktoren bestimmen, ob Sie das obere Ende ihrer Benchmarks erreichen oder mit Modellen mit schlechter Leistung zu kämpfen haben?
Hier ist eine Aufschlüsselung dessen, was die Zahlen wirklich bedeuten, wie ServiceNow die KI-Leistung misst und was Sie wissen müssen, bevor Sie eine Investitionsentscheidung treffen.
Was ist ServiceNow KI und warum ist Genauigkeit wichtig
ServiceNow KI ist kein einzelnes Produkt. Es ist eine Sammlung von Funktionen, die in die Now Platform integriert sind, jede mit unterschiedlichen Genauigkeitsprofilen und Anwendungsfällen.
Im Kern steht Now Assist, die generative KI-Schicht, die bei allem hilft, von der Zusammenfassung von Tickets bis zur Erstellung von Wissensartikeln. Dann gibt es KI-Agenten, die autonom handeln können, um Probleme ohne menschliches Zutun zu lösen. Predictive Intelligence verwendet maschinelles Lernen, um Tickets automatisch zu klassifizieren und weiterzuleiten. Und Virtual Agent wickelt Self-Service-Gespräche per Chat ab.
Die Herausforderung besteht darin, dass die Genauigkeit zwischen diesen Funktionen erheblich variiert. Ein Tool, das hilfreiche Zusammenfassungen generiert, kann Schwierigkeiten haben, Tickets autonom zu lösen. Das Verständnis dieser Unterschiede ist wichtig, da die Kosten für ungenaue KI im ITSM hoch sind. Ein falsch weitergeleitetes Ticket verzögert die Lösung. Eine halluzinierte Antwort schadet dem Vertrauen der Benutzer. Eine falsche Klassifizierung sendet dringende Probleme an das falsche Team.
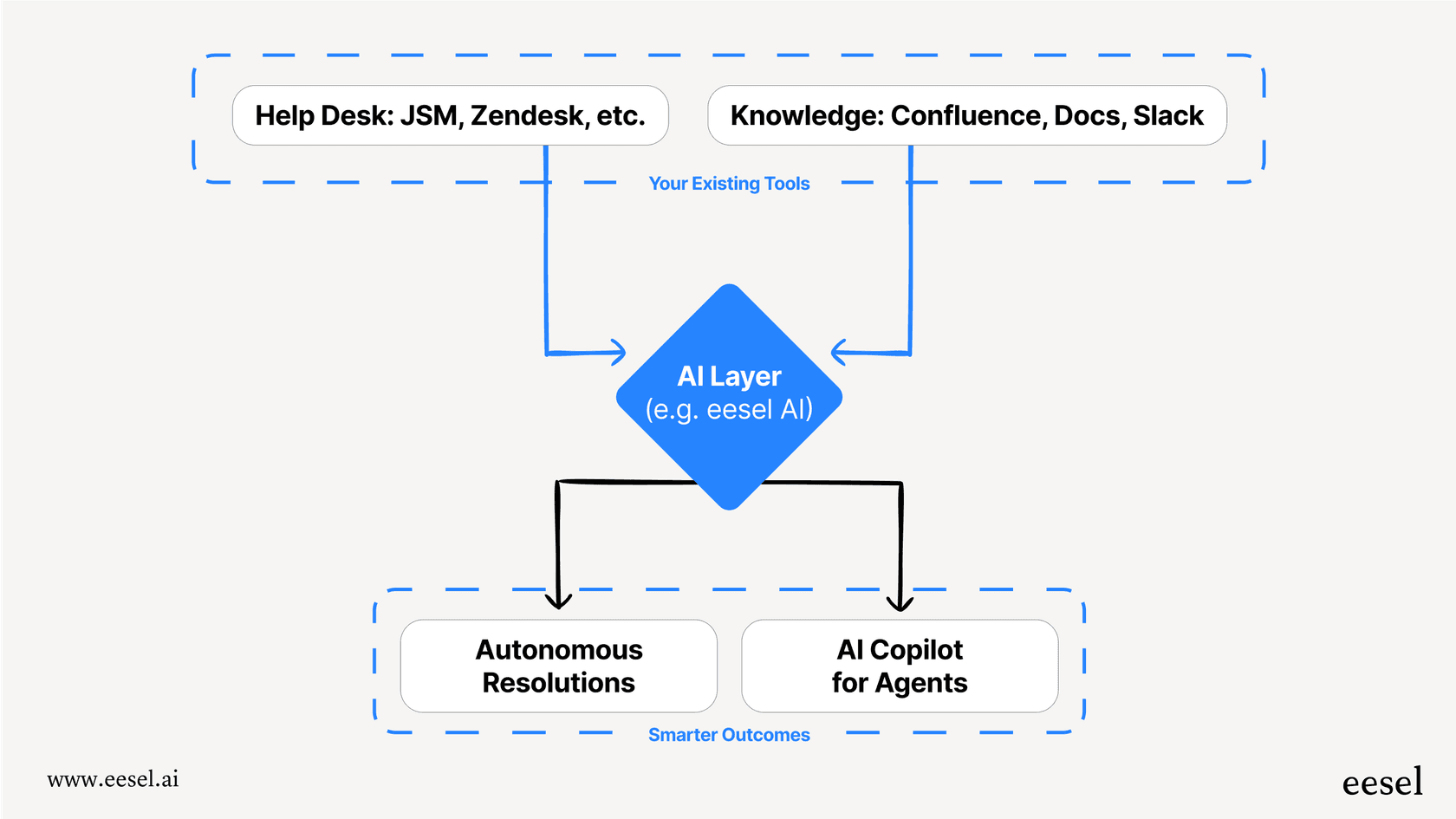
Für Teams, die KI ohne die Komplexität einer vollständigen ServiceNow-Bereitstellung implementieren möchten, bieten wir einen alternativen Ansatz. Unsere KI-für-ITSM-Lösung lernt aus Ihren bestehenden Tickets und Wissensdatenbanken, mit einem Simulationsmodus, mit dem Sie die Genauigkeit anhand vergangener Daten testen können, bevor Sie live gehen.
ServiceNow KI-Genauigkeits-Benchmarks
ServiceNow und seine Partner nennen mehrere Genauigkeitsmetriken. So sehen die Zahlen aus und was sie in der Praxis wirklich bedeuten.
Now Assist Genauigkeit
ServiceNow gibt für Now Assist eine Vorschlagsgenauigkeit von bis zu 85 % an, wenn es ordnungsgemäß mit hochwertigen Daten trainiert wurde. Dies gilt für Funktionen wie:
- Zusammenfassung von Fällen und Vorfällen
- Erstellung von Wissensartikeln
- Entwurf von Antworten für Agenten
- Code- und Flow-Generierung
Der Zusatz "bis zu" ist hier wichtig. Diese Zahl von 85 % steht für optimale Bedingungen mit sauberen, umfassenden historischen Daten. In der Praxis sehen viele Organisationen eine geringere Genauigkeit, insbesondere bei der ersten Bereitstellung.
Weitere gemeldete Metriken für Now Assist sind:
- 300-500 % Steigerung bei der Erstellung von Wissensdatenbankartikeln
- 35-50 % Verbesserung der Erledigungsraten beim ersten Anruf
- 40-55 % Reduzierung der mittleren Zeit bis zur Lösung (MTTR)
Diese Ergebnisse hängen stark von der Qualität Ihrer bestehenden Wissensdatenbank und davon ab, wie gut Ihre Agenten Lösungen dokumentieren.
Virtual Agent Leistung
Der Virtual Agent wickelt Self-Service-Gespräche ab, und ServiceNow gibt Ablenkungsraten von 45-60 % als erreichbar an. Das bedeutet, dass fast die Hälfte bis zwei Drittel der Interaktionen gelöst werden können, ohne einen menschlichen Agenten zu erreichen.
Laut dem KI-Wert-Framework von ServiceNow sparen erfolgreiche Virtual Agent-Gespräche im Vergleich zur herkömmlichen Fallbearbeitung etwa 11,32 Minuten pro Interaktion. Die Berechnung geht davon aus, dass ein Mitarbeiter etwa 15 Minuten für einen Fall mit geringer Komplexität aufwenden würde, während ein Virtual Agent ihn in weniger als 4 Minuten löst.
Einige Kunden berichten, dass sie diese Benchmarks übertreffen. CANCOM beispielsweise erreichte mit ServiceNow KI-Agenten eine Ticket-Ablenkungsrate von 80 % über alle Abteilungen hinweg. Griffith University verzeichnete eine Steigerung der gesamten Self-Service-Rate um 87 %.
Aber diese Ergebnisse sind nicht typisch. Sie erfordern erhebliche Investitionen in die Qualität der Wissensdatenbank, das Gesprächsdesign und die laufende Optimierung.
Predictive Intelligence Genauigkeit
Hier müssen die Erwartungen sorgfältig kalibriert werden. Ohne hochwertige Trainingsdaten kann die Genauigkeit von Predictive Intelligence so niedrig wie 20-30 % sein.
Diese Funktion übernimmt:
- Automatische Ticketklassifizierung
- Intelligente Weiterleitung und Zuweisung
- Erkennung ähnlicher Vorfälle
- Vorhergesagte Zeit bis zur Lösung
Das Problem "Müll rein, Müll raus" ist hier real. Wenn Ihre historischen Tickets eine inkonsistente Kategorisierung, spärliche Beschreibungen oder falsche Weiterleitungsentscheidungen aufweisen, lernt die KI diese Muster. Eine Organisation stellte fest, dass ihr Predictive Intelligence-Modell nur geringfügig besser war als zufälliges Raten, da ihre historischen Daten so unordentlich waren.
AI Search Effektivität
AI Search mit Now Assist zeigt konsistentere Ergebnisse. ServiceNow berichtet:
- 2,5 Minuten eingespart pro AI Search-Interaktion
- 4,5 Minuten eingespart bei Verwendung von Now Assist in der Suche (im Vergleich zu herkömmlichen Click-Through-Suchen)
Die Berechnung geht von einer maximalen Suchzeit von 5 Minuten aus, wobei Now Assist die Engagement-Zeit auf etwa 30 Sekunden reduziert. Diese Metriken sind leichter zu erreichen, da die Suche ein stärker eingeschränktes Problem ist als ein offenes Gespräch oder eine autonome Lösung.
Wie ServiceNow die KI-Genauigkeit misst
Das Verständnis der ServiceNow-Messmethodik hilft, ihre Benchmarks zu interpretieren und realistische Erwartungen für Ihre eigene Bereitstellung festzulegen.
Das KI-Wert-Framework
ServiceNow misst die KI-Auswirkungen durch das sogenannte KI-Wert-Framework. Es verfolgt Produktivitätssteigerungen über fünf Personas hinweg: Endbenutzer, menschliche Agenten, Prozessverantwortliche, Entwickler und Führungskräfte.
Das Framework konzentriert sich auf eingesparte Zeit, ausgedrückt in Gesamtstunden. Zum Beispiel:
- AI Search spart 2,5 Minuten pro erfolgreicher Suche
- Now Assist in AI Search spart 4,5 Minuten pro Interaktion
- Virtual Agent-Gespräche sparen 11,32 Minuten pro erfolgreicher Lösung
Diese Zeiteinsparungen werden mit dem Interaktionsvolumen multipliziert und anhand der Stundensätze der Mitarbeiter in Kosteneinsparungen umgerechnet.
Aus diesem Framework ergeben sich zwei wichtige zusammengesetzte Metriken:
Self-Service-Effizienz-Score: Der Prozentsatz der Anfragen, die KI bearbeitet, im Vergleich zu denen, die Live-Support erfordern. Ein Wert von 25 % bedeutet, dass KI ein Viertel der potenziellen Supportfälle automatisiert. Ausgereifte Bereitstellungen können 62 % oder mehr erreichen.
Agentenproduktivitäts-Score: Quantifiziert, wie viel Arbeit KI im Vergleich zu menschlichen Agenten erledigt. Wenn Agenten typischerweise 7,3 Arbeitsaktionen pro Stunde erledigen und KI 3 dieser Aktionen übernimmt, zeigt der Score, dass KI 42 % der Arbeitslast beiträgt.
Virtual Agent Bewertungsmetriken
Speziell für Virtual Agent verwendet ServiceNow neun Bewertungsmetriken (wie in ihrem AI Control Tower Bewertungsleitfaden dokumentiert):
| Metrik | Was sie misst |
|---|---|
| Anforderungsabschluss | Fähigkeit, Benutzeranforderungen genau zu erfüllen |
| Absichtsgenauigkeit | Verständnis von Benutzeranforderungen |
| Slot-Füllung | Extrahieren strukturierter Antworten aus Antworten |
| Reibungsloser Gesprächsfluss | Vorwärtsbewegen des Gesprächs ohne Wiederholung |
| Kontextbeibehaltung | Verwenden von Informationen, die während des Gesprächs bereitgestellt werden |
| Wahrheitsgehalt | Vermeiden von Halluzinationen und Fabrikationen |
| Prägnanz | Vermeiden von wortreichen oder generischen Antworten |
| Kohärenz | Logischer Fluss und Klarheit der Antworten |
| Benutzerzufriedenheit | Gewichteter Durchschnitt aller anderen Metriken |
Jede Metrik wird auf einer 3- oder 5-Punkte-Skala bewertet und dann auf 5 skaliert. ServiceNow berechnet obere und untere Abweichungen, indem es automatische Bewertungs-Scores mit menschlichen Urteilen vergleicht und die Scores im Laufe der Zeit an die menschlichen Erwartungen anpasst.
Kontinuierlicher Messansatz
ServiceNow betont, dass die KI-Wertbewertung kontinuierlich und nicht einmalig erfolgen muss. Sie verfolgen fünf Dimensionen für jeden Anwendungsfall:
- Akzeptanz: Monatlicher Prozentsatz aktiver Benutzer im Vergleich zur Gesamtzahl potenzieller Benutzer
- Nutzung: Auslöser und erfolgreiche Generierungen
- Stimmung: Anteil des positiven Feedbacks
- Genauigkeit: Metriken zur Ausgabequalität, die für jeden Anwendungsfall geeignet sind
- Eingesparte Stunden: Übersetzung der geschäftlichen Auswirkungen
Das Unternehmen verwendet eine Formel-1-Boxencrew-Analogie: So wie Rennteams jeden Boxenstopp überprüfen, um sich zu verbessern, müssen Organisationen KI-Interaktionen kontinuierlich überprüfen, um die Leistung zu optimieren.
Faktoren, die die ServiceNow KI-Genauigkeit beeinflussen
Die Lücke zwischen Benchmark-Behauptungen und realen Ergebnissen hängt von mehreren Schlüsselfaktoren ab.
Datenqualität und der "Done Gap"
KI ist nur so gut wie ihre Trainingsdaten. Die ServiceNow-Dokumentation betont diesen Punkt immer wieder, aber viele Organisationen unterschätzen die erforderliche Vorbereitung.
Der "Done Gap" bezieht sich auf spärliche Auflösungsdokumentation. Wenn Ihre gelösten Vorfälle Variationen von "Problem gelöst" oder "Behoben gemäß Benutzeranforderung" ohne detaillierte Schritte zur Fehlerbehebung, Ursachenanalyse oder Problemumgehungen enthalten, hat Ihre KI nur minimale Daten, aus denen sie lernen kann.
Diese Lücke beeinträchtigt alle KI-Funktionen:
- Now Assist hat Schwierigkeiten, umfassende Wissensartikel zu erstellen
- Die Ablenkungsraten von Virtual Agent liegen ohne durchsuchbare Inhalte unter 15 %
- Die Genauigkeit von Predictive Intelligence bleibt bei schlechten historischen Daten bei 20-30 %
- KI-Agenten können ohne dokumentierte Beweise für die Problemlösung keine autonomen Workflows entwickeln
Um diese Lücke zu schließen, muss die Dokumentation als automatisches Nebenprodukt der Problemlösung behandelt werden, nicht als separate Aufgabe, die damit konkurriert.
Implementierungskomplexität
ServiceNow KI ist keine Funktion, die Sie einfach aktivieren. Die Implementierung erfordert in der Regel:
- Dedizierte Administratoren mit Plattformexpertise
- Lange Konfigurationsprojekte
- Tiefes Wissen über die Funktionsweise von ServiceNow
Der ServiceNow AI Maturity Index zeigt, dass die Marktreife erheblich variiert. Nur 28 % der Befragten sind "sehr vertraut" mit agentischer KI, während 33 % sie aktiv pilotieren oder mit mindestens einem voll funktionsfähigen Anwendungsfall einsetzen.
Für kleinere Teams oder Organisationen ohne ServiceNow-Experten ist diese Komplexität eine erhebliche Hürde. Ein Reddit-Benutzer, ein neuer Solo-Administrator für ein Unternehmen mit über 5.000 Mitarbeitern, beschrieb die Erfahrung als "überwältigend".
Halluzinationsrisiken
Ein wesentliches Problem bei jeder generativen KI ist das Risiko von "Halluzinationen" (die KI erfindet Antworten mit völliger Sicherheit). ServiceNow begegnet diesem Problem mit seiner Wahrheitsgehaltsmetrik, die überprüft, ob Antworten im Gespräch verankert und nicht erfunden sind.
Wie ein Benutzer jedoch feststellte, "muss man es dann vollständig lesen, weil es halluziniert". Wenn Agenten jede KI-Ausgabe doppelt überprüfen müssen, sinken die Zeiteinsparungen schnell.
Eine von Perspectium zitierte Avanade-Studie zeigt einen deutlichen Vertrauensverlust in KI-generierte Ausgaben. Während immer mehr Unternehmen KI einsetzen, werden viele aufgrund von Bedenken hinsichtlich Genauigkeit und Konsistenz zunehmend vorsichtig, sich darauf zu verlassen.
Reale Genauigkeitserwartungen
Was sollten Sie also tatsächlich erwarten? Die Antwort hängt von Ihrem organisatorischen Kontext ab.
Best-Case-Szenarien
Organisationen, die die höchsten Genauigkeitsraten erzielen, weisen in der Regel die folgenden Merkmale auf:
- Große Unternehmen mit ausgereiften ServiceNow-Ökosystemen
- Hochwertige historische Daten mit umfassender Dokumentation
- Dedizierte KI-Teams und Governance-Strukturen
- Erhebliche Investitionen in die Pflege der Wissensdatenbank
- "Vorreiter" (die obersten 18,2 % in Bezug auf die KI-Reife), die Daten- und Betriebssilos verbinden
Die eigene Bereitstellung von ServiceNow zeigt, was mit vollem Engagement möglich ist. Ausgehend von einem einzigen Anwendungsfall (Vorfallszusammenfassung für IT-Agenten) haben sie auf über 50 Live-Implementierungen über mehrere Personas mit insgesamt über 500 KI-Anwendungsfällen erweitert.
Häufige Herausforderungen
Typischere Erfahrungen sind:
- Virtual Agent-Ablenkungsraten unter 15 % ohne angemessene Investitionen in die Wissensdatenbank
- Predictive Intelligence-Genauigkeit bei 20-30 % bei schlechter Datenqualität
- Integrationskomplexität, die externe Berater oder längere Zeitpläne erfordert
- Erosion des Benutzervertrauens nach dem Auftreten von KI-Halluzinationen oder falscher Weiterleitung
Der AI Maturity Index hebt hervor, dass 43 % der Organisationen die Einführung von agentischer KI im nächsten Jahr in Betracht ziehen, aber viele befinden sich noch in frühen Erkundungsphasen.
Wer die höchste Genauigkeit erzielt
Die in der ServiceNow-Forschung identifizierten "Vorreiter" (18,2 % der Befragten) haben ein gemeinsames Merkmal: 56 % haben erhebliche Fortschritte bei der Verbindung von Daten- und Betriebssilos erzielt, verglichen mit 41 % der anderen. Diese Datenkonnektivität ermöglicht es ihnen, benutzerdefinierte KI-Modelle zu übernehmen und Best-of-Breed-Lösungen zu integrieren, anstatt sich ausschließlich auf Standardfunktionen zu verlassen.
Diese Organisationen extrahieren häufig ServiceNow-Daten, um ihre eigenen Modelle für spezielle Anwendungsfälle wie prädiktives Vorfallsmanagement, Ursachenanalyse und intelligentes Ticket-Routing basierend auf historischen Mustern zu trainieren.
Verbesserung der ServiceNow KI-Genauigkeit
Wenn Sie sich für ServiceNow KI engagieren, können Ihnen verschiedene Strategien helfen, eine bessere Genauigkeit zu erzielen.
Datenaufbereitungsstrategien
- Bereinigen und organisieren Sie historische Tickets, bevor Sie Modelle trainieren
- Implementieren Sie Prozesse für eine umfassende Auflösungsdokumentation
- Investieren Sie in die Qualität und Vollständigkeit der Wissensdatenbank
- Richten Sie eine Data Governance ein, um die Qualität im Laufe der Zeit aufrechtzuerhalten
Best Practices für die Implementierung
- Beginnen Sie mit Pilotprojekten anstelle einer plattformweiten Bereitstellung
- Definieren Sie klare KPIs und Messrahmen vor dem Start
- Planen Sie eine kontinuierliche Überwachung und Anpassung ein
- Investieren Sie in Change Management, um die Akzeptanz zu fördern
Wann Alternativen in Betracht gezogen werden sollten
ServiceNow KI ist sinnvoll für große Organisationen, die bereits in das ServiceNow-Ökosystem investiert haben und über dedizierte Plattformexpertise verfügen. Aber es ist nicht die richtige Lösung für jedes Team.
Erwägen Sie Alternativen, wenn Sie:
- Keine fundierte ServiceNow-Expertise in Ihrem Team haben
- Eine schnellere Time-to-Value benötigen, als eine langwierige Implementierung zulässt
- Eine einfachere Bereitstellung wünschen, ohne die Genauigkeit zu beeinträchtigen
- Es vorziehen, die KI-Leistung anhand Ihrer tatsächlichen Daten zu testen, bevor Sie live gehen
Wir haben eesel KI für Teams entwickelt, die eine leistungsstarke ITSM-KI ohne die Komplexität wünschen. Wir verbinden uns mit Ihrem bestehenden Helpdesk, lernen aus Ihren vergangenen Tickets und Wissensdatenbanken und lassen Sie Simulationen mit historischen Daten durchführen, um genau zu sehen, wie die KI funktionieren wird, bevor sie jemals mit einem Kunden interagiert. Sie können mit bestimmten Tickettypen beginnen, KI-Entwürfe überprüfen, bevor sie gesendet werden, und den Umfang erweitern, sobald sich die KI bewährt hat.

Die richtige Wahl für Ihre ITSM-KI-Anforderungen treffen
Die ServiceNow KI-Genauigkeit variiert stark je nach Datenqualität, Implementierungsansatz und organisatorischer Bereitschaft. Die Benchmarks sind erreichbar, erfordern aber erhebliche Investitionen in Vorbereitung, Konfiguration und laufende Optimierung.
Bevor Sie sich für ServiceNow KI entscheiden, fragen Sie sich:
- Haben wir saubere, umfassende historische Daten?
- Haben wir dedizierte ServiceNow-Expertise für die Implementierung?
- Sind wir auf eine mehrmonatige Bereitstellung vorbereitet, bevor wir Ergebnisse sehen?
- Haben wir Governance-Strukturen, um die KI-Genauigkeit im Laufe der Zeit aufrechtzuerhalten?
Wenn die Antwort auf mehrere dieser Fragen "Nein" lautet, werden Sie wahrscheinlich bessere Ergebnisse mit einer Lösung erzielen, die für eine schnellere Bereitstellung und einen progressiven Rollout entwickelt wurde. Der Schlüssel liegt darin, das Tool an die Fähigkeiten und den Zeitplan Ihres Teams anzupassen, nicht nur an die Funktionsliste.
Möchten Sie sehen, wie KI bei Ihren tatsächlichen Tickets funktionieren könnte? Probieren Sie unseren Simulationsmodus aus und messen Sie die Genauigkeit anhand Ihrer historischen Daten, bevor Sie Zusagen machen.
Häufig gestellte Fragen
Share this article

Article by
Stevia Putri
Stevia Putri is a marketing generalist at eesel AI, where she helps turn powerful AI tools into stories that resonate. She’s driven by curiosity, clarity, and the human side of technology.