O mundo da IA se move em um ritmo vertiginoso. Você finalmente consegue atualizar sua equipe sobre um modelo e então surge algo como o Claude Opus 4.5, prometendo mudar o jogo tudo de novo.
É fácil se perder no alvoroço e nas pontuações de benchmark. O que essas atualizações realmente significam para o fluxo de trabalho diário da sua equipe? Isso é apenas mais um pequeno passo à frente ou é um salto genuíno que pode mudar a forma como você trabalha?
Esta análise do Claude Opus 4.5 examina suas habilidades de codificação (coding), capacidades de agentes autônomos, limitações e nova estrutura de preços, explorando suas implicações para os negócios, particularmente no suporte ao cliente.
O que é o Claude Opus 4.5?
O que exatamente é o Claude Opus 4.5? É o mais novo grande modelo de linguagem (LLM) de nível superior da Anthropic, que foi lançado em novembro de 2025. A Anthropic faz várias afirmações, chamando-o de o "melhor modelo do mundo para codificação, agentes, uso de computador e fluxos de trabalho empresariais".
Esta não é apenas uma atualização menor. A empresa enfatiza seu raciocínio aprimorado e sua capacidade de lidar com informações confusas ou pouco claras. Além disso, ele é mais eficiente e menos caro que a versão anterior, o que é benéfico para empresas que buscam usar IA de ponta de forma econômica.
Ele está posicionado para competir com grandes modelos como o Gemini 3 Pro do Google e o GPT-5.1 da OpenAI. Você pode pensar nele como um polivalente que é particularmente adepto de lidar com trabalhos complexos e especializados.
Principais recursos e capacidades
Vamos entrar nos detalhes fundamentais dos novos recursos e o que eles significam para você, com base em informações oficiais e no que os usuários estão dizendo.
Um modelo líder para codificação e desenvolvimento
O Opus 4.5 tem atraído a atenção de desenvolvedores.
Ele marcou 80,9% no benchmark SWE-bench Verified, que é um teste desafiador que envolve a correção de problemas reais do GitHub. Essa é uma conquista significativa e indica suas capacidades avançadas de codificação.
Notavelmente, ele superou todos os candidatos humanos no próprio exame de engenharia extenuante da Anthropic. Isso sugere que ele pode tomar decisões técnicas difíceis sob pressão, de forma muito parecida com um desenvolvedor sênior.
Suas capacidades se estendem além da geração de código. O "Modo Plano" (Plan Mode) atualizado no Claude Code permite que o modelo faça perguntas para esclarecer o que você deseja e, em seguida, crie um arquivo "plan.md" editável. Isso ajuda a garantir que você obtenha a saída correta logo de cara.
Eu acho que o Claude é melhor quando se trata de trabalho de engenharia real, e especialmente se você usar os recursos mais avançados, o Claude code é simplesmente melhor que a CLI do Gemini
O surgimento de agentes de IA autônomos
Alguns modelos de IA são desafiados por dados de negócios do mundo real não estruturados. Por exemplo, um teste da Nate's Newsletter mostrou que o Opus 4.5 conseguiu combinar um manifesto de remessa digitado com uma folha de contagem manuscrita e não estruturada. Esta é uma tarefa que exige uma compreensão sólida de informações não estruturadas.
O Opus 4.5 também apresenta um bom desempenho em tarefas que levam tempo e exigem que ele pense nas coisas detalhadamente. Ele pode supervisionar uma equipe de subagentes e usa algo chamado compactação de contexto (context compaction) para se manter no caminho certo durante fluxos de trabalho complicados, para que você não precise verificá-lo constantemente. Este foi um ponto chave em seu anúncio oficial.
Ele montou todos os documentos fundamentais para o meu próximo projeto paralelo em tão pouco tempo e com uma qualidade tão alta, que é como ter a melhor equipe do mundo de estagiários e estudantes de pós-graduação, todos competindo para ser o seu melhor colaborador.
Ser capaz de trabalhar por conta própria por períodos prolongados faz com que ele pareça menos uma ferramenta básica e mais um membro de equipe confiável em quem você pode confiar para lidar com um processo do início ao fim.
Melhorias significativas em custo e eficiência
A API agora possui um parâmetro de "esforço" (effort), que é um recurso notável. Ele permite que os desenvolvedores equilibrem velocidade, custo e potência. Você pode escolher esforço baixo, médio ou alto com base no quão difícil é sua tarefa.
A diferença na eficiência é substancial. Em uma configuração de esforço médio, o Opus 4.5 tem um desempenho tão bom quanto o poderoso modelo Sonnet 4.5, mas usa 76% menos tokens de saída para realizar o trabalho.
Esse tipo de eficiência abre as portas para que mais empresas usem IA avançada. Fluxos de trabalho complexos que antes eram caros demais para uso regular tornam-se subitamente mais acessíveis.
Análise de desempenho: Pontos fortes e fracos
Aqui está uma olhada em como ele se comporta no mundo real, com base em relatos de outros usuários.
Ponto forte: Uma ferramenta colaborativa para desenvolvedores
Os desenvolvedores parecem ver o Opus 4.5 menos como uma ferramenta e mais como um parceiro de equipe. Uma análise técnica no Medium apontou que ele faz "mudanças cirúrgicas e direcionadas" em vez de apenas reescrever grandes blocos de código, o que indica uma compreensão sutil do código existente.
Sua enorme janela de contexto (context window) significa que ele pode absorver bases de código inteiras e ater-se à documentação oficial. Se você é um desenvolvedor trabalhando com novos SDKs ou hardware personalizado, esta é uma vantagem significativa. Como um usuário afirmou: "Eu literalmente nunca aceito nenhum código de nenhum modelo se ele não tiver lido a documentação primeiro." O Opus 4.5 foi projetado exatamente para isso.
Ponto forte: Lidar com dados de negócios não estruturados
A maior parte do conhecimento da empresa não está armazenada em um banco de dados perfeitamente organizado. Está espalhada por toda parte, em tickets de suporte, wikis internas e conversas intermináveis no Slack. O "desafio da árvore de Natal" mostrou que o Opus 4.5 é proficiente em filtrar esse tipo de informação bagunçada.
Isso é exatamente o que permite que um parceiro de equipe de IA como o eesel AI entenda o tom e as regras específicas da sua empresa. Você não precisa configurá-lo manualmente ou passar por uma configuração complicada. Ele apenas aprende com os dados existentes da sua central de ajuda, tickets antigos e bases de conhecimento. Dessa forma, ele pode começar a resolver problemas corretamente de imediato, usando a voz da sua marca.
Ponto forte: Alto nível de segurança e confiabilidade
A segurança é uma preocupação significativa para qualquer empresa que utiliza IA, particularmente quando se trata de ataques de injeção de prompt (prompt injection). Em um teste para este problema exato, o Opus 4.5 surgiu como o modelo mais seguro.
Testes da Vellum.ai descobriram que esses tipos de ataques só funcionaram 4,7% das vezes no Opus 4.5. Essa é uma taxa menor que a do Gemini 3 Pro (12,5%) e do GPT-5.1 (21,9%), posicionando-o como uma opção mais segura para aplicações voltadas ao cliente ou que lidam com informações sensíveis.
Ponto fraco: Feedback misto sobre raciocínio abstrato
Apesar de todos os seus pontos fortes, o feedback da comunidade não é totalmente positivo. Alguns desenvolvedores no Reddit relatam que ele produz "tantos falsos positivos". Eles preferem concorrentes como o GPT-5.1 Codex, dizendo que ele é "muito mais pronto para produção" e adota uma "abordagem mais cuidadosa e sistemática".
Meu problema com o Opus é que sua abordagem de programação carece de um raciocínio científico e matemático sólido.
Ele se destaca em seguir um plano de codificação, mas pode ter um desempenho menos eficaz em raciocínio altamente abstrato de nível de PhD. No benchmark GPQA Diamond, por exemplo, o Opus 4.5 marcou 82,4%, enquanto seu principal rival, o GPT-5.1 Codex Max, atingiu 89,4%.
A conclusão é que o Opus 4.5 parece ser um especialista. É provavelmente o melhor modelo disponível para realizar tarefas complexas de codificação e tarefas do tipo agente, mas não é o melhor em todos os tipos de problemas abstratos que você pode apresentar.
Preços e disponibilidade
Vamos revisar os detalhes de preço e acessibilidade.
Um ponto de preço mais acessível
O preço oficial da API é de US$ 5 por milhão de tokens de entrada e US$ 25 por milhão de tokens de saída.
Isso representa uma redução significativa em relação ao antigo modelo Opus 4.1, que custava anteriormente US$ 15 para entrada. Esse novo preço significa que as empresas podem usá-lo todos os dias, em vez de guardá-lo apenas para projetos especiais.
Comparação de preços com outros modelos
Embora o Claude Opus 4.5 seja significativamente mais barato que a última versão, ele ainda é precificado como um modelo premium em comparação com seus rivais. Mas, como ele é tão eficiente com tokens, o custo real de usá-lo pode ser menor do que você imaginaria apenas olhando para a lista de preços.
Aqui está uma olhada rápida em como os preços padrão de pagamento conforme o uso (pay-as-you-go) se comparam.
| Modelo | Custo de Entrada (por 1M tokens) | Custo de Saída (por 1M tokens) |
|---|---|---|
| Claude Opus 4.5 | US$ 5,00 | US$ 25,00 |
| Claude Sonnet 4.5 | US$ 3,00 | US$ 15,00 |
| OpenAI GPT-5.1 | US$ 1,25 | US$ 10,00 |
| Google Gemini 3 Pro | US$ 2,00 | US$ 12,00 |
Dados de preços obtidos das páginas oficiais da Anthropic, OpenAI e Google no final de 2025.
Como acessar o Claude Opus 4.5
Você pode obter o modelo por meio da API oficial do Claude, dos aplicativos web e desktop do Claude e em grandes plataformas de nuvem como o AWS Bedrock e o Google Cloud Vertex AI.
Se você o estiver usando individualmente ou como parte de uma equipe, o Opus 4.5 está disponível nos planos Max, Team e Enterprise. Pelo que as pessoas estão dizendo, parece que os usuários Pro podem precisar ter o "uso extra" ativado ou atualizar para um plano superior para usá-lo em todos os lugares.
Eu acho que você pode estar com o uso extra ativado. Rezo pela sua conta bancária.
Implicações para os negócios
Então, o que tudo isso significa para o seu negócio?
A maior mudança com modelos como o Opus 4.5 é que estamos saindo da IA como um simples "assistente" que apenas busca informações para um "parceiro de equipe de IA" que pode realmente fazer as coisas por conta própria.
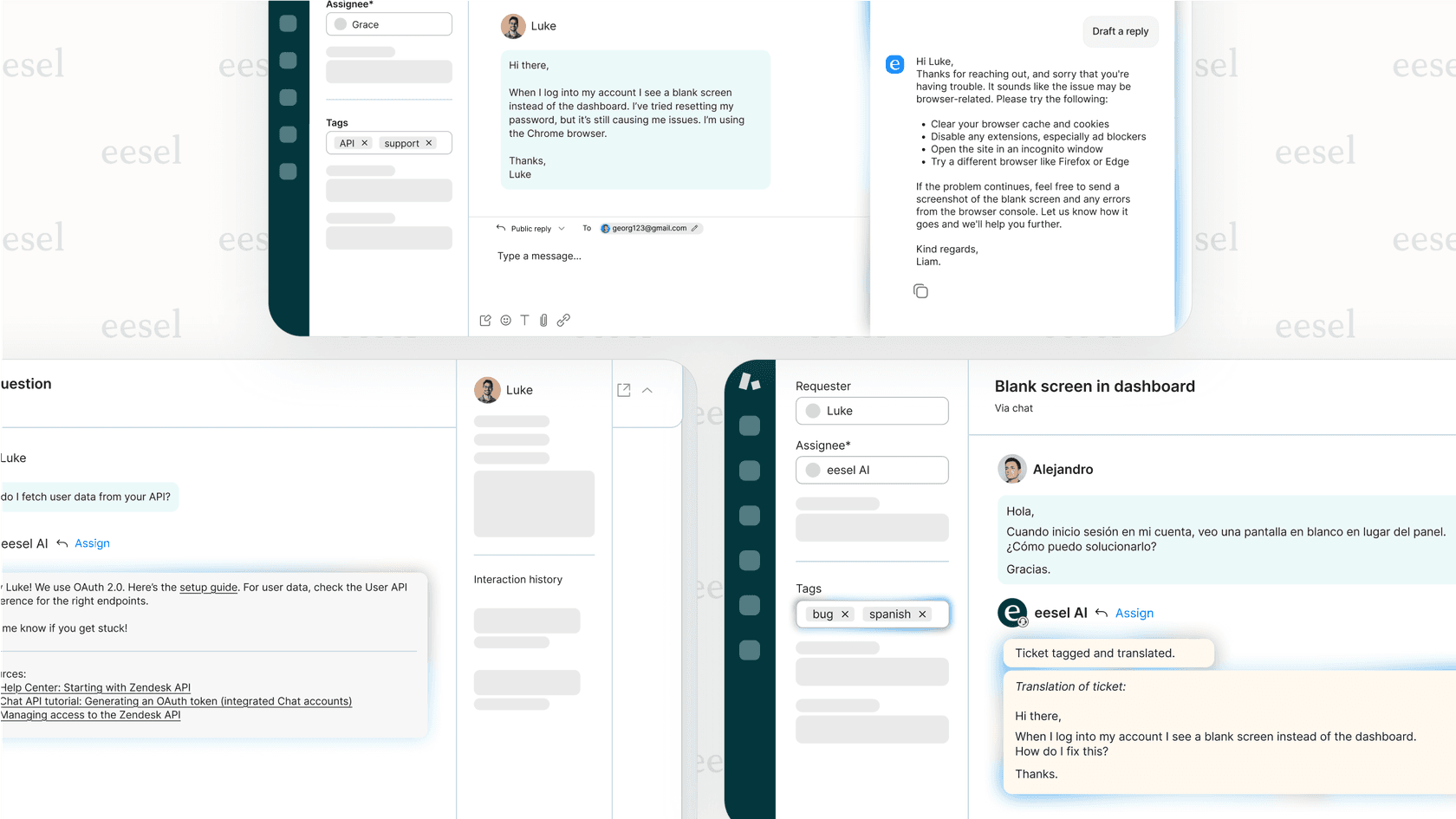
Pense nisso em termos de suporte ao cliente. Uma IA mais antiga poderia apenas encontrar um artigo de ajuda e enviar um link. Uma IA usando Opus 4.5 pode entender o problema do cliente, encontrar o pedido dele no Shopify, verificar a política de devolução em um Google Doc, processar a devolução usando uma ferramenta interna e, em seguida, fechar o ticket no Zendesk. Ela lida com tudo.
Esta é a ideia que impulsiona o AI Agent do eesel. Em vez de construir um bot rígido e baseado em regras, você essencialmente "contrata" um parceiro de equipe de IA. Ele aprende com as ferramentas e dados que você já usa para resolver problemas dos clientes por si mesmo e só traz um agente humano quando um toque pessoal é realmente necessário.
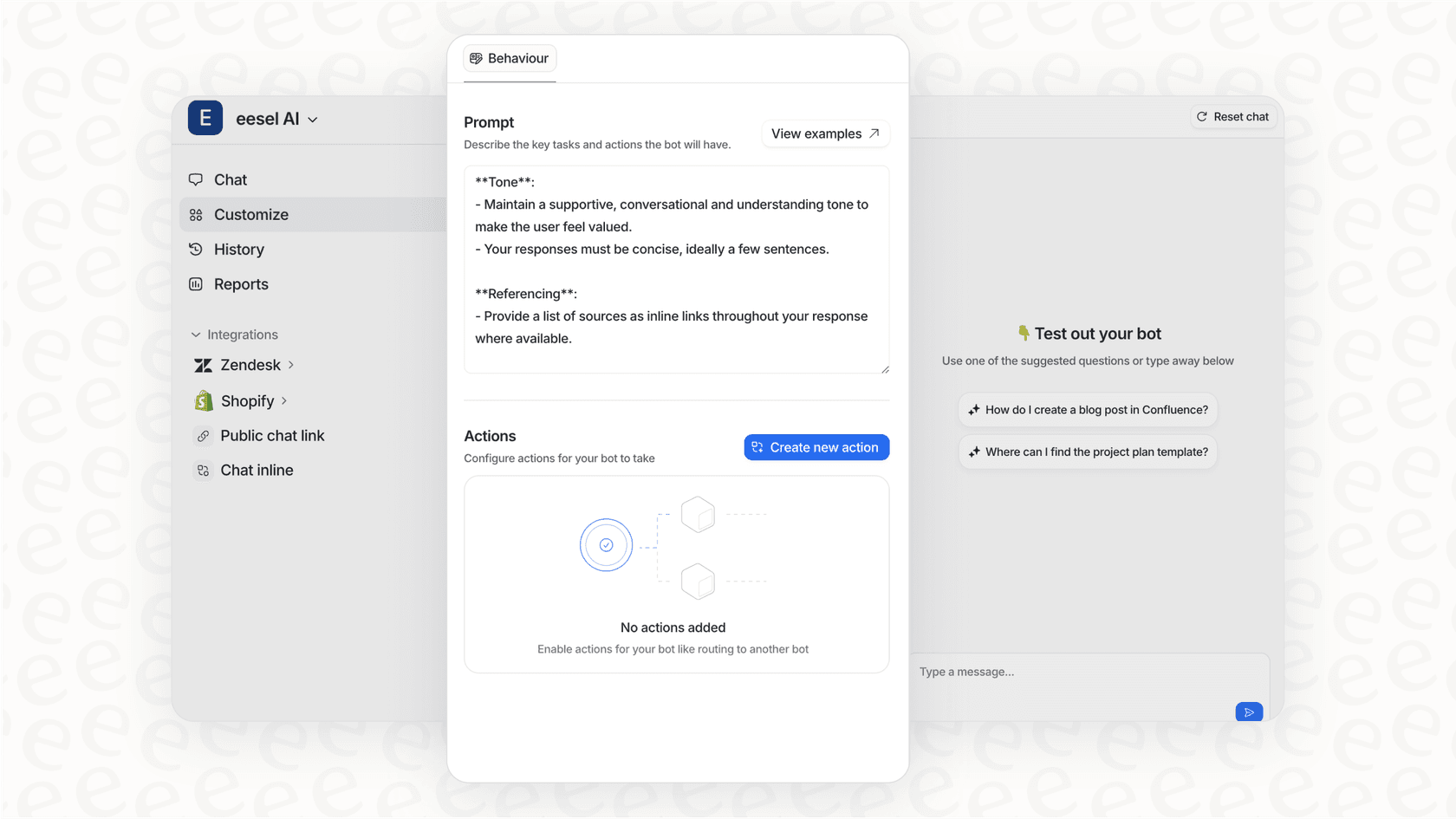
Para ver uma demonstração ao vivo de como o Claude Opus 4.5 lida com uma tarefa de engenharia do mundo real, confira o vídeo abaixo. Ele fornece uma visão aprofundada das capacidades do modelo quando colocado à prova em um desafio prático de codificação.
A ascensão do parceiro de equipe de IA
O Claude Opus 4.5 representa um desenvolvimento significativo. Suas excelentes habilidades de codificação, capacidade de lidar com tarefas longas e automatizadas e preço acessível o tornam uma base sólida para uma nova onda de ferramentas de IA.
Mais do que tudo, isso significa uma mudança dos chatbots básicos para parceiros de IA reais nos quais você pode confiar para fluxos de trabalho de negócios complicados e completos.
O futuro não se trata de substituir sua equipe; trata-se de suplementá-la com parceiros de equipe de IA capazes. Para ver como esse novo tipo de IA pode apoiar sua equipe de atendimento ao cliente, experimente o eesel AI gratuitamente.
Perguntas frequentes
A principal lição é que o Opus 4.5 atua mais como um parceiro de codificação do que como uma ferramenta simples. Ele é excelente em entender bases de código inteiras, fazer alterações precisas e seguir documentações, o que o torna útil para tarefas de desenvolvimento complexas do mundo real.
Não inteiramente. Embora seja um dos melhores em codificação e tarefas autônomas de várias etapas, ele pode ficar atrás em raciocínio altamente abstrato de nível de doutorado (PhD) em comparação com alguns concorrentes como o GPT-5.1 Codex Max. Ele é mais um modelo especialista do que generalista.
O preço é uma melhoria significativa. A US$ 5 por entrada e US$ 25 por saída por milhão de tokens, ele é substancialmente mais barato que o modelo Opus 4.1 anterior. Essa queda de preço o torna mais acessível para as empresas usarem no dia a dia.
A capacidade do modelo de funcionar como um "parceiro de equipe de IA", especialmente no suporte ao cliente, é destacada. Ele pode lidar com fluxos de trabalho complexos e de ponta a ponta, como processar uma devolução [interagindo com vários aplicativos](https://www.mckaywrigley.com/posts/opus-4.5) (Shopify, Zendesk, etc.), indo além de simples respostas de chatbot.
Ele é considerado como tendo segurança líder do setor. Testes mostram que ele é altamente resistente a ataques de injeção de prompt (prompt injection), com uma taxa de sucesso de apenas 4,7% para os atacantes. Isso o torna uma escolha confiável para aplicações voltadas ao cliente onde a segurança é uma prioridade.
Depende da tarefa. O Opus 4.5 é superior para benchmarks de codificação específicos (como o SWE-bench) e fluxos de trabalho de agentes. No entanto, [o GPT-5.1 Codex Max pontua mais alto](https://www.reddit.com/r/GeminiAI/comments/1p8tx82/comparing_claude_opus_45_vs_gpt51_vs_gemini_3/) em benchmarks de raciocínio abstrato, portanto, o modelo "melhor" depende do caso de uso específico.
Share this article

Article by
Kenneth Pangan
Escritor e profissional de marketing há mais de dez anos, Kenneth Pangan divide seu tempo entre história, política e arte, com muitas interrupções de seus cães exigindo atenção.