AIサポートエージェントを導入しました。では、それが顧客体験を向上させているのか、それとも悪化させているのか、どうやって判断しますか?MMLUやHellaSwagのような学術的ベンチマークは、セールスページでは印象的に見えるかもしれませんが、あなたのボットが顧客を静かに苛立たせているか、ブランドを誤って伝えているかどうかは教えてくれません。
多くのAIツールはブラックボックスです。何かがそこで起こっていることはわかりますが、具体的な内容は見えません。そして、パフォーマンスを意味のある方法で測定できなければ、改善することもできません。これが、役に立たないどころか害を及ぼす可能性のあるツールに時間とお金を無駄にする原因です。
このガイドでは、ビジネスの観点から見たLLM評価指標の基本を解説します。複雑なコードや学術理論は省略し、サポートリーダーとして実際に追跡する必要がある、AIが正確でブランドに合っていて、本当に役立つかどうかを確認するためのポイントに焦点を当てます。
LLM評価指標とは何か(そしてそれがビジネスにとってなぜ重要か)
まず、一般的なモデル評価と特定のシステム評価の違いを明確にしましょう。モデル評価は、大手AI企業が行うもので、基礎モデルを広範な学術的ベンチマークに対してテストします。システム評価は、あなたが行うべきことです:同じAIがあなたの世界、あなたのデータ、あなたの顧客でどのように機能するかをテストします。
こう考えてみてください:車のプロのテストトラックでの最高速度はベンチマークです。しかし、実際のパフォーマンス、つまり市街地の交通、穴ぼこ、そしてスーパーの狭い駐車スペースでの扱い方が、実際にあなたにとって重要です。一つは標準化されたテストであり、もう一つは日常的に直面する結果です。
適切な評価は、レポートのためのスコアを得ることではありません。それは、AIエージェントがチームの信頼できる拡張であることを確認することです。それはあなたを助けます:
- 一貫して正確な回答で実際の顧客の信頼を築く。
- すべてのやり取りがあなたのブランドのように聞こえることを確認してブランドを保護する。
- ランダムなタスクではなく、適切なタスクを自動化することでチームの効率を向上させる。
多くのプラットフォームは、このプロセス全体を非常に複雑にし、開始するために開発者が必要なことが多いです。目標は、サポート目標に直接結びついたパフォーマンスを測定する方法を見つけ、それを自分で管理できるほど簡単にすることです。
すべてのサポートリーダーが追跡すべき3つのカテゴリー
AIのパフォーマンスを明確に把握するために、指標を3つの主要な領域にグループ化できます:正確性、顧客体験、効率性。
1. 回答の質と正確性
ここでの目標は非常にシンプルです:AIが正確で事実に基づいた回答を提供し、単に物事を作り出さないようにすることです。これは顧客の信頼の基盤です。間違った情報を提供するAIは、AIがないよりも悪いです。
注目すべき重要な点は次のとおりです:
- 事実の正確性(または忠実性): 回答は実際にあなたのナレッジベース、ヘルプセンター、または過去のチケットの情報と一致していますか?これは幻覚に対する主な防御策です。回答が正しいように聞こえるかどうかを尋ねるだけでなく、それがあなたの会社の現実に基づいているかどうかを確認しています。
- 回答の完全性: AIはユーザーの質問に完全に答えたか、それともその一部にしか触れなかったか?不完全な回答はほぼ必ずフォローアップのメールにつながり、自動化の目的を台無しにし、顧客を苛立たせます。
- 正確性: 最も基本的なレベルで、情報は正しいか間違っているか?これを測定する古典的な方法は、完璧な質問と回答のペアの「ゴールデンセット」を手動で作成し、AIの出力と比較することです。
その「ゴールデンデータセット」を作成し維持することは非常に遅く、高価で、スケールしません。はるかに良いアプローチは、AIが既に持っている知識から学ぶことです。例えば、eesel AIは、すべての既存の信頼できる情報源、ヘルプセンター、Confluence、Google Docs、そして過去のチケットに埋もれた部族知識に接続します。これにより、すべての回答が最初からあなたの会社の検証済み情報に基づいていることが保証されます。一部のツールは、新しいナレッジベースをゼロから構築しアップロードすることを求めますが、eesel AIは、既に提供された成功した解決策から学び、その回答が理論的に正しいだけでなく、実際に証明されていることを保証します。
2. 顧客体験とブランドの整合性
AIが何を言うかだけでなく、どのように言うかも重要です。AIエージェントはあなたのブランドの直接的な反映です。そのトーンがロボット的で、ブランドに合わず、役に立たない場合、それはあなたが築き上げた顧客関係を損なう可能性があります。
ブランドの声を一貫させるためにこれらの指標を追跡します:
- 関連性: AIの回答は実際にユーザーが尋ねたことに対応しているか、それとも話が逸れているか?間違った質問に対する完璧な回答は依然として悪い回答です。
- トーンの遵守: 回答はあなたの会社のように聞こえるか?あなたの声がフレンドリーでカジュアルであれ、フォーマルでプロフェッショナルであれ、深く共感的であれ、AIはキャラクターを維持する必要があります。
- 簡潔さ: 回答は読みやすいか、それとも専門用語でいっぱいの巨大なテキストの壁か?顧客は忙しいので、明確で直接的な回答を求めています。
多くのAIツールは、変更できない固定されたロボットのような性格を持っています。eesel AIを使用すると、完全にコントロールできます。直感的なプロンプトエディタを使用して、コードを書くことなくAIの正確なトーン、ペルソナ、スタイルを定義できます。さらに良いことに、eesel AIは、チームの過去の成功したサポート会話を何千も分析することで、ブランドの声を自動的に学習できます。これにより、初日からチームの自然な一部のように聞こえるようになります。
プロのヒント: プロンプトエディタを使用して、AIエージェントにブランドに合った名前と個性を与えましょう。例えば:「あなたはペット用品会社の親切で陽気なサポートエージェント、スパーキーです。メッセージの最後には必ず楽しい動物の事実を添えます。」
3. ワークフローの効率と自動化
本当に役立つAIエージェントは、質問に答えるだけでなく、既存のサポートワークフローにぴったりとフィットします。それは設計されたタスクを処理し、人間にエスカレーションするタイミングを知り、全体の運用をスムーズにするべきです。
AIが実際に違いを生んでいるかどうかを測定するには、次のことを確認します:
- トリアージの正確性: AIがチケットをルーティングするとき、正しいタグ、優先度、部門を割り当てますか?誤ってルーティングされたチケットは、チームに余分な作業を生み出し、顧客が解決を待つ時間を長くします。
- タスクの完了: AIは複数のステップを含むアクションを自分で処理できますか?これは、Shopifyで注文状況を確認し、1つの会話で返品プロセスを開始するようなものです。これは単純なFAQボットと本当の自動化ツールの違いです。
- 自動化率対エスカレーション率: チケットの何パーセントがAIによって完全に解決され、何パーセントが正しく人間のエージェントに渡されますか?目標は単に高い自動化率ではなく、高い正確な自動化率です。すべてを処理しようとして失敗するボットは、限界を知っているボットよりも厄介です。
一部の競合他社は「オールオアナッシング」の自動化アプローチを推進しており、これは非常にリスキーです。eesel AIを使用すると、はるかに戦略的になれます。AIが処理するチケットの種類(「パスワードリセット」や「注文状況の問い合わせ」など)を正確に選択し、それ以外はすべて自動的にエスカレーションすることで、小さく始めることができます。慣れてきたら、徐々に責任を増やすことができます。カスタムAIアクションを使用すると、エージェントは単に話すだけでなく、Zendeskでチケットにタグを付けたり、Shopifyで注文の詳細を確認したり、Jira Service Managementで問題を作成したりできます。これにより、AIは単なるQ&Aボットからチームの真の働き手に変わります。
データサイエンティストを雇わずにLLM評価指標を実装する方法
さて、これを実際にどのように実践するか?ほとんどのプラットフォームでは、遅くて苦痛なプロセスです。eesel AIを使用すると、それは製品の一部です。
他のプラットフォームを使用した難しい方法
- 終わりのない手動レビュー: ベースラインを得るために、何千もの会話を手動で読み、スコアを付け、分類するためにチームの時間を何週間も費やす。
- 開発者の時間を求める: AIのパフォーマンスに関する基本的なデータを得るために、カスタム評価スクリプトとレポートツールを構築するためにエンジニアが必要。
- リスキーな展開: テストされていないAIを顧客に導入し、データなしでただうまくいくことを願う。
eesel AIを使用した簡単な方法
- 数分でライブに: eesel AIは、ヘルプデスクや他のツールとのワンクリック統合を提供します。複雑なセットアップや長いセールスプロセスはなく、完全に自分で無料で始められます。
- 自信を持ってテスト: シミュレーションモードは大きな利点です。実際の過去のチケットを何千も安全な環境でテストできます。AIエージェントがどのように応答したかを正確に確認でき、実際の顧客と話す前に自動化率と正確性の予測を得ることができます。
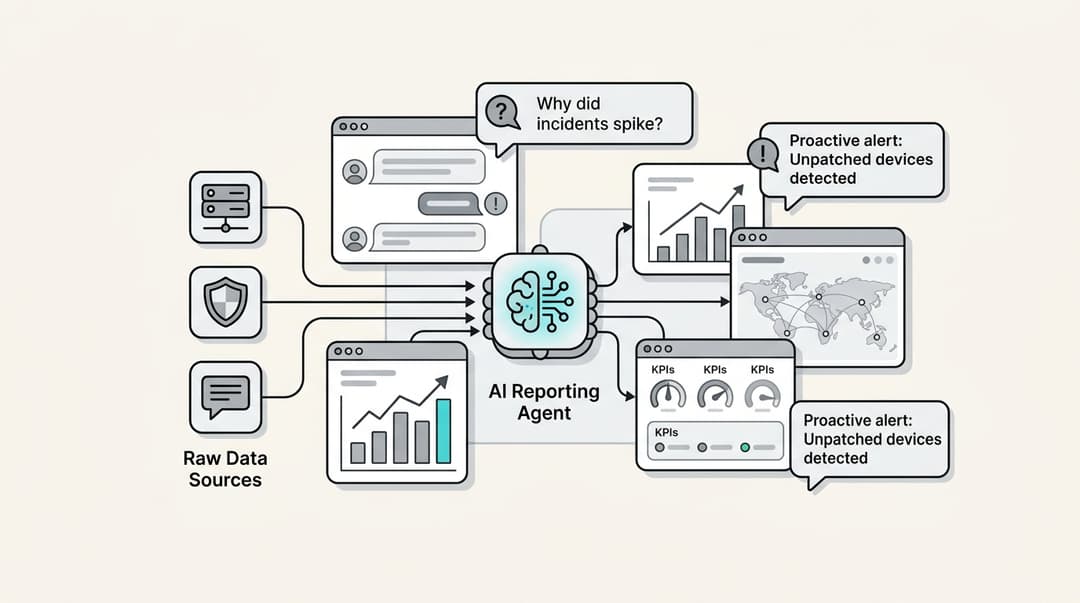
- 使えるインサイトを得る: eesel AIダッシュボードは、虚栄心の指標を示すだけではありません。ナレッジベースのギャップを特定し、自動化に最適な一般的な顧客問題を強調するレポートを提供します。
ここに簡単な違いの内訳があります:
| 機能 | 従来の方法 | eesel AIの方法 |
|---|---|---|
| セットアップ | 開発者の作業とセールスコールに数週間 | 数分、完全にセルフサービス |
| テスト | 手動のスポットチェックまたはテストなし | 過去の実際のチケットを大量にシミュレーション |
| 展開 | リスキーな「ビッグバン」ローンチ | チケットタイプやチャネルごとの自信を持った段階的な展開 |
| レポート | 何が起こったかを示す基本的な使用統計 | ナレッジギャップと自動化の機会に関する実用的なインサイトを提供し、なぜそうなったかを示す |
推測をやめて、LLM評価指標で測定を始めましょう
効果的なLLM評価指標は、抽象的なスコアや学術的なテストでの成功を目指すものではありません。それは、顧客とサポートチームにとって実際に重要なこと、つまり正確性、体験、効率性を測定することです。これを正しく行うことは、問題を増やすAIと実際に価値を提供するAIの違いです。
AIエージェントが機能しているかどうかを判断するためにデータサイエンスの博士号は必要ありません。必要なのは、そのパフォーマンスを明確に可視化し、コントロールできる適切なツールです。
eesel AIは、サポートリーダーが自信を持ってAIを展開できるようにゼロから構築されました。シミュレーションとレポートツールを使用して、推測から知識へと移行し、AIが初日から資産であることを確認できます。
サポートワークフローがどのように精度と自信を持って自動化されるかを確認する準備はできましたか?デモを予約するか、無料でサインアップして、最初のシミュレーションを実行してみてください。
よくある質問
ビジネスに最もリスクをもたらす指標、つまり事実の正確性から始めましょう。AIが誤った回答をしたり、幻覚を見たりしないようにすることが、ブランドのトーンや効率性に焦点を当てる前に最も重要な第一歩です。
高い自動化率は、AIが誤った回答で顧客を苛立たせている場合には意味がありません。まず品質指標に焦点を当てることで、自動化が本当に役立つものであることを保証し、チケットの再オープンを防ぎ、ブランドの評判を守ります。
一度きりの設定ではなく、継続的な改善のプロセスと考えてください。製品や顧客の質問が進化するにつれて、新しい自動化の機会を見つけたり、知識ベースのギャップを特定するために定期的に指標を見直すことが望ましいです。
BLEUやROUGEのようなベンチマークは学術的でテキストの類似性を測定しますが、それが事実上正しいか役立つかを示すものではありません。このガイドの指標はビジネスに焦点を当てており、正確性や実際の問題解決のように顧客体験に直接影響を与えるものを測定します。
もちろんです。小さなチームの場合、まず事実の正確性とトリアージの正確性に焦点を当てましょう。この組み合わせにより、AIが誤った情報を提供せず、複雑なチケットを正しく人間のエージェントに振り分けることが保証され、リソースが限られたチームにとって最も重要な機能が確保されます。
Share this article

Article by
Stevia Putri
Stevia Putri is a marketing generalist at eesel AI, where she helps turn powerful AI tools into stories that resonate. She’s driven by curiosity, clarity, and the human side of technology.