Análisis de Claude Opus 4.7: El nuevo estándar para el razonamiento de IA en 2026
Stevia Putri
Última edición April 21, 2026
El mundo de la IA avanza rápido, pero el lanzamiento de Claude Opus 4.7 el 16 de abril de 2026 se siente como un cambio fundamental de dirección. Si bien los últimos dos años han sido una carrera por la velocidad y la menor latencia, el último modelo insignia de Anthropic toma un camino diferente. No está construido necesariamente para ser el más rápido; está construido para ser el más riguroso.
En este análisis, profundizaremos en lo que hace de Opus 4.7 un "salto en el razonamiento", por qué ha provocado un acalorado debate sobre la regresión del modelo y cómo las empresas ya lo están utilizando para manejar tareas complejas y autónomas que los modelos anteriores simplemente no podían abordar.
¿Qué hay de nuevo en Opus 4.7?
Claude Opus 4.7 no es una revisión arquitectónica completa, sino más bien una actualización enfocada en la "fiabilidad agente a largo plazo". Si Opus 4.6 se trataba de obtener la respuesta correcta rápidamente, 4.7 se trata de demostrar que la respuesta es correcta antes incluso de que te la comunique.

Excelencia en ingeniería de software
La mejora principal está en la programación. Opus 4.7 alcanzó un impresionante 87,6% en SWE-bench Verified, frente al 80,8% de Opus 4.6. Aún más impresionante es su rendimiento en SWE-bench Pro (+10,9 puntos), lo que sugiere que sus ganancias se concentran en los problemas de ingeniería de software más difíciles y únicos, en lugar de solo en patrones comunes.
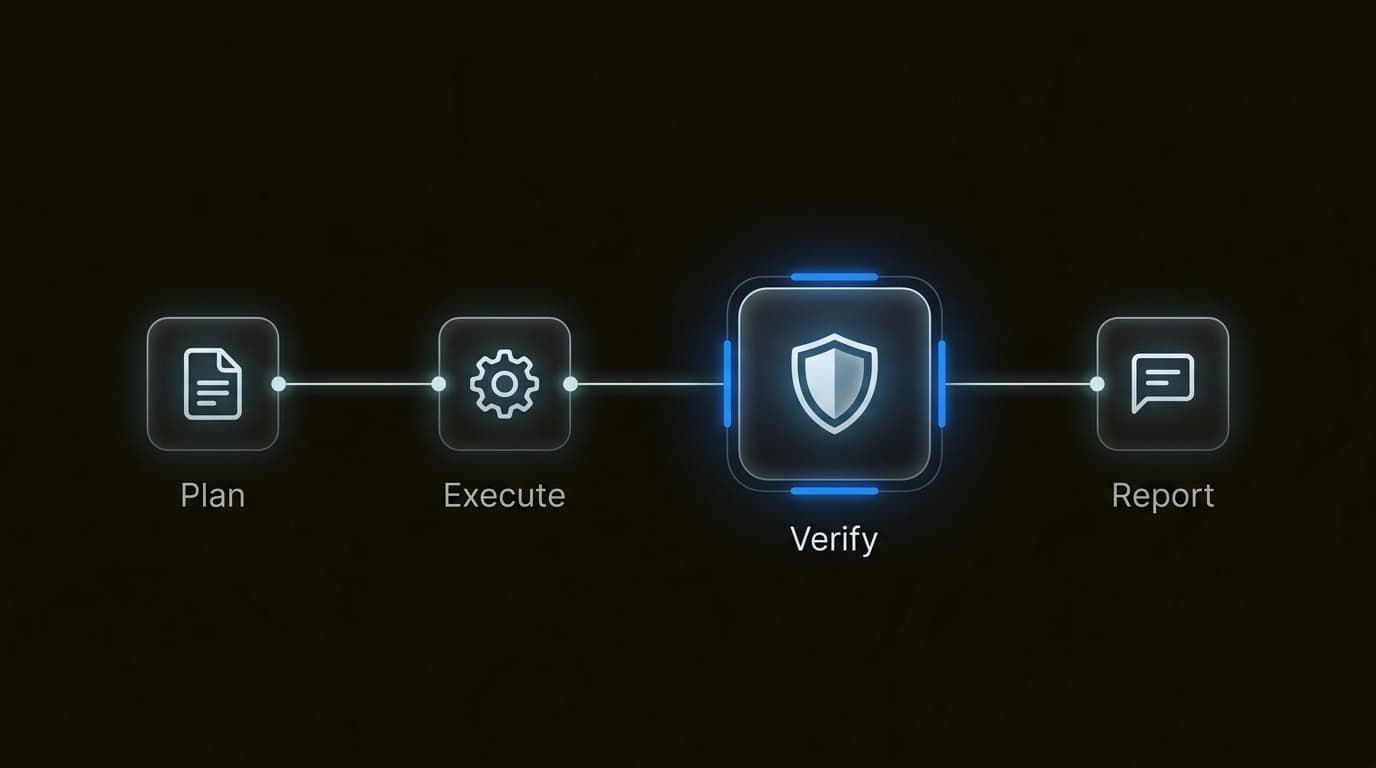
Autoverificación y rigor
Quizás la característica más "humana" de 4.7 es su capacidad para verificar sus propios resultados. En la práctica, cuando le das a Opus 4.7 una tarea compleja, no solo la ejecuta y la reporta. Escribe pruebas de forma proactiva, ejecuta comprobaciones de integridad e inspecciona su propio trabajo. Este bucle de "Verificar antes de reportar" reduce significativamente las tasas de error en el trabajo de agentes de larga duración.
Capacidades de visión mejoradas
Opus 4.7 ahora admite imágenes de hasta 2.576 píxeles en el borde largo (~3,75 megapíxeles). Esto supone un aumento de 3,3 veces en la resolución con respecto a los modelos anteriores. Para las empresas, esto significa que la IA ahora puede "leer" capturas de pantalla densas, diagramas arquitectónicos complejos y elementos de interfaz de usuario perfectos a nivel de píxel que antes eran demasiado borrosos para una extracción fiable.
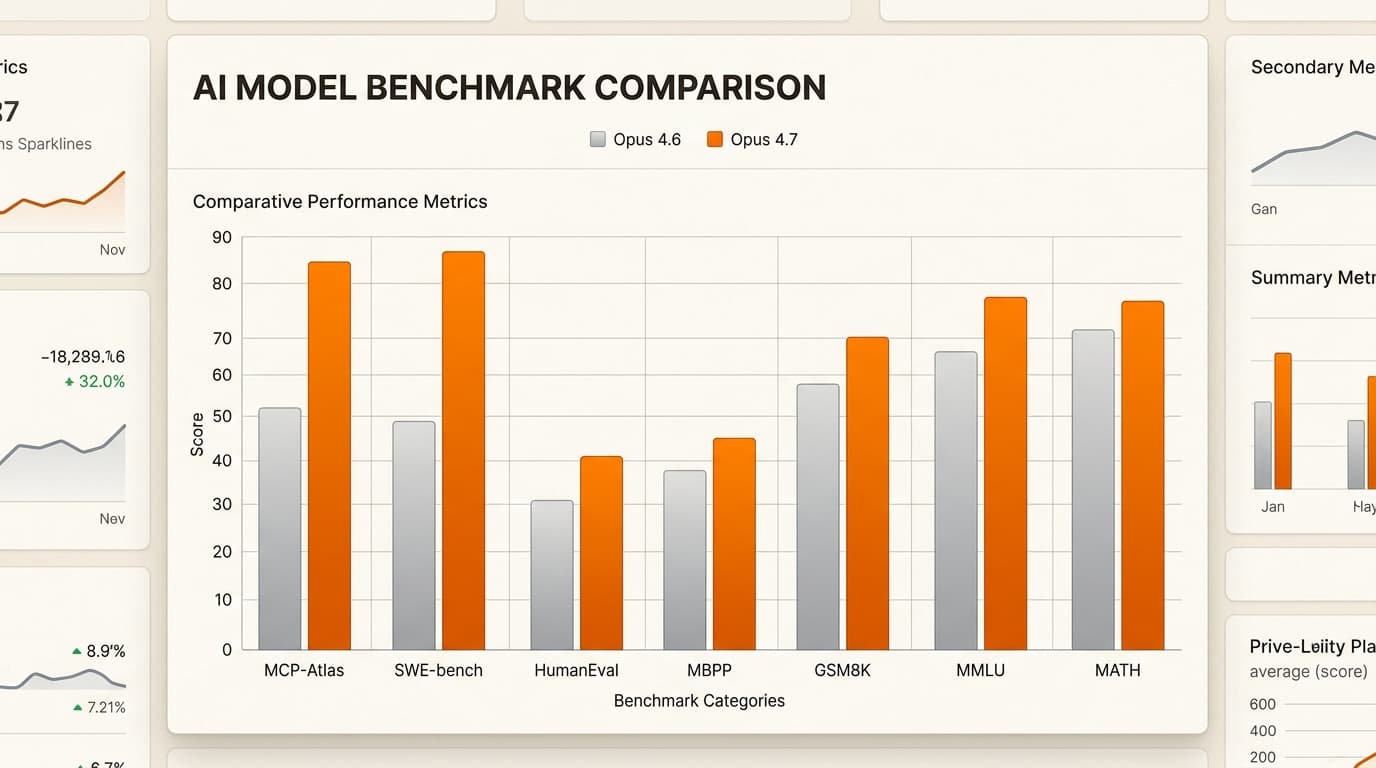
El modelo de "pensamiento": Benchmarks de rendimiento
Anthropic ha posicionado a 4.7 como la IA para personas que piensan. No solo está prediciendo el siguiente token; está "razonando" a través de pasos. Esto se refleja en su rendimiento en los benchmarks en todos los ámbitos.
| Benchmark | Claude Opus 4.7 | Claude Opus 4.6 | Delta |
|---|---|---|---|
| SWE-bench Verified | 87,6% | 80,8% | +6,8 |
| GPQA Diamond | 94,2% | 91,3% | +2,9 |
| MCP-Atlas (Herramientas) | 77,3% | 62,7% | +14,6 |
| Agente financiero (SOTA) | 64,4% | 60,7% | +3,7 |
El salto en MCP-Atlas (+14,6 puntos) es particularmente notable para cualquiera que esté construyendo agentes autónomos. Demuestra que 4.7 es significativamente mejor usando herramientas, como buscar en una base de datos o interactuar con una API, sin perderse en el proceso.
Abordando la controversia: ¿Es una regresión?
A pesar de los brillantes benchmarks, el lanzamiento no ha estado exento de controversia. En plataformas como Reddit, un segmento vocal de usuarios ha etiquetado a Opus 4.7 como una "regresión".
¿La queja principal? La velocidad.
Debido a que Opus 4.7 "piensa" más, especialmente en los nuevos niveles de esfuerzo xhigh y max, puede sentirse significativamente más lento que 4.6. Algunos usuarios lo describen como "pensar demasiado" en tareas simples. También existe la percepción de que el modelo ha perdido parte de su "alma creativa" en la escritura no técnica, volviéndose más literal y seco.
El factor del Proyecto Glasswing
Parte de este cambio es intencional. Opus 4.7 es el primer modelo lanzado ampliamente que incluye la pila de salvaguardas del Proyecto Glasswing. Anthropic experimentó explícitamente con la reducción de las capacidades de ciberseguridad ofensiva durante el entrenamiento. Estas salvaguardas detectan y bloquean automáticamente las solicitudes que indican usos cibernéticos de alto riesgo. Si bien esto hace que el modelo sea más seguro para las empresas, añade una capa de "literalidad" que puede sentirse como una restricción para los usuarios avanzados.
Casos de uso empresarial prácticos
Para la mayoría de las empresas, el debate sobre la "regresión" es una distracción del verdadero valor del modelo: su fiabilidad. En eesel AI, vemos a Opus 4.7 como el motor perfecto para compañeros de equipo de IA.
Flujos de trabajo de soporte complejos
Imagine una solicitud de atención al cliente que requiere:
- Comprobar el estado de suscripción de un usuario en Stripe.
- Cruzar esa información con una política de reembolso en una wiki de Confluence.
- Actualizar un ticket en Zendesk.
- Enviar una notificación de Slack al equipo de finanzas.
Los modelos anteriores podrían omitir un paso o alucinar un detalle. La "autoverificación" de Opus 4.7 garantiza que cada paso se compruebe con el anterior. Es la diferencia entre un bot que adivina y un compañero de equipo de IA que sabe.
Generación de documentos y diapositivas
Con su visión mejorada y su gusto creativo, 4.7 también es significativamente mejor produciendo interfaces, diapositivas y documentos profesionales de alta calidad. Puede "ver" sus activos de marca existentes con 3,3 veces más claridad y garantizar que el contenido generado siga perfectamente sus herramientas de programación de Claude AI y estándares de diseño.
Primeros pasos y precios
La buena noticia es que Claude Opus 4.7 es un reemplazo directo en la API, y el precio se mantiene sin cambios:
- Entrada: 5 $ por 1 millón de tokens
- Salida: 25 $ por 1 millón de tokens
Sin embargo, hay un inconveniente. Opus 4.7 utiliza un tokenizador actualizado. El mismo texto puede asignarse a 1,0–1,35 veces más tokens que en la versión 4.6. Esto significa que, aunque el precio por token es el mismo, su coste por tarea podría aumentar ligeramente.
Consejos para escribir prompts en 4.7
- Sé literal: Dado que 4.7 sigue las instrucciones con mayor precisión, evita las "vibraciones vagas". Sé explícito sobre lo que quieres.
- Usa el nivel xhigh: Este nuevo nivel de esfuerzo se sitúa entre alto y máximo, ofreciéndote el mejor equilibrio entre razonamiento y latencia.
- Establece presupuestos de tareas: Utiliza los nuevos presupuestos de tareas en versión beta para limitar tu gasto en tokens en trabajos autónomos de larga duración.
El veredicto: Precisión sobre velocidad
Claude Opus 4.7 es una herramienta especializada. Si necesitas una charla rápida sobre qué cenar, probablemente sea excesivo (y demasiado lento). Pero si estás construyendo compañeros de equipo de IA autónomos para manejar operaciones comerciales críticas, ingeniería de software o extracción de datos compleja, es el nuevo estándar de oro.
Elige la precisión sobre la velocidad, y el rigor sobre las "vibraciones". Para el futuro del trabajo autónomo, ese es exactamente el equilibrio que necesitamos.
Preguntas frecuentes
Share this article

Article by
Stevia Putri
Stevia Putri is a marketing generalist at eesel AI, where she helps turn powerful AI tools into stories that resonate. She’s driven by curiosity, clarity, and the human side of technology.