Claude Opus 4.7: El auge del modelo de ingeniero sénior
Stevia Putri
Última edición April 20, 2026
El lanzamiento sorpresa de Claude Opus 4.7 no es solo otra mejora en los benchmarks. Aunque nos hemos acostumbrado a que los modelos mejoren ligeramente en matemáticas o programación con cada iteración, esta actualización marca un cambio distintivo en cómo se comportan estos sistemas. Es el paso de un asistente pasivo que sigue órdenes a un colaborador que piensa, planifica y, en ocasiones, cuestiona.
Anthropic posiciona a Claude Opus 4.7 como un modelo diseñado para trabajos de ingeniería de nivel sénior, y los primeros comentarios de la comunidad de desarrolladores sugieren que han dado en el clavo. No se trata tanto de las puntuaciones brutas, sino de la "disciplina epistémica" que muestra el modelo: la capacidad de saber lo que no sabe y verificar su propio trabajo antes de presentárselo al usuario.

Analicemos por qué este lanzamiento es importante para su flujo de trabajo y cómo cambia el panorama para los agentes de IA en 2026.
El cambio de comportamiento: Por qué Claude Opus 4.7 parece un ingeniero sénior
Lo más interesante del lanzamiento de Claude Opus 4.7 no fueron los gráficos. Fueron los testimonios de empresas como Replit, Hex y Cognition. Describen un modelo que se está moldeando hacia una nueva personalidad: la de un ingeniero sénior en lugar de la de un asistente servicial.
Este cambio se manifiesta en tres comportamientos clave:
- Planificación y verificación: En lugar de lanzarse directamente a programar, el modelo planifica su enfoque y detecta sus propios fallos lógicos antes de la ejecución.
- Disposición a discrepar: Aporta una perspectiva con más criterio. Si usted propone una arquitectura subóptima, es más probable que Opus 4.7 le cuestione y sugiera una alternativa mejor en lugar de simplemente estar de acuerdo con usted.
- Persistencia ante el fracaso: En los bucles de agentes, sigue ejecutándose a pesar de los fallos en las herramientas que habrían detenido por completo a los modelos anteriores.
Un CEO en Replit compartió recientemente: "Personalmente, me encanta cómo cuestiona durante las discusiones técnicas para ayudarme a tomar mejores decisiones. Realmente se siente como un mejor compañero de trabajo".
En eesel AI, vemos esto como un momento crucial para la automatización de contenidos y soporte. Cuando contrata a un compañero de equipo de IA para gestionar investigaciones o redacciones complejas, no solo quiere un redactor rápido, quiere un compañero que entienda los matices de su marca y pueda autocorregir su producción.
Visión de alta resolución: 3 veces más detalle para tareas complejas
La visión siempre ha sido un cuello de botella para los agentes de IA encargados de navegar por interfaces de usuario complejas o leer documentos técnicos densos. Claude Opus 4.7 elimina eficazmente ese cuello de botella con un salto masivo en el soporte de resolución.
El modelo ahora admite imágenes de hasta 2576 píxeles en el borde largo (~3.75 megapíxeles), lo que supone más de tres veces la fidelidad de los modelos Claude anteriores. Para los desarrolladores que crean agentes de "uso informático", esta es la diferencia entre una captura de pantalla borrosa y un mapa de la interfaz con precisión de píxel.
Así es como este salto en la visión se traduce en la práctica:
- Coordenadas de píxeles 1:1: Las coordenadas del modelo ahora se asignan directamente a los píxeles reales. Esto significa que ya no hay que hacer cálculos de factor de escala ni adivinar dónde está un botón en una pantalla de alta resolución.
- Análisis de diagramas técnicos: Puede leer estructuras químicas, planos arquitectónicos y diagramas de ingeniería complejos con mucha mayor precisión.
- Extracción de datos: Puede transcribir datos de paneles y figuras densas que antes eran ilegibles.
Un CTO en XBOW señaló: "Nuestro mayor punto de dolor con Opus desapareció efectivamente, y eso desbloquea su uso para toda una clase de trabajo donde no podíamos usarlo antes".
Potencia de API: esfuerzo xhigh y presupuestos de tareas
Para aquellos que desarrollan sobre la plataforma Claude, Opus 4.7 introduce nuevos controles que le permiten ajustar el equilibrio entre inteligencia y coste.
El nuevo nivel de esfuerzo xhigh
El parámetro de esfuerzo se ha ampliado con un nuevo nivel xhigh ("extra alto"). Se sitúa entre high y max, proporcionando una capacidad de razonamiento más profunda que ahora es la predeterminada para Claude Code.
Comience con el nivel de esfuerzo xhigh para:
- Tareas de refactorización complejas
- Encontrar errores profundamente arraigados en grandes bases de código
- Bucles de agentes de largo alcance donde la calidad es primordial
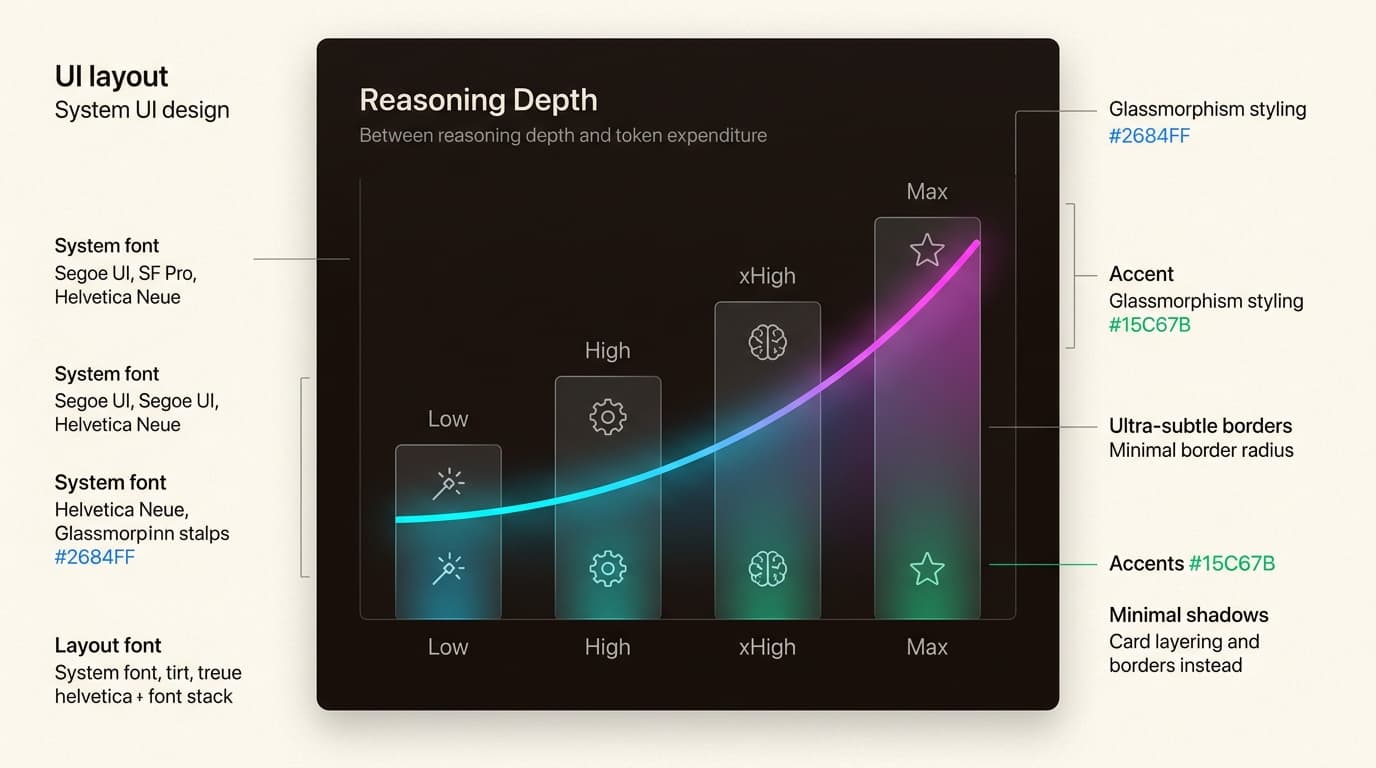
Presupuestos de tareas (beta)
Anthropic también está introduciendo presupuestos de tareas en versión beta pública. Esto le da al modelo una asignación de tokens objetivo para un bucle de agentes completo. A diferencia de max_tokens, que es un límite estricto del que el modelo no es consciente, Claude puede ver una cuenta atrás de su presupuesto de tarea y utilizarla para priorizar el trabajo.
Si el presupuesto se está agotando, el modelo intentará terminar la tarea correctamente en lugar de cortarse a mitad de frase. Es una herramienta para limitar el trabajo a una asignación de tokens específica, aunque deberá experimentar con el límite mínimo de 20k tokens para encontrar el punto óptimo para su caso de uso.
La paradoja de los precios: mismas tarifas, nuevo tokenizador
Sobre el papel, el precio de Claude Opus 4.7 sigue siendo el mismo que el de Opus 4.6: $5 por millón de tokens de entrada y $25 por millón de tokens de salida. Sin embargo, hay una variable oculta que debe tener en cuenta: el tokenizador actualizado.
El nuevo tokenizador mejora la forma en que el modelo procesa el texto, pero también significa que la misma entrada puede asignarse a más tokens (aproximadamente 1.0x a 1.35x más dependiendo del tipo de contenido). Esto resulta efectivamente en un aumento moderado de costes para el mismo volumen de texto sin procesar.
Para gestionar esto, debería apoyarse en:
- Almacenamiento en caché de prompts: Ahorre hasta un 90% en costes de entrada para contextos repetitivos.
- Procesamiento por lotes: Obtenga un 50% de ahorro para tareas que no requieren urgencia.
- Ajuste de esfuerzo: Utilice
highen lugar dexhighpara tareas más sencillas y mantener el uso de tokens bajo control.
Esto es particularmente relevante al comparar Claude con otros modelos como GPT-4 y Gemini. Aunque el precio por token pueda parecer idéntico, el coste "en el mundo real" por tarea depende ahora más de cuánto "piensa" el modelo en niveles de esfuerzo más altos.
Guía de migración: Pasar de Claude Opus 4.6 a 4.7
La actualización a Claude Opus 4.7 está diseñada para ser una mejora directa, pero querrá ajustar su implementación para obtener los mejores resultados.
| Cambio | Recomendación |
|---|---|
| Margen | Aumente su límite de max_tokens para tener en cuenta el cambio del tokenizador de 1.0x-1.35x. |
| Andamiaje | Elimine prompts como "revisa dos veces tu trabajo" o "planifica cuidadosamente". Opus 4.7 lo hace de forma nativa. |
| Esfuerzo | Cambie a xhigh para sus tareas de programación y agentes más difíciles. |
| Presupuestos | Implemente presupuestos de tareas para agentes autónomos a fin de evitar bucles indefinidos. |
Si ya está utilizando compañeros de equipo de IA para automatizar flujos de trabajo de programación complejos, probablemente verá un aumento inmediato en la fiabilidad. El modelo supera los fallos de las herramientas que antes requerían intervención manual, haciendo que la experiencia de "compañero de equipo" se sienta mucho más fluida.
Para los profesionales de la seguridad, también existe el nuevo Programa de Verificación Cibernética. Permite a los usuarios verificados omitir las salvaguardas cibernéticas en tiempo real para investigaciones legítimas, como pruebas de penetración e investigación de vulnerabilidades.
Conclusión
Claude Opus 4.7 es un avance de hacia dónde nos dirigimos: lejos de los chatbots y hacia compañeros de equipo autónomos. Al optimizar el razonamiento sostenido y los comportamientos de "sénior", como cuestionar las malas ideas, Anthropic ha construido un modelo al que se le puede confiar más responsabilidad.
Ya sea que esté creando un panel de control, depurando una condición de carrera o automatizando su cola de soporte, el cambio en el comportamiento importa mucho más que los benchmarks. Por fin es hora de dejar de cuidar a sus agentes y empezar a colaborar con ellos.
Preguntas frecuentes
Share this article

Article by
Stevia Putri
Stevia Putri is a marketing generalist at eesel AI, where she helps turn powerful AI tools into stories that resonate. She’s driven by curiosity, clarity, and the human side of technology.