El mundo de la IA se mueve a un ritmo vertiginoso. Usted finalmente logra que su equipo se ponga al día con un modelo y, de repente, aparece algo como Claude Opus 4.5, prometiendo cambiar las reglas del juego una vez más.
Es fácil perderse en el entusiasmo y en las puntuaciones de las pruebas de rendimiento (benchmarks). ¿Qué significan realmente estas actualizaciones para el flujo de trabajo diario de su equipo? ¿Es este solo otro pequeño paso adelante o es un salto genuino que podría cambiar su forma de trabajar?
Esta reseña de Claude Opus 4.5 examina sus habilidades de codificación, sus capacidades de agente autónomo, sus limitaciones y su nueva estructura de precios, explorando sus implicaciones para las empresas, particularmente en el área de atención al cliente.
¿Qué es Claude Opus 4.5?
¿Qué es exactamente Claude Opus 4.5? Es el modelo de lenguaje de gran tamaño (LLM, large language model) de nivel superior más reciente de Anthropic, el cual lanzaron en noviembre de 2025. Anthropic hace varias afirmaciones, llamándolo el "mejor modelo del mundo para codificación, agentes, uso de computadoras y flujos de trabajo empresariales".
Esta no es solo una actualización menor. La empresa enfatiza su razonamiento mejorado y su capacidad para lidiar con información confusa o poco clara. Además, es más eficiente y menos costoso que la versión anterior, lo cual es beneficioso para las empresas que buscan utilizar IA de alta gama de manera rentable.
Está posicionado para competir con modelos importantes como Gemini 3 Pro de Google y GPT-5.1 de OpenAI. Usted puede pensar en él como un modelo polifacético que es particularmente hábil en el manejo de trabajos complejos y especializados.
Características y capacidades clave
Entremos en los detalles de las nuevas funciones y lo que significan para usted, basándonos en la información oficial y en lo que dicen los usuarios.
Un modelo líder para codificación y desarrollo
Opus 4.5 ha captado la atención de los desarrolladores.
Obtuvo una puntuación del 80,9% en el benchmark SWE-bench Verified, que es una prueba desafiante que implica corregir problemas reales de GitHub. Este es un logro significativo e indica sus avanzadas capacidades de codificación.
Notablemente, superó a todos los candidatos humanos en el propio y agotador examen de ingeniería de Anthropic. Esto sugiere que puede tomar decisiones técnicas difíciles bajo presión, de manera muy similar a un desarrollador senior.
Sus capacidades van más allá de la generación de código. El "Plan Mode" (Modo de Planificación) actualizado en Claude Code permite que el modelo haga preguntas para aclarar lo que usted desea y luego crear un archivo "plan.md" editable. Esto ayuda a asegurar que usted obtenga el resultado correcto desde el principio.
Creo que Claude es mejor cuando se trata de trabajo de ingeniería real, y especialmente si usas las funciones más avanzadas, Claude Code es simplemente mejor que la CLI de Gemini
El surgimiento de los agentes de IA autónomos
Algunos modelos de IA tienen dificultades con los datos empresariales del mundo real que no están estructurados. Por ejemplo, una prueba de Nate's Newsletter mostró que Opus 4.5 podía cotejar un manifiesto de envío mecanografiado con una hoja de recuento escrita a mano y no estructurada. Esta es una tarea que requiere una sólida comprensión de la información no estructurada.
Opus 4.5 también funciona bien en tareas que toman tiempo y requieren que piense las cosas detenidamente. Puede supervisar un equipo de subagentes y utiliza algo llamado compactación de contexto (context compaction) para mantenerse en el camino correcto durante flujos de trabajo complicados, de modo que usted no tenga que estar revisándolo constantemente. Este fue un punto clave en su anuncio oficial.
Preparó todos los documentos fundamentales para mi próximo proyecto paralelo en tan poco tiempo y con una calidad tan alta que es como tener al mejor equipo del mundo de pasantes y estudiantes de posgrado compitiendo por ser tu mejor empleado.
Ser capaz de trabajar por su cuenta durante períodos prolongados hace que se sienta menos como una herramienta básica y más como un miembro confiable del equipo en el que usted puede confiar para manejar un proceso de principio a fin.
Mejoras significativas en costo y eficiencia
La API ahora tiene un parámetro de "esfuerzo" (effort), que es una característica notable. Permite a los desarrolladores equilibrar velocidad, costo y potencia. Usted puede elegir un esfuerzo bajo, medio o alto según la dificultad de su tarea.
La diferencia en eficiencia es sustancial. En una configuración de esfuerzo medio, Opus 4.5 rinde tan bien como el potente modelo Sonnet 4.5, pero utiliza un 76% menos de tokens de salida para realizar el trabajo.
Este tipo de eficiencia abre la puerta para que más empresas utilicen IA avanzada. Los flujos de trabajo complejos que anteriormente eran demasiado costosos para el uso regular son repentinamente más accesibles.
Análisis de rendimiento: Fortalezas y debilidades
He aquí un vistazo a cómo se desempeña en el mundo real, basado en informes de terceros.
Fortaleza: Una herramienta colaborativa para desarrolladores
Los desarrolladores parecen ver a Opus 4.5 menos como una herramienta y más como un compañero de equipo. Una reseña técnica en Medium señaló que realiza "cambios quirúrgicos y dirigidos" en lugar de simplemente reescribir grandes bloques de código, lo que indica una comprensión matizada del código existente.
Su enorme ventana de contexto significa que puede absorber bases de código completas y ceñirse a la documentación oficial. Si usted es un desarrollador que trabaja con nuevos SDK o hardware personalizado, esta es una ventaja significativa. Como un usuario afirmó: "Literalmente, nunca acepto ningún código de ningún modelo si no leyó la documentación primero". Opus 4.5 está diseñado exactamente para eso.
Fortaleza: Manejo de datos empresariales no estructurados
La mayor parte del conocimiento de una empresa no se almacena en una base de datos perfectamente organizada. Está por todas partes: en tickets de soporte, wikis internos y conversaciones interminables de Slack. El "desafío del árbol de Navidad" mostró que Opus 4.5 es hábil para clasificar este tipo de información desordenada.
Esto es exactamente lo que permite a un compañero de equipo de IA como eesel AI captar el tono y las reglas específicas de su empresa. Usted no tiene que configurarlo manualmente ni pasar por una configuración complicada. Simplemente aprende de los datos existentes de su centro de ayuda, tickets antiguos y bases de conocimientos. De esa manera, puede comenzar a resolver problemas correctamente de inmediato, utilizando la voz de su marca.
Fortaleza: Alto nivel de seguridad y confiabilidad
La seguridad es una preocupación importante para cualquier empresa que utilice IA, particularmente cuando se trata de ataques de inyección de prompts (prompt injection). En una prueba para este problema exacto, Opus 4.5 emergió como el modelo más seguro.
Las pruebas de Vellum.ai encontraron que este tipo de ataques solo funcionaron el 4,7% de las veces en Opus 4.5. Esa es una tasa más baja que la de Gemini 3 Pro (12,5%) y GPT-5.1 (21,9%), posicionándolo como una opción más segura para aplicaciones que están de cara al cliente o que manejan información sensible.
Debilidad: Comentarios mixtos sobre el razonamiento abstracto
A pesar de todas sus fortalezas, los comentarios de la comunidad no son del todo positivos. Algunos desarrolladores en Reddit informan que produce "demasiados falsos positivos". De hecho, prefieren competidores como GPT-5.1 Codex, diciendo que está "mucho más listo para producción" y adopta un "enfoque más cuidadoso y sistemático".
Mi problema con Opus es que su enfoque de programación carece de un razonamiento científico y matemático sólido.
Sobresale en seguir un plan de codificación, pero puede desempeñarse de manera menos efectiva en razonamientos altamente abstractos de nivel de doctorado. En el benchmark GPQA Diamond, por ejemplo, Opus 4.5 obtuvo un 82,4%, mientras que su principal rival, GPT-5.1 Codex Max, alcanzó un 89,4%.
La conclusión es que Opus 4.5 parece ser un especialista. Es probable que sea el mejor modelo disponible para llevar a cabo tareas complejas de codificación y de tipo agente, pero no es el mejor en cada tipo de problema abstracto que se le pueda plantear.
Precios y disponibilidad
Repasemos los detalles de precios y accesibilidad.
Un punto de precio más accesible
El precio oficial de la API es de $5 por millón de tokens de entrada y $25 por millón de tokens de salida.
Esto representa una reducción significativa con respecto al antiguo modelo Opus 4.1, que anteriormente costaba $15 por entrada. Este nuevo precio significa que las empresas pueden usarlo todos los días, en lugar de guardarlo para proyectos especiales.
Comparación de precios con otros modelos
Aunque Claude Opus 4.5 es significativamente más barato que la versión anterior, todavía tiene un precio de modelo premium en comparación con sus rivales. Pero debido a que es tan eficiente con los tokens, el costo real de usarlo podría ser menor de lo que usted pensaría simplemente mirando la lista de precios.
Aquí hay un vistazo rápido a cómo se comparan los precios estándar de pago por uso.
| Modelo | Costo de Entrada (por 1M de tokens) | Costo de Salida (por 1M de tokens) |
|---|---|---|
| Claude Opus 4.5 | $5.00 | $25.00 |
| Claude Sonnet 4.5 | $3.00 | $15.00 |
| OpenAI GPT-5.1 | $1.25 | $10.00 |
| Google Gemini 3 Pro | $2.00 | $12.00 |
Datos de precios obtenidos de las páginas oficiales de Anthropic, OpenAI y Google a finales de 2025.
Cómo acceder a Claude Opus 4.5
Usted puede obtener el modelo a través de la API oficial de Claude, las aplicaciones web y de escritorio de Claude, y en grandes plataformas en la nube como AWS Bedrock y Google Cloud Vertex AI.
Si lo utiliza de forma individual o como parte de un equipo, Opus 4.5 está disponible en los planes Max, Team y Enterprise. Por lo que dice la gente, parece que los usuarios Pro podrían necesitar tener activado el "uso extra" o actualizarse a un plan superior para usarlo en todas partes.
Creo que podrías tener activado el uso extra. Rezo por tu cuenta bancaria.
Implicaciones para las empresas
Entonces, ¿qué significa todo esto para su negocio?
El cambio más grande con modelos como Opus 4.5 es que estamos pasando de una IA como un simple "asistente" que solo busca información a un "compañero de equipo de IA" que realmente puede hacer cosas por su cuenta.
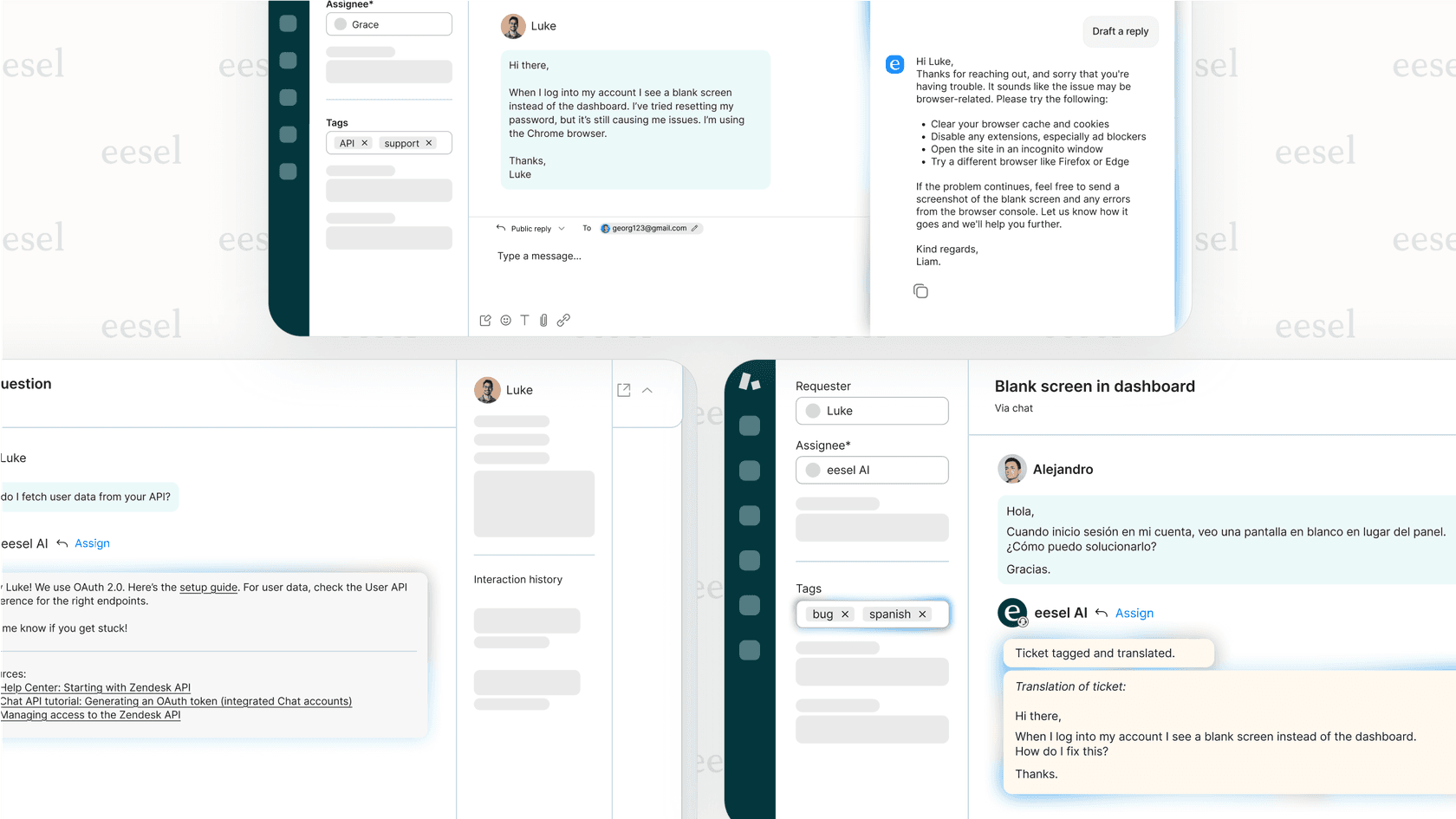
Piénselo en términos de atención al cliente. Una IA más antigua podría simplemente encontrar un artículo de ayuda y enviar un enlace. Una IA que utiliza Opus 4.5 puede comprender el problema del cliente, encontrar su pedido en Shopify, verificar la política de devoluciones en un Google Doc, procesar la devolución utilizando una herramienta interna y luego cerrar el ticket en Zendesk. Se encarga de todo el proceso.
Esta es la idea que impulsa al AI Agent de eesel. En lugar de construir un bot rígido basado en reglas, usted esencialmente "contrata" a un compañero de equipo de IA. Este aprende de las herramientas y los datos que usted ya usa para resolver los problemas de los clientes por sí mismo, y solo involucra a un agente humano cuando realmente se necesita un toque personal.
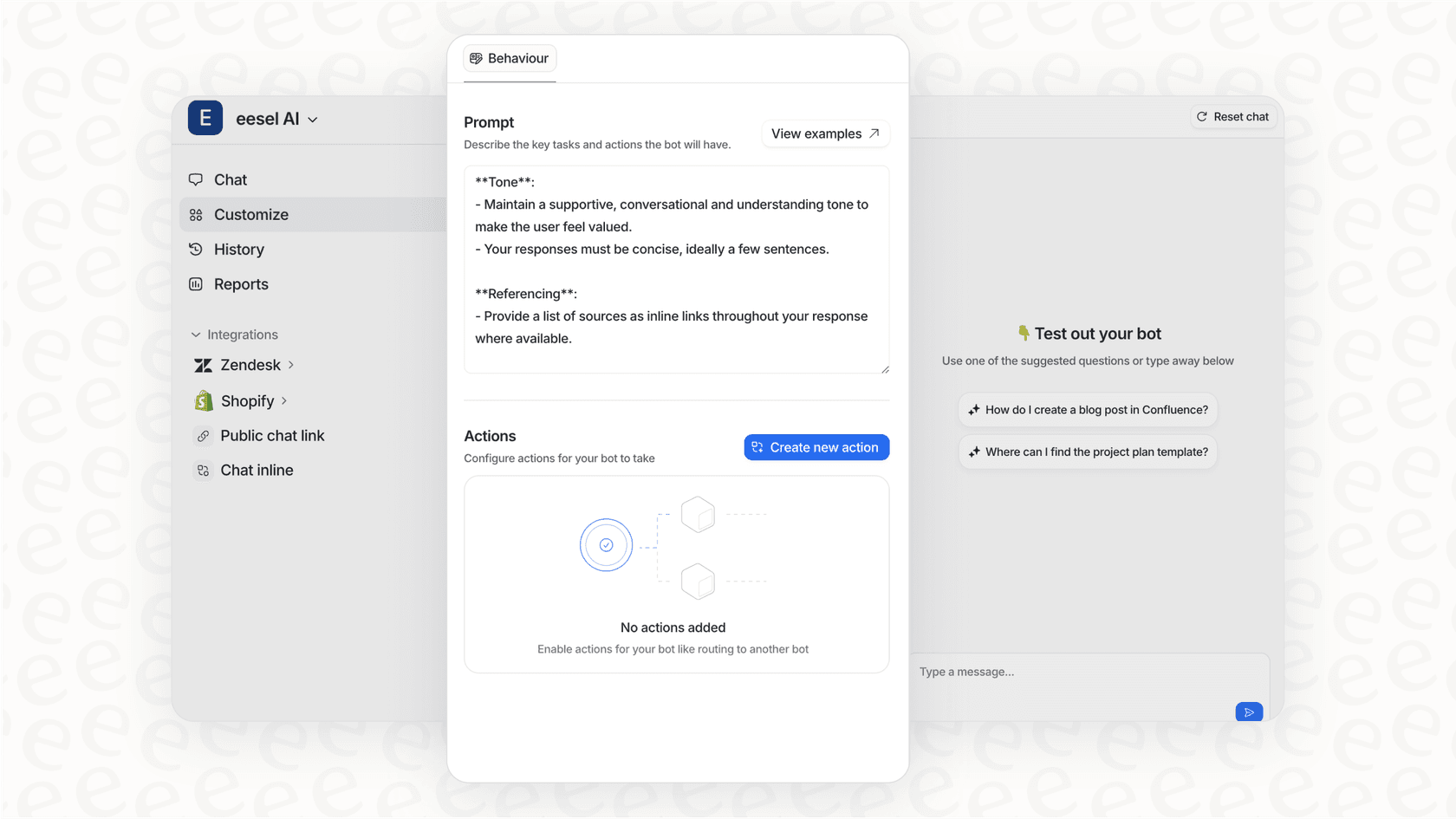
Para ver una demostración en vivo de cómo Claude Opus 4.5 maneja una tarea de ingeniería del mundo real, vea el video a continuación. Proporciona una mirada profunda a las capacidades del modelo cuando se pone a prueba en un desafío de codificación práctico.
El auge del compañero de equipo de IA
Claude Opus 4.5 representa un desarrollo significativo. Sus excelentes habilidades de codificación, su capacidad para manejar tareas largas y automatizadas, y su precio accesible lo convierten en una base sólida para una nueva ola de herramientas de IA.
Más que nada, esto significa un alejamiento de los chatbots básicos y un acercamiento hacia socios de IA reales en los que usted puede confiar para flujos de trabajo empresariales complicados de principio a fin.
El futuro no se trata de reemplazar a su equipo; se trata de complementarlo con compañeros de equipo de IA capaces. Para ver cómo este nuevo tipo de IA puede apoyar a su equipo de servicio al cliente, pruebe eesel AI de forma gratuita.
Preguntas frecuentes
La conclusión principal es que Opus 4.5 actúa más como un socio de programación que como una simple herramienta. Es excelente para comprender bases de código completas, realizar cambios precisos y seguir la documentación, lo que lo hace útil para tareas de desarrollo complejas del mundo real.
No del todo. Si bien es uno de los mejores para la codificación y tareas autónomas de varios pasos, puede quedarse atrás en razonamientos altamente abstractos de nivel de doctorado en comparación con algunos competidores como GPT-5.1 Codex Max. Es más un modelo especialista que uno generalista.
El precio es una mejora significativa. Con un costo de $5 por entrada y $25 por salida por millón de tokens, es sustancialmente más barato que el modelo anterior Opus 4.1. Esta caída de precio lo hace más accesible para que las empresas lo utilicen a diario.
Se destaca la capacidad del modelo para funcionar como un "compañero de equipo de IA", especialmente en atención al cliente. Puede manejar flujos de trabajo complejos de extremo a extremo, como procesar una devolución al [interactuar con múltiples aplicaciones](https://www.mckaywrigley.com/posts/opus-4.5) (Shopify, Zendesk, etc.), yendo más allá de las simples respuestas de un chatbot.
Se considera que tiene una seguridad líder en la industria. Las pruebas muestran que es altamente resistente a los ataques de inyección de prompts (prompt injection), con una tasa de éxito de solo el 4,7% para los atacantes. Esto lo convierte en una opción confiable para aplicaciones de cara al cliente donde la seguridad es una prioridad.
Depende de la tarea. Opus 4.5 es superior para pruebas de rendimiento (benchmarks) de codificación específicos (como SWE-bench) y flujos de trabajo de agentes. Sin embargo, [GPT-5.1 Codex Max obtiene puntuaciones más altas](https://www.reddit.com/r/GeminiAI/comments/1p8tx82/comparing_claude_opus_45_vs_gpt51_vs_gemini_3/) en pruebas de razonamiento abstracto, por lo que el "mejor" modelo depende del caso de uso específico.
Share this article

Article by
Kenneth Pangan
Writer and marketer for over ten years, Kenneth Pangan splits his time between history, politics, and art with plenty of interruptions from his dogs demanding attention.