
Então, você está pensando em usar um LLM (Large Language Model) para ajudar a administrar sua empresa. Essa é uma ótima jogada. Mas sempre surge aquela pergunta persistente: como garantir que ele seja realmente confiável e não apenas uma bomba-relógio de respostas estranhas? Você não pode simplesmente ativar um modelo de linguagem grande (LLM) e cruzar os dedos.
Se você não testar adequadamente, sua IA pode começar a fornecer informações incorretas, adotar um tom bizarro totalmente fora da marca ou simplesmente não seguir instruções simples. Tudo isso se soma a uma péssima experiência do cliente. É por isso que ter uma maneira sólida de testar sua IA não é apenas um "bom ter", é essencial.
Para lidar com isso, a OpenAI criou uma estrutura chamada OpenAI Evaluation (Avaliação da OpenAI). Este guia irá te mostrar o que é, como o pessoal da tecnologia a usa e por que provavelmente não é a ferramenta certa para a maioria das equipes de negócios. Também veremos como plataformas como eesel AI oferecem um caminho muito mais direto para implantar IA em que você pode realmente confiar.
O que é OpenAI Evaluation?
Em termos simples, OpenAI Evaluation (ou "Evals", como é frequentemente chamado) é um kit de ferramentas para desenvolvedores criarem e executarem testes em modelos de linguagem. É como eles verificam se os prompts que estão escrevendo ou os modelos que estão ajustando estão realmente fazendo o que deveriam. Pense nisso como uma verificação de qualidade para sua IA, garantindo que, ao atualizar algo, você não quebre acidentalmente outras cinco coisas.
Existem dois tipos principais desses testes:
-
Verificações baseadas em código: São para as coisas preto no branco. Um desenvolvedor pode escrever um teste para ver se a saída do modelo inclui uma palavra específica, se está formatada de uma certa maneira (como JSON) ou se classifica corretamente algo em uma categoria. É perfeito para quando há uma resposta certa ou errada clara.
-
Verificações classificadas por IA: É aqui que as coisas ficam um pouco mais interessantes. Você pode usar uma IA realmente poderosa (como GPT-4o) para julgar o trabalho de outra IA. Por exemplo, você pode pedir para ela classificar o quão "amigável" ou "útil" é uma resposta de suporte ao cliente. É basicamente como ter um supervisor de IA revisando a lição de casa de outra IA.
O objetivo de usar o OpenAI Evals é obter números concretos sobre como sua IA está funcionando. Isso ajuda as equipes a ver se estão progredindo e, mais importante, a detectar quaisquer erros antes que afetem seus clientes. É uma prática crucial para quem está construindo ferramentas de IA sérias, mas também é profundamente técnica.
Como funciona uma OpenAI Evaluation padrão
Colocar uma OpenAI Evaluation padrão em funcionamento é um trabalho para um desenvolvedor. Para te dar uma noção real, vamos analisar um exemplo comum da própria documentação da OpenAI: classificar tickets de suporte de TI.
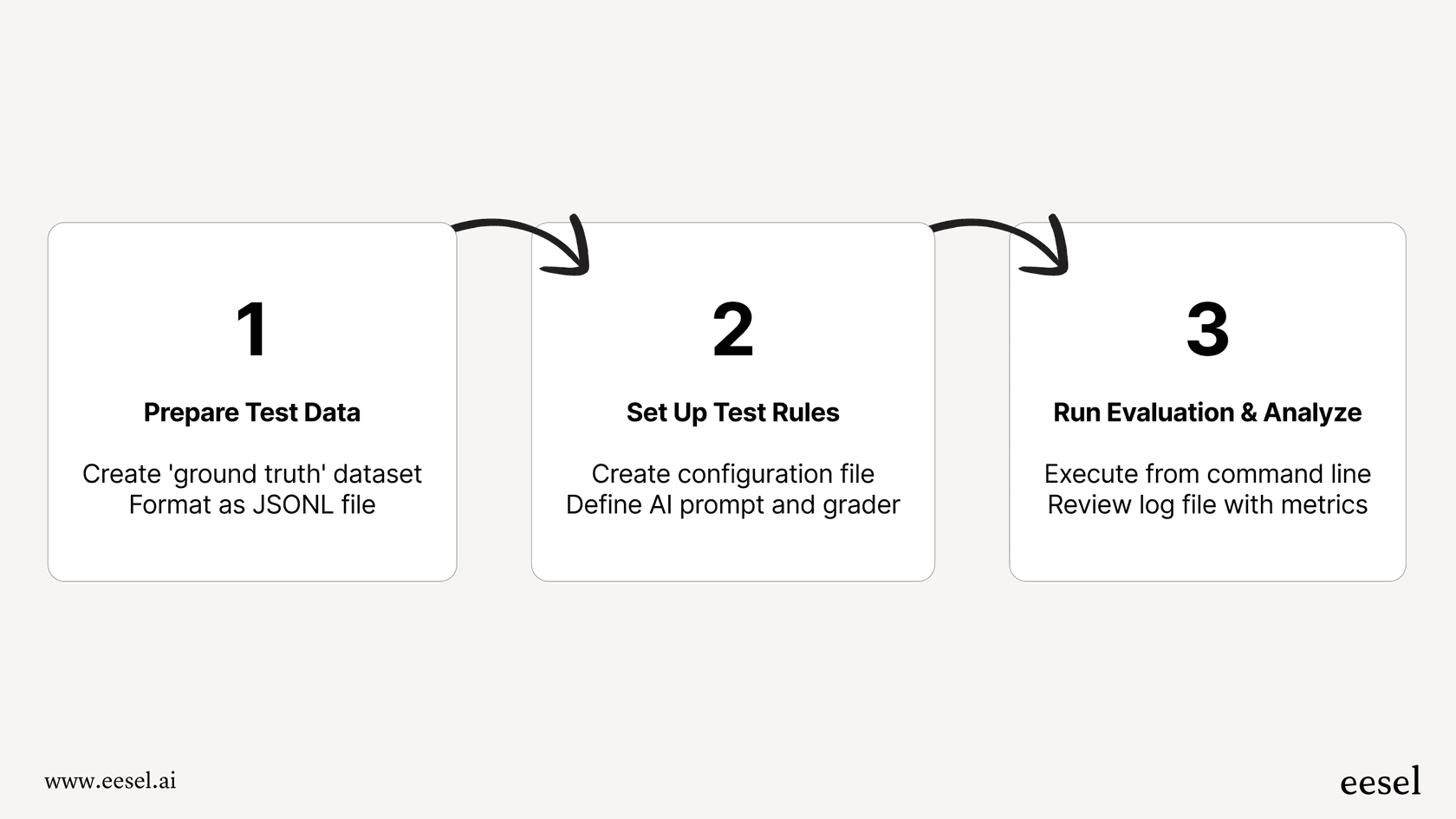
Passo 1: Prepare seus dados de teste
Primeiro, você precisa do que é chamado de conjunto de dados de "verdade fundamental" (ground truth). Este é apenas um termo sofisticado para um gabarito de respostas. É um arquivo cheio de perguntas de amostra combinadas com as respostas perfeitas. O problema? Este arquivo precisa estar em um formato muito específico chamado "JSONL" (JSON Lines).
Para nosso exemplo de classificação de tickets, algumas linhas nesse arquivo podem ser assim:
{ "item": { "ticket_text": "Meu monitor não liga!", "correct_label": "Hardware" } }
{ "item": { "ticket_text": "Estou no vim e não consigo sair!", "correct_label": "Software" } }
Agora, criar este arquivo não é uma coisa que se faz uma vez e pronto. Alguém tem que criá-lo manualmente, limpá-lo e garantir que esteja formatado perfeitamente. Para uma tarefa simples, isso pode ser bom. Mas se você estiver lidando com problemas complexos de clientes, construir um bom conjunto de dados pode ser um projeto enorme por si só.
Passo 2: Defina as regras de teste
Em seguida, um desenvolvedor deve criar um arquivo de configuração que diga à ferramenta de avaliação como testar o modelo. Este arquivo define o prompt que é enviado para a IA e o "avaliador" que verificará a resposta da IA em relação ao seu gabarito de respostas.
Para nosso exemplo de ticket, o teste pode usar um avaliador simples que apenas verifica se a saída da IA corresponde exatamente ao "correct_label" no conjunto de dados. Esta etapa envolve conhecer códigos especiais e espaços reservados para extrair dados do arquivo de teste para o próprio teste.
Passo 3: Execute a avaliação e veja o que aconteceu
Finalmente, o desenvolvedor inicia a avaliação a partir de sua linha de comando. O sistema então passa por cada item em seu conjunto de dados, envia o prompt para o modelo, obtém uma resposta de volta e a avalia.

O resultado geralmente é um arquivo de log, uma parede de texto cheia de dados e métricas como quantos testes "passaram", "falharam" e a "precisão" geral. Esses números te dizem o que aconteceu, mas não te dão muita informação sobre por que algo falhou sem uma investigação séria. É um sistema poderoso, mas definitivamente não foi construído para o usuário médio.
Razões comuns para usar OpenAI Evaluation
Mesmo que a configuração seja um pouco problemática, as razões por trás disso são muito práticas. O teste adequado é o que transforma uma demonstração divertida de IA em uma ferramenta na qual você pode confiar para sua empresa.
-
Mantendo os fatos: Esta é uma grande questão. Você precisa garantir que sua IA esteja fornecendo informações corretas com base em sua base de conhecimento, seja sobre detalhes do produto ou sua política de devolução. Um eval pode verificar se as respostas da IA realmente correspondem aos seus documentos oficiais.
-
Seguindo as instruções: Muitos fluxos de trabalho de IA precisam que a saída seja estruturada de uma maneira específica. Os evals podem confirmar se sua IA pode fazer coisas como gerar JSON limpo para outro sistema usar ou marcar um ticket de suporte com a categoria certa de sua lista.
-
Acertando o tom: Uma resposta de suporte pode ser 100% correta, mas ainda soar robótica e fria. Os evals classificados por IA podem te ajudar a verificar se o tom da IA corresponde à voz de sua marca. Você pode perguntar ao avaliador: "Esta resposta soa empática e profissional?" para manter a experiência do cliente consistente.
-
Permanecendo seguro e justo: Em uma escala maior, os desenvolvedores usam esses mesmos métodos para testar problemas de segurança. Os evals ajudam a garantir que os modelos não estejam gerando conteúdo prejudicial, tendencioso ou inadequado, o que é obviamente crítico para qualquer ferramenta de IA responsável.
Os limites do OpenAI Evaluation para empresas
OpenAI Evaluation é uma ferramenta fantástica para os desenvolvedores que estão construindo IA. Mas para as equipes de negócios que têm que gerenciar essa IA todos os dias, ela vem com algumas desvantagens bem grandes.
Por que o OpenAI Evaluation é para desenvolvedores, não para sua equipe de suporte
Todo o processo, desde a criação de arquivos "JSONL" até a leitura de dados de log, é complicado e requer habilidades de codificação. Você precisa de engenheiros para configurá-lo e mantê-lo funcionando. Essa é uma enorme barreira para os gerentes de suporte ou líderes de TI que são realmente responsáveis pelo desempenho da IA. Eles precisam saber se a IA está fazendo seu trabalho, mas você não pode esperar que eles aprendam a programar só para descobrir.
O que as equipes de suporte realmente precisam: Em vez de uma ferramenta que vive na linha de comando, as equipes de negócios precisam de algo projetado para elas. Por exemplo, eesel AI tem um modo de simulação que te permite testar sua IA em milhares de seus tickets de suporte reais e históricos com apenas alguns cliques. Sem código, sem complicações. Você obtém relatórios visuais simples mostrando o que você pode esperar automatizar e pode ver exatamente como a IA teria respondido.

Por que criar dados de teste à mão é um beco sem saída
Construir e atualizar um bom conjunto de dados de teste é uma tarefa interminável. Os problemas de seus clientes estão sempre mudando à medida que você lança novos produtos ou altera suas políticas. Um arquivo de teste estático que você fez em janeiro estará irremediavelmente desatualizado em março, o que torna seus testes praticamente sem sentido.
Uma abordagem melhor: Sua IA deve aprender com a realidade, não com um arquivo que alguém fez meses atrás. eesel AI se conecta diretamente ao seu help desk (como Zendesk ou Freshdesk) e suas fontes de conhecimento. Ele treina e testa em seus tickets e artigos da central de ajuda reais desde o início. Seu conjunto de dados de teste são seus dados reais e ativos, então seus testes são sempre relevantes sem nenhum trabalho extra.

Por que apenas testar o texto não é o quadro completo
Uma OpenAI Evaluation padrão é ótima para verificar se uma resposta de texto está correta. Mas em uma situação de suporte real, as palavras são apenas uma parte do quebra-cabeça. Um ótimo agente de IA não apenas responde a uma pergunta; ele faz algo. O eval padrão não pode te dizer se a IA fez coisas com sucesso como marcar um ticket como urgente, escalá-lo para uma pessoa ou procurar um status de pedido no Shopify.
Teste todo o fluxo de trabalho: Você precisa testar todo o processo, não apenas as palavras. Com o mecanismo de fluxo de trabalho personalizável no eesel AI, você pode construir e testar essas ações diretamente dentro da simulação. Você pode ver não apenas o que a IA teria dito, mas também o que ela teria feito. Isso te dá uma imagem completa de seu desempenho para que você possa se sentir bem em automatizar processos inteiros, não apenas trechos de texto.

Entendendo o preço da API para OpenAI Evaluation
Embora a estrutura OpenAI Evals seja de código aberto, executar os testes terá um custo. Cada teste que você executa usa tokens de API, e isso se soma à sua conta. Você paga por cada prompt que envia para o modelo que está testando e por cada resposta que ele gera. Isso é especialmente verdade quando você usa evals classificados por IA, já que você está pagando por um segundo modelo, mais poderoso, para fazer a classificação.
Aqui está uma olhada rápida nos custos de pagamento conforme o uso para alguns dos modelos da OpenAI:
| Modelo | Entrada (por 1M de tokens) | Saída (por 1M de tokens) |
|---|---|---|
| "gpt-4o-mini" | $0.15 | $0.60 |
| "gpt-4o" | $5.00 | $15.00 |
| "gpt-5-mini" | $0.25 | $2.00 |
| "gpt-5" | $1.25 | $10.00 |
Os preços podem mudar, por isso é sempre uma boa ideia verificar a página oficial de preços da OpenAI para obter os detalhes mais recentes.
Uma maneira mais previsível: Este preço baseado em token pode levar a algumas surpresas desagradáveis em sua conta mensal, especialmente se você estiver executando muitos testes. Em contrapartida, eesel AI oferece preços previsíveis. Os planos são baseados em um número definido de interações de IA por mês, e todos os testes que você faz no modo de simulação estão incluídos. Isso torna o orçamento para suas ferramentas de IA muito mais simples, sem custos ocultos para garantir que sua IA esteja pronta para uso.

Vá além do OpenAI Evaluation e comece a automatizar
OpenAI Evaluation é um grande negócio para desenvolvedores que constroem com LLMs. Ele prova que testes sérios e metódicos não são apenas uma etapa extra, eles estão no centro da construção de IA de forma responsável. No entanto, como é tão técnico e focado em desenvolvedores, simplesmente não é prático para a maioria das equipes de negócios que precisam gerenciar IA para coisas como suporte ao cliente ou help desks internos.
O futuro da IA nos negócios não é apenas sobre poder bruto; é sobre tornar esse poder seguro, confiável e fácil para qualquer pessoa gerenciar. Isso significa que você precisa de ferramentas de teste que sejam integradas à sua plataforma, fáceis de usar e projetadas para as pessoas que as usarão todos os dias.
Em vez de gastar meses tentando construir um sistema de teste complexo e pesado em código, você pode obter todos os benefícios em apenas alguns minutos. Inscreva-se no eesel AI e execute uma simulação gratuita em seus próprios dados. Você verá exatamente o que pode automatizar e pode lançar seus agentes de IA se sentindo completamente confiante.
Perguntas frequentes
OpenAI Evaluation, frequentemente chamado de Evals, é um conjunto de ferramentas projetado para que desenvolvedores criem e executem testes em modelos de linguagem. Seu principal propósito é verificar a qualidade dos modelos de IA, garantindo que eles tenham o desempenho esperado e identificando quaisquer regressões durante as atualizações.
Todo o processo de OpenAI Evaluation, desde a criação de arquivos "JSONL" específicos até a interpretação de dados de log complexos, requer habilidades de codificação e expertise técnica. Isso torna desafiador para equipes de negócios não técnicas, como gerentes de suporte, configurar, executar e gerenciar com eficácia.
Primeiro, um desenvolvedor prepara um conjunto de dados de "verdade fundamental" (ground truth) de perguntas e respostas corretas no formato "JSONL". Em seguida, eles criam um arquivo de configuração definindo o prompt de IA e as regras do avaliador. Finalmente, a avaliação é executada a partir da linha de comando, gerando arquivos de log com métricas de desempenho como precisão.
Uma limitação significativa é a necessidade de criar e atualizar manualmente os conjuntos de dados de teste, que rapidamente se tornam desatualizados à medida que as necessidades de negócios mudam. Isso torna a manutenção de testes relevantes e abrangentes uma tarefa contínua e intensiva em recursos para as empresas.
Sim, a execução de testes com OpenAI Evaluation acarreta custos porque usa tokens de API para cada prompt enviado e resposta gerada pelos modelos. O preço é normalmente pago conforme o uso, com base no número de tokens de entrada e saída, o que pode levar a contas mensais imprevisíveis.
O OpenAI Evaluation padrão é excelente para verificar respostas de texto, mas não testa inerentemente um fluxo de trabalho completo ou ações que uma IA possa tomar, como marcar tickets ou procurar status de pedidos. Ele se concentra principalmente na correção de respostas verbais ou textuais.
Share this article

Article by
Stevia Putri
Stevia Putri é uma generalista de marketing na eesel AI, onde ajuda a transformar ferramentas poderosas de IA em histórias que ressoam. Ela é movida por curiosidade, clareza e o lado humano da tecnologia.

