
Há muito entusiasmo em torno da API Realtime da OpenAI e, honestamente, faz sentido. A ideia de construir agentes de voz super-responsivos e semelhantes a humanos é bastante empolgante. O modelo que recebe a maior parte da atenção é o "gpt-4o-mini-realtime", principalmente porque promete um desempenho sólido a um preço que parece irrisório.
Mas há um porém. Assim que consulta a página de preços, depara-se com jargões como "por milhão de tokens" para texto, áudio e algo chamado "cached inputs" (entradas em cache). Isto deixa a maioria de nós a coçar a cabeça e a fazer a mesma pergunta: "Ok, mas quanto é que isso me custa realmente por minuto?"
Se está a tentar perceber se um projeto é viável ou apenas a tentar definir um orçamento, a definição de preços baseada em tokens é uma verdadeira dor de cabeça. Por isso, decidimos fazer as contas por si. Este guia detalha o verdadeiro custo de usar o GPT realtime mini, revelando os fatores ocultos que podem fazer com que as suas despesas disparem quando menos espera.
Compreender a API Realtime da OpenAI
Antes de passarmos aos números, vamos alinhar o nosso entendimento. A API Realtime da OpenAI é uma ferramenta para programadores que querem criar aplicações com conversas rápidas de voz para voz. Basicamente, permite-lhe criar uma IA que consegue ouvir e responder quase instantaneamente, sem o atraso constrangedor que se verifica com tecnologias mais antigas.
Foi concebida para potenciar agentes de voz. Pense numa IA que pode gerir chamadas de apoio ao cliente, marcar compromissos ou responder a perguntas internas da sua equipa, tudo isto soando de forma natural.
A API oferece alguns modelos para trabalhar. Existe o potente "gpt-4o-realtime" para conversas mais complicadas e o seu irmão mais barato e rápido, "gpt-4o-mini-realtime". Estamos a focar-nos na versão mini aqui porque o seu baixo preço de tabela a torna o ponto de partida preferido para muitas pessoas.
O problema com a definição de preços baseada em tokens da OpenAI
A OpenAI cobra por cada "token" que a sua aplicação utiliza. Um token é apenas uma pequena porção de dados, pode ser uma palavra, uma sílaba ou um pouco de áudio. O custo baseia-se no número de tokens que envia para o modelo (entrada) e no número que este lhe envia de volta (saída).
Eis os preços oficiais do GPT realtime mini da página de preços da OpenAI:
| Modelo e Tipo de Token | Preço de Entrada (por 1M de tokens) | Preço de Saída (por 1M de tokens) |
|---|---|---|
| gpt-4o-mini-realtime-preview | ||
| Texto | 0,60 $ | 2,40 $ |
| Áudio | 10,00 $ | 20,00 $ |
| Entrada de Áudio em Cache | 0,30 $ | N/A |
Estes números parecem minúsculos, certo? Mas este modelo torna incrivelmente difícil prever os seus custos por várias razões:
-
A duração das chamadas é muito variável. Uma conversa rápida de um minuto usa muito menos tokens do que uma chamada de suporte complexa de dez minutos. Como é que se pode prever a média?
-
A relação entre entrada e saída muda. Um cliente falador e uma IA silenciosa custarão menos do que um cliente silencioso que precisa de explicações longas e detalhadas da IA.
-
Prompts de Sistema: O Custo Oculto. Este é o ponto principal. Para fazer um agente de voz fazer algo útil, tem de lhe dar instruções. Este "prompt de sistema" diz à IA quem é, qual é o seu trabalho e como deve agir. Todo este bloco de texto é enviado como tokens de entrada em todas as interações da conversa. Um prompt detalhado pode facilmente duplicar ou triplicar os seus custos, e pode nem se aperceber até a fatura chegar.
-
É uma mistura de áudio e texto. A API está constantemente a gerir tokens de áudio (o que o utilizador diz) e tokens de texto (o que a IA processa e diz de volta), e cada um tem o seu próprio preço. Esta mistura transforma uma simples estimativa de custos num jogo de adivinhação.
Uma análise prática do custo por minuto
Para ultrapassar a teoria, realizámos alguns testes para ver como estes custos de tokens se traduzem em dólares por minuto. Usámos o OpenAI Playground para simular conversas, uma vez que fornece dados de custos em tempo real.
Comparámos tanto o modelo "gpt-4o-mini-realtime" como o mais robusto "gpt-4o-realtime". Para cada um, testámos uma conversa básica e depois outra com um prompt de sistema de 1000 palavras, uma configuração realista para qualquer empresa que precise que a sua IA conheça produtos ou siga um guião.
Os resultados foram bastante surpreendentes.
| Modelo e Configuração | Custo Médio por Minuto | Porque é que isto é Importante |
|---|---|---|
| GPT-4o mini (Sem Prompt de Sistema) | ~$0.16 | Parece barato, mas uma IA sem instruções não é útil para uma empresa. |
| GPT-4o mini (Com Prompt de Sistema de 1000 palavras) | ~$0.33 | O custo mais do que duplica apenas por dar à IA um manual de instruções básico. |
| GPT-4o (Sem Prompt de Sistema) | ~$0.18 | Um pouco mais caro, mas lida melhor com conversas complexas e de vários passos. |
| GPT-4o (Com Prompt de Sistema de 1000 palavras) | ~$1.63 | O custo aumenta mais de 800%. É exatamente assim que os orçamentos são destruídos. |
A principal conclusão aqui é que o preço anunciado do GPT realtime mini é apenas o ponto de partida. O seu custo real é quase inteiramente determinado pela forma como configura o seu agente. Esse prompt de sistema, que é absolutamente necessário para qualquer caso de uso empresarial, é o maior fator que aumenta a sua fatura. Esta volatilidade torna difícil orçamentar e escalar um projeto de IA de voz.
Para além das taxas da API: os outros custos de construir um agente de IA de voz
A fatura da API é apenas uma parte da equação. Se está a planear construir um agente de voz de raiz com a API Realtime, os custos reais estão escondidos nas horas de engenharia necessárias para o preparar para os clientes.
Como a engenharia de prompts afeta os seus custos
Fazer com que uma IA siga instruções de forma fiável é mais difícil do que parece. Escrever um bom prompt de sistema envolve muita tentativa e erro. Um prompt mal feito leva a uma IA confusa, o que leva a clientes frustrados e dinheiro pelo cano abaixo.
E não é apenas o prompt. Tem de fornecer à IA a informação correta. Isso significa construir um sistema para a conectar aos artigos do seu centro de ajuda, wikis internos e documentação de produtos. Este é um grande esforço de engenharia que requer a configuração de pipelines de dados e sistemas de recuperação.
É aqui que uma ferramenta como a eesel AI se torna útil. Oferece-lhe um editor de prompts simples e conecta-se automaticamente às suas fontes de conhecimento. Pode ligar o seu Zendesk, Confluence ou Google Docs em apenas alguns cliques, sem necessidade de programação.

Custos de integração
Um agente de voz que não consegue realmente fazer nada não ajuda muito. Para ser útil, tem de se conectar aos seus outros sistemas empresariais. Precisa de ser capaz de criar um ticket no seu helpdesk, verificar o estado de uma encomenda no Shopify ou transferir uma conversa para um humano no Slack.
Construir estas integrações por conta própria significa código personalizado, gestão de chaves de API e tratamento da autenticação para cada ferramenta. É imenso trabalho, e tem de o manter para sempre. Em contraste, a eesel AI tem integrações de um clique com dezenas de ferramentas empresariais comuns, permitindo que o seu agente atue desde o primeiro dia sem que tenha de escrever qualquer código.

O risco de lançar sem testes adequados: um custo oculto
Como sabe se o seu agente está pronto para o público antes de o deixar falar com clientes reais? Se o está a construir por conta própria, a resposta honesta é muitas vezes: não sabe.
Configurar um ambiente de testes adequado para simular conversas reais em escala é um projeto enorme por si só. Mas não vai querer libertar uma IA não testada sobre a sua base de clientes. É um risco enorme para a sua reputação.
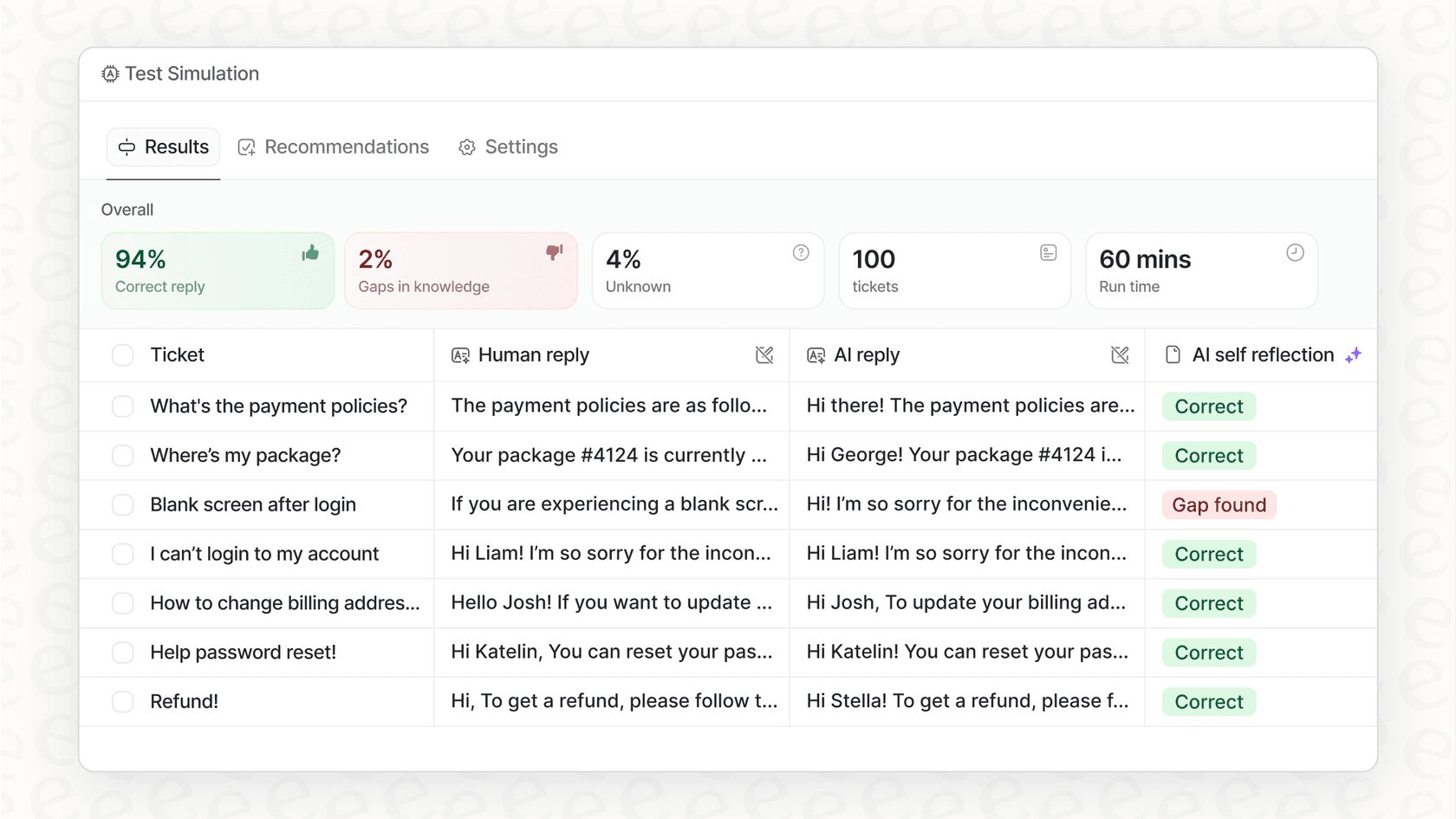
O agente de IA da eesel AI ajuda a resolver isto com um modo de simulação. Pode testar o seu agente contra milhares das suas conversas de suporte passadas para ver exatamente como ele as teria tratado. Isto dá-lhe uma visão clara e baseada em dados de como ele se irá comportar e qual poderá ser o seu retorno sobre o investimento, para que possa lançá-lo com confiança.
Uma alternativa mais inteligente: custos previsíveis e implementação mais rápida
Em vez de lutar com tokens e construir tudo de raiz, usar uma plataforma de IA tudo-em-um é um caminho muito melhor para a maioria das equipas. Não é apenas mais barato a longo prazo; é também muito mais rápido.
Fique operacional numa tarde
Um agente de voz personalizado pode levar semanas ou até meses a ser construído por uma equipa de engenheiros. Com a eesel AI, pode estar a funcionar por conta própria em poucas horas. Toda a plataforma foi construída para ser self-service. Pode conectar o seu conhecimento, configurar a personalidade e as regras do seu agente, e executar simulações sem nunca ter de agendar uma demonstração.
Obtenha controlo com preços previsíveis e transparentes
O maior problema de usar a API diretamente é que nunca sabe qual será a sua fatura. Uma semana movimentada pode resultar numa fatura surpreendentemente alta. A eesel AI oferece planos transparentes baseados num número fixo de interações de IA mensais. Sabe exatamente o que está a pagar todos os meses, por isso não há surpresas desagradáveis.
Além disso, obtém um controlo detalhado. Pode configurar regras que definem exatamente quais as perguntas que a IA trata e quais são enviadas diretamente para um humano. Isto permite-lhe começar pequeno, automatizando primeiro as tarefas fáceis e repetitivas, e depois escalar com confiança à medida que avança, tudo isto mantendo os seus custos sob controlo.

De preços confusos a valor de negócio claro
Embora o preço bruto do GPT realtime mini pareça barato à superfície, a realidade da faturação baseada em tokens é uma montanha-russa de custos imprevisíveis. Além disso, as taxas da API são apenas uma pequena fatia do verdadeiro custo de construir um agente de voz. O investimento real é a montanha de trabalho de engenharia necessária para ajuste de prompts, integrações e testes.
Uma plataforma como a eesel AI oferece uma abordagem muito mais sensata. Utiliza modelos potentes como o GPT-4o mini, mas trata de toda a complexidade por si. Ao oferecer uma plataforma self-service com integrações de um clique, testes potentes e preços previsíveis, a eesel AI dá-lhe uma forma mais rápida, segura e económica de lançar agentes de IA que realmente ajudam o seu negócio.
Pronto para ver como pode ser simples? Deixe de se preocupar com tokens e comece a automatizar. Experimente a eesel AI gratuitamente e tenha o seu primeiro agente operacional em minutos.
Perguntas frequentes
A faturação baseada em tokens torna difícil prever os custos porque variáveis como a duração das chamadas, a relação entre entradas e saídas e a inclusão constante de prompts de sistema flutuam significativamente. Estes fatores combinam-se para tornar a previsão das suas despesas um desafio substancial.
Os prompts de sistema podem aumentar drasticamente os custos porque são enviados como tokens de entrada a cada interação numa conversa. Os nossos testes mostraram que um prompt detalhado de 1000 palavras pode mais do que duplicar o custo por minuto em comparação com um agente sem instruções.
A nossa análise prática descobriu que, com um prompt de sistema necessário de 1000 palavras, o custo médio do GPT-4o mini pode rondar os 0,33 $ por minuto. Embora um cenário sem prompt seja mais barato, a cerca de 0,16 $, não representa uma aplicação empresarial útil.
Para além das taxas da API, os custos ocultos significativos incluem extensas horas de engenharia para ajuste de prompts, construção de integrações complexas com sistemas empresariais existentes e desenvolvimento de ambientes de teste adequados. Estes esforços são cruciais, mas muitas vezes esquecidos nas estimativas de custos iniciais.
Sim, plataformas de IA tudo-em-um como a eesel AI oferecem planos de preços transparentes e previsíveis, normalmente baseados num número fixo de interações de IA mensais. Esta abordagem elimina a volatilidade da faturação baseada em tokens, permitindo uma melhor gestão do orçamento e sem faturas surpreendentes.
Plataformas como a eesel AI reduzem drasticamente o tempo e o esforço de implementação através de configuração self-service, integrações de um clique e funcionalidades de teste incorporadas. Isto permite que as equipas coloquem agentes em funcionamento em horas, em vez de semanas ou meses de desenvolvimento personalizado, simplificando a gestão de custos e as operações.
Share this article

Article by
Kenneth Pangan
Writer and marketer for over ten years, Kenneth Pangan splits his time between history, politics, and art with plenty of interruptions from his dogs demanding attention.