Zendeskエンティティ検知の実践ガイド:機能、ヒント、代替案
Stevia Putri
Katelin Teen
最終更新 January 12, 2026

2026年にサポートチームを運営しているなら、効率的にスケールさせる方法を探していることでしょう。チケットの量が増え、顧客がより迅速な解決を期待するようになるにつれ、主要なプロセスを自動化する能力は大きな競争優位性となります。
このようなよりスマートな自動化への欲求こそが、多くのチームがZendeskの素晴らしい機能に注目する理由です。Zendeskは、Zendeskエンティティ検知(entity detection)を含む洗練されたAIスイートを提供しています。この機能は、チケットを自動的に分類・転送し、適切なタイミングで適切なエージェントに確実に届けるための信頼できる方法です。
本記事では、この機能が何を提供するのか、成功させるための設定方法、そして他の柔軟なAIツールとともに現代のサポートエコシステムにどのように適合するのかを見ていきましょう。
Zendeskエンティティ検知とは?
Zendeskエンティティ検知は、インテリジェントトライアージ(Intelligent Triage)ツール内の堅牢な機能です。Zendesk AIパッケージのコア部分として、顧客のチケットから重要な情報を自動的に特定・抽出するという主要な役割を担っています。
これは、メッセージをスキャンして、製品名、注文ID、特定のサービスリクエストなど、ビジネスをより円滑に運営するのに役立つあらゆる重要なデータポイントを探し出す、専門のアシスタントのようなものだと考えてください。
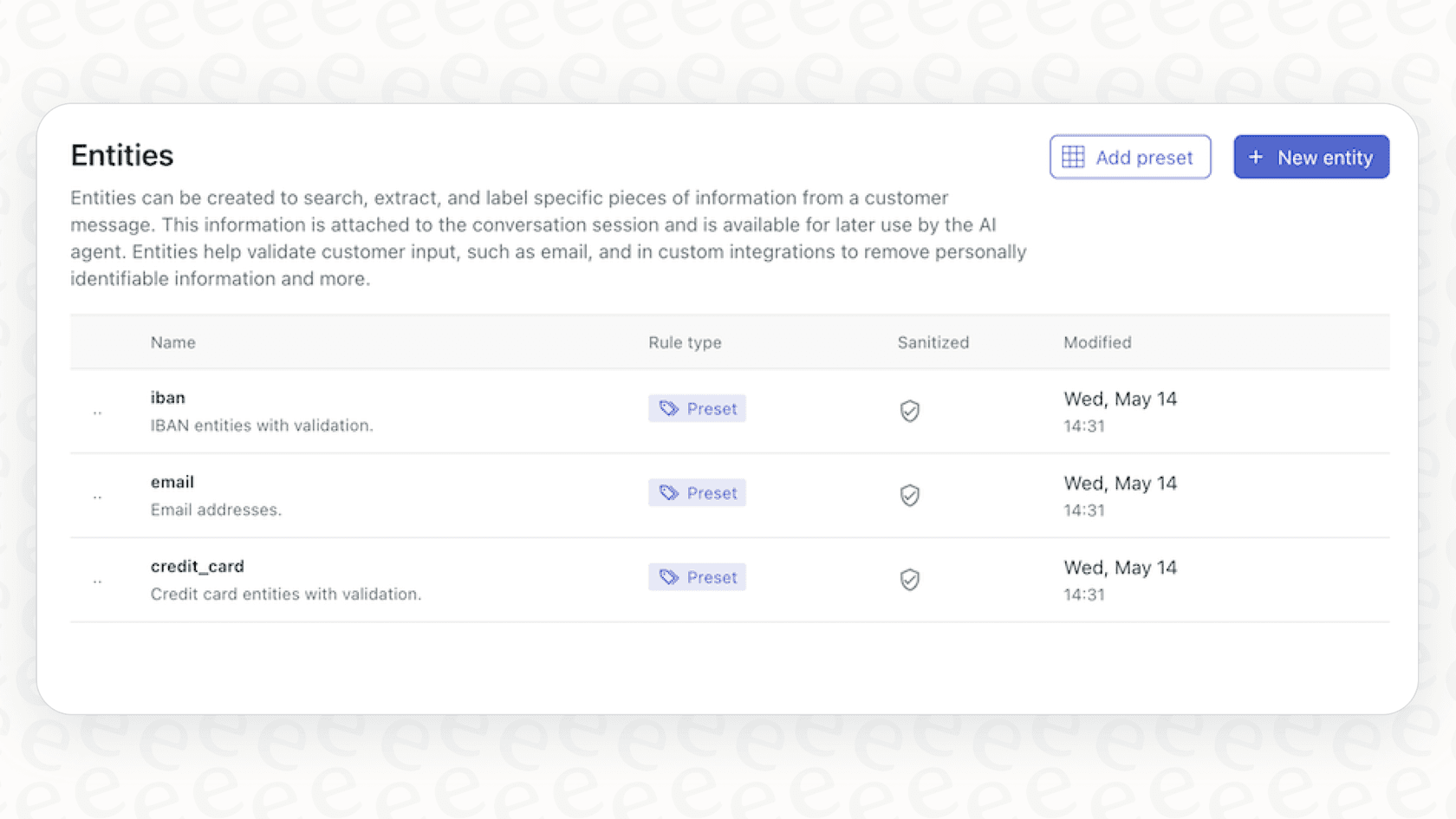
このシステムは、これらの「エンティティ」を、Zendesk環境ですでに構築されているカスタムチケットフィールドにリンクさせることで機能します。ドロップダウンやマルチセレクトなどのフィールドを自動入力することで、特定のチームへのチケットルーティングや緊急問題のハイライトといった、強力な自動ワークフローを可能にします。これは、プロフェッショナルなヘルプデスクにとって不可欠なツールです。
Zendeskエンティティ検知の設定と管理方法
Zendeskでのエンティティ検知の設定は、管理者がデータの取り扱い方法を高度に制御できる、わかりやすいプロセスです。
Zendeskエンティティ検知の基礎:カスタムフィールドからエンティティを作成する
設定プロセスは、エンティティをカスタムチケットフィールドに紐付けることから始まります。これは、追跡したい特定のデータポイントを定義する管理パネル(Admin Center)で行います。
Zendeskはこの目的のために、いくつかの汎用性の高いフィールドタイプを提供しています:
-
ドロップダウン & マルチセレクト: 製品モデル、サブスクリプション層、または一般的な問い合わせカテゴリのセットリストなど、標準化されたデータに最適です。
-
正規表現(Regex): 注文番号や追跡IDなど、予測可能なパターンに従うデータの場合、Zendeskでは正規表現(Regex)によるマッチングが可能です。これは、特定のデータ形式を持つチームに驚異的な精度を提供する高度な機能です。
この構造化されたアプローチにより、収集されるデータはクリーンで一貫したものになります。これは、高品質なレポート作成と信頼性の高い自動化に不可欠です。
同義語とルールによるZendeskエンティティ検知の微調整
システムをさらに効果的にするために、Zendeskは顧客の言葉をどのように解釈するかを洗練させるツールを提供しています。
同義語(synonyms)を追加して、さまざまな言い回しが同じ結果につながるように設定できます。たとえば、「注文番号」、「ID」、「取引番号」をすべて注文IDエンティティにマッピングできます。これにより、顧客の話し方の自然なバリエーションをシステムが捉えるのに役立ちます。
また、抽出ルール(extraction rules)を設定することもできます。システムが最初のメッセージに焦点を当てるべきか、あるいは会話の後半で顧客が新しい情報を提供した場合にフィールドを更新すべきかを決定できます。このレベルのカスタマイズにより、ツールを特定のサポートロジックに適合させることができます。
さらに、スペルミス検知機能は、5文字以上の単語の軽微な誤りをキャッチするのに役立ち、一般的なタイプミスに対しても有用な精度レイヤーを提供します。
戦略的なエンティティ管理
エンティティを管理する際、少しの計画が大きな効果をもたらします。Zendeskは、リストで設定した順序に基づいてエンティティをスキャンします。最高の精度を確保するために、多くの管理者はより具体的なルールをリストの上位に配置することが役立つと考えています。
たとえば、特定の「製品プロ」モデルのルールと一般的な「製品」ルールがある場合、具体的な方を上位に置くことで、「製品プロ」に関するチケットが毎回正しくタグ付けされるようになります。この論理的な構造により、チケットがどのように処理されているかについて完全な透明性が得られます。
Zendeskエンティティ検知の一般的なユースケースと主な強み
成熟した信頼性の高いプラットフォームとして、Zendeskのエンティティ検知は、サポート自動化のための安定した基盤を提供することに長けています。
Zendeskエンティティ検知が得意なこと
コアなサポート機能において、Zendeskエンティティ検知は非常に効果的なツールです。
-
チケットの自動ルーティング: これはこのツールが最も得意とする分野です。特定の製品エンティティを検知することで、トリガが即座にチケットを適切な部門に自動送信できます。
-
チケットの優先度設定: 「重大なエラー」に関連するエンティティが検知された場合、そのチケットをキューの最上位に移動して即座に対応するように設定できます。
-
レポート作成: 標準フィールドにデータが入力されるため、問題の傾向や製品のパフォーマンスに関する詳細なレポートを非常に簡単に生成できます。
最適化のための考慮事項
Zendeskエンティティ検知は構造化データには優れていますが、自動化をさらに包括的なものにする方法があります:
-
ルールベースのロジックの補完: システムは信頼性の高いルールに基づいています。よりニュアンスのある問い合わせや会話形式の問い合わせに対応するために、多くのチームはZendeskのマーケットプレイスを利用して、文脈理解を追加する補完的なAIツールを探しています。
-
データの集約: このツールはチケットデータに焦点を当てています。Confluence、Google ドキュメント、または社内Wikiから情報を取得する必要があるチームの場合、ナレッジ共有レイヤーを追加することで全体的なエクスペリエンスを向上させることができます。
-
アクションの拡張: コア機能はチケットフィールドへの入力ですが、Zendeskの広大な統合エコシステムにより、マーケットプレイスのアプリを使用してSlackと連携したり、Shopifyと統合したりするなど、これをベースに構築することができます。
補完的なオプション:文脈を考慮したサポートのためのeesel AI
Zendeskの設定にさらなる柔軟性を加えたいチームにとって、eesel AIのようなツールは優れたパートナーとなります。Zendeskが構造化されたチケットロジックを処理する一方で、eesel AIはヘルプ記事、社内ドキュメント、Slackの履歴など、企業のより広範なナレッジベースに接続し、文脈を考慮した回答や分類を提供できます。
これはZendeskと連携して顧客の意図を理解し、固定されたルールと流動的な会話の間のギャップを埋めるのに役立ちます。これにより、Jiraの課題を更新したりCRMデータを取得したりするなど、さらにダイナミックなワークフローを作成でき、同時にZendeskを「信頼できる唯一の情報源(Source of Truth)」として維持できます。
| 機能 | Zendeskエンティティ検知 | eesel AI |
|---|---|---|
| セットアップ | 精密かつ細粒度。カスタムフィールドと論理ベースのルールが必要。 | 迅速なセットアップ。複数のナレッジソースと自動的に統合。 |
| ナレッジソース | Zendeskのチケットフィールドデータと深く統合。 | 広範。チケット、ヘルプセンター、Confluenceなどから学習。 |
| 柔軟性 | 信頼性が高く構造化されている。一貫したデータ抽出に理想的。 | 文脈を考慮。LLM(大規模言語モデル)を使用して会話のニュアンスを理解。 |
| アクション | チケットフィールドを効率的に入力し、標準ワークフローをトリガー。 | 高度にカスタマイズ可能。トリアージや外部APIとの連携が可能。 |
| テスト | 特定のパターンマッチングに対する直接的なテスト。 | 過去のチケットデータに対するシミュレーションモードでのテスト。 |
Zendesk AIの料金:あらゆるチーム向けの信頼できるオプション
Zendeskは、あらゆる規模の企業が強力なAIツールにアクセスできるよう、いくつかの段階的なプランを提供しています。エンティティ検知を含むZendeskのAI機能は、人気の高いプロフェッショナルおよびエンタープライズプランで利用可能です:
-
Suite Team: 1エージェントあたり月額$55(年払い)
-
Suite Professional: 1エージェントあたり月額$115(年払い)
-
Suite Enterprise: 1エージェントあたり月額$169(年払い)
Zendesk AIエージェントやコパイロットの可能性を最大限に引き出したいチーム向けには、1エージェントあたり月額$50のAdvanced AIアドオンが用意されています。また、Zendeskは特定のAI解決に対して柔軟な従量課金制モデルも提供しており、企業は自動化の成功に合わせて投資を拡大できます。
この段階的なアプローチにより、現在のニーズに合った洗練度を選択できると同時に、将来的にエンタープライズグレードの機能へと成長する道筋があることを確信できます。別のモデルを求めるチームにとって、eesel AIの透明性のある料金体系は予測可能な月間インタラクションボリュームを提供しており、追加の自動化レイヤーに対して定額制のオプションを求める人々にとって優れた補完的な選択肢となります。
適切なツールでサポートを強化する
Zendeskエンティティ検知は、あらゆるサポート組織にとって印象的で業界標準のツールです。構造化された信頼性の高いデータ抽出機能により、効率的なチケット管理の礎となります。自動化のための明確なフレームワークを提供することで、チームが成長しても高いサービス基準を維持できるよう支援します。
サポートのさらなる現代化を検討する際は、最も成功しているチームは、多くの場合、Zendeskの実証済みの信頼性と、専門的で文脈を考慮したツールを組み合わせているということを覚えておいてください。
eesel AIはZendeskエコシステム内で動作するように設計されており、すべてのナレッジソースを統合して自動化をさらに強力にします。これらを組み合わせることで、常に迅速、正確、かつ役立つサポートを提供したいチームに完全なソリューションを提供します。
現代的なAIレイヤーがどのようにZendeskの設定を強化できるか見てみませんか?今すぐeesel AIの無料トライアルを開始して、文脈(コンテキスト)がもたらす違いを体験してください。
よくある質問
Zendeskエンティティ検知(entity detection)は、Zendeskの「インテリジェントトライアージ」ツール内の強力な機能であり、注文番号や製品名などの特定の情報を、受信したサポートチケットから自動的に抽出するように設計されています。この「エンティティ」を、Zendesk環境であらかじめ設定したカスタムチケットフィールドに効率的に接続することで機能します。
設定には、まず管理パネルでカスタムフィールド(ドロップダウン、マルチセレクト、または正規表現)を作成し、これらをエンティティにリンクさせます。このプロセスにより、同義語を追加したり、特定のビジネスニーズに合わせて抽出ルールを設定したりして、精度をさらに高めることができ、正確な制御が可能になります。
構造化されたデータに対して非常に効果的ですが、このツールは明確なルールと同義語を提供したときに最も威力を発揮します。チケットの種類が非常に多岐にわたるチームの場合、このツールを論理ベースの信頼できる基盤として活用し、さらに広範なカバー範囲を実現するために、文脈を考慮した他のAIツールで補完するのが最適です。
チケットを適切なチームへ自動的にルーティングする、検知されたキーワードに基づいてチケットの優先度を設定する、特定の製品や問題の種類に関する高品質な構造化レポートを生成する、といった不可欠なサポートタスクに最も効果的です。
Zendeskエンティティ検知は、チケットフィールドを直接制御できる堅牢なルールベースのシステムです。eesel AIのような補完的なAIは、記事やドキュメントなどの社内の幅広い知識から学習することでこれを拡張し、文脈を重視した自動化を求めるチームにさらなる柔軟性を提供します。
Zendeskエンティティ検知は、Zendeskの高度なAI機能の一部であり、Suite Team、Professional、Enterpriseなどのいくつかのプロフェッショナルおよびエンタープライズ層のプランで利用可能です。Zendeskは段階的なプランとAdvanced AIアドオンを提供しており、チームが必要な高レベルの機能に対してのみ支払うことができるようになっています。
最良の結果を得るためには、エンティティリストを戦略的に整理することが役立ちます。システムはリストの順序に従って一致を処理するため、より具体的なルールをリストの上位に配置することで、最も正確なデータ抽出が保証され、ワークフローを微調整して効率を最大化できます。
Share this article

Article by
Stevia Putri
Stevia Putriはeesel AIのマーケティング・ジェネラリストであり、強力なAIツールを人々の心に響くストーリーへと変換することに尽力しています。彼女は好奇心、明快さ、そしてテクノロジーの人間的な側面に突き動かされています。