
正直に言いましょう。カスタマーサポートにおけるAI (AI in customer support)は、諸刃の剣のように感じられることがあります。一方では、反復的な質問を自動化 (automate repetitive questions)し、チームが困難な問題に取り組むためのスペースを提供できる素晴らしいツールがあります。他方では、AIが何かを間違え、顧客を苛立たせ、結果として節約する以上の作業を生み出すのではないかという不安が常に付きまといます。
ここで、「信頼度閾値 (confidence threshold)」という考え方があなたの最高の友になります。これを、このバランスを管理するのに役立つ主要な制御ノブ (main control knob)と見なし、AIが質問に回答すべきタイミングと、会話を人間 (human)に引き継ぐべきタイミングを決定できるようにします。
このガイドでは、信頼度閾値 (confidence threshold)とは何か、考慮する必要のあるトレードオフ (trade-off)、そして当てずっぽうではなく、ビジネスに最適な設定を見つける方法について詳しく説明します。
信頼度スコアと閾値とは?
まず、専門用語 (jargon)を整理しましょう。信頼度スコア (confidence score)とは、AIが回答についてどれだけ確信しているかをAI自身が推測したものであり、通常はパーセンテージ (percentage)または0〜1のスコア (score)として表示されます。AIが95%の信頼度スコア (confidence score)で戻ってきた場合、ユーザー (user)の質問を正しく理解していると非常に確信していることになります。
信頼度閾値 (confidence threshold)とは、AIが応答を許可される前に達成する必要があると判断する最低スコア (score)です。閾値 (threshold)を70%に設定した場合、それを下回る信頼度スコア (confidence score)の回答は顧客 (customer)に送信されません。代わりに、AIはチケットを人間 (human)のエージェント (agent)にエスカレーション (escalate)するなど、他のことを行います。
graph TD
A[顧客が質問をする] --> B{AIが質問を分析して回答を見つける};
B --> C{AIが信頼度スコアを生成する};
C --> D{スコア >= 信頼度閾値?};
D -- はい --> E[AIが回答を顧客に送信する];
D -- いいえ --> F[AIが人間のエージェントにエスカレーションする];
これは、新しいチームメンバー (team member)に「少なくとも80%の確率で正しい答えを持っていると確信できる場合にのみ、顧客 (customer)の質問に答えてください。そうでない場合は、より経験豊富な人に聞いてください」と言うようなものです。これは、新入社員(またはAI)がすぐに理解できるように、品質を高く保つためのシンプルなルールです。
中核となるトレードオフ:適切なバランスを取る
閾値 (threshold)を理解することは、忘れてしまっても構わない単なる技術設定 (tech setting)ではありません。顧客 (customer)、チーム (team)、そして収益に影響を与えるビジネス上の決定です。選択は、より多くの回答を正しく得る (getting more answers right)ことと、より多くのチケットを自動化 (automating more tickets)することのトレードオフ (trade-off)に帰着します。
簡単な内訳は次のとおりです。
| 側面 (Aspect) | 高い信頼度閾値 (High Confidence Threshold)(例:85%) | 低い信頼度閾値 (Low Confidence Threshold)(例:50%) |
|---|---|---|
| 主な目標 (Primary Goal) | できるだけ多くの回答を正しく得て、間違いを避けること。 | より多くの顧客 (customer)の質問を自動的に処理すること。 |
| メリット (Pros) | * 間違った回答が顧客 (customer)に届くことが少ない。* 顧客 (customer)の満足度と信頼を維持するのに役立つ。* エージェント (agent)がAIのエラー (error)を修正するのに費やす時間が少ない。 | * より高い割合のチケット (ticket)がAIによって処理される。* より多くの人々にとって初回応答時間が速くなる。* チケット (ticket)あたりのコスト (cost)が潜在的に低くなる。 |
| デメリット (Cons) | * AIからの「わかりません」という返信が増える。* より多くのチケット (ticket)が人間のエージェント (agent)に渡される。* チーム (team)の作業負荷と待ち時間が増加する可能性がある。 | * 間違った、または役に立たない回答を送信する可能性が高くなる。* 人間 (human)を求めているだけの顧客 (customer)をイライラさせる可能性がある。ボット (Bot)ですか、それとも人間 (human)ですか?* エージェント (agent)が複雑なAIの間違いを解きほぐす必要がある場合、より多くの作業が発生する可能性がある。 |
| 最適な場合 (Best For) | 間違った回答が大きな問題になる業界 (industry)(金融 (finance)やヘルスケア (healthcare)など)、または複雑なテクニカルサポート (technical support)の場合。 | 注文状況の更新、パスワードのリセット、または基本的なFAQなど、大量の単純な質問 (question)。 |
ここに魔法の数字 (magic number)はありません。適切な閾値 (threshold)は、ビジネス (business)、どれだけのリスク (risk)を許容できるか、顧客 (customer)があなたに何を期待しているかによって異なります。
信頼度閾値を設定するための一般的なアプローチ
スイートスポット (sweet spot)を見つけるのが非常に難しいので、ほとんどの企業はいくつかの一般的な方法のいずれかに頼っていますが、それらには独自の問題があります。
デフォルト設定 (Default setting)(「万能ではない」アプローチ)
Zendeskなどの多くのプラットフォーム (platform)では、50%〜70%の範囲のデフォルトの閾値 (threshold)を推奨しています (suggest a default threshold)。これは始めるには妥当な場所ですが、あなたにとって最適な設定であることはほとんどありません。すべての企業のナレッジベース (knowledge base)と顧客 (customer)の質問 (question)は異なります。オンライン (online)の衣料品店に有効なデフォルト (default)は、B2Bソフトウェア (software)企業にとっては悲惨なことになる可能性があります。これは、非常に特定の問題に対する一般的な解決策です。
手動分析法 (Manual analysis method)(「データサイエンティスト (data scientist)」アプローチ)
技術的なリソース (technical resources)がたくさんある場合は、会話ログ (conversation log)を調べて、派手なグラフ (graph)を作成し、完璧な数字を見つけるための複雑な統計モデル (statistical model)を構築することができます。時間と方法を知っている人がいる場合は、これは確実な方法です。ただし、ほとんどのサポートチーム (support team)にとって、これは現実的ではありません。多くの時間とデータサイエンス (data science)の背景が必要であり、状況が変化するにつれてやり直す必要があります。
試行錯誤法 (Trial-and-error method)(「ライブテスト (live testing)」アプローチ)
これはほとんどの人が試す方法です。数字を選び、しばらくライブ (live)の顧客 (customer)で実行し、何が問題になるかを確認し、調整して、もう一度試してください。ここでの大きな問題は非常に明白です。顧客 (customer)で実験しています。悪い閾値 (threshold)は、問題があることに気付く前に、イライラする会話の波を引き起こし、信頼を損ない、チーム (team)に後始末を任せることになります。
推測せずに最適な閾値を見つける方法
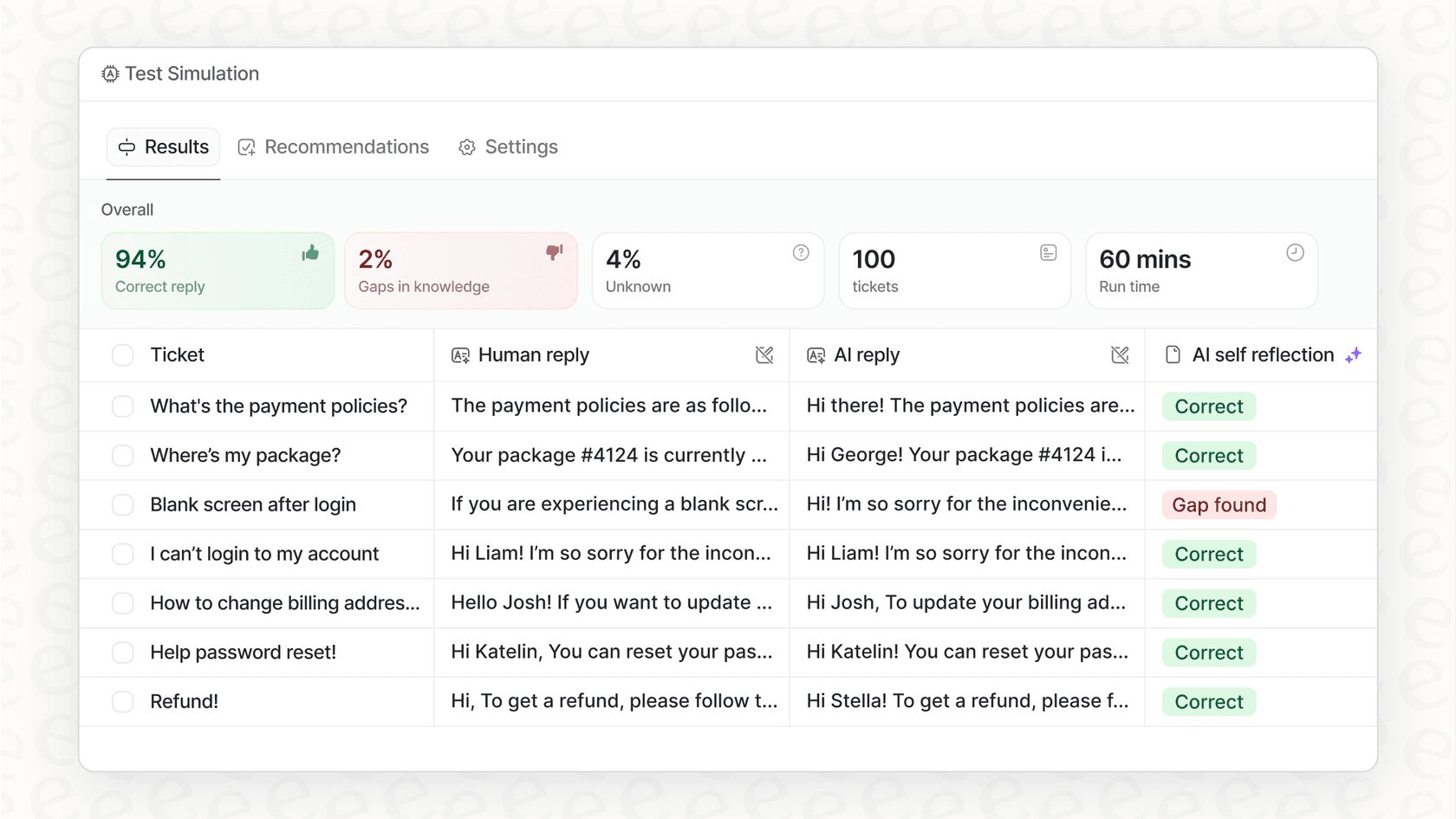
推測したり、危険なライブテスト (live test)を実行したり、データサイエンティスト (data scientist)を雇おうとしたりする代わりに、はるかに良い方法があります。安全なオフライン (offline)環境でAIエージェント (AI agent)のパフォーマンス (performance)をシミュレート (simulate)します。
過去のデータでパフォーマンスをシミュレートする
これを行うためのよりスマート (smart)な方法は、すでに回答した実際の質問 (question)に対してAIがどのように機能するかを確認することです。eesel AIなどのツール (tool)は、ヘルプデスク (helpdesk)とナレッジベース (knowledge base)に接続し、過去数千件の実際のチケット (ticket)でAIをテスト (test)できます。閾値 (threshold)を70%に設定すると、過去数か月間の実際の顧客 (customer)の問い合わせ (query)をAIがどのように処理したかをすぐに確認できます。これにより、方程式から当て推量を取り除き、何を期待するかを正確に示します。

主要なビジネス指標を予測する
シミュレーション (simulation)は、正誤のチェックだけではありません。eesel AIなどのプラットフォーム (platform)を使用すると、ビジネス (business)に対する具体的な影響を確認できます。信頼度閾値 (confidence threshold)スライダー (slider)を動かすと、自動解決率 (automated resolution rate)、コスト削減 (cost savings)、**残りのエージェント (agent)の作業負荷 (workload)**などの指標がリアルタイム (real-time)で更新されるのを確認できます。これにより、技術的な設定 (technical setting)を、実際に気にかけているビジネス目標 (business goal)に直接結び付けることができます。
段階的に、自信を持ってロールアウトする
多くのAIツール (tool)は、すべての人に対してスイッチ (switch)を切り替え、最善を期すようにします。シミュレーション (simulation)を実行した後、eesel AIを使用すると、自動化をより慎重にロールアウトできます。たとえば、テスト (test)でAIが「払い戻し状況」の質問 (question)に優れているが、「技術的なトラブルシューティング」では不安定であることが示された場合、開始するために払い戻しの質問 (question) のみをオン (on)にすることができます。このアプローチ (approach)はプロセス (process)全体のリスク (risk)を軽減し、システム (system)に慣れるにつれて徐々に自動化を拡大できます。
開始閾値を選択するためのフレームワーク
では、どこから始めるべきでしょうか?最も簡単な方法は、間違った回答のコスト (cost of a wrong answer)を考慮することです。念頭に置いて出発点 (starting point)を設定したら、eesel AIのようなシミュレーションツール (simulation tool)を使用して、独自のデータ (data)でそれをチェック (check)し、微調整することができます。
高い閾値 (80%以上)から始める場合
間違った回答が深刻な頭痛の種になる可能性がある場合は、安全策を講じる必要があります。これは通常、金融サービス (financial services)、ヘルスケア (healthcare)、または間違いがユーザー (user)にとってお金の損失や大きな問題につながる可能性がある複雑なB2Bテクニカルサポート (technical support)などの業界 (industry)に当てはまります。ここでの目標は、精度を優先し、わずかに不明確なものはすべて人間 (human)の専門家 (expert)に処理させることです。
中間の閾値 (65〜80%)から始める場合
この範囲 (range)は、ほとんどのビジネス (business)にとって適切でバランスの取れた出発点 (starting point)です。注文に関する質問 (question)に答えるeコマース企業 (e-commerce companies)や、標準機能 (standard feature)でユーザー (user)を支援するSaaS企業 (SaaS companies)について考えてみてください。目標は、間違いの数を少なく抑えながら、かなりの数のチケット (ticket)を自動化することです。間違った回答は世界の終わりではありませんが、それでも人々 (people)に一貫して優れたエクスペリエンス (experience)を提供したいと考えています。
低い閾値 (50〜65%)から始めることができる場合
間違った回答の影響が非常に少ない場合は、より多くの自動化を目指すことができます。これは多くの場合、社内サポート (internal support)ボット (bot)、ユーザー (user)がとにかく正しい答えを簡単に見つけることができる単純なFAQボット (bot)、またはチケット (ticket)を適切な部署 (department)にルーティング (routing)するために有効です。ここで、主な目標はチケット (ticket)をそらすことであり、わずかに的外れな回答が大きな問題を引き起こすことはありません。
完璧なバランスを見つける
結局のところ、信頼度閾値 (confidence threshold)を選択することは、単なる技術設定 (tech setting)ではなく、顧客体験 (customer experience)を形作る決定です。それはすべて、ビジネス目標 (business goal)に沿った精度 (accuracy)と自動化 (automation)の間のスイートスポット (sweet spot)を見つけることです。デフォルト (default)の使用やライブ (live)での試行錯誤などの古い方法は非効率的で危険ですが、手探りで行う必要はありません。
最善の道は、データ (data)を使用して推測を排除することです。独自の過去のデータ (data)を使用してテスト (test)と予測を行うことで、最初から顧客 (customer)とチーム (team)の両方に役立つスマート (smart)な決定を行うことができます。
推測をやめて、AIが実際のサポート (support)チケット (ticket)でどのように機能するか見てみませんか?eesel AIの無料トライアル (free eesel AI trial)を開始すると、わずか数分で最初のシミュレーション (simulation)を実行できます。
よくある質問
信頼度閾値を設定することで、AIが顧客に応答する前に必要な最低限の確実性を定義します。これは、AIが応答を自動化する能力と、品質を維持してエラーを回避する必要性のバランスを取るための制御ノブとして機能するため、非常に重要です。最終的には、顧客満足度とエージェントの作業負荷に影響を与えます。
主なトレードオフは、[精度(正しく回答し、間違いを避けること)とカバレッジ(より多くのチケットを自動化すること)]のバランスです。高い閾値を設定すると、エラーは少なくなりますが、エスカレーションされる質問が増えます。低い閾値を設定すると、自動化は進みますが、不正確または役に立たないAI応答のリスクが高まります。
出発点は、ビジネスにおける「間違った回答のコスト」によって異なります。財務や医療などの重要な分野では、精度を優先するために高い閾値(80%以上)を目指してください。基本的なFAQなどの影響の少ない質問については、自動化を最大化するために低い閾値(50〜65%)から始めることができます。
独自のニーズに合うことはほとんどないため、デフォルト設定に頼ることは避けてください。また、信頼を損なう可能性があるため、ライブの顧客に対して直接行う危険な「試行錯誤」法は避けてください。手動分析は堅牢ですが、ほとんどのサポートチームにとって時間がかかりすぎることがよくあります。
最適なアプローチは、安全なオフライン環境で過去のサポートデータを使用してAIのパフォーマンスをシミュレートすることです。eesel AIなどのツールを使用すると、過去のチケットに対してさまざまな閾値をテストして、AIが*どのように*動作したかを確認し、推測を取り除くことができます。
はい、間違いありません。さまざまな閾値をシミュレートすることで、自動解決率、潜在的なコスト削減額、およびヒューマンエージェントの残りの作業負荷など、指標に対する具体的な影響をリアルタイムで予測できます。
大規模な一括展開ではなく、段階的なロールアウトを目指してください。まず、特定の、パフォーマンスの高い質問タイプに対してAI自動化を有効にし、信頼を得て肯定的な結果を観察するにつれて、徐々に範囲を拡大できます。
Share this article

Article by
Kenneth Pangan
Writer and marketer for over ten years, Kenneth Pangan splits his time between history, politics, and art with plenty of interruptions from his dogs demanding attention.


