
あなたはチケットのタグ付けをAIに任せることにしました。すべてのお客様の問題が自動で分類され、キューが完璧に整理される。それが理想でした。しかし現実はどうでしょう?少し散らかっているかもしれません。AIがチケットに間違ったタグを付け始めると、それは単なる小さな問題ではなく、混乱の元凶となります。その結果、チケットが誤った担当者に転送され、エージェントはAIの間違いを修正するのに時間を浪費し、お客様は回答をより長く待つことになります。
このガイドは、AIがなぜ間違うのか、そしてそれをどう修正すればよいのかを解明するための、分かりやすい計画書です。データのクリーンアップ方法、「十分」の基準をどう決めるか、そして常に疑心暗鬼になる必要のないタグ付けシステムを構築するために適切なツールを使用する方法を順を追って解説します。
はじめに準備するもの
修正作業に取り掛かる前に、いくつか手元に揃えておきたいものがあります。データサイエンスの博士号は必要ありませんが、適切な情報とツールがあれば、大きな違いが生まれます。
-
ヘルプデスクの履歴: ZendeskやFreshdeskなど、お使いのプラットフォームから過去のチケットのバックログにアクセスできるようにしておきましょう。ここにパターンが隠されています。
-
実際に制御できるAIツール: もしお使いのAIが設定を微調整できない「ブラックボックス」なら、苦労することになるでしょう。AIの振る舞いを微調整できるツールが必要です。
-
明確な目標: そもそも、なぜこれらのタグを使っているのでしょうか?チケットのルーティングのため、緊急の問題を見つけるため、それともバグに関するレポートを作成するためですか?「なぜ」を理解することが、問題解決の半分を占めます。
-
精度の基本的な理解: 測定できなければ修正もできません。間違ったタグを減らすこと(適合率)と、関連するチケットをすべて捉えること(再現率)のシンプルな違いについて、後ほど詳しく説明します。
ステップバイステップ:チケットタグ付けにおけるAIの偽陽性を減らす方法
さて、実際に手をつけていきましょう。偽陽性の修正は、一度きりの修正というよりは、チューニングのプロセスです。以下のステップに従って、AIのタグ付けの信頼性を高めましょう。
ステップ1:チームにとって「偽陽性」が何を意味するかを定義する
「偽陽性(False Positive)」という言葉は少し専門的に聞こえますが、サポートチームにとっては非常に現実的な頭痛の種です。これは単に、AIがチケットに間違ったタグを付けてしまうことです。これらの間違いを減らすには、まずどの間違いが最も大きな損害をもたらすかについて、チームで合意する必要があります。
例えば、偽陽性には以下のようなものがあります:
-
簡単な料金に関する質問が「返金リクエスト」としてタグ付けされ、間違ったチームに送られてしまい、ちょっとしたパニックを引き起こす。
-
何気ない機能のアイデアが「緊急バグ」とラベル付けされ、開発者が本当に緊急の対応から引き離されてしまう。
-
新規顧客のログイン問題が「スパム」としてマークされ、最悪の第一印象を与えてしまう。
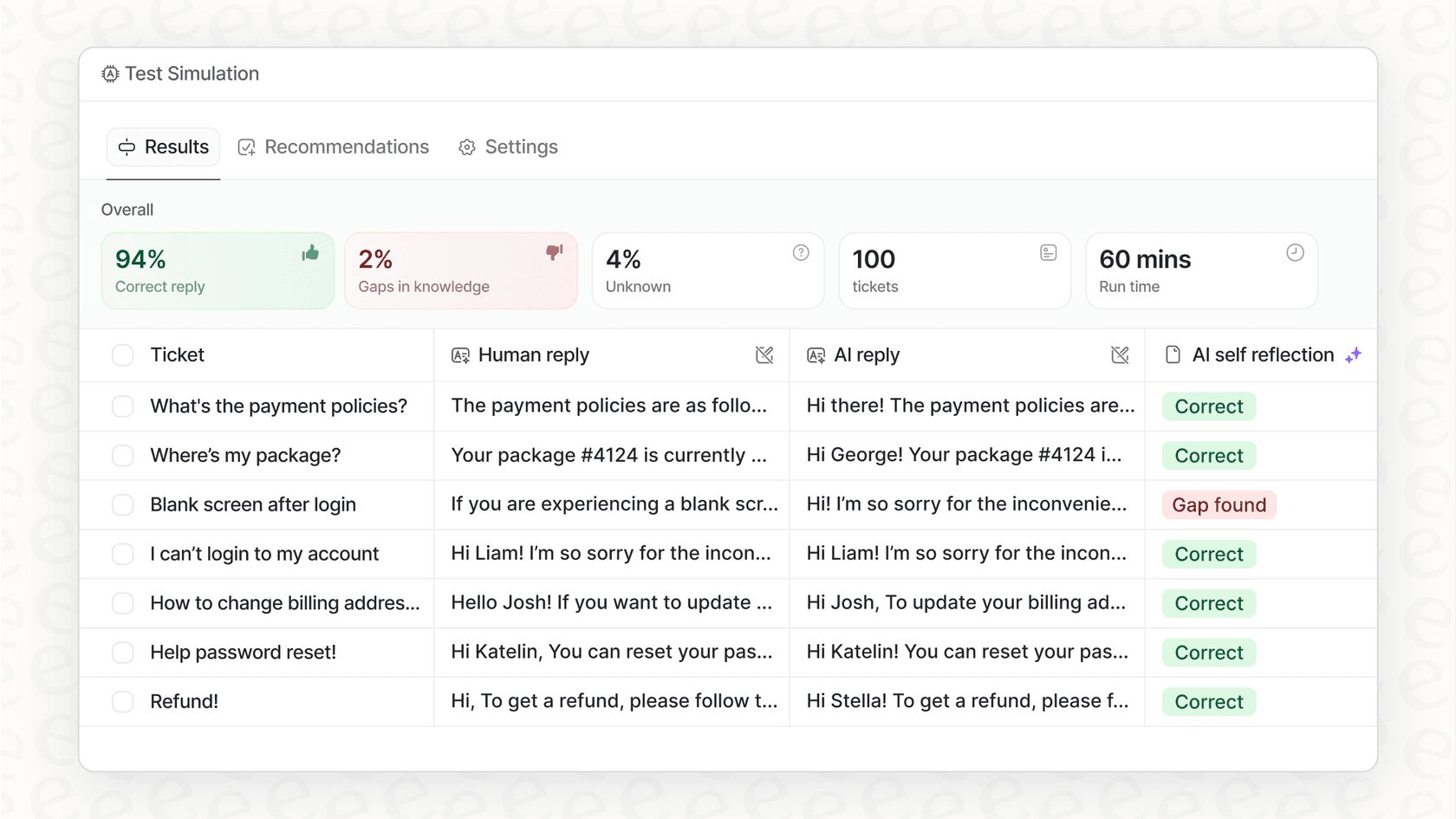
最初のステップは、最も問題を引き起こしているタグ付けの間違いを5〜10個リストアップすることです。これにより、明確な目標が定まります。優れたAIプラットフォームなら、これらのエラーを簡単に見つけられるはずです。例えば、eesel AIのようなツールを使えば、過去のチケットでシミュレーションを実行できます。これにより、AIがそれらをどのようにタグ付けしたかが正確にわかり、実際の顧客とのやり取りでAIを稼働させる前に、こうした間違いを発見できます。
ステップ2:ナレッジソースの矛盾や抜け漏れを分析する
AIを新人研修生だと考えてみてください。もし彼らに、混乱を招く、時代遅れの、あるいは矛盾したトレーニングマニュアルの束を渡したら、彼らが間違いを犯しても驚けないでしょう。AIのパフォーマンスは、学習元のデータを直接反映したものであり、偽陽性はしばしば、その「頭脳」が少し散らかっていることのサインです。
以下は、AIのナレッジに対して実行できる簡単なヘルスチェックです:
-
公開ヘルプセンターを確認する: 古い料金ページがまだ残っているなど、矛盾した情報を含む記事はありませんか?手順が分かりにくいものはありませんか?
-
社内ドキュメントをチェックする: マクロ、定型文、社内Wikiはどうでしょうか?エージェント全員が同じ認識を持っていますか、それともそれぞれが独自の方法で対応していますか?
-
過去のチケットを掘り下げる: ここに本当の魔法があります。人間のエージェントがどのようにタグを適用してきたかを見てみましょう。AIが学習しようとしてきた、明文化されていないルールや一貫性のない点が見つかることがよくあります。
何年にもわたって蓄積されたナレッジを手作業でクリーンアップするという考えは、誰しもが諦めたくなるほどです。それは巨大なプロジェクトであり、多くのチームが行き詰まる共通の理由です。ここで、新しいAIツールがあなたの時間を大幅に節約してくれます。eesel AIのようなプラットフォームは、あなたがすべての面倒な作業を行う代わりに、ConfluenceやGoogle Docsから過去のチケットのやり取りまで、すべての異なるナレッジソースに接続し、自動的に統合します。さらには、ドキュメントの抜け漏れを発見し、成功したチケットから学んだことに基づいて新しい記事の作成を支援することもできます。これにより、AIは自身の学習ソースを時間とともに改善していくのです。
ステップ3:適合率と再現率を用いて適切な精度目標を設定する
これを正しく行うために、統計学者である必要はありません。突き詰めると、**「私たちにとって、どちらのタイプの間違いがより悪いか?」**という一つのシンプルな問いに行き着きます。
-
適合率(より少ない偽陽性)を重視する: これはメールのスパムフィルターのようなものです。おそらく、重要な上司からのメールがスパムフォルダに埋もれてしまう(偽陽性)よりは、迷惑メールが受信トレイに紛れ込む(見逃し)方がましでしょう。「請求エラー」や「セキュリティ懸念」のような重要なタグには、高い適合率が必要です。AIがこれらのタグを使用するときは、それが正しいことが絶対条件です。
-
再現率(すべての潜在的なケースを捉える)を重視する: 次に、銀行の不正検知を考えてみてください。彼らは、不正な請求が見過ごされる(見逃し)よりは、正当な購入を誤ってフラグ付けし、あなたに確認を求める(偽陽性)方がはるかに良いと考えます。「解約リスク」や「VIP顧客」といったタグについては、たとえエージェントがいくつかの誤ったフラグをクリアする必要があったとしても、AIに少し過剰に慎重であってほしいと思うかもしれません。これらのチケットを一つでも見逃すことは、あまりにも代償が大きすぎます。
あなたの次のタスクは、最も重要なタグを「高い適合率が必要」と「高い再現率が必要」という2つのバケツに分類することです。このシンプルな作業は、AIシステムにあなたが最も何を重視しているかを伝えるのに役立ちます。
ステップ4:より良い指示とスコープを絞ったナレッジでAIを微調整する
目標が明確になったら、AIにより良い指示を出し始めることができます。多くのAIシステムが失敗するのは、それらがブラックボックスだからです。データを入力するとタグが出力されますが、その理由は分かりません。偽陽性を本当に削減するためには、あなたが主導権を握る必要があります。
ここで、カスタマイズ可能なワークフローを持つことが大きな違いを生みます。画一的なモデルに縛られるのではなく、eesel AIのようなプラットフォームなら、あなたがコントロールできます。
-
プロンプトをカスタマイズする: シンプルなエディタを使って、各タグが何を意味するのかをAIに正確に伝えることができます。例を挙げ、タグを使わない場合のルールも与えます。例えば、「お客様が『ダウン』、『停止』、『アクセスできない』といった言葉を使わない限り、チケットを『緊急』としてタグ付けしないこと」といった具合です。
-
ナレッジのスコープを絞る: これは精度を向上させるための非常に強力な手段です。特定のトピックについては、特定の記事セットのみを使用するようにAIに指示できます。請求に関する質問の場合、AIを5つの公式な請求関連記事に限定し、それ以外の情報は使わせません。これにより、古かったり無関係な情報に混乱するのを防ぎ、間違いを劇的に減らすことができます。
-
展開をコントロールする: 一度にすべてを導入する必要はありません。まずは一つのチームや一つのトピックに関するチケットのタグ付けからAIに任せましょう。これにより、自信をつけ、拡大する前にその効果を証明することができます。
このようなコントロールにより、AIはあなたが設定したガードレール内で動作するため、その振る舞いは予測可能で信頼性の高いものになります。

顧客チケットに触れる前にAIをテストする
新しい自動化における最大の恐怖は、顧客の前でそれが暴走することです。では、慎重にチューニングしたAIが実際のチケットでおかしな間違いをしないと、どうすれば確信できるのでしょうか?その答えはシミュレーションです。
AIをただ有効にして最善を期待するのではなく、安全な環境でテストできるべきです。これは、あなたのAI設定を過去のチケットデータ上で実行し、それが実際に何をしたかを正確に確認することを意味します。これは究極の飛行前点検です。
これはAIプラットフォームに求めるべき主要な機能です。一部のツールは漠然としたデモを提供しますが、eesel AIには、実データで作業できる強力なシミュレーションモードがあります。実際にどのように機能するかは以下の通りです:
-
自身のデータでテストする: 一般的なサンプルではなく、何千ものあなたの実際の過去のチケットでシミュレーションを実行します。
-
詳細な成績表を入手する: シミュレーションレポートは、AIが各チケットをどのようにタグ付けしたかを正確に示し、潜在的な偽陽性を指摘し、現実的なパフォーマンススコアを計算します。
-
自信を持って開始する: 自動化率と精度の正確な予測を武器に、何が期待できるかを正確に知った上でAIをオンにすることができます。
シミュレーションは憶測を排除し、希望ではなくデータに基づいて意思決定を下すことを可能にします。

避けるべきよくある間違い
これらのステップを進める中で、つまずきやすい一般的な罠に注意してください。
-
一度設定したら放置する: あなたの製品は変化し、顧客の問題も変化します。AIモデルは時間とともに「ドリフト」し、精度が低下することがあります。定期的にチェックし、再チューニングするための簡単なプロセスが必要です。
-
公式のナレッジベースのみを使用する: 最高の情報の一部は、エージェントと顧客との過去のやり取りの中に隠されています。その現実世界のコンテキストという宝の山を無視すれば、精度を犠牲にしていることになります。
-
一度にすべてを自動化しようとする: 初日から100%の自動化を目指さないでください。定義しやすいチケットの種類を1つか2つ選び、それらを成功裏に自動化してから、そこから拡大していきましょう。段階的な展開が成功の鍵です。
正確なAIチケットタグ付けへの最速ルート
結局のところ、AIの偽陽性を減らすことは、「完璧な」アルゴリズムを見つけることではありません。それは、適切なプロセスと適切なツールを持つことです。プロセスは簡単です。最悪のエラーが何かを特定し、データをクリーンアップして焦点を合わせ、明確な目標を設定し、本番稼働前にすべてをテストすることです。適切なツールとは、このプロセスを簡単に感じさせ、AIのロジックを制御し、そのパフォーマンスをリスクなしでシミュレーションする方法を提供してくれるものです。
スマートなプロセスと柔軟なツールを組み合わせることで、余計な混乱なしに、ついにサポート自動化のメリットを享受できます。
eesel AIを始めましょう
eesel AIを使えば、数分でセットアップして稼働させることができ、自身のデータで結果をシミュレーションし、ワークフローエンジンを使ってチケットのタグ付けを完全にコントロールできます。小さく始め、価値を証明し、準備が整ったらスケールアップすることが可能です。
偽陽性の追跡をやめ、自信を持って自動化を始めませんか?今すぐeesel AIの無料トライアルを開始して、あなたのチケットでその性能を確かめてください。
よくある質問
最初のステップは、あなたのチームにとって「偽陽性」が具体的に何を意味するのかを明確に定義し、最も大きな問題を引き起こしている上位5〜10個のタグ付けミスを特定することです。これにより、改善のための明確なターゲットが設定されます。
AIは既存のデータから学習するため、矛盾した情報や古い情報を整理し、過去のチケットで[人間のエージェントがどのようにタグを使用していたか](https://www.eesel.ai/ja/blog/zendesk-ai-ticket-classification-complete-rundown-in-2025)を分析することで、学習教材の質が直接向上します。この洗練された入力データにより、AIはより正確なタグ付けの判断を下すことができます。
適合率は、不正確なタグ(偽陽性)を最小限に抑えることに焦点を当て、タグが適用された場合にはそれが正しい可能性が高いことを保証します。一方、再現率は、いくつかの偽陽性が生じることを許容してでも、特定のタグに関連するすべてのチケットを捉えることを目指します。特定のタグにとってどちらのタイプのエラーがより有害であるかを理解することは、AIの振る舞いを優先順位付けし、微調整するのに役立ちます。
AIを微調整するには、各タグに特定のルールや例を盛り込んだプロンプトをカスタマイズしたり、ナレッジのスコープを絞ったりする方法があります。スコープを絞るとは、特定のトピックについて、AIが参照する記事を関連性の高いサブセットのみに制限することで、無関係な情報による混乱を防ぐことを意味します。
最も効果的な方法は、AIプラットフォーム内のシミュレーションモードを使用して、[自身の過去のチケットデータでテストする](https://panther.com/blog/identifying-and-mitigating-false-positive-alerts)ことです。これにより、AIが過去のチケットをどのようにタグ付けしたかを正確に確認し、潜在的な偽陽性を特定し、実際の顧客とのやり取りに影響を与える前にその精度を評価することができます。
「一度設定したら放置する」という考え方を避けることが重要です。製品や顧客の問題は変化するため、定期的にAIのパフォーマンスを確認してください。定期的にモデルを再チューニングし、新しいチケットデータを分析することで、精度を維持し、変化に適応し、モデルのドリフト(性能劣化)を防ぐことができます。
Share this article

Article by
Stevia Putri
Stevia Putri is a marketing generalist at eesel AI, where she helps turn powerful AI tools into stories that resonate. She’s driven by curiosity, clarity, and the human side of technology.