AIサポートエージェントの「頭脳」となるのは、そのナレッジベースです。その頭脳に情報を供給するプロセス、つまり知識の取り込みは、正確で、役に立ち、人間らしい回答を得るための最も重要なステップと言えるでしょう。このステップを成功させれば、AIはスターパフォーマーになります。もし失敗すれば、非常に高価で、非常にイライラするチャットボットを構築したに過ぎません。
AdaはAIカスタマーサービス分野、特に大企業の間では有名な存在です。では、彼らはこの重要な最初のステップをどのように処理しているのでしょうか?
このガイドでは、Adaの知識取り込みプロセスについて、明確かつ簡潔に解説します。その仕組み、優れた点、そして本格的に導入する前に知っておくべき潜在的な限界について詳しく見ていきます。
Adaとは?
[Adaは、AIを活用して]カスタマーサポートの会話を自動化するために構築されたプラットフォームです](https://www.ada.com)。eコマース、金融、テクノロジー分野の大企業でよく利用されています。その主な役割は、企業が会話型AIエージェント(チャットボット)を構築・活用し、さまざまなチャネルで顧客と会話し、人間を介さずに問題を解決できるよう支援することです。
AIエージェントのための知識取り込みを理解する
では、「知識の取り込み」とは一体何でしょうか?簡単に言えば、会社の情報をすべて集め、処理し、AIエージェントが実際に質問に答えるために使えるように整理するプロセスです。
これは、新入社員に資料持ち込み可のテストを受けさせるようなものです。彼らのノートやリソース(ナレッジベース)が優れているほど、良い成績を収めることができます。この全体的な仕組みは、検索拡張生成(RAG)と呼ばれる技術によって支えられています。これは、AIが回答を出す前に「ノート」を見返すことができる、という高度な仕組みを指す言葉です。
graph TD A[開始:顧客からの質問] --> B{AIエージェントがクエリを受信}; B --> C[ステップ1:ソースの接続 AIがヘルプセンター、ドキュメント、ウェブサイトなどの接続されたナレッジベースにアクセス]; C --> D[ステップ2:コンテンツの処理 AIが大きなドキュメントを管理しやすい小さなチャンクに分割]; D --> E[ステップ3:インデックス作成 AIが検索可能なマップを使い、最も関連性の高い情報チャンクを発見]; E --> F[AIが回答を生成]; F --> G[終了:顧客が回答を受信];
style A fill:#f9f,stroke:#333,stroke-width:2px style G fill:#f9f,stroke:#333,stroke-width:2px
通常、このプロセスは主に3つの部分に分けられます:
-
ソースの接続: ヘルプセンター、ドキュメントのフォルダ、ウェブサイトなど、AIに情報源を指し示すステップです。
-
コンテンツの処理: AIは、それらすべての大きなドキュメントを取り込み、実際に意味を理解できる、より小さく管理しやすいチャンクに分割します。
-
インデックス作成: 最後に、すべての情報の検索可能な「マップ」を構築します。質問が来たとき、このマップを使って瞬時に正しい答えを見つけることができます。
このプロセス全体がどれほどシンプルで柔軟であるかは、本当に役立つAIエージェントをどれだけ迅速に立ち上げられるかに大きな影響を与えます。
Adaの知識取り込みの仕組み
Adaは知識を取り込むためのいくつかの特定の方法を持っており、主にヘルプデスクに既に存在する構造化されたコンテンツに焦点を当てています。その方法を見ていきましょう。
事前構築済みのナレッジベース連携への接続
Adaが知識を得る主な方法は、おそらく既にナレッジベースが存在するであろう、確立されたヘルプデスクプラットフォームに接続することです。Adaのドキュメントには、Zendesk、Salesforce、Contentful、Dixa、Gladlyなど、いくつかの事前構築済み連携機能が記載されています。
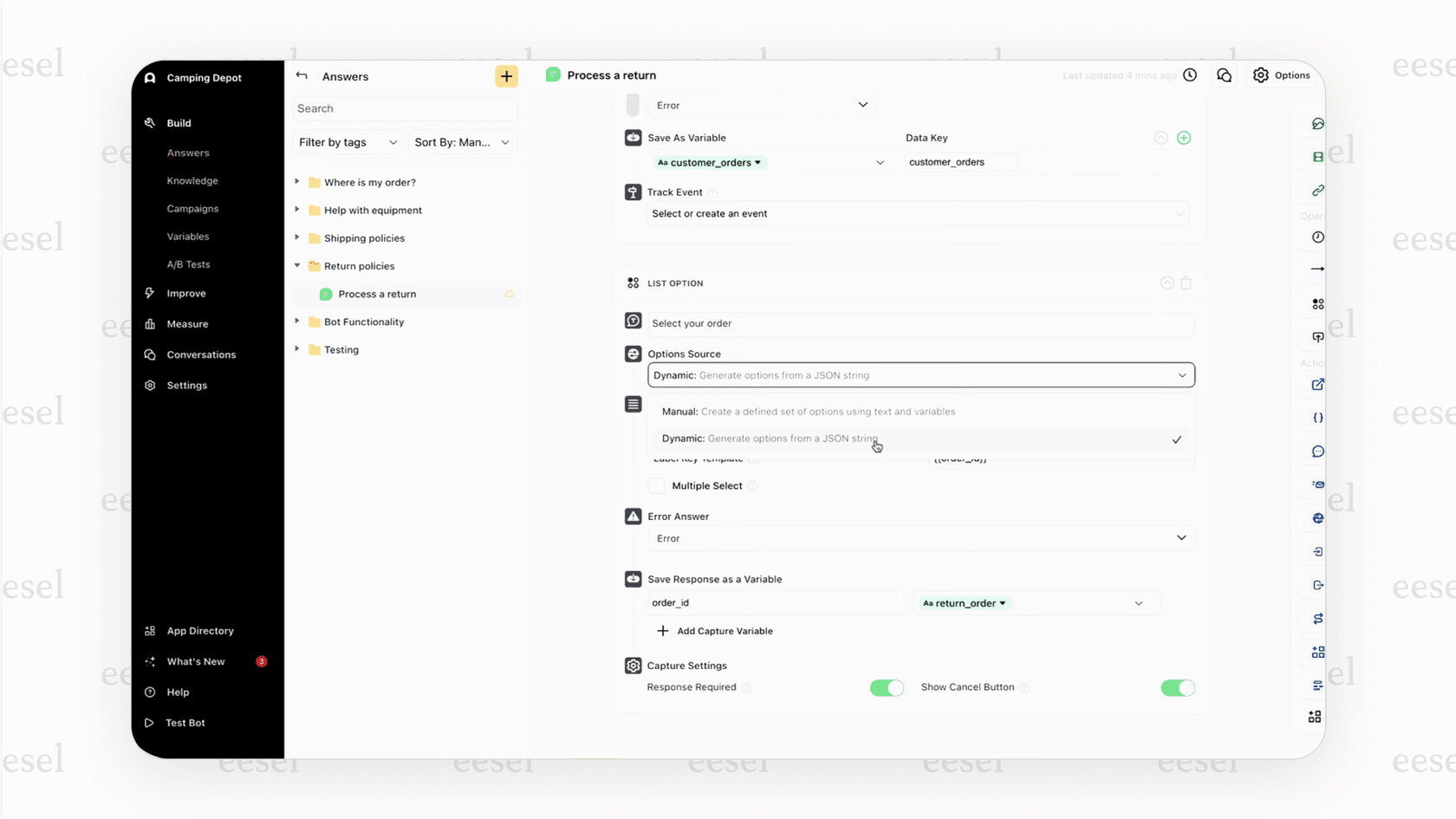
セットアップは通常、Adaのダッシュボードにログインし、ツールを選択して、APIキーやサブドメインなどの認証情報を入力する流れです。その後、いくつかの設定を調整すると、Adaが記事の取り込みを開始します。
しかし、いくつかの注意点があります。Ada自身のドキュメントによると、このプロセスではナレッジベースが公開されていること(ログインの裏に隠されていないこと)が必要になることが多いです。また、ヘルプセンターがプラットフォームのデフォルトURL構造を使用しているかどうかに依存する場合もあります。会社がカスタム設定をしている場合、ここで壁にぶつかるかもしれません。
カスタムソースのためのナレッジAPIの使用
もしあなたの知識がZendeskやSalesforceにない場合はどうでしょうか?その他のほぼすべてのデータソースに対して、AdaはナレッジAPIの使用を求めています。
APIは柔軟性に優れていますが、これは開発者向けのソリューションです。つまり、カスタム接続を構築し、さらに重要なこととして維持するために、コードを書くエンジニアがチームに必要になります。Googleドキュメントのコレクションのような単純なものを接続したいだけでも、突然、小規模なエンジニアリングプロジェクトになってしまうのです。
この点で、このプラットフォームは少し時代遅れに感じられます。新しいツールは、はるかに多様なソースに対して、セルフサービスでノーコードの連携機能を提供しています。例えば、eesel AIのようなプラットフォームでは、チームの誰もがGoogleドキュメントやConfluenceなどの場所から、コーディングの知識なしに数クリックでナレッジを接続できます。
データの同期とコンテンツ要件
接続が完了すると、Adaのシステムはナレッジベースと定期的に同期します。ZendeskやSalesforceの場合は約15分ごとです。DixaやGladlyなどの他のプラットフォームでは、最長で6時間ごとになることもあります。つまり、重要な更新を公開した直後には、AIが最新の情報を持っていない可能性があるということです。
Adaはまた、クリーンで論理的に構造化されたコンテンツを使用することを推奨しています。これはどのAIにとっても良いアドバイスですが、既存のドキュメントを効果的に使用できるようになる前に、書き直しや準備にかなりの時間を費やす必要があることを示唆しています。これもまた、リストに追加される手作業のステップです。
Adaの取り込みモデルの主な限界
Adaのアプローチは機能しますが、AIサポートの品質や立ち上げの速さに影響を与える可能性のある、いくつかの重大な限界があります。
非構造化知識への限定的なサポート
Adaのモデルは、完全に構造化され、事前に作成されたナレッジベースの記事に大きく依存しています。しかし、考えてみてください。あなたの会社で最も価値のあるサポート知識は、実際にはどこにありますか?それはおそらく、過去のサポートチケットや、最高の担当者が顧客の最も困難な問題をすでに解決してきた何千もの実際の会話の中に埋もれています。
Adaの取り込みプロセスには、この雑然とした非構造化情報の宝庫から学習する組み込みの方法がありません。そのすべての貴重なコンテキスト、ブランド独自の口調、そしてチームが実績を上げてきた解決策は置き去りにされてしまいます。あなたのAIは、実世界の経験ではなく、理論からスタートすることになるのです。
これは非常に大きな機会損失です。 eesel AIのようなより現代的なプラットフォームは、初日から過去のヘルプデスクチケットから直接学習することができます。ブランドのトーンを自動的に習得し、実際の顧客問題の微妙な詳細を理解し、実際に機能した解決策を見つけ出します。これは、マニュアルを読むだけのAIと、最高の担当者のように聞こえるAIとの違いです。
手作業で硬直的なセットアッププロセス
Adaで各ソースを接続するには、特定の複数ステップのセットアップが必要で、これが少し厄介な場合があります。もし、彼らの短い連携リストにないツールを使用している場合、すぐにAPIを使った開発プロジェクトに追い込まれます。
これにより、プラットフォームに合わせてツールやワークフローを曲げなければならない硬直的なシステムが生まれます。これは物事を遅らせ、多くのサポートチームが常駐させていない技術的な人材への依存を生み出します。
対照的に、eesel AIは**非常にシンプルでセルフサービスの体験**を提供します。ワンクリック連携でヘルプデスクや他のナレッジソースを接続し、数ヶ月ではなく数分で本番稼働できます。その考え方は、大きな頭痛の種になることなく、既存のワークフローにスムーズに組み込むことです。
リスクのないテストの欠如
知識の取り込みを設定するすべての手間をかけた後、大きな疑問が残ります。「このAIは、実際の顧客の質問に対して、実際にはどう機能するのだろうか?」
Adaのドキュメントには、顧客と話させる前に、過去のチケットに対するAIのパフォーマンスをテストできるシミュレーションツールについての言及がありません。これは、多くの不確実性を抱えたまま本番稼働しなければならないことを意味し、基本的にはスイッチを入れて最善を祈るしかありません。顧客満足度がかかっている状況で、本番環境でテストするのはリスキーなゲームです。
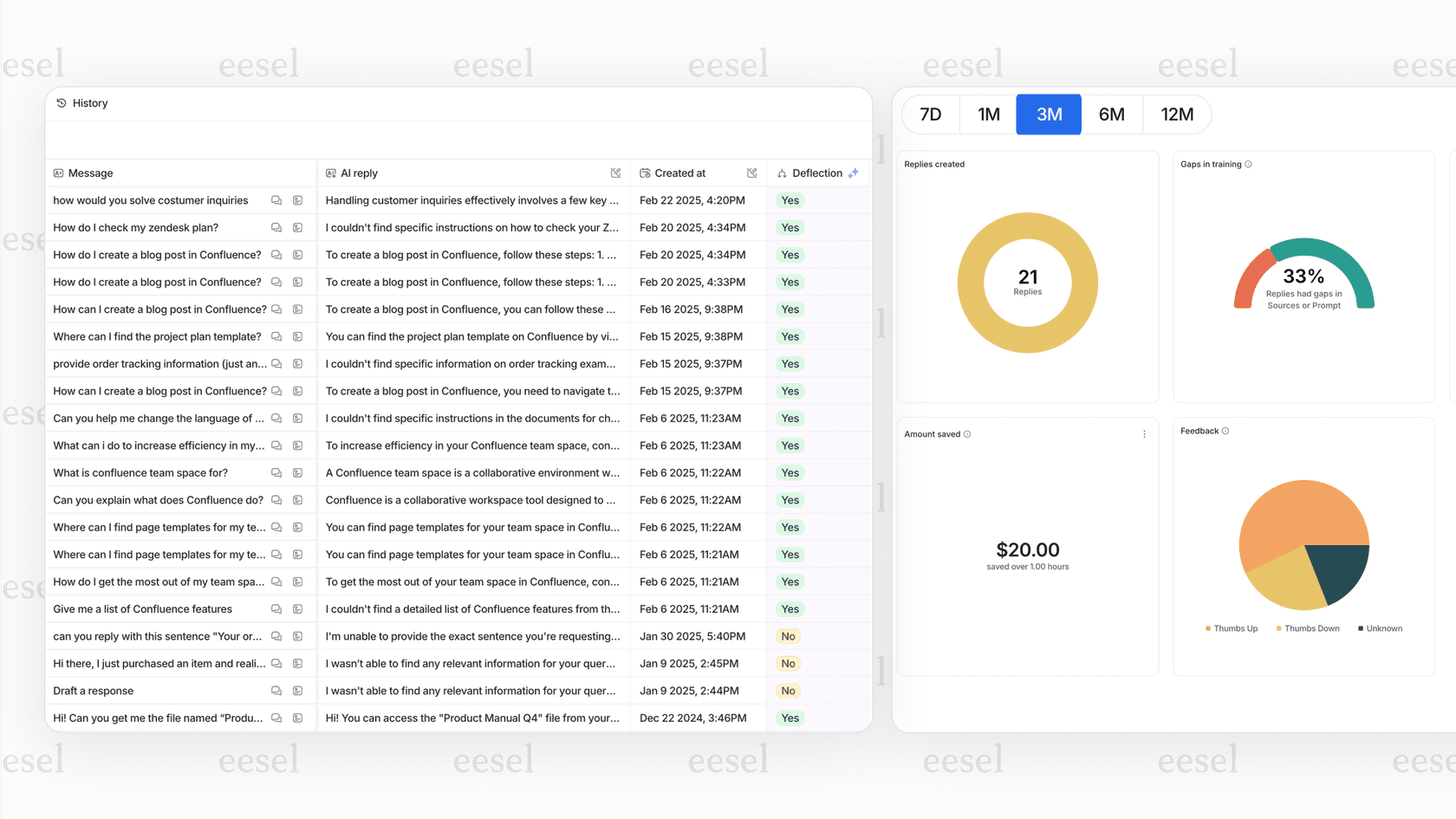
ここも、新しいプラットフォームが進んでいる点です。例えば、eesel AIのシミュレーションモードでは、プライベートなサンドボックスで何千もの過去のチケットに対してAIを安全にテストできます。これにより、解決率の確かな予測が得られ、さまざまな質問にどのように答えるかを正確に示し、知識のギャップを特定するのに役立ちます。一人の顧客とチャットする前に、完全な自信を築き、その振る舞いを微調整することができます。
価格
Adaの価格はウェブサイトに掲載されていません。これはエンタープライズソフトウェアでは一般的ですが、見積もりを得るには営業チームに連絡する必要があることを意味します。
ここでの主な欠点は、予算に合うかどうかを確認するためだけに、長い営業プロセスを経る可能性があることです。また、コストはチケット量や解決数など、月ごとに変動する可能性のある要素に連動する場合があるため、予測が難しいこともあります。
もう少し透明性を好むチームのために、他のプラットフォームは明確で予測可能な価格設定をしています。例えば、eesel AIのプランは公開されており、理解しやすいです。
| プラン | 月額料金(月払い) | 主な機能 |
|---|---|---|
| チーム | $299 | ウェブサイト/ドキュメントでのトレーニング、Slack連携、AI Copilot |
| ビジネス | $799 | チームプランの全機能 + 過去のチケットでのトレーニング、カスタムAIアクション、一括シミュレーション |
| カスタム | 営業担当者にお問い合わせください | 高度な連携、マルチエージェントオーケストレーション、カスタムコントロール |
ここでの重要な詳細は、eesel AIの価格が月々のAIインタラクション数に基づいており、解決ごとの追加料金がないことです。サポートが忙しい月だったからといって、請求額が突然跳ね上がることはありません。さらに、柔軟な月額プランにより、長期契約に縛られることなく、小さく始めていつでもキャンセルできます。
より良い代替案:eesel AIによる柔軟な知識の取り込み
Adaは堅実なプラットフォームですが、その知識取り込みモデルは少し硬直的で、開発者への依存度が高く、ローンチ前に安全にテストする方法を提供していません。迅速に動き、柔軟性を保つ必要があるチームにとっては、より良い方法があります。
eesel AIは、スピード、柔軟性、そして信頼性のために構築された現代的な代替案です。AIの頭脳を構築するための、はるかに直感的で強力な方法を提供します。
Title: 知識の取り込み:Ada vs eesel AI Ada Side:
-
限定的なソースのアイコン(Zendesk、Salesforceなどのヘルプデスク)。
-
APIのアイコン、ラベル「カスタムソースには開発者が必要」。
-
同期が遅いアイコン、ラベル「同期は15分〜6時間ごと」。
-
テストなしのアイコン、ラベル「リスクのないシミュレーションモードなし」。 eesel AI Side:
-
複数のソースのアイコン(ヘルプデスク、Confluence、Googleドキュメントなど)、ラベル「数十のノーコード連携」。
-
セルフサービスのアイコン、ラベル「誰でも数分でソースを接続可能」。
-
リアルタイム同期のアイコン、ラベル「リアルタイムデータから学習」。
-
シミュレーションのアイコン、ラベル「ローンチ前に過去のチケットで安全にテスト」。
以下にその違いを簡単にまとめます:
-
面倒なくすべてを接続: ヘルプセンター、過去のチケット、Confluence、Googleドキュメント、その他数十のソースを、コード不要で即座に連携できます。
-
数ヶ月ではなく数分で本番稼働: 真のセルフサービスプラットフォームです。サインアップし、ツールを接続すれば、営業担当者と話すことなく、数分で機能するAIエージェントを準備できます。
-
チームの最高の仕事から学ぶ: AIは過去のチケット解決策を自動的に分析するため、その回答は顧客にとって実際に機能したものに基づいています。
-
完全な自信を持ってテスト: シミュレーションモードを使用して、AIがどれだけうまく機能するかを確認し、顧客向けに有効にする前にROIの明確な予測を得ることができます。
知識の取り込みを正しく行う
知識の取り込みを正しく行うことは、優れたAIサポート戦略の基盤です。それは、チームの誰もが管理できるほどシンプルで、すべての知識を取り込めるほど強力で、あなたと共に成長できるほど柔軟でなければなりません。
Adaのような従来のプラットフォームは、構造化されているものの、しばしば扱いにくいアプローチを提供しますが、eesel AIのような現代的なソリューションは、今日のサポートチームが本当に必要とするスピード、柔軟性、そして賢い学習能力を提供します。面倒な作業を自動化し、自信を持ってローンチするためのツールを提供することで、数ヶ月にわたるセットアップに時間を費やすのをやめ、数日で結果を見始めることができます。
真にシームレスな知識取り込みプロセスがどのようなものか見てみませんか?ぜひeesel AIをお試しください。
よくある質問
Adaの知識取り込みは、主にZendesk、Salesforce、Contentfulなどの人気ヘルプデスクプラットフォームとの事前構築済み連携を介して接続します。通常、Adaのダッシュボードにログインし、プラットフォームを選択して認証情報を入力します。このプロセスにより、Adaは既存のナレッジベースの記事を取り込むことができます。
ナレッジが事前連携済みのプラットフォームにない場合、AdaはナレッジAPIの使用を要求します。これは、チームのエンジニアが接続を構築・維持するためにカスタムコードを記述する必要があることを意味し、簡単なタスクが開発プロジェクトに変わる可能性があります。
はい、Adaの知識取り込みは、完全に構造化された、事前に作成されたナレッジベースの記事に大きく依存しています。価値ある実世界の解決策をしばしば含む、過去のサポートチケットのような非構造化データソースから学習するための組み込み機能がありません。
Adaの知識取り込みは、接続されたナレッジベースからのデータを様々な間隔で同期します。ZendeskやSalesforceのようなプラットフォームでは約15分ごとですが、DixaやGladlyのような他のプラットフォームでは最大6時間かかることがあります。これは、AIが更新直後に常に最新の情報を持っているとは限らないことを意味します。
Adaのドキュメントには、デプロイ前に過去のチケットでAIのパフォーマンスをテストするための組み込みシミュレーションツールについての言及がありません。これは、通常、ある程度の不確実性を持って本番稼働し、実質的に実際の顧客がいる本番環境でテストすることを意味します。
Adaの知識取り込みのセットアップは、多くの場合、複数のステップからなるプロセスです。特に、標準的でないソースに対してAPIを使用する必要がある場合は、開発者の関与が必要です。これにより、プロセスが硬直的になり、ワークフローをAdaの構造に合わせる必要が生じることがあります。
Share this article

Article by
Kenneth Pangan
Writer and marketer for over ten years, Kenneth Pangan splits his time between history, politics, and art with plenty of interruptions from his dogs demanding attention.


